AWS for Industries
AWS Professional Services and BMW collaborate to optimize petabyte-scale storage costs for automated driving data
As automated driving platforms evolve, they continue to generate unprecedented volumes of data from various sensors, simulations, and testing environments. A single automated driving test vehicle can produce tens of terabytes of data daily, which means that organizations managing entire fleets require petabyte-scale storage. The rapid growth in data, combined with the need to retain historical data for training and validation, creates significant challenges for managing storage costs effectively.
Amazon Simple Storage Service (Amazon S3) is the best storage solution in AWS to store petabytes of data, offering a rich set of features to optimize costs and performance. For automated driving workloads, Amazon Mountpoint for S3 enables high-throughput data access to Amazon S3 during processing, helping eliminate the need to duplicate data to other storage options. This helps lower the cost of running data intensive workloads in the cloud. Additionally, features like Amazon Storage Lens and Amazon S3 Access Logging and Storage Tiering help provide customers like BMW with exceptional insights into their data access patterns and detailed breakdowns of storage costs.
BMW Group recently worked alongside AWS Professional Services—a global team of experts that can help companies realize their desired business outcomes when using the AWS Cloud—to help migrate significant automated driving workloads to AWS. After scaling up data collection and large-scale reprocessing pipelines, software architects at BMW identified opportunities to optimize data workloads and reduce cloud storage costs. The initiative led to a collaboration with AWS Professional Services that focused on leveraging Amazon S3 features to analyse data, recommend and implement cost-saving solutions, and monitor achieved cost reductions.
In this blog post, we explore how AWS used Amazon S3 features to help optimize costs for a petabyte-scale automated driving data lake. While this blog focuses on automated driving, we note that the strategies and recommendations that we discuss are broadly applicable across industries dealing with large-scale data storage. Whether you’re in finance, handling transaction records, or in media, storing high-resolution video content, the principles we explore can be adapted to help optimize your Amazon S3 storage costs.
Challenges of managing petabyte-scale data lakes
Organizations managing petabyte-scale data lakes face three key challenges:
1. Rising costs: Organizations face rapid data expansion, which makes cost prediction and management increasingly difficult. Redundant data and successive versions can accumulate quickly. The implementation of proper life cycle management becomes crucial, yet it is complex to carry out at scale, requiring careful planning and continuous monitoring. Additionally, indirect costs, such as versioning overhead and unexpected retrieval fees, can disrupt predictable cost structures.
2. Limited visibility: Organizations managing petabyte-scale data lakes struggle to understand data access patterns and diverse workload requirements across their entire data estate. This limited visibility complicates storage optimization and cost management, especially with seasonal fluctuations and evolving business needs.
3. Complex decision-making: The combination of substantial storage costs and insufficient visibility into data usage patterns, coupled with organizational complexities, often leads to decision paralysis in data management initiatives. Without comprehensive insights into data access patterns, lifecycle stages, and usage trends, organizations struggle to implement effective data tiering and archival strategies. The risk of suboptimal decisions about data movement between storage tiers increases when lacking actionable intelligence, potentially resulting in unnecessary costs or performance issues.
How Amazon S3 can help address the above challenges
These interconnected challenges—cost, limited visibility, and complex decision-making—may together form a significant hurdle to the effective management of petabyte-scale data storage. Amazon S3 offers a rich set of features to address these challenges:
- Amazon S3 Storage Lens is a cloud storage analytics feature that provides organization-wide visibility into object storage usage, activity trends, and optimization recommendations for Amazon S3.
- Amazon S3 Intelligent-Tiering Storage class automatically moves data to cheaper storage classes after 30 days.
- Amazon S3 Server Access Logging delivers detailed records for each request made to a bucket.
For organizations managing large-scale data lakes, Amazon S3 Storage Lens and Amazon S3 Intelligent Tiering are a great starting point to understand and automatically optimize Amazon S3 storage. However, for the volume of data involved in this use case, waiting 30 days for data to be transitioned by Amazon S3 Intelligent Tiering would be too long and costly. To address this, Amazon S3 Server Access Logging can be used by customers to obtain more detailed and immediate insights into data access patterns.
In the following sections, we’ll explore proven strategies and best practices that organizations can adopt to help optimize Amazon S3 storage costs while maintaining operational efficiency and performance. Specifically, we will explore how BMW implemented a strategy to help optimize its automated driving data and help reduce its Amazon S3 costs.
Technical solution
The architecture uses Amazon S3 Inventory reports and Amazon S3 Access Logging to provide detailed visibility into object sizes and access patterns. It then exposes the data through Amazon Athena, an interactive query service that simplifies data analysis in Amazon S3 using standard structured query language (SQL). The data is finally visualized through Grafana dashboards to help empower data architects to make informed decisions about storage optimization and data expiration.
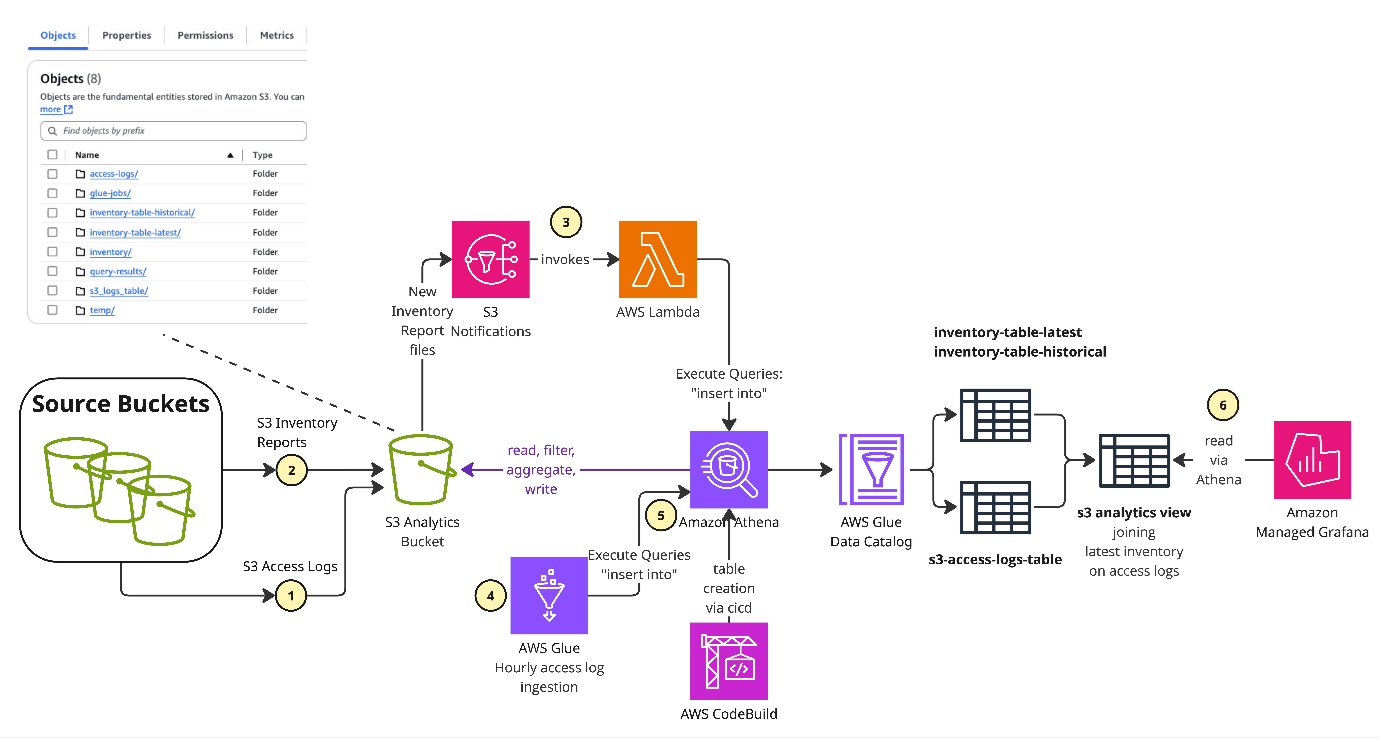
Figure 1: Architecture with Amazon S3 inventory reports and access logs
Walk-through of the solution
Step 1: Access logs: AWS set up Amazon S3 Server Access Logging for all the data Amazon S3 buckets to a centralized logging bucket. To manage the high volume of logs, we filter, aggregate, and then delete access logs within one hour of creation.
Step 2: Inventory report: We configured daily Amazon S3 Inventory reports, using the Apache Parquet format for optimal query performance. These reports capture essential metadata, including object size, last modified date, and storage class information.
Step 3: Event processing: Amazon S3 Event Notifications were created in Amazon S3 analytics bucket to trigger a serverless AWS Lambda function to ingest inventory reports. The Lambda function creates an Apache Iceberg–formatted table in Amazon S3 for storing inventory reports, partitioned by date.
Step 4: Data engineering: We used AWS Glue, a service for discovering, preparing, and integrating all an organization’s data at any scale, and it runs each hour to process new access logs. Once successfully processed, those raw logs are automatically deleted to optimize storage. Each time the AWS Glue job is triggered, it puts the Amazon S3 access logs into Parquet format. That transformation extracts and stores only the most relevant data attributes for our analysis, including object key, minimum and maximum timestamps from Amazon S3 GetObject operations, and it aggregates metrics like number of requests and gigabytes retrieved for the given hour. The Parquet-formatted data is then stored in a dedicated Amazon S3 location where it is partitioned by date, which helps significantly improves query performance and helps reduce storage costs as compared with using raw logs.
Step 5: Data analytics: For deployment, AWS created Amazon Athena tables that map onto the processed access logs and the inventory data, facilitating immediate SQL-based analysis. Next, created a view in AWS Athena that joins access logs to inventory reports. This helps in gaining insights from the data, such as which data is not being accessed at all, with breakdowns by tags and prefixes.
Step 6: Visualization: AWS set up Grafana dashboards using the Amazon Athena connector to help visualize the data. Dashboards include time-series charts of access patterns, storage distribution heat maps, and interactive filters. The visualizations are the main tool to help customers make data-driven decisions on storage optimizations and monitor the impact of actions.
Key benefits
Using the analytics infrastructure set forth in Figure 1 helps organisations see the following benefits:
Cost optimization at scale: Detailed visibility into object access patterns helps enable organizations to identify cost-saving opportunities with precision. This insight helps support data-driven decisions about either the transitioning of rarely accessed data to lower-cost storage tiers or the complete removal of unnecessary data. While there are operational costs associated with the solution—such as inventory reports at $0.0025 per million objects and storage for access logs—customers may experience a substantial return on investment from optimized storage-class selection and data cleanup.
Automated data life cycle management: The solution helps customers make evidence-based decisions about data retention and storage tiering. By understanding actual usage patterns, organizations can implement automated life cycle policies so that data moves between storage tiers according to real access patterns rather than assumptions or predictions. This helps reduce manual intervention while making sure that data is always stored in the most cost-effective way throughout its life cycle.
Enhanced data governance: Analytics-driven insights help enable organizations to make informed decisions to optimize data workloads without sacrificing on data consumer needs. The potential cost savings provide a clear and measurable justification for investments in storage optimizations.
Analytics and outcomes for BMW
With the data analytics infrastructure set up, AWS and BMW analysed data access patterns to enhance inventory reports with custom fields such as file types and sensor relationships. The analysis revealed a rapid growth in data volume and associated costs, which were driven by upscaling of automated driving reprocessing workloads.
We decided to make two key Amazon S3 configuration changes immediately. First, we activated the Amazon S3 Intelligent-Tiering storage class across all buckets. As mentioned earlier, this feature helps optimizes storage costs by transitioning data to colder access tiers when access patterns are unpredictable. Second, we disabled versioning, which previously required deletion-marked data to be retained for at least one day before expiration. This adjustment helped accelerate storage cleanup with BMW’s existing lifecycle management system.
Further investigations indicated improvement potential for data that is used as a cache to avoid redundant reprocessing runs. Our analysis showed that specific results were not accessed, and parts of the cache data wasn’t reused for subsequent pipeline steps. After evaluation, we adapted the pipeline and deleted unused data—eliminating nearly 30 percent of the account’s total Amazon S3 data and costs.
Additional recommendations required consultation with end-users, as they involved fundamental workflow changes. These included policies on which reprocessing results should be kept for caching and for how long, as well as retention periods for rarely accessed visualization and log files. Based on our access pattern data, the BMW team is now continuously refactoring their caching and lifecycle mechanisms for more prompt removal of data.
AWS Professional Services subsequently deployed the above solution in BMW’s larger central repository of vehicle recordings for its advanced driver-assistance systems test fleet. While already using Amazon S3 Intelligent-Tiering Storage class, BMW now uses this solution to identify recordings for faster archiving based on access patterns—potentially within days of arrival rather than waiting the standard 30 days of the Amazon S3 Intelligent-Tiering Storage class transition period.
A reusable cost optimization framework
The technical solution presented can offer high reusability and significant return on investment potential. A key success factor in its development was the collaboration between AWS experts and BMW stakeholders with deep understanding of data workflows and business context—essential resources for effective Amazon S3 cost optimization.
While specific optimization actions will vary by use case, we can share valuable general guidance to help optimize Amazon S3 cost.
Start with the dashboard for Amazon S3 Storage Lens—the first cloud storage analytics solution to provide a single view of object storage usage and activity across hundreds, or even thousands, of accounts in an organization—which can be found in the AWS Console for a comprehensive daily snapshot of your Amazon S3 storage. The dashboard provided most of the decision-making data for BMW, although it was required to set up Amazon S3 access logs and implement custom data pipeline to capture the critical last-read access date for each object.
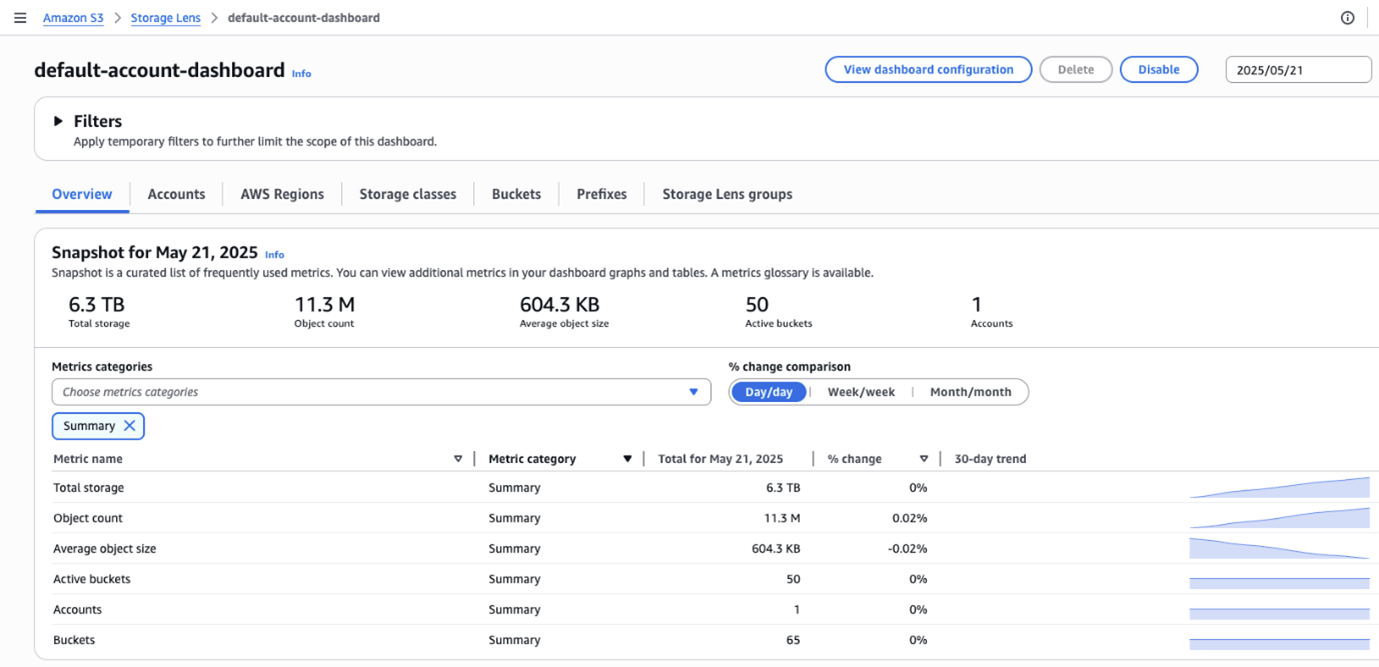
Figure 2: View of the Amazon S3 Storage Lens dashboard
Our Grafana dashboards featured breakdowns by tags, object prefixes, and suffixes aligned with business context. We incorporated file size analysis because Amazon S3 Intelligent-Tiering excludes objects below 128 KB and transition costs for small objects can take longer to offset through storage savings compared with larger files. Additional metrics included request versus storage cost ratios, gigabytes read, and projected costs across different storage classes—all crucial for informed decision-making.
We note that data lake administrators should evaluate object versioning requirements carefully and weigh automated deletion of noncurrent versions against data recovery costs and compliance needs.
Conclusion
The collaboration between AWS Professional Services and BMW demonstrates how data-driven analytics can transform storage cost management for petabyte-scale environments. By using our solution, BMW gained substantially greater visibility into its Amazon S3 storage patterns and the ability to make informed decisions, which resulted in significant cost savings.
- 30 percent of unused data was identified and deleted immediately
- Inactive data is transitioned to 40 percent cheaper storage after 30 days with Amazon S3 Intelligent Tiering
- Significant savings were achieved from optimized lifecycle management
What makes the approach particularly powerful is that it helps empower organizations to make proactive data management decisions well before the end of the standard Amazon S3 Intelligent-Tiering 30-day transition period. This solution can help organizations can identify optimization opportunities within days rather than waiting for automated tiering to take effect.
The framework is highly adaptable across industries facing similar data storage challenges. Whether you’re managing financial transaction records or media content libraries, a similar solution can help you:
- Gain visibility into your data access patterns
- Understand the business context of your storage
- Monitor and make data-driven decisions about storage classes and retention
- Implement automated policies based on actual usage patterns
As data volumes continue to grow rapidly across industries, implementing the strategies described here will help organizations be better positioned for more effective cost management while maintaining the performance and accessibility their businesses require.
The BMW case shows that even in the most data-intensive environments, such as automated driving development, significant cost optimization is achievable without compromising operational capabilities. By combining AWS storage optimization with analytics-driven insights, an organization can transform its approach to data storage so that a growing cost center becomes a strategically managed asset.