AWS for Industries
From code to chemistry: using Kiro to tackle ADME-Tox, a key drug discovery challenge
We gave ourselves one month, two developers, one scientist, and one rule: no expanding the team when it got hard. Here is what we built, and why the constraints were the point.
Introduction
Building production-ready agentic AI solutions can present significant challenges from navigating complex architectures to establishing clear development patterns. The life sciences industry adds further complexity: strict regulations, diverse data modalities, and the variety of diseases all require additional time and specialized approaches. Opportunities across the biopharma value chain to accelerate molecular search, safety, synthesis, and eventual clinical comparison ultimately benefit patients.
In our first installment, we walked through how a small team used Kiro, an agentic AI-powered Integrated Development Environment (IDE) released by AWS, to go from a natural language specification to a working drug discovery agent in just three weeks. We covered how the Kiro spec-driven development model, Agent Hooks, and MCP server connectivity collapsed what would traditionally be months of architecture design and infrastructure setup into days of focused code iteration. The result was a production-ready target identification agent that synthesizes insights across 30+ fragmented biomedical data sources, identifies potential therapeutic targets with cited evidence, and provides traceable recommendations that scientists can validate and act upon.
At AWS, we focus on removing the undifferentiated heavy lifting so you can concentrate on what makes your science unique. Amazon Bio-Discovery launched in April 2026, is one such solution to accelerating drug discovery, specifically antibody therapeutics, by connecting generative AI models with physical, automated lab testing. Amazon Bio Discovery enables researchers to access 40+ AI biology models through a no-code interface to design, predict, and optimize drug candidates. But between a validated target and a clinical trial submission lies a critical evaluation step that eliminates approximately 90% of candidates (Sun et al): understanding how a molecule behaves in the human body. We set out to close that gap.
Enter: ADME-Tox
In biopharmaceutical discovery, promising hits emerge from screening workflows in monthly to quarterly campaigns. As efficacy, binding, and various phenotypic measurements are captured well-by-well, the next question is not “Is it active?” but rather “What’s the safety profile?” How will knowing about the physical and metabolic properties of the hit or lead influence its residence time in the body? Absorption, Distribution, Metabolism, Excretion, and Toxicity – collectively known as ADME-Tox – represent the gauntlet that eliminates approximately 90% of drug candidates before they ever reach a clinical trial (Sun et al).
In the clinical development phase of therapeutic testing, a candidate passes through Phase I (healthy volunteers), Phase II (small population of patients with disease indication), and Phase III (larger studies). Poor ADME-Tox profiles are among the leading causes of late-stage attrition: 30-45% of candidates fail in Phase II – III clinical trials due to emerging safety concerns (Sun et al). Without better preclinical risk models, pipeline triage, and pairing of observed ADME-Tox from Phase I into preclinical discussions, more R&D leads will be developed that ultimately fall out of the clinical pipeline, diverting time and money from potentially safer and more targeted patient therapeutics.
The standard battery of in vitro ADME-Tox assays (CYP, solubility, Caco-2, PAMPA, hERG, PPB) has only an estimated 50-70% predictive accuracy for human drug metabolism. How can we make sure the drugs we are considering making have a decent shot at passing preclinical testing with appropriate properties to perform in downstream clinical development? As general LLMs continue to evolve, we wanted to explore whether they are capable enough at reasoning and data analysis to suitably assess safety and toxicity risks of selected approved and known drug-like molecules.
Team and timeline
This is where our second drug discovery agent enters the picture. Building on the architectural patterns, Kiro spec conventions, the newly launched Kiro Autonomous Agent, and Amazon Bedrock integrations established in Part 1, we set out to answer a simple question: Could three people working part-time over the course of a single month, build a production-ready ADME-Tox prediction agent?
Our trio comprised two developers: a Principal Solutions Architect scientific solutions architect with a background in bioinformatics and a full-stack developer who had no prior experience with ADME modeling. A career scientist rounded out the group, serving as workflow validation, prompt tester, and data source recommender. We did this work in the in-between, between customer meetings, demos, trainings, and the general demands of our work weeks. Each contributor averaged 5 hours per week on this project across four weeks, approximately 60 combined hours in total.
That constraint was intentional. This blog series posits that the Kiro spec-first, agent-assisted development model is designed precisely for this reality: skilled developers with limited bandwidth who need to move fast without sacrificing production quality. Part 1 validated that thesis for a greenfield discovery workflow. Part 2 stress-tests against a domain that is simultaneously more scientifically complex and more operationally consequential.
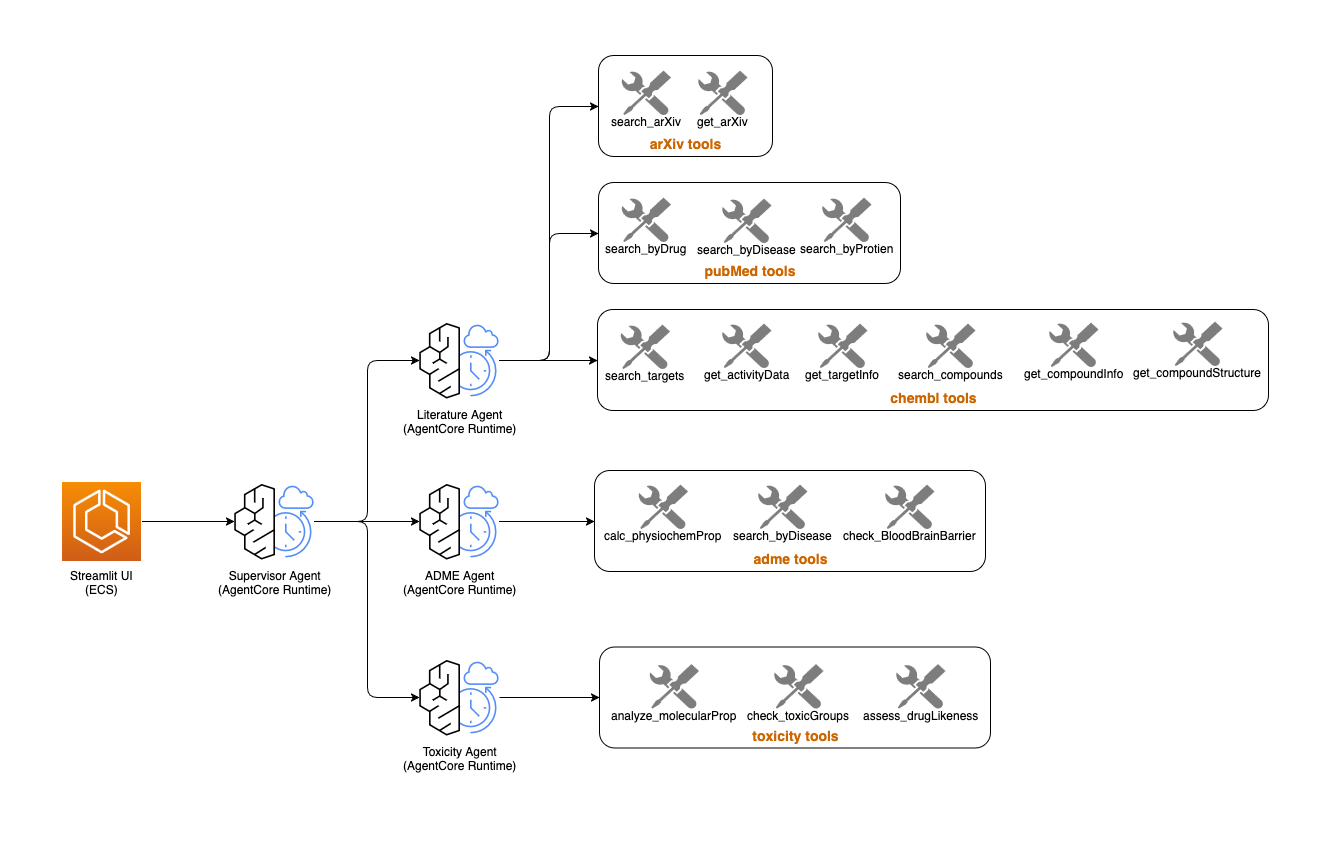
Figure 1: Draft architecture for the ADME-Tox Kiro solution. Multi-agentic frameworks, Kiro powers, and AgentCore primitives contribute.
Building from prompts and open-source data
We utilized Kiro in spec-driven design mode through a series of prompts, working between services and creating code and artifacts.
Step 1: Amazon Quick Research agent prompt
Step 2: Generate README.md for empty GitHub repository
Amazon Quick Report prompt

Figure 2: Amazon Quick UI, showing prompt and system architecture upon query
Step 3: Leverage Kiro Autonomous Agent
Kiro Autonomous Agent is a frontier agent that represents a new class of AI agents designed to autonomously handle software development work as an asynchronous teammate. Kiro Autonomous Agent can learn from the initial agents and tools built by developers in Kiro IDE and apply the same patterns and codebase to build additional agents and tools without requiring constant human guidance.
Our initial system spec utilized multiple open-source repositories, including APIs to ChEMBL, PubChem, the NIH ADME@NCATS library, RDKit, and multiple other libraries. Using Amazon Bedrock AgentCore Runtime, we set up a model based on our previously communicated biomarker agent, an architectural pattern that gathers data sources and uses supervisor agents to construct the end analysis.
Early results
Disclaimer: This agentic system accesses open-source data and algorithms; it does not constitute medical advice or recommendations. Results should always be reviewed by a human-in-the-loop, as would be expected in preclinical testing at a pharmaceutical company.
We first tested the system on two closely related structural analogs: a marketed Cox-2 pain reliever and a 4-isopropyl analog. Specific data points (MW, logP) align with ChEMBL and PubChem, others are calculated.
For the prompt:
The output, with the following performance logs:
The system delivered results in under 1 minute.
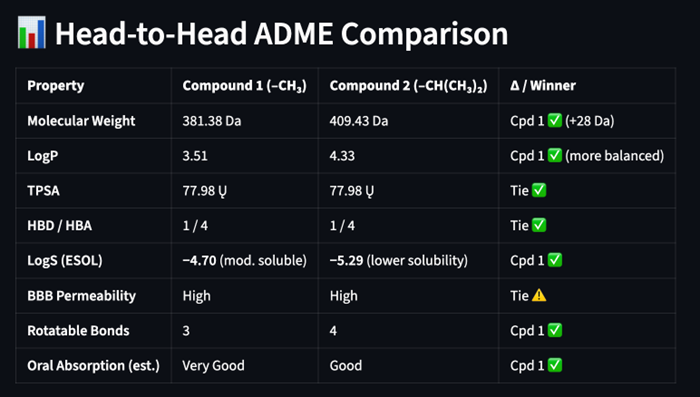
Figure 3: Head-to-head comparison of iPr analog against marketed drug for base ADME properties
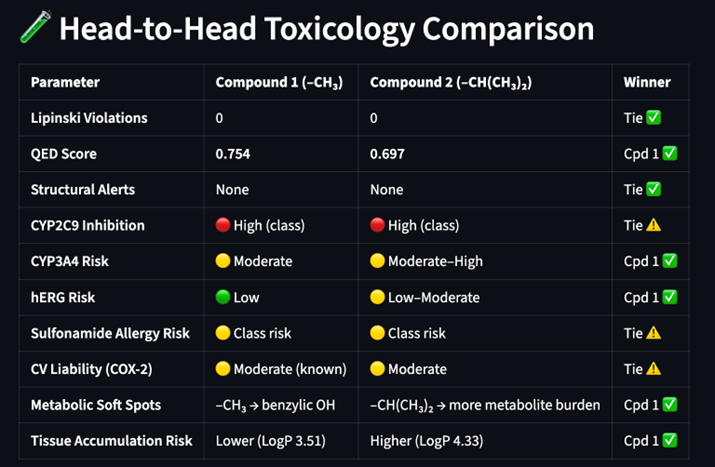
Figure 4: Comparing the head-to-head toxicology exports from ChEMBL, RDKit, PubChem using Anthropic Claude Sonnet 4.6 called through Amazon Bedrock AgentCore Amazon Bedrock AgentCore
As expected, the approved drug (Compound 1) shows a better overall ADME-Tox profile, with the CYP2C9 liability called out in both. The model reasons further, using known oxidation sites and logP to infer zero-shot reasoning and comparators. Of note, the system flags potentially harmful Cox-2 inhibitors, like Vioxx, that were removed from the market.
We then tested a different molecular class: two generic sulfonamide antibacterials.
Using the prompt:
The initial ADME comparison shows the molecules have similar chemical and physicochemical properties.
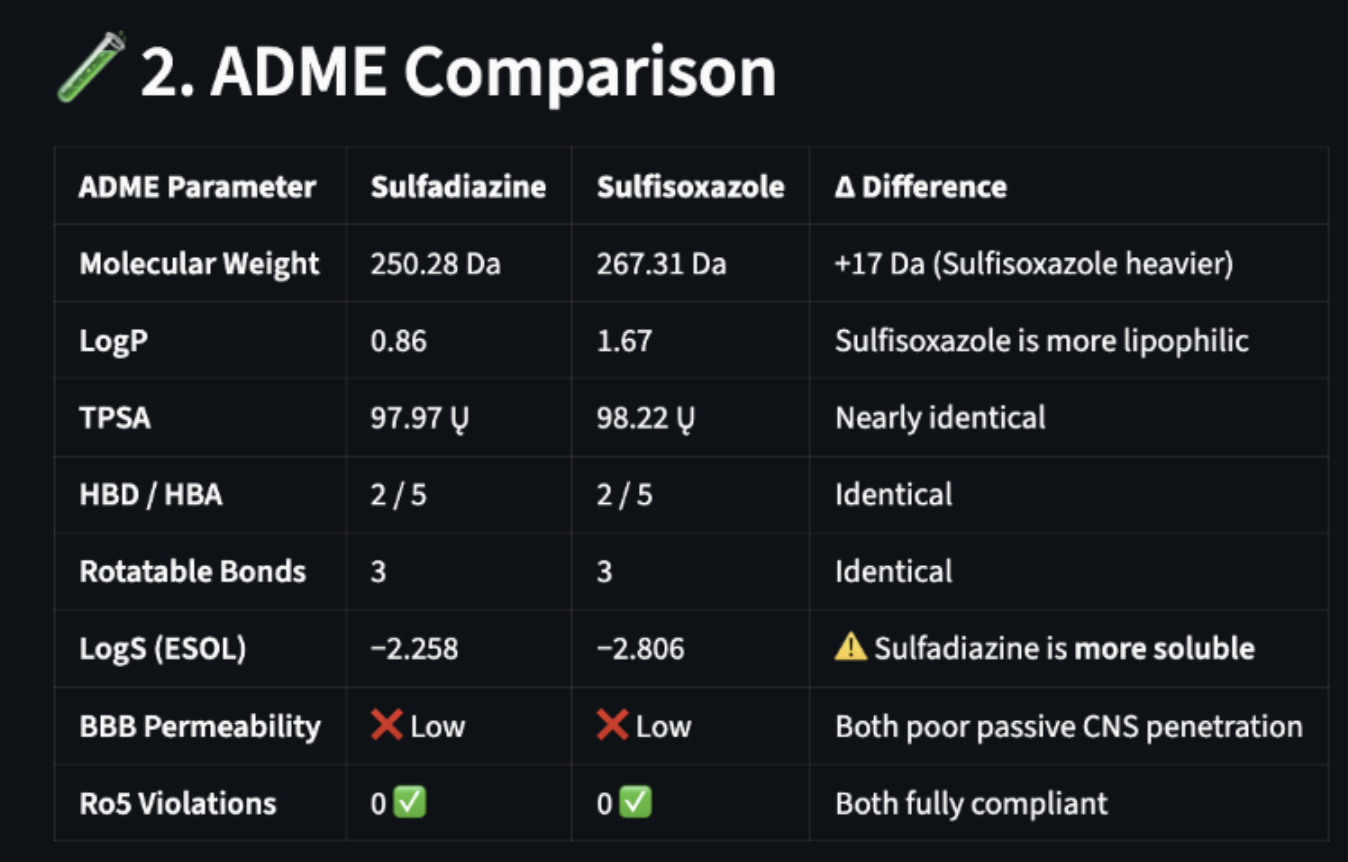
Figure 5: Computed ADME-Tox properties (RDKit)
However, in this example, multiple PubMed studies contraindicate one of the two molecules based on kidney injury (nephrotoxicity).
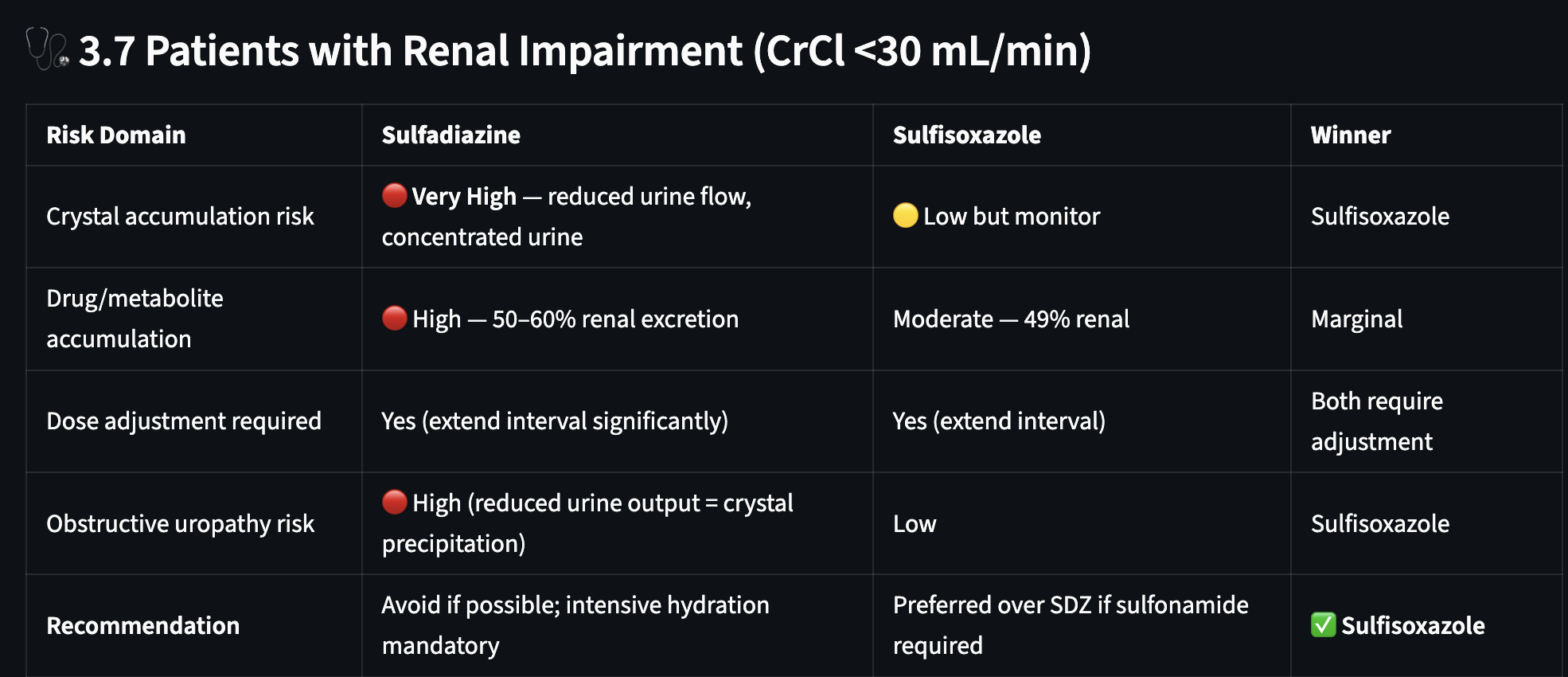
Figure 6: Comparison of sulfadiazine and sulfisoxazole for renal clearance using downstream clinical observations extracted from literature
The system reasons and provides a comparative risk profile, using its knowledge bases and Anthropic Claude Sonnet 4.6 and Anthropic Claude Sonnet 4.6 to predict a “winner” based on classification. This view is extensible in our testing to comparing 5 analogs of a specific lead (or 5 separate drugs for a given indication).
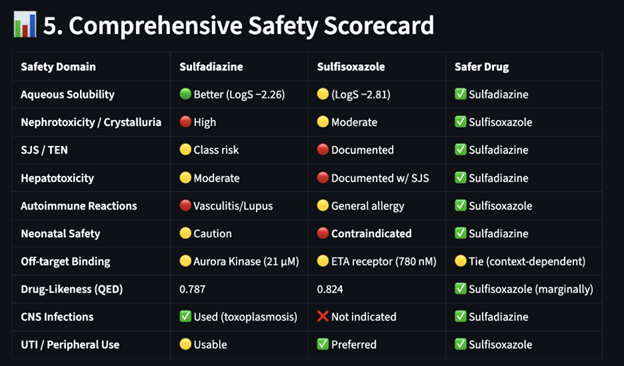 Figure 7: Comparative safety scorecard, given current source data sets (see above)
Figure 7: Comparative safety scorecard, given current source data sets (see above)
During testing with multiple other entities from common names, SMILES inputs, and trade names in live demos at the April 2026 AWS Life Sciences Symposium, the system returned results in 1–2 minutes and generally matched similar searches across public databases.
Potential future directions
The authors recognize the limitation of accessing open-source models and databases for this study. Ideally, future builds will incorporate fine-tuned multimodal foundation models and will use data sets captured from clinical or academic collaborators. Expanding the agents’ understanding of molecular (or biologic) design to, for example, iterate to improve ADME-Tox safety will be a future area.
We also recognize that a panoply of windows, modals, and systems may exist in a given research computing or R&D IT environment, and that our agentic system may be better served as an integration into another portal: an ELN, a LIMS, or a compound design motif, perhaps even into a safety prediction step of Amazon Bio Discovery.
Conclusion
ADME-Tox assessment informs research, preclinical, and clinical evaluation risk of lead molecules. We built this agent in approximately 60 hours, with two developers and one scientist. It works. Not perfectly, not to replace in vitro testing but well enough to complement early-stage decision-making during hit-to-lead and subsequent development. Surfacing actionable results for a bench scientist, project manager, or lab leader in minutes should be an attractive application of agentic systems for life sciences.
Kiro’s spec-driven development and use of autonomous agents allowed us to move from scientific requirements to working agents without losing the thread between what the science needed and what the code did. If you have suitable domain knowledge and access to a Kiro-like environment, you can use the steps and prompts described above to build in an even shorter time (sub-3 hours, per recent hackathon attempts!)
AWS has collected multiple agentic approaches to Research and Development-relevant situations, many of which are available in our Sample Agents for Healthcare and Life Sciences on AWS repository. These agents highlight how agentic AI can transform early-stage drug discovery by rapidly analyzing and synthesizing vast amounts of complex biological data and using it to understand the biological profile of the medicines in question.
To learn more about agentic systems and Kiro-driven scientific solutions on AWS, visit our Healthcare and Life Sciences page or reach out to your AWS Life Sciences representative.