AWS for Industries
Federated learning-based protein language models with Apheris on AWS
Healthcare and Life Sciences (HCLS) organizations face significant challenges in leveraging their valuable proprietary datasets due to privacy regulations and IP protection concerns. Apheris, an AWS technology partner, offers Apheris Gateway, which enables federated learning-based AI model training across multiple sites without sharing raw data. This allows data custodians to share insights while maintaining privacy and control over their sensitive data. The AI Structural Biology (AISB) consortium, consisting of major pharmaceutical companies like AbbVie, AstraZeneca, Johnson & Johnson, and Sanofi, has adopted this technology to advance research in AI-driven drug discovery.
We will show how you can use Apheris Gateway on Amazon Web Services (AWS) to fine-tune protein language models (pLMs) or foundation models (FMs), specifically the evolutionary scale modeling (ESM-2) architecture, for protein binding site prediction.
Organizations invest substantial intellectual and financial resources to generate training data through complex research and experimentation. As a result, these scarce datasets are critical intellectual property that requires privacy-preserving training strategies.
Federated learning is a machine learning approach that can train models across multiple distributed sites or organizations without sharing raw data. It supports collaborative model development, while preserving data privacy, eliminating the need to consolidate sensitive data into a central repository.
The process begins with a central server distributing a base model to participating sites, where each site trains the model using only its local data. The sites then send model updates back to the central server, which aggregates and redistributes these updates to improve the global model’s performance. This approach ensures regulatory compliance while unlocking the value of private datasets, making it essential for industries like HCLS, finance, and automotive, where data protection is paramount.
We will demonstrate a federated implementation of low-rank adaptation (LoRA) to fine-tune the 35M-parameter ESM-2 model for protein binding site prediction. This uses a full rank aggregation scheme for the LoRA adapters (FRA-LoRA), developed by Apheris on AWS infrastructure. Experimental results on real-world data demonstrate that this approach achieves comparable performance to traditional, centralized learning techniques while preserving data privacy.
HCLS customers can leverage the Apheris solution by either joining existing federated networks or establishing their own custom networks. Researchers, data scientists, and machine learning engineers can deploy and run federated workloads on diverse and distributed datasets, resulting in more robust and generalizable AI models.
Federated fine-tuning of ESM-2 model on AWS
The ESM architecture adapts large language model (LLM) concepts to process protein amino acid sequences numerically through a transformer-based system that handles the 20 standard amino acids. The model converts each amino acid token into a high-dimensional vector through an embedding layer. It combines these with positional encodings to maintain sequence order, and feeds them into transformer layers for downstream tasks like binding site prediction.
Unlike traditional multi-step pipelines that require time-intensive multiple sequence alignment (MSA) and 3D structure prediction for molecular docking analysis, ESM-2 employs a more efficient sequence-based training strategy that eliminates the MSA step. You can fine-tune an ESM-2 model using protein sequences with token-level binding site annotations from a binding site classification dataset.
With large models, traditional fine-tuning becomes challenging and resource-intensive, even for small datasets. LoRA offers a parameter-efficient solution by freezing original weights and introducing two smaller, low-dimensional adapters to approximate weight matrix updates. This reduces computational overhead while maintaining model performance.
Federated learning enables model fine-tuning on datasets with privacy or intellectual property restrictions. In this approach, sites train models locally and share only updated model weights with a central server for aggregation and redistribution.
In the following example we fine-tune the ESM-2 model, managed by Apheris Gateway, on Amazon Elastic Kubernetes Service (Amazon EKS), using decentralized datasets. Apheris supports training a federated model either sequentially on each dataset or through multiple rounds across all datasets with aggregated updates. In this setup, each training site operates its own Amazon EKS cluster with exclusive Amazon Simple Storage Service (Amazon S3) storage, verifying that only model parameters are shared between sites.
Architectural setup
The architecture diagram of Apheris’ federated fine-tuning framework on AWS is illustrated in Figure 1. It consists of individual Amazon EKS clusters.
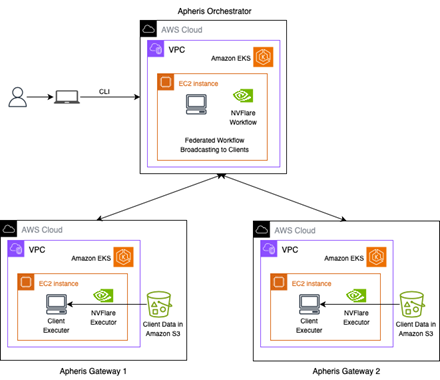
Figure 1: Architecture of federated fine-tuning of protein language model with Apheris on AWS
The Apheris Gateway is an agent that customers can deploy into a Kubernetes cluster, which launches computations as pods in this cluster. Each Gateway, hosting its local training data, deploys within its own isolated Amazon Virtual Private Cloud (Amazon VPC). The central Apheris Orchestrator, responsible for model parameter collection and aggregation, also deploys in its own VPC.
The setup uses Amazon S3, in combination with the Apheris Data Access Layer and configurable access permissions in the Apheris product, to manage data access control. This enables strict enforcement of data governance rules. It stores training data in S3 buckets while supporting Amazon Redshift and Amazon SageMaker Data Wrangler as additional data sources.
The Amazon EKS cluster provides the only access to Amazon S3, while the Apheris Gateway agent initiates computations within the EKS cluster, maintaining data confinement within the Gateway. The NVIDIA FLARE™ connectivity layer manages communications between Gateways and the Orchestrator using remote procedure call (gRPC) over the transport layer security (TLS)-encrypted channels. Each Gateway runs an NVFLARE client, while the Orchestrator runs the NVFLARE server.
The workflow is based on the NVIDIA FLARE Scatter and Gather workflow. The central Orchestrator sends a training broadcast task to the participating sites, each operating an Apheris Gateway. The components of the Apheris Gateway in the client, that receives the broadcast and starts executing the computation, is referred to as the Client Executor. The central Orchestrator runs inside its own Amazon EKS cluster and stores the aggregated model parameters on its local storage.
A data scientist, or ML engineer, can use the Apheris command line interface (CLI) to start a training workflow on the central Orchestrator and, upon successful completion, download the persisted model parameters. The actual training iterations take place on the Gateway, where a Client Executor is created. This Client Executor initializes a model with the parameters received from the Orchestrator. After a predefined number of local training iterations, the model parameters, which are either full weight updates or low rank adapters, are sent back to the central Orchestrator for aggregation.
The following example uses the FRA-LoRA aggregation scheme, where full weight updates are first averaged across clients. After aggregation, the averaged weights are decomposed into two low-rank adapter matrices, which are then sent back to the clients for the next training round. The application of parameter efficient fine-tuning significantly reduced the number of parameters to two percent of the original number of parameters.
Performance analysis
Through the following experiments, you can evaluate the effectiveness of federated fine-tuning for ESM-2 by using a comprehensive dataset of 173,820 protein sequences, curated from UniProt and the Protein Data Bank. It was organized by protein families and trimmed to a maximum length of 1,000 amino acids as a context window for the pLM.
In the first experiment, create two independent and identically distributed (IID) datasets through random splitting. Train the model on 5,000 sample batches for each dataset and aggregate the model parameters after 30 communication rounds. Each communication round involves local training consisting of 5,000 steps, where training samples are drawn at random from the local data of each Gateway. This process occurs concurrently on both Gateways. Upon completion of local training, the Gateways send their model updates to the central Orchestrator, which aggregates them into a global update. The Orchestrator sends back this global update to the Gateways to initiate the next round of local training.
In the second experiment, test the approach under more challenging conditions by introducing an imbalanced label distribution between the two clients. Specifically, split the first client’s data with a ratio of 0.2 (label 0) to 0.8 (label 1), while the second client’s data with an inverse ratio of 0.8 (label 0) to 0.2 (label 1). This assesses the model’s robustness under non-uniform data distribution. In addition to the imbalanced distribution, add noise of the magnitude 1e-4 to the gradients to implement differential privacy. Run this experiment for 30 communication rounds to get a better impression of the long-term development of the training performance.
Results for balanced datasets (Experiment 1)
To compare the results with a centralized approach, train the model for 30 rounds on a centralized dataset, using a sample of 5,000 batches in each round. As seen in the resulting metrics (Figure 2), federated training of models outperforms centralized training by incorporating more diverse samples in each update step. Each training client processes 5,000 samples from its federated dataset to compute a local update, and the central server aggregates these local updates into a single global update.
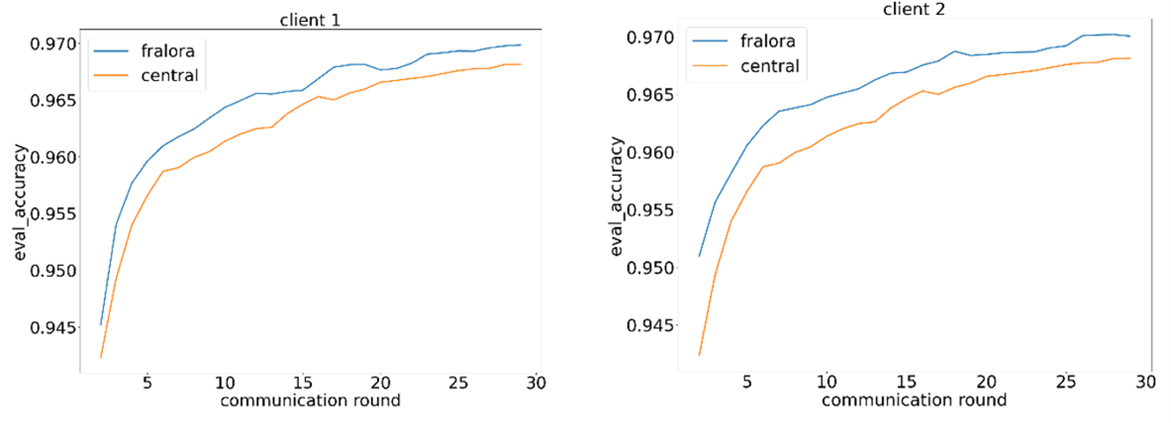
Figure 2: Comparison of model accuracy at each client for each iteration
Figure 3 demonstrates that the F1 score follows a similar trend, showing improvement as precision increases significantly. While fewer positive predictions reduce recall, the overall F1 score and prediction quality improve.
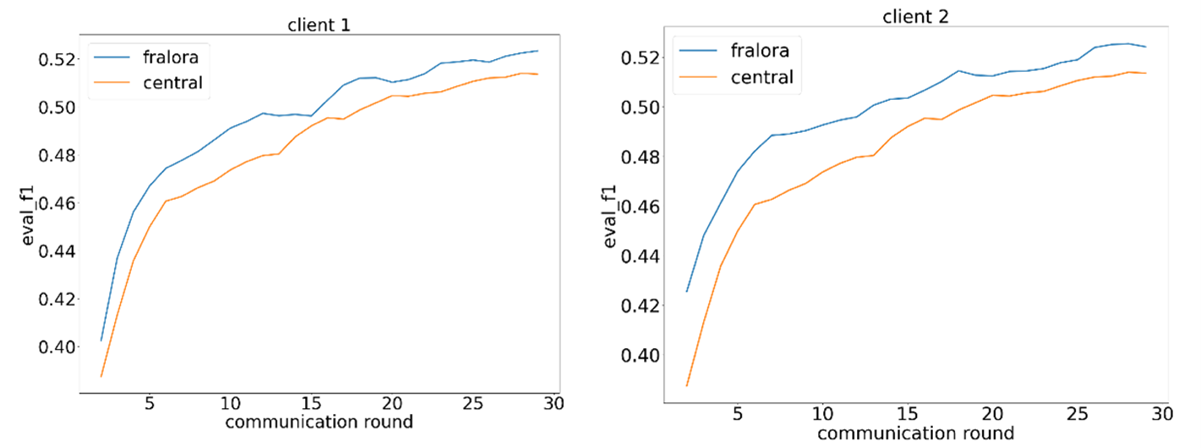
Figure 3: Comparison of F1 score at each client for each iteration
Figure 4 shows the inverse relationship between precision and recall. During fine-tuning, the model predicts fewer false-positive binding sites while slightly increasing the number of missed actual binding sites, thus improving its overall precision.
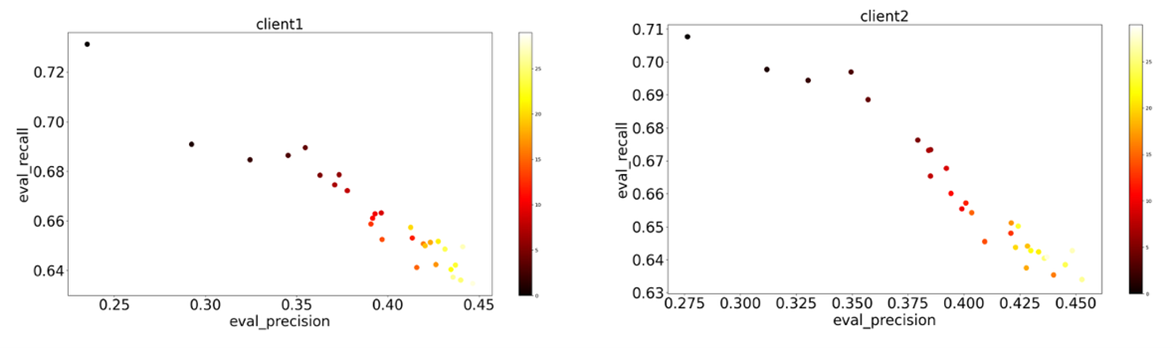 Figure 4: Progression of precision against recall
Figure 4: Progression of precision against recall
Results for imbalanced datasets with noise (Experiment 2)
As seen in Figures 5-7, the results of the second experiment are consistent with the observation from the first experiment. Neither the different label distribution nor the added noise significantly impacts performance. The accuracy (Figure 5) and F1 score (Figure 6) outperform the central model on both clients. This is due to the label distribution skew, which makes neither client similar to the central dataset.
On the other hand, since the model iterates through 5000 batches on each client, it ultimately achieves a better update compared to the central model, which only iterates through 5000 batches on the central dataset. The weights in centralized and federated training are still updated with the same learning rate. However, the federated updated direction is leading to a faster convergence than in the centralized approach, as a higher share of the training space is contributing to each update step.
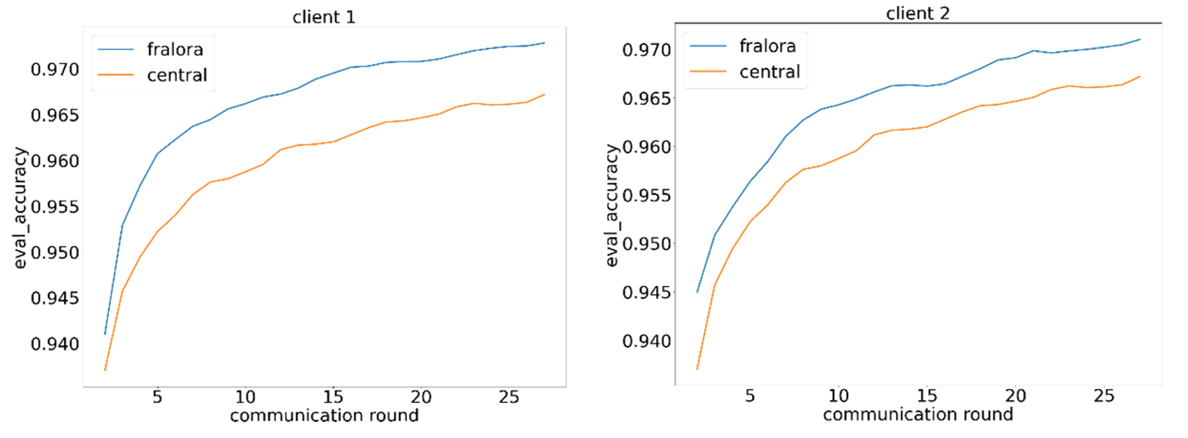
Figure 5: Comparison of model accuracy
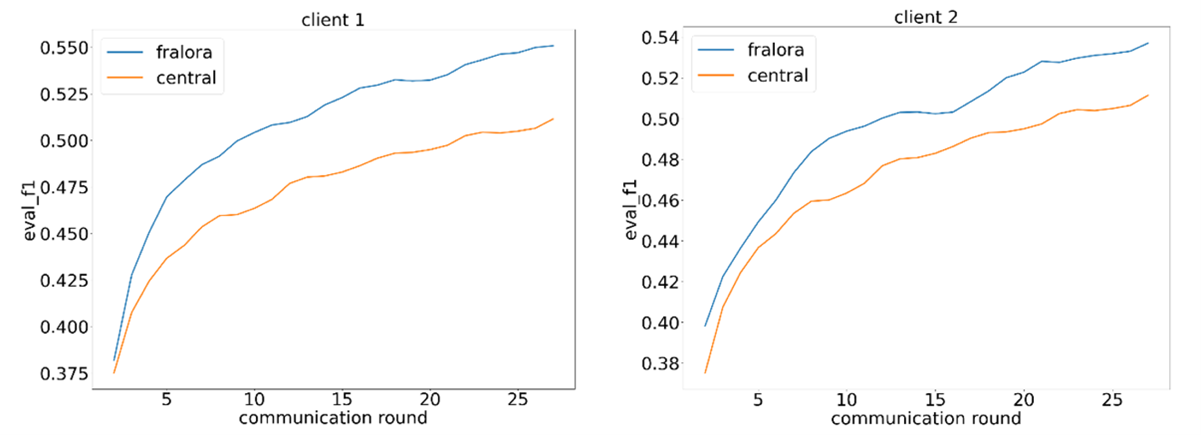
Figure 6: Comparison of F1 score
The progression of precision and recall (Figure 7) follows the same pattern as in the first example. The training behavior remains consistent despite unbalanced datasets and additional noise. This indicates that the federated approach demonstrates considerable robustness, even under less favorable conditions.
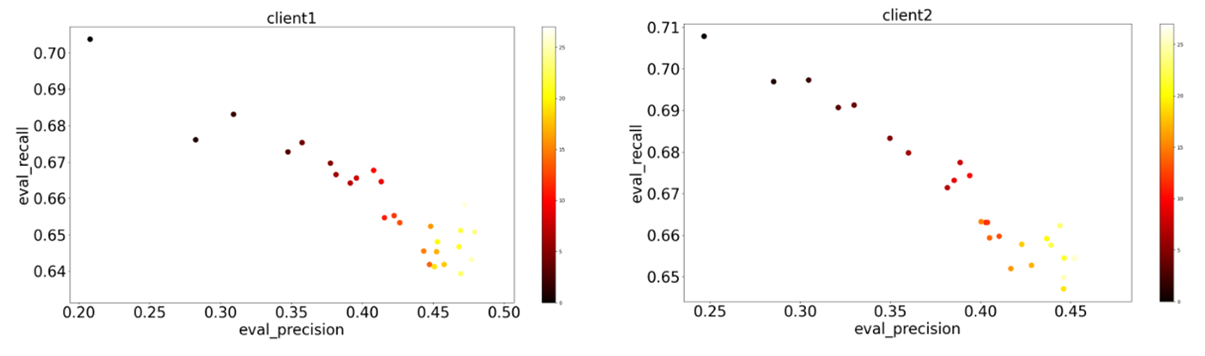
Figure 7: Progression of precision against recall over time for imbalanced datasets
Conclusion
We demonstrated how you can implement Apheris Gateway on AWS for federated fine-tuning of protein language models like ESM-2 for AI-driven drug discovery. The results show how LoRA’s parameter-efficient fine-tuning integrates with federated learning, improving training performance by leveraging joint updates. The approach achieves enhanced efficiency through parallel updates across multiple clients, accelerating the model’s overall convergence.
A particular advantage of implementing LoRA is the substantial reduction in trainable parameters—from 34,316,885 in the original ESM-2 model to just 553,922 (less than two percent) when applying LoRA on the target ‘query’, ‘key’, and ‘value’ modules. This compression reduces communication overhead and supports the inclusion of compute resource-limited participants in collaborative model training. This demonstrates the practical viability of the approach.
Apheris enables deployment of the setup on AWS for organizations looking to leverage new collaborations in regulated industries. The effectiveness of this method in maintaining model performance, while preserving data privacy and reducing computational overhead, has significant value in the Healthcare and Life Sciences industry.
For further details on adoption and usage, refer to the product page on AWS Marketplace. Or contact an AWS Representative to know how we can help accelerate your business.