AWS for Industries
From spec to production: a three-week drug discovery agent using Kiro
Introduction
Building production-ready agentic AI solutions can present significant challenges—from navigating complex architectures to establishing clear development patterns. The life sciences industry adds further complexity: strict regulations, diverse data modalities, and the variety of diseases all require additional time and specialized approaches. At AWS, we believe there’s a better path forward.
AWS continues to invest in AI tools that accelerate the time from agentic AI development to production and make it easier for scientists to harness the full power of AI regardless of their technical background. Since launching mid-2025, life sciences customers have turned to Kiro – the first AI coding tool built around specification driven (spec-driven) development – to accelerate use cases across the value chain, from R&D workflows like target identification and clinical trial design to commercial operations like 340B revenue protection, reducing development timelines from months to weeks.
AWS meets life sciences customers wherever they are on their AI journey. For developers, we offer sample agents for healthcare and life sciences on AWS. This toolkit helps developers quickly build agents for common workflows across drug research, clinical trials, and commercialization with a growing catalog of starter agents and supervisor agents that can complete multi-agent workflows. For organizations seeking production-ready solutions, we offer purpose-built accelerators that can be readily integrated and customized within existing environments. These accelerators are built for production scale and address foundational needs such as security best practices, network configuration, and architectural design, allowing customers to focus on what differentiates their business.
To demonstrate how customers can rapidly build similar solutions, our team built a production-ready target identification agent in just three weeks with three developers. This accelerator, now available through AWS, demonstrates that rapid agentic AI development is feasible and fast, even for complex domains using a spec-driven development approach with Kiro, an agentic AI coding environment, and AWS services like Amazon Bedrock AgentCore.
This blog shares our methodology, architecture decisions, and lessons learned to help you rapidly build your own agentic AI solutions for life sciences and beyond.
The Use Case: Target identification for drug discovery
Through close collaboration with leading pharmaceutical and biotechnology organizations, we identified critical workflow challenges facing early asset R&D scientists. Target identification requires synthesizing information across multiple data modalities — clinical trial results, genomic sequencing data, protein pathway databases, scientific literature (including PubMed, which alone adds approximately 1.5 million papers annually), and other sources—each with its own format, terminology, and access patterns. Researchers can only read a small fraction of this published knowledge, creating a significant bottleneck in the drug discovery pipeline that ultimately delays treatments reaching patients who need them.
Searching through all this data becomes a bottleneck in the drug discovery pipeline which ultimately delays treatments reaching patients who need them. Our life sciences customers are turning to agentic AI to eliminate this bottleneck, accelerating target identification from months to weeks and bringing treatments to patients faster.
For the TargetID in drug discovery agent, we defined clear success criteria: our agent needed to not only retrieve relevant information but also reason across data sources, identify patterns, and provide evidence-based recommendations that scientists could validate and act upon. This approach mirrors how Rackspace Technology used Kiro to transform their development process, completing 52 weeks of estimated work in just 3 weeks and achieving a 90% increase in efficiency by transitioning developers from coders into code architects and orchestrators. This customer-centric approach ensured we were building something genuinely useful, not just technically impressive. The goals are:
- Unify fragmented knowledge across multiple sources including PubMed scientific literature, ClinicalTrials.gov and other public repositories
- Maintain scientific rigor by providing cited summaries and traceable sources to preserve research integrity
- Democratize computational tools for bench scientists without requiring specialized data engineering skills
To develop a production-ready solution, we defined our best practices as:
- Build for production from the beginning: Implement observability for our agents and logging in Amazon CloudWatch from the get-go. Implement enterprise-grade security with AgentCore Identity for inbound and outbound authentication to ensure user is verified before invoking the agent, and agent has permission and necessary tokens before calling the tools.
- Enable effective knowledge sharing and best practices with advanced context management: Identify Model Context Protocol (MCP) servers (e.g., Strands) and steering files that provide advanced context to Kiro about our use case
- Maintain shared specification documents and team collaboration: Ensure Kiro has access to previous implementation details so that each feature is developed with a unified architecture and consistent design choices
Our Solution: Spec-Driven Development with Kiro
Why Spec-Driven Development?
The key to our rapid development was to adopt a spec-driven methodology. To understand our approach, it is important to distinguish between two common development methodologies. “Vibe coding” refers to the iterative, exploratory approach where developers write code directly based on intuition and immediate needs, refining through trial and error. While this can work for small prototypes, it becomes challenging to scale the solution and ensure the quality and consistency of the generated code. Spec-driven development, by contrast, separates planning from execution. In spec-driven design, you create detailed specifications before any code is written, providing clear requirements, architecture decisions, and implementation steps.
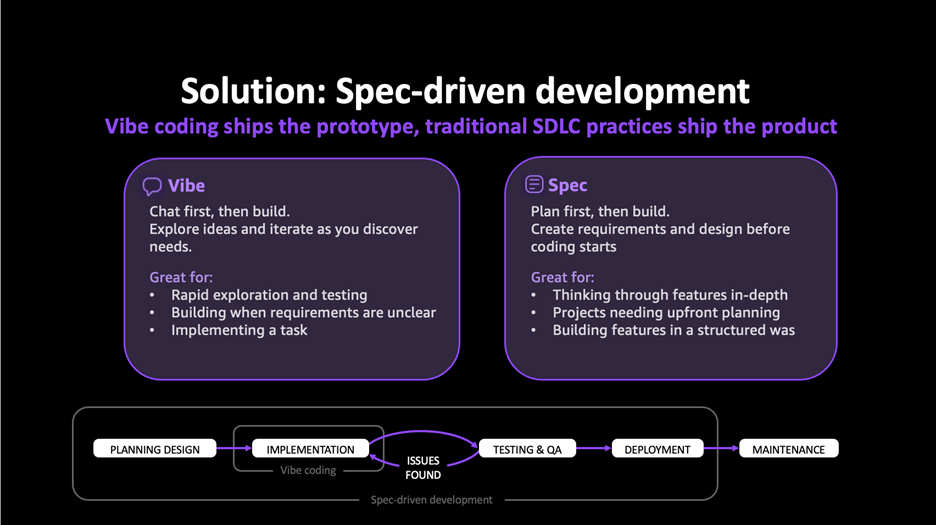 Figure 1: Difference between Vibe coding and Specification driven design.
Figure 1: Difference between Vibe coding and Specification driven design.
How Spec-Driven Development Works
Rather than jumping straight into coding, Kiro creates three foundational documents for each feature based on an initial prompt describing the feature (See Figure 2). The documents are created in order and then you are asked to review and give feedback before proceeding to the next step to ensure what is specified is what was intended.
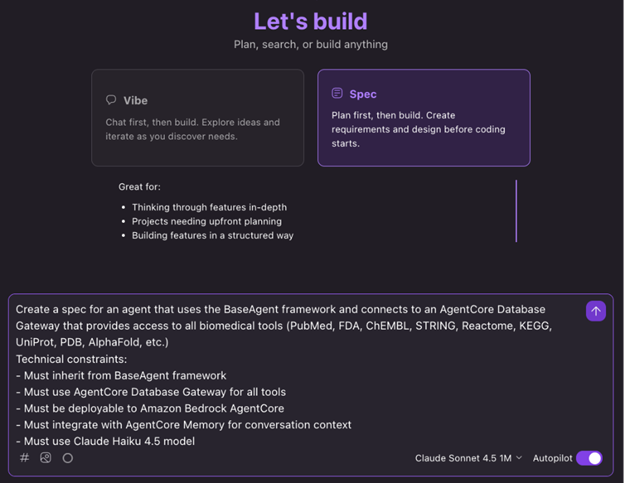 Figure 2: Example Initial Prompt to Kiro to build agent
Figure 2: Example Initial Prompt to Kiro to build agent
These files form the foundation of each specification:
1. requirements.md defines what we’re building, including feature requirements, acceptance criteria, and success metrics. This document captures the “why” and “what” in business terms that stakeholders can validate.
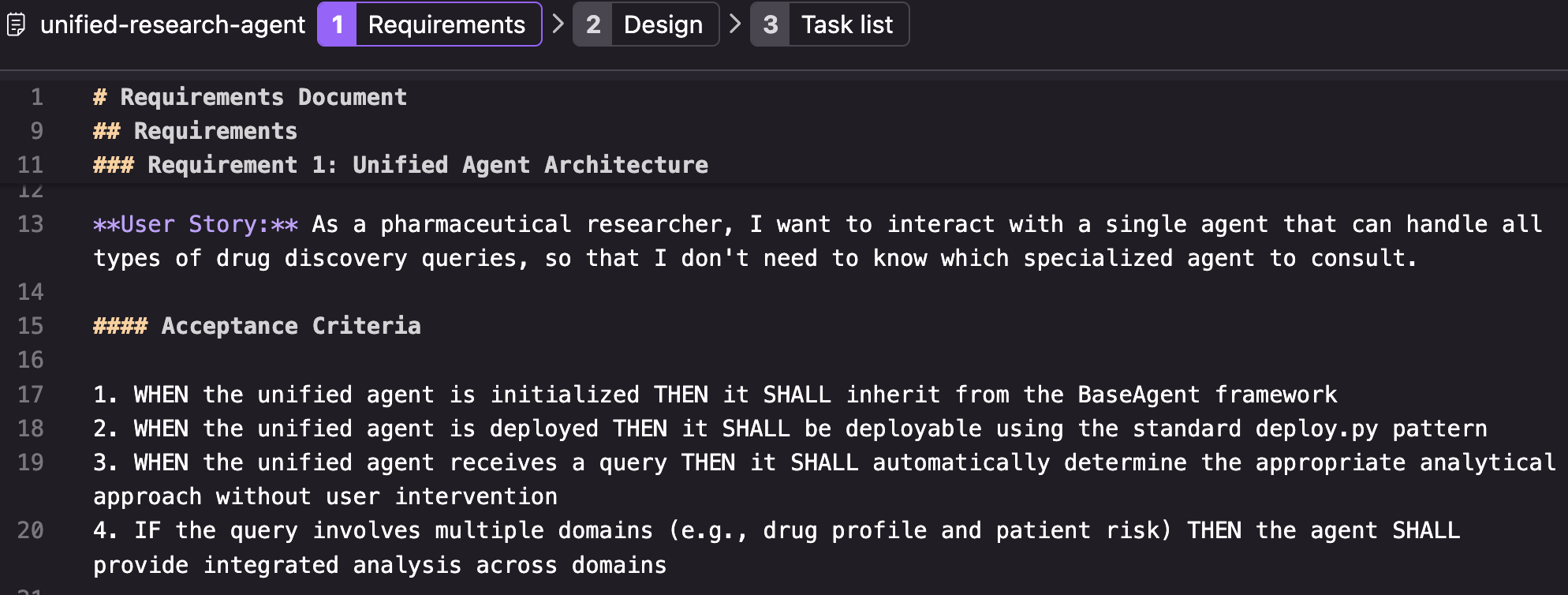
Figure 3: Example of requirements.md
2. design.md outlines the technical architecture, implementation approach, and integration points. This bridges business requirements with technical execution, documenting decisions about frameworks, APIs, and data flows.
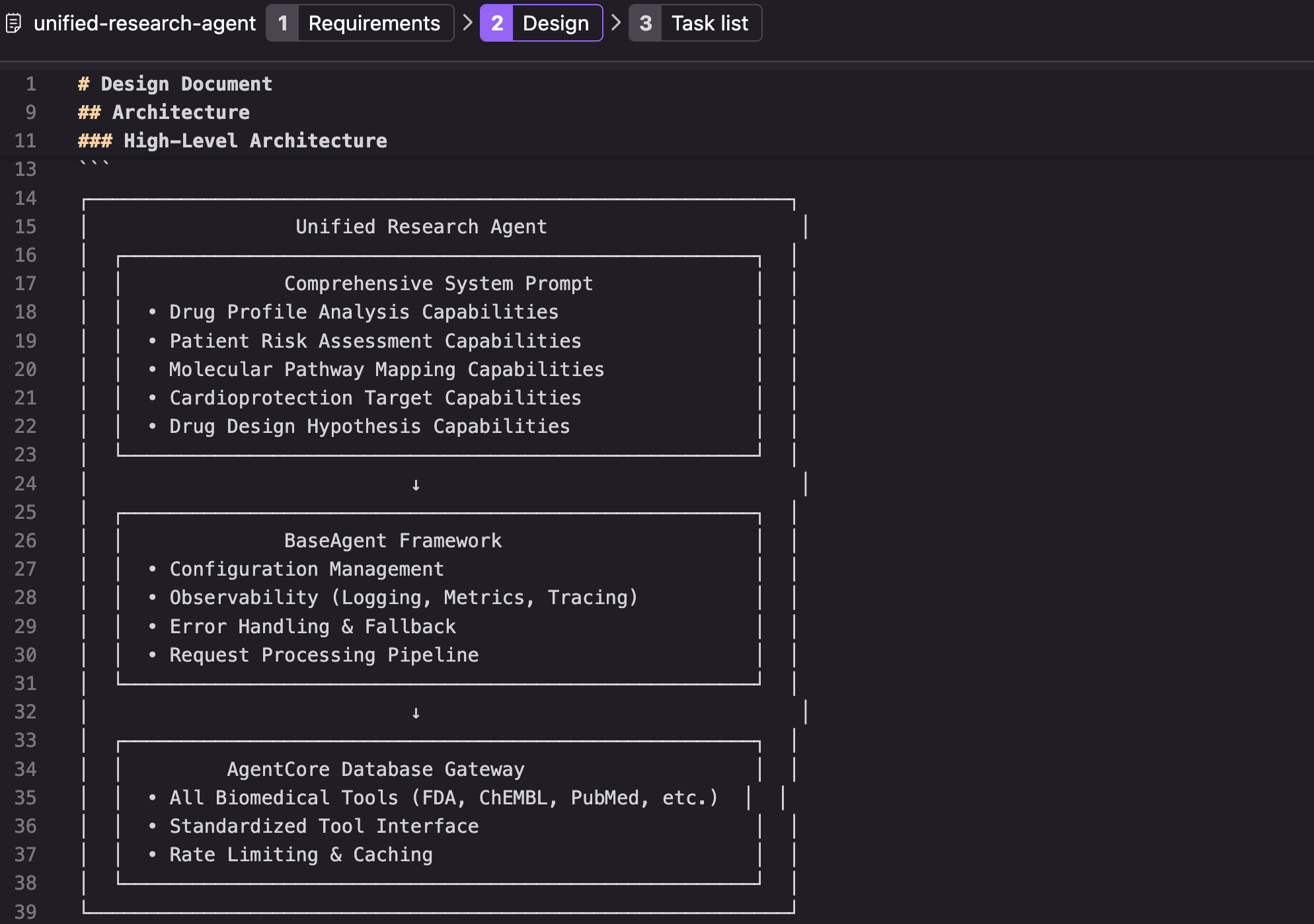
Figure 4: Example of design.md
3. tasks.md breaks down the design into specific, actionable implementation steps. Each task is granular enough for autonomous execution while maintaining context about the broader feature.
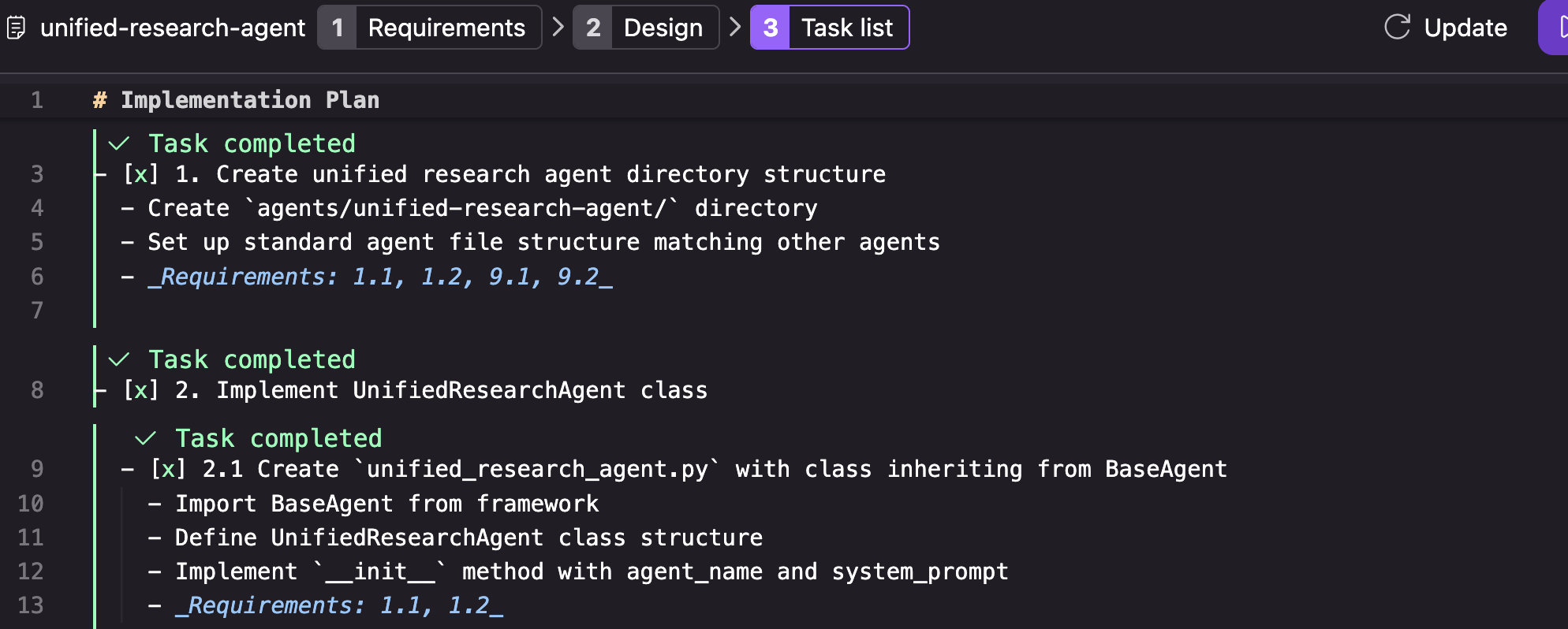
Figure 5: Example of tasks.md
This approach provides four critical advantages for your team.
- It creates context that enables Kiro to autonomously implement features while developers focus on review and validation.
- It makes onboarding new team members trivial—they can read the specs to understand both what was built and why or ask questions of the codebase.
- It enables you to tell Kiro to “develop a new feature based on the previous implementation with the same tech stack,” dramatically accelerating subsequent features.
- Most importantly, spec-driven development maintains human-in-the-loop oversight at the planning stage. We reviewed and refined Kiro’s interpretation of our prompts in the requirements, design, and tasks documents before execution began. If Kiro misunderstood the intent, we could easily correct it and let it revise—Kiro decouples planning from execution, preventing costly rework. Kiro can then use those updated intents as baseline for continued improvement. Our solution architects prompted Kiro and were required to review and guide to make sure Kiro’s interpretation of our prompts was accurate in its requirements, design, and tasks documents. If it was not, it is easy to correct Kiro, and have it revise before executing.
Using Kiro’s Agent Steering feature, we maintained consistent agentic AI behavior across our entire development project without repeatedly explaining conventions. We created three steering documents that guided Kiro’s suggestions: a ‘product’ document defining our project’s purpose and key capabilities, a ‘structure’ document enforcing organizational principles like tool abstraction patterns and error handling standards, and a ‘tech’ document specifying our technology stack and development guidelines. Steering documents differ from specification documents in scope: steering documents encapsulate context for your entire project, while specification documents can focus on specific features being developed. Each time you write a document, the steering documents are automatically added as additional context for Kiro to consider before generating code. For example, when building new features, the ‘structure’ document ensured agents were created in the correct directory structure, while the ‘tech’ document automatically guided class creation patterns for different agent types. This embedded knowledge allowed Kiro to provide contextually appropriate implementations and maintain our coding standards automatically, whether we were developing new features or refactoring existing code.
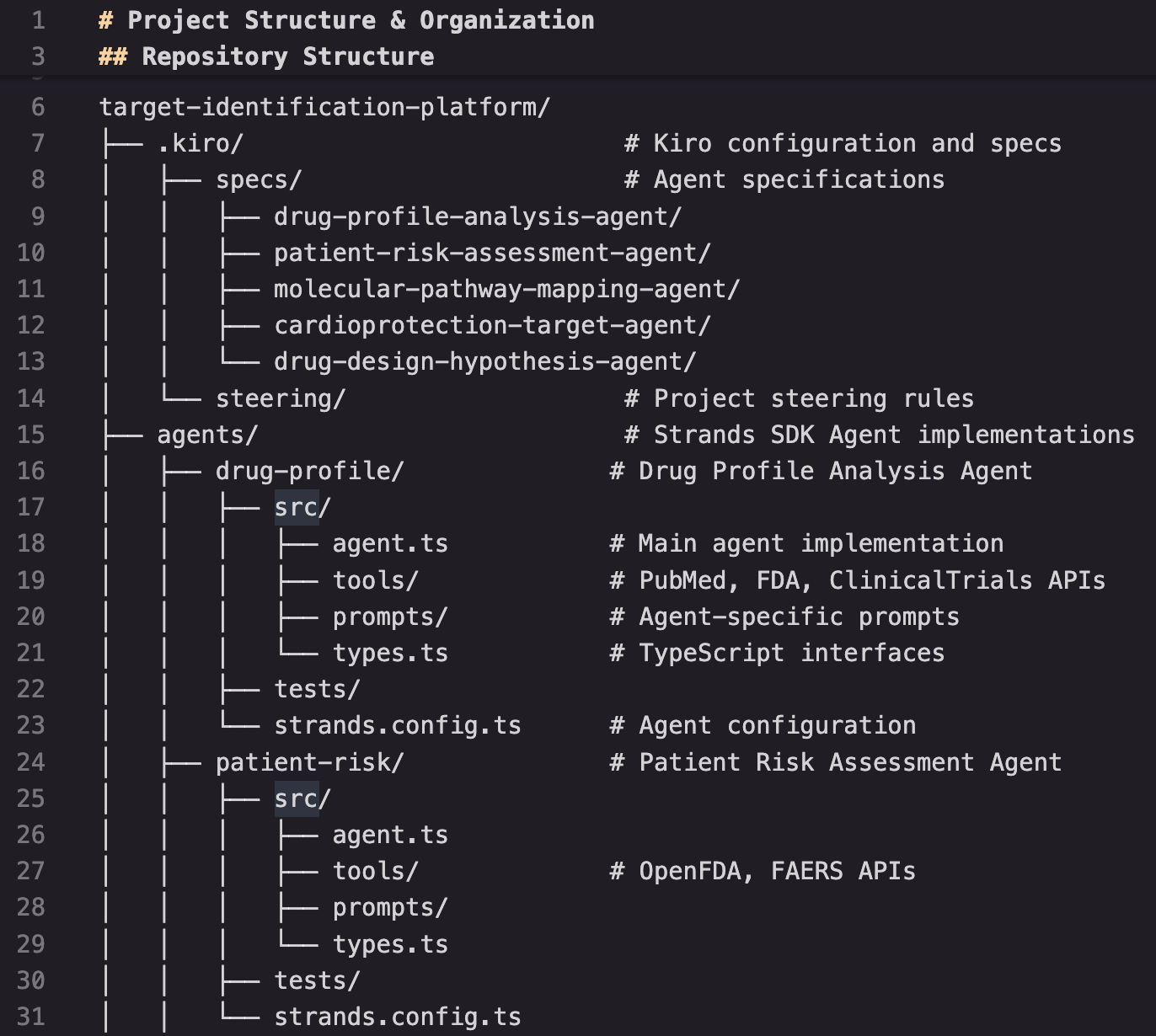
Figure 6: Example of structure.md

Figure 7: Example of tech.md
We used Kiro’s Agent Hooks to automatically update our README.md documentation whenever code changes occurred. Agent Hooks listen for file system events—like saves, creations, or deletions—and execute predefined AI prompts in the background. Instead of manually prompting Kiro to update documentation after each implementation, the hooks delegated this routine task to run automatically. This automation of repetitive tasks—updating documentation, generating unit tests, optimizing code performance, and maintaining coding standards—all happened automatically as we worked, allowing us to scale productivity by delegating routine tasks to agentic AI executing in the background based on predefined instructions. Since hooks are stored at the repository level, our entire team benefited from this automation immediately upon repository checkout.
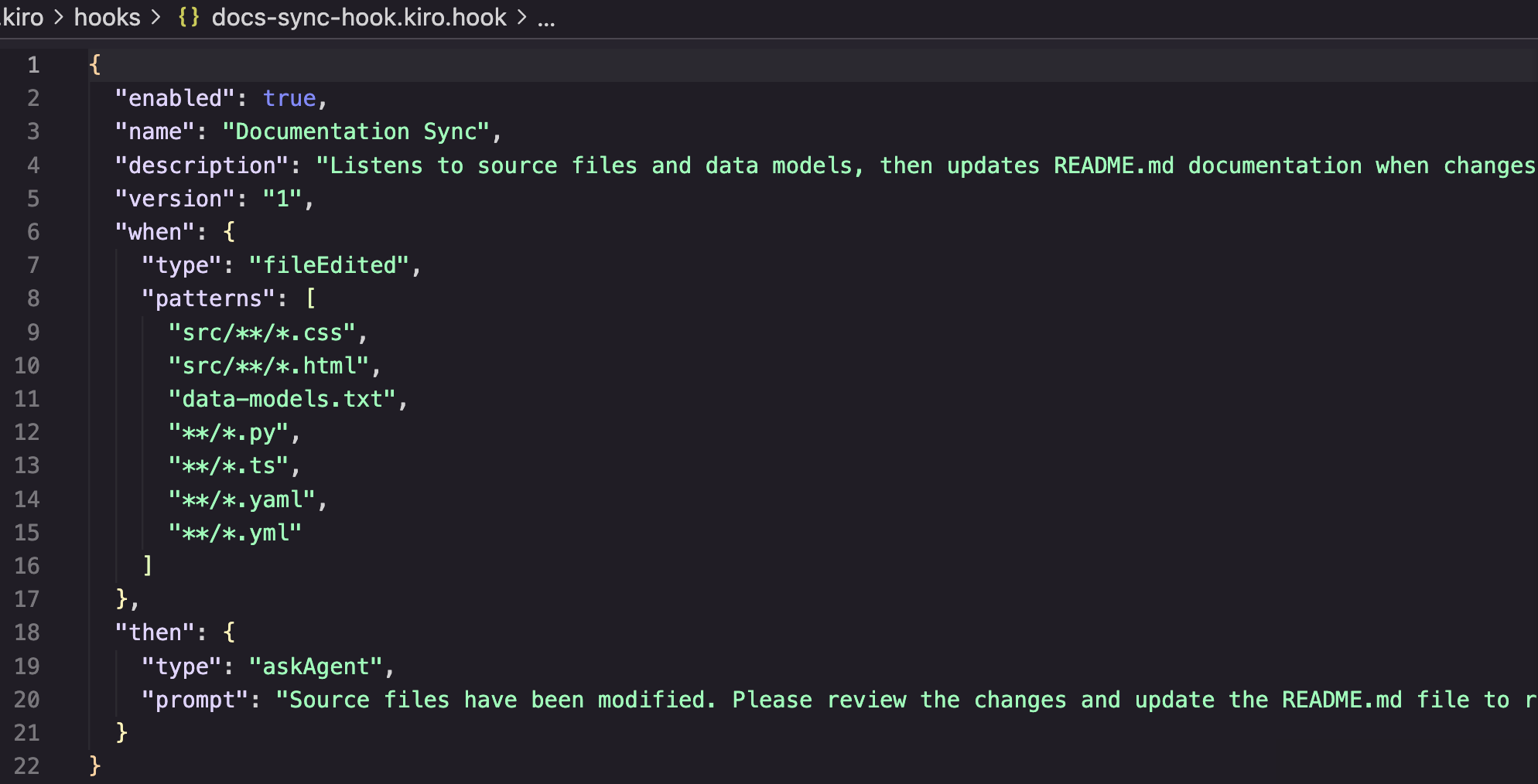
Figure 8: Example of Agent Hook
Thus, the spec-driven approach in Kiro shifted our development from being about authoring each line of code to guiding and delegating tasks to the AI agent to complete with human oversight.
Architecture Overview
Our architecture leverages a single unified agent built with AWS services, following a serverless pattern that maximizes scalability and minimizes operational overhead. It simplified deployment and maintenance while still providing comprehensive target identification capabilities. The agent orchestrates its various tools and data sources intelligently based on the query context, determining which capabilities to invoke and how to synthesize results into coherent responses.
How It Works: When a scientist asks about potential targets for a specific disease, the unified agent intelligently determines which tools to invoke based on query context. For example, it might first search PubMed literature for recent research, cross-reference findings with clinical trial outcomes, analyze protein pathways to identify interaction networks, and check adverse event databases for safety signals—all orchestrated seamlessly through a single conversational interface.
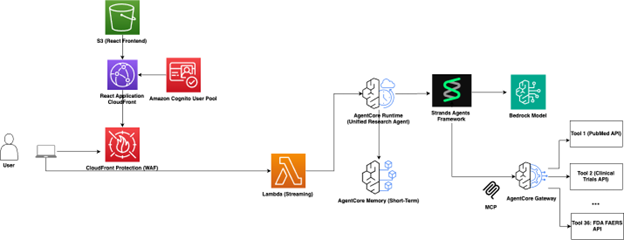
Figure 9: Architecture of the TargetID agent
Core Components:
- Amazon Bedrock AgentCore: Provides the foundation for agent orchestration and reasoning
- Strands Agents SDK: Enables rapid agent development with pre-built patterns
- AWS Lambda: Executes tool functions for data retrieval and analysis
- Amazon Simple Storage Service (Amazon S3): Stores intermediate results and maintains conversation context
- Amazon CloudWatch: Provides comprehensive observability and monitoring
Integration Points:
- Public APIs: Integrated with 30+ APIs including UniProt for protein data, PubMed for literature search, and ClinicalTrials.gov
- MCP Servers: use for data sources where available
- Internal data sources: Proprietary research databases and experimental results
- Specialized models: Biology-specific language models for domain reasoning
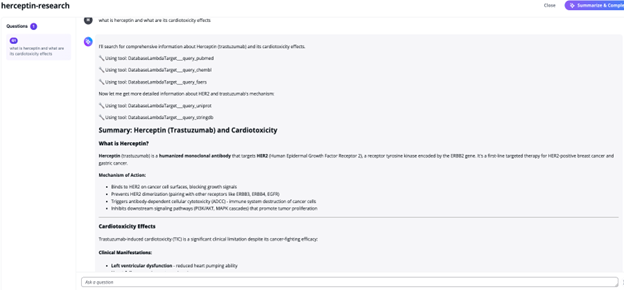
Figure 10: Screen shot of TargetID agent application
Kiro accelerated our ability to build out this serverless architecture—seamlessly connecting Bedrock AgentCore, Strands SDK, Lambda functions, and 30+ external APIs into a unified, production-grade solution.
The Power of Small, Focused Teams
The spec-driven approach made it possible for just three solution architects to build a working system in three weeks while juggling meetings, workshops, and other priorities. By investing time upfront in comprehensive specifications, we minimized back-and-forth during implementation. Kiro handled the repetitive coding tasks while developers focused on high-value activities: architecture decisions, integration design, and validation.
Here is a breakdown of the 3 weeks timeline:
- Day 1-3: Requirements gathering and stakeholder alignment on features
- Day 4-6: Technical design and architecture decisions
- Day 7-14: Creating Kiro Specs. Implementation in Kiro of the full-stack webapp including the Target ID Agent
- Day 14-21: Testing and gathering feedback. Iterated on prompt engineering and other feature requests, with Kiro’s help
With this approach, we found the following benefits:
- Kiro generated more than 95% of the business logic code, saving over 80 hours development time
- README documentation written by Kiro saved us an estimated 8 hours, both doc writing process itself as well as communicating these details with new team members
- All team members following the same coding standards and frameworks with the help of steering documents
Despite being a new tool for our team, Kiro delivered immediate value through its intuitive prompt-based interface—enabling us to start without a steep learning curve. The platform’s efficiency translated into significant time and resource savings as quantified above, allowing our team to focus on other priorities in parallel. Most importantly, Kiro dramatically accelerates time-to-value: teams can realistically build and deploy a simple agent with API integrations in just one day.
Moreover, by documenting our standards in Kiro’s steering docs, we ensured consistent code quality without manual enforcement. Agent hooks automated repetitive tasks like updating documentation when code changed, further reducing manual overhead. Working with Kiro still allowed us to have:
- Clear Role Distribution: the responsibilities were divided, so each SA was able to work independently focused on their set of tools and integration.
- Collaboration: each SA iterated on their personal piece using Kiro’s spec driven abilities to keep it coherent and unified.
- Production readiness and security compliance: we have Kiro guidance to build on par with our team’s standards
With development best practices and AI-assisted coding, our team was able to accomplish our goals within a short timeframe.
5 Key Takeaways
1. Invest in Specifications Upfront—It Pays Off Fast
Define clear acceptance criteria with stakeholders before writing any code. Using structured documentation through Requirements.md, Design.md, and Tasks.md creates effective guardrails and provides comprehensive context for both human developers and AI assistants. The clear separation between planning and execution phases improves workflow efficiency and prevents costly rework downstream.
2. Start with Comprehensive Steering Documents
Create steering documents that capture your architecture decisions, coding standards, and integration patterns. Front-loading these requirements and design decisions saves iteration time and establishes patterns that can be reused for subsequent features. These documents serve as both a guide for development and a reference for validation throughout the project.
3. Connect to MCP Knowledge Sources
Leverage MCP servers for relevant documentation to improve code generation accuracy. Connect to AWS MCP servers and other relevant knowledge sources during development—they prove invaluable for maintaining consistency with best practices and generating production-quality code. The right knowledge connections make your AI assistant significantly more effective.
4. Trust Your Data—Label Everything Else
In life sciences, stakeholders need confidence that insights come from real biological data and the appropriate data sources. While AI coding agents can generate mock or simulated data for development purposes, it is critical that all implementation uses actual API endpoints with real data—nothing in the production system should be simulated. If you need test data during development, explicitly mark it in both the data itself and any outputs generated from it. If not and the test data is too accurate and not labeled, it becomes difficult to identify if this is the mock data or an actual proper response. This transparency builds trust and prevents incorrect assumptions about your agent’s capabilities.
5. Build Observability from Day One
Implement comprehensive observability and monitoring from the beginning so you can understand agent behavior in production. Amazon Bedrock AgentCore provides built-in observability, monitoring, guardrails, and security controls. Security is paramount in production agent deployments. We implemented comprehensive authentication using Amazon Cognito for both user access and machine-to-machine communication between agents and tools. IAM role-based permissions control agent execution and Bedrock model access, while AgentCore Gateway tools are secured through OAuth 2.0 JWT tokens with scoped authorization, ensuring robust security across all system boundaries. Consider using AgentCore Evaluations for continuous quality monitoring through built-in and custom evaluators, and AgentCore Policy for deterministic authorization enforcement with full CloudWatch logging for audit compliance. Plan for continuous evaluation and improvement—your first version won’t be perfect, but it should be measurable.
Future Direction
Develop with Kiro Powers
Kiro Powers are specialized expertise modules that dynamically load context and tools on-demand, solving the context overload problem of traditional MCP servers. Instead of loading all MCP servers upfront and consuming large amounts of context, Powers activate only when relevant to the current task. They bundle MCP tools, steering files (best practice documents), and automation hooks together with built-in best practices from domain experts. For example, the Amazon Bedrock AgentCore Power provides instant expertise for building production-ready AI agents – when you mention “agent deployment and authentication,” it automatically loads relevant tools and knowledge to keep your AI assistant focused. By using the ‘Build an agent with Amazon Bedrock AgentCore‘ Power, we can speed up overall development time through:
- One-click installation rather than complex MCP configuration
- Enabling all developers to deploy agents regardless of their previous knowledge of Amazon Bedrock AgentCore
Leverage Kiro Autonomous Agent for building additional agents and tools
Kiro Autonomous Agent is a frontier agent that represents a new class of AI agents designed to autonomously handle software development work as an asynchronous teammate.
Kiro Autonomous Agent can learn from the initial agents and tools built by developers in Kiro IDE and apply the same patterns and codebase to build additional agents and tools without requiring constant human guidance. For example, Kiro Autonomous Agent can build a Patient Risk Assessment agent using the existing Target ID agent following the same pattern and codebase.
Conclusion
Building a production-ready drug discovery target identification agent in three weeks demonstrates that rapid agentic AI development is not just possible—it’s practical with the right methodology and tools. This implementation successfully achieved all success criteria defined in the use case section: the TargetID agent effectively synthesizes insights across fragmented biomedical data sources, identifies potential therapeutic targets, and provides evidence-based recommendations for drug discovery research.
The combination of spec-driven development, multi-agent collaboration, and AWS services like Bedrock AgentCore and Strands SDK enables small teams to deliver sophisticated AI solutions quickly. This approach not only accelerates the development lifecycle but also ensures consistency in design patterns, security practices, and code quality across multiple agents
The broader vision extends beyond this single use case. By establishing patterns for rapid agent development, we’re creating an accelerator that life sciences organizations can use to innovate faster, bringing treatments to patients more quickly. The decades-long timelines and billions of dollars traditionally required for drug discovery create real human costs—every month saved in the development pipeline potentially means lives saved.
Try this approach for your own agentic AI projects! Start with clear customer needs, invest in comprehensive specifications, leverage multi-agent architectures where appropriate, and don’t compromise production-readiness. As healthcare organizations continue to explore AI-driven solutions, the combination of Amazon Bedrock‘s robust foundation models and Kiro Autonomous Agent’s autonomous development capabilities provides a scalable, reliable pathway for building sophisticated healthcare AI applications that can adapt and grow with evolving clinical requirements. The toolkit and methodology we’ve developed can accelerate your journey from concept to production.
Additional Resources
- Life Sciences Agents in Production: Early Research
- Kiro
- Learn more about Kiro Specs
- Amazon Bedrock AgentCore Documentation
- Strands Agents SDK on GitHub
- Sample Agents for Healthcare and Life Sciences on AWS
- Accelerating genomics variant interpretation with AWS HealthOmics and Amazon Bedrock AgentCore
- Build a biomedical research agent with Biomni tools and Amazon Bedrock AgentCore Gateway