AWS for Industries
Build Secure Data Mesh with AWS and Partner Solutions
Introduction
Data mesh emerges as a transformative architectural paradigm that revolutionizes how organizations manage and share data across domains. By treating data as a product and decentralizing ownership to domain teams, data mesh enables scalable, secure, and efficient data sharing while preserving domain autonomy. This blog is intended for data architects and technical leaders who are implementing or planning to implement modern data mesh architectures. While this blog draws primarily from innovative implementations by leading global financial services organizations working with AWS and its partners, the principles and solutions discussed apply broadly across industries.
Financial institutions are increasingly adopting data mesh architectures to create comprehensive customer views across diverse products while maintaining domain-specific governance. These organizations face unique challenges in regulated environments where data has traditionally existed in silos. Today’s solutions leverage open table formats like Apache Iceberg, storage-compute separation across engines, and cloud-scale capabilities—representing an advancement over traditional query federation approaches.
The modern data mesh approach enables secure data sharing at the storage level while maintaining strict controls through entity authentication, consistent access controls, comprehensive audit trails, and data lineage tracking. This allows teams to select specialized engines that best suit their specific needs without compromising security or compliance requirements.
This blog explores three critical requirements for implementing a successful data mesh architecture that leverages both AWS native analytics services and third-party engines: (1) Cross-Catalog Metadata Federation, (2) Cross-Account & Cross-Engine Authentication and Authorization, and (3) Distributed Policy Enforcement.
We’ll examine practical implementation patterns with AWS as both a data producer and consumer, showcasing integration approaches with partners like Databricks and Snowflake as representative examples. These patterns show how organizations build flexible, secure, and scalable data architectures that support the core data mesh principles while maintaining enterprise-wide governance.
Core Concepts
Data Mesh
Data Mesh is an architectural and organizational approach to data management that shifts from centralized data platforms to a distributed, domain-oriented ownership model. It treats data as a product, making domain teams responsible for the data they produce. For example, in a financial institution, the credit card division owns and manages its customer transaction data as a product, making it securely available to other divisions, like fraud detection or marketing analytics, through well-defined interfaces and access controls.
Core principles of data mesh include (1) domain-oriented ownership, (2) data as a product, (3) self-serve data infrastructure and (4) federated governance. For additional information, visit What is Data Mesh? and Let’s Architect! Architecting a data mesh.
In data mesh data, data producers expose their data for consumption to data consumers. A federated governance layer regulates access to the data. Consumers and producers need to access and share data between AWS native services and AWS Partner platform.
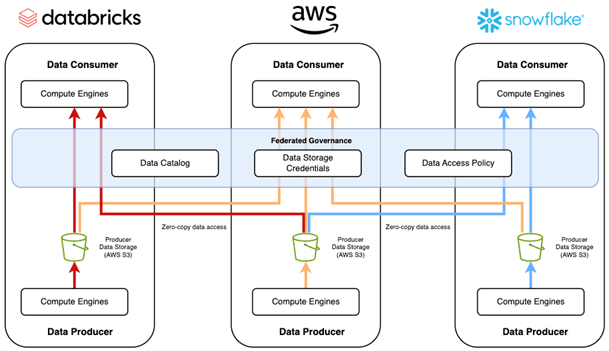
Figure 1. shows conceptual data mesh design with AWS native services and AWS partners, such as Databricks and Snowflake. Both the AWS and AWS partners play the roles of data consumers and data producers.
Iceberg open table data format
Apache Iceberg is an open table format crucial for data mesh architectures, primarily because of its cross-platform compatibility, which enables consistent data access across diverse query engines like Amazon Athena, Snowflake, and Databricks—essential for heterogeneous data mesh environments. It also supports schema evolution without disrupting consumers, provides time travel capabilities for governance and auditability, maintains data consistency through ACID transactions, and enables fine-grained access control across platforms, which help maintain interoperability between domains while preserving data integrity and governance.
AWS Lake Formation
AWS Lake Formation helps you centrally govern, secure, and share data for analytics and machine learning. It provides fine-grained access control for data stored in various data stores including Amazon Simple Storage Service (Amazon S3) and Amazon Redshift and metadata in AWS Glue Data Catalog.
The next generation of Amazon SageMaker
The lakehouse architecture of Amazon SageMaker unifies data lakes and warehouses on one open platform using Apache Iceberg. The Lakehouse streamlines connecting to, cataloging, and managing permissions on data from multiple sources. Built on AWS Glue Data Catalog and AWS Lake Formation, it organizes data through catalogs that can be accessed through an open Apache Iceberg REST API, providing secure access to data with consistent, fine-grained access controls.
Amazon SageMaker Unified Studio functions as the development environment and orchestration layer for Amazon Lakehouse architecture. While Lakehouse provides the Apache Iceberg-based data foundation, SageMaker Unified Studio is where data scientists, analysts, and developers interact with data from both AWS services and external partner platforms. Refer to Connect, share, and query where your data sits using Amazon SageMaker Unified Studio blog for additional information.
Identity and Access Control Management
Financial Services organizations have evolved from siloed data to data mesh architectures, enabled by open table formats, storage-compute separation, and cloud capabilities. This shift allows secure data sharing at the storage level rather than through query federation, while maintaining strict controls through entity authentication, consistent cross-engine access controls, comprehensive auditing, compliance monitoring, and data lineage tracking. This approach enables teams to select specialized engines while preserving organizational security and compliance requirements.
As data mesh architectures evolve for cross-engine data sharing, two key security requirements emerge:
- Consistent entity identities across platforms
- Uniform access controls across platforms
User vs. Engine Identity
In multi-query engine environments, both user and engine identities are essential. Users need consistent identities across services (managed via federated identity provider, IDP servers), while engines require system identities when connecting to federated data sources on users’ behalf. Engines must establish trust relationships with each other to maintain security while enabling seamless cross-engine operations.
Access Controls
After identity verification, access control involves two key aspects: policy definition (specifying allowed actions across AWS and non-AWS engines) and policy enforcement (implemented at engine level with regular synchronization). This approach maintains consistent security, regardless of whether data is accessed through AWS or partner engines.
Multi-engine data meshes leverage two complementary access control models:
- Coarse-grained access using IAM/S3 policies.
- Fine-grained access control (FGAC) using Lake formation.
Lake formation supports various permission models for managing fine-grained access control permission, including role-based access control using named resources with data filters:
- Tag-based access control (TBAC): LF-Tags is a mechanism that can group similar resources together and grant permission on the group of resources to principals, enabling you to scale your permissions.
- Attribute-based access control (ABAC): You can now grant permissions on a resource based on user attribute and is context-driven, enabling precise security measures like row-level filtering based on specific attribute values.
Successful implementation requires careful policy translation across engines to maintain consistent security enforcement, regardless of which access point users use to interact with the data mesh.
Data interoperability requirements in data mesh architectures
Data interoperability is the ability of systems to securely access, interpret, and process data from a common storage layer without duplication. In this blog, we focus specifically on interoperability between data consumers and producers using AWS-managed storage across AWS native services and Partner platforms.
Key Data Interoperability Requirements for Data Mesh Implementation:
1. Cross-Catalog Metadata Federation – Enabling domain data products to be discoverable across organizational boundaries through federated metadata catalogs
2. Cross-Account Authentication and Authorization – Implementing secure credential management that allows consumer query engines to access producer data with appropriate permissions
3. Distributed Policy Enforcement – Establishing consistent governance mechanisms that apply producer-defined access policies across data consumption points
Figure 2 illustrates the application of permission granularity in a data mesh architecture. It shows the distinction between coarse-grained and fine-grained permissions based on whether the system assumes User identity or Engine identity during the data federation process.
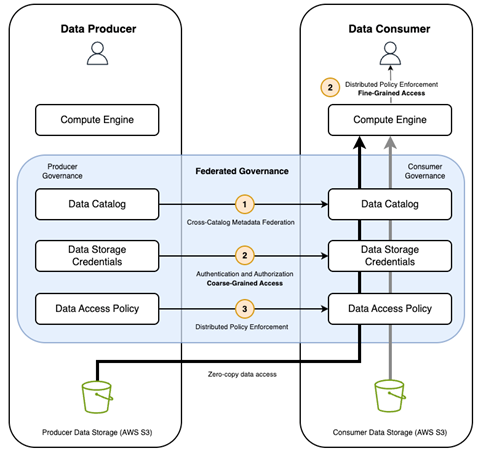 Figure 2. This diagram illustrates how data interoperability requirements enable secure sharing between producer and consumer platforms in a data mesh. Cross Catalog access is done using Application/system identity and Engine for a User identity enforces then FGAC control, as defined in the consumer catalog.
Figure 2. This diagram illustrates how data interoperability requirements enable secure sharing between producer and consumer platforms in a data mesh. Cross Catalog access is done using Application/system identity and Engine for a User identity enforces then FGAC control, as defined in the consumer catalog.
Let’s explore how AWS and its partners build data mesh architectures and implement data interoperability requirements through two key patterns: AWS Platform as a Data Producer and AWS Platform as a Data Consumer.
Implementing data mesh: AWS as a Data Producer
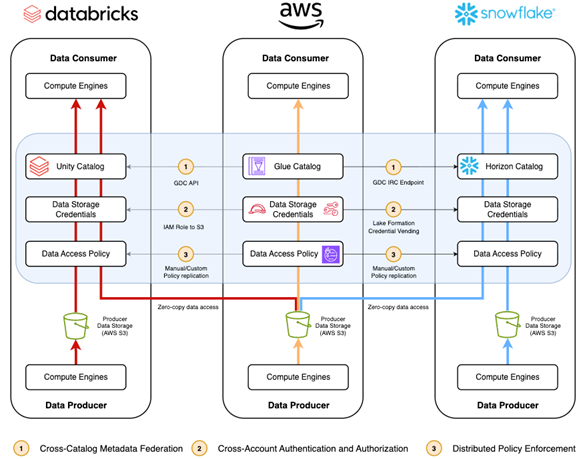
Figure 3. This diagram shows AWS functioning as a data producer in a data mesh architecture, illustrating data flow from producers using AWS native services to consumers using both AWS partners and AWS native services. Both AWS native compute engines and partner compute engines consume data directly from the AWS-managed data lake.
AWS native data interoperability capabilities as a data producer
1. Cross-Catalog Metadata Federation
Third party query engines use the AWS Glue Data Catalog (GDC) to discover and understand data in AWS data lake managed by Lake Formation. GDC provides a consistent way to maintain schema definitions, data types, locations, and other metadata. Catalog federation to Glue Data Catalog can be established either via AWS Glue API or AWS Glue Iceberg REST Endpoint (Glue IRC).
While both approaches support Apache Iceberg tables, Glue IRC API enables a standard set of REST APIs for integration and provides support for authentication and authorization simplifying the framework.
2. Cross-Account Authentication and Authorization
Third-party query engines access data discovered in the GDC catalog using either Lake Formation managed credentials or IAM Principal Roles for direct S3 access. Lake Formation credential vending is the recommended approach.
| Feature | Lake Formation Credentials | IAM Principal for S3 |
| Purpose | Data lake access management | AWS resource access control |
| Granularity | Fine-grained (table/column/row) | Coarse-grained (bucket/prefix/object) |
| Management | Centralized in Lake Formation | IAM and S3 bucket policies |
| IAM/S3 policies | Lake Formation control is applied | Directly control access |
| User experience | No direct S3 permissions needed | Explicit S3 permissions required |
| Integration | AWS analytics and third-party apps | Direct application/user access |
Table 1. This table compares Lake Formation credentials vending (recommended approach) versus IAM Principal Role methods for accessing S3 locations.
3. Distributed Policy Enforcement
Integrating with AWS Lake Formation enables third-party services to securely access data in Amazon S3-based data lakes with full table access permissions. Organizations need to supplement this with manual policy sharing or additional mechanisms for the third-party query engine to enforce fine-grained access control policies.
Partner specific data interoperability capabilities as data consumers
Databricks
1. Cross-Catalog Metadata Federation
Databricks Lakehouse Federation lets organizations query and govern external data systems as Lakehouse extensions. When connecting to GDC, Databricks uses the GDC API for metadata discovery and federation, not the Iceberg REST Catalog endpoint. Refer to Announcing General Availability of Hive Metastore and AWS Glue Federation in Unity Catalog for additional information.
2. Cross-Account Authentication and Authorization
For data access permissions, Databricks uses traditional cross-account IAM role-based access patterns to reach S3 data, rather than Lake Formation’s credential vending mechanisms. Customers must explicitly register S3 bucket storage in the Unity Catalog for each table they federate to.
3. Distributed Policy Enforcement
To replicate Lake Formation’s fine-grained access controls in Databricks, you need a synchronization mechanism to extract access policies from Lake Formation, transform them into equivalent Databricks Unity Catalog permissions. These fine-grained access policies can either be replicated manually or via a custom-built solution that keeps both systems synchronized.
Snowflake
1. Cross-Catalog Metadata Federation
To implement cross-catalog metadata federation from AWS Glue Data Catalog to Snowflake Horizon catalog, Snowflake uses a catalog integration. To integrate with AWS Glue, Snowflake recommends creating a catalog integration for the AWS Glue Iceberg REST endpoint, which supports additional Iceberg table features such as catalog-vended credentials. Refer to Catalog integration for Apache IRC for additional information.
2. Cross-Account Authentication and Authorization
Snowflake Horizon Catalog integration with AWS Glue’s Iceberg REST endpoint supports Lake Formation credentials vending (currently coarse-grained only). Refer to Use catalog-vended credentials for Apache Iceberg™ tables for additional information.
3. Distributed Policy Enforcement
To replicate Lake Formation’s fine-grained access controls in Snowflake, you need a synchronization mechanism to extract access policies from Lake Formation, transform them into equivalent Snowflake Horizon Catalog permissions. These fine-grained access policies can either be replicated manually or via a custom-built solution that keeps both systems synchronized.
| Patterns | Requirements | Integration Capabilities |
| Databricks as Consumer (AWS as Producer) | 1. Catalog federation | UC to GDC federation |
| 2. Data storage permissions | IAM role access to S3
(no support for LF credentials) |
|
| 3. Data policy enforcement | Fine-grained policies replicated via custom process and enforced by Databricks | |
| Snowflake as Consumer (AWS as a Producer) | 1. Metadata federation | CREATE CATALOG INTEGRATION (Apache Iceberg™ REST) |
| 2.Data storage permissions | Use catalog-vended credentials for Apache Iceberg™ with Lake Formation credentials with full table access | |
| 3. Data access policies | FGAC policies replicated via custom process and enforced by Snowflake |
Table 2. This table summarizes the integration capabilities provided by Databricks and Snowflake that enable data interoperability with an AWS-managed data lake when implementing the AWS as Data Producer pattern.
Implementing Data Mesh: AWS Platform as a Data Consumer
Figure 4 illustrates the data from data producers using AWS partner platforms to data consumers using AWS native analytic services.
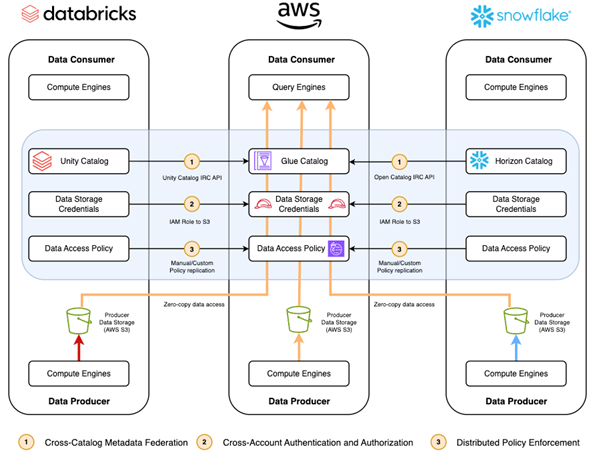
Figure 4. This diagram shows an AWS platform functioning as a data consumer in a data mesh architecture. AWS native compute consumes data from the AWS-managed data lake and from the partners’ managed storage.
AWS native data interoperability capabilities as a data consumer
1. Cross-Catalog Metadata Federation
AWS Glue now supports catalog federation to remote Iceberg. This capability enables you to federate AWS Glue Data Catalog with Databricks Unity Catalog, Snowflake Polaris Catalog as well as Horizon Catalog and custom Iceberg REST catalog implementations. Once integrated, AWS Glue automatically manages metadata synchronization in the background, ensuring query results reflect the latest table changes from remote catalogs. Federated tables are discoverable and queryable using AWS analytics engines including Amazon Redshift, Amazon EMR, Amazon Athena, and AWS Glue.
2. Cross-Account Authentication and Authorization
Lake Formation extends data governance to federated sources using the same applications integration process AWS native services employ for data lake access. Catalog federation uses Lake Formation fine-grained access control against federated data sources.
When a user submits a query to an AWS compute service like Athena, the AWS native service forwards the request to Lake Formation to verify access permissions and get the credentials. Upon authorization, Lake Formation provides these credentials to the AWS native service, enabling it to access the requested data in Amazon S3. When querying federated tables, AWS Glue discovers current metadata from the remote catalog at query time, while Lake Formation manages access by vending scoped credentials to the table data stored in S3 bucket. The AWS native service then applies the policy-based filtering to the retrieved data before returning results to the user.
3. Distributed Policy Enforcement
Lake Formation provides comprehensive access control for federated Iceberg catalogs, allowing data owners to grant column-, row-, and cell-level permissions when sharing federated tables across AWS accounts. Lake Formation also supports tag-based access control (TBAC) on databases/tables/columns of federated catalogs, enabling organizations to streamline governance by applying tags to remote catalog objects rather than managing individual resource policies. However, organizations must implement supplementary policy sharing or additional mechanisms to synchronize fine-grained access controls from third-party platforms to Lake Formation for subsequent enforcement.
Partner specific data interoperability capabilities as data producers
Databricks
1. Cross-Catalog Metadata Federation
Unity Catalog is built on OpenAPI specifications, with Apache 2.0 licensing, offering broad compatibility through multiple API standards. See Open Sourcing Unity Catalog for product details.
Databricks provides access to Unity Catalog tables using the Unity REST API and Apache Iceberg REST catalog. Refer to Access Databricks tables from Apache Iceberg clients and Enable external data access to Unity Catalog for specific instructions.
2. Cross-Account Authentication and Authorization
Unity Catalog credential vending allows users to configure external clients to inherit privileges on data governed by Databricks. Both Iceberg and Delta clients support credential vending. See Unity Catalog credential vending for external system access, access Databricks data using external systems, as well as and how to create service credentials for AWS specific instructions.
For data access permissions, Glue Data Catalog uses traditional cross-account IAM role-based access patterns to reach S3 data and not Unity credential vending mechanisms. Customers must explicitly setup permission to S3 bucket storage as part of federation so that Lake Formation manages temporary credential vending.
3. Distributed Policy Enforcement
Replicating Databricks Unity Catalog’s fine-grained controls in Lake Formation requires a synchronization mechanism that extracts and transforms Unity Catalog policies into equivalent Lake Formation permissions. Organizations implement this either through manual policy replication or by developing a custom solution that maintains continuous synchronization between both governance systems.
Snowflake
1. Cross-Catalog Metadata Federation
Snowflake Open Catalog is designed to support interoperability with third-party query engines by exposing any Iceberg table metadata via open APIs. This allows external engines to access the metadata and query data stored in Snowflake Open Catalog, supporting a federated data access approach. In addition, Horizon Catalog exposes Apache Iceberg™ REST APIs, which lets you to read the Iceberg tables by using external query engines. Please note that while Snowflake Open Catalog is a managed version of Apache Polaris, customers can also choose to self-host Apache Polaris directly. Visit Getting started with Snowflake Open Catalog for further reference.
2. Cross-Account Authentication and Authorization
Snowflake Open Catalog credential vending centralizes access management for both Open Catalog metadata and Apache Iceberg table storage locations. When enabled, Open Catalog provides query engines with temporary storage credentials to access table data, eliminating the need to manage storage access separately. Refer to Snowflake Open Catalog credentials vending and Enable credential vending for an external catalog for specific instructions.
Query Iceberg tables in Snowflake in a new or existing Snowflake account by using a single Horizon Catalog endpoint and provides query engines with temporary storage credentials to access table data. Refer to Query Apache Iceberg™ tables with an external engine through Snowflake Horizon Catalog.
For data access permissions, GDC uses cross-account IAM role-based access patterns to reach S3 data and not Snowflake credential vending mechanisms. Customers must explicitly setup permission to S3 bucket storage as part of federation so that Lake Formation manages temporary credential vending.
3. Distributed Policy Enforcement
To replicate Snowflake’s fine-grained controls in Lake Formation, you need a synchronization mechanism to extract access policies from Snowflake, transform them into equivalent Lake Formation permissions. These fine-grained access policies can either be replicated manually or via a custom-built solution that keeps both systems synchronized.
| Patterns | Requirements | Integration Capabilities |
| Databricks as Producer (AWS as Consumer) | 1. Catalog federation | AWS Glue catalog federation to Unity Catalog |
| 2. Data storage permissions | IAM Role for S3 access | |
| 3. Data policy enforcement | FGAC policies replicated manually or via custom logic to Lake Formation for enforcement | |
| Snowflake as Producer (AWS as a Consumer) | 1. Metadata federation | AWS Glue catalog federation to use Open Catalog or Horizon Catalog IRC APIs |
| 2. Data storage permissions | IAM Role for S3 access | |
| 3. Data access policies | FGAC policies replicated manually or via custom logic to Lake Formation for enforcement |
Table 3. This table summarizes the integration capabilities provided by AWS that enable data interoperability with Databricks and Snowflake when implementing the AWS as Data Consumer pattern.
Conclusion
Implementing a successful data mesh architecture requires addressing three critical interoperability requirements: Cross-Catalog Metadata Federation, Cross-Account Authentication and Authorization, and Distributed Policy Enforcement. AWS Lake Formation provides a robust foundation for data mesh implementations, while partners supporting open table formats like Apache Iceberg offer complementary capabilities that enable organizations to build flexible, secure, and scalable data architectures. We demonstrate these patterns using Databricks and Snowflake as representative examples.
Apache Iceberg offers compelling advantages as a table format for organizations considering data mesh architectures. Its cross-platform compatibility enables consistent data access across different query engines, while providing streamlined integration options with simplified authentication/authorization. The format also supports valuable features like schema evolution, time travel capabilities, and ACID transactions, which can help maintain data integrity in distributed ownership scenarios. These characteristics make Iceberg worth evaluating for teams looking to implement data mesh approaches
Implement cross-catalog metadata federation by leveraging AWS and partner capabilities to create a unified view of distributed data assets, making data discovery seamless while preserving domain ownership. This critical balance enables Financial Services organizations to maintain both innovation speed and regulatory compliance while breaking down traditional data silos.
Finally, teams should establish standardized policy definitions across the organization before implementing data mesh. Creating a common framework for security policies that can be translated between platforms (AWS Lake Formation, Databricks, Snowflake, and others) maintains consistent governance while allowing domain teams the autonomy to manage their data products. Policy standardization remains a key focus area, with efforts directed toward establishing common policy definition formats and improving cross-engine policy translation. As these technologies mature, organizations can confidently build secure, scalable data mesh architectures that enable domain teams to own their data products while maintaining enterprise-wide governance and interoperability across the entire data ecosystem.