AWS for Industries
How We Built Healthcare AI You Can Trust: The Science Behind Amazon Connect Health
Introduction
Healthcare providers today spend hours on documentation, coding, and administrative tasks that pull them away from patient care. AI is being adopted in healthcare to help reduce administrative burden, improve patient care management, and increase workflow efficiency. Yet, the central concern for healthcare leaders remains: which AI can be trusted in healthcare workflows? At AWS, we partner with clinicians, train models on large scale real world de-identified medical data, and evaluate purpose-built agents against clinical workflows, safety requirements, and accuracy thresholds that healthcare demands.
In March 2026, we launched Amazon Connect Health, an agentic solution for healthcare. Amazon Connect Health drafts clinical notes and corresponding medical codes by combining Automatic Speech Recognition (ASR) with task-specific fine-tuning trained on historical documentations and coding decisions, freeing them to focus on patient care instead of administrative tasks. Patient engagement agents in Amazon Connect Health let patients complete tasks such as appointment scheduling and insurance verification instantly through a voice agent, while connecting to live support for complex requests when needed.
In this blog, you will gain detailed insight into the scientific rigor behind Amazon Connect Health, including our training methods (supervised fine-tuning, reinforcement learning, multi-agent collaboration), how we validate against real-world data (automated and manual evaluation, LLM agentic environments), and the evidence mapping and source tracing we provide for every output to reinforce safety and trust.
Amazon Connect Health
Amazon Connect Health provides three purpose-built point of care capabilities designed to transform administrative workflows: pre-visit patient insights, during-visit ambient documentation, and post-visit medical coding, and two patient facing capabilities handling patient authentication and appointment management.
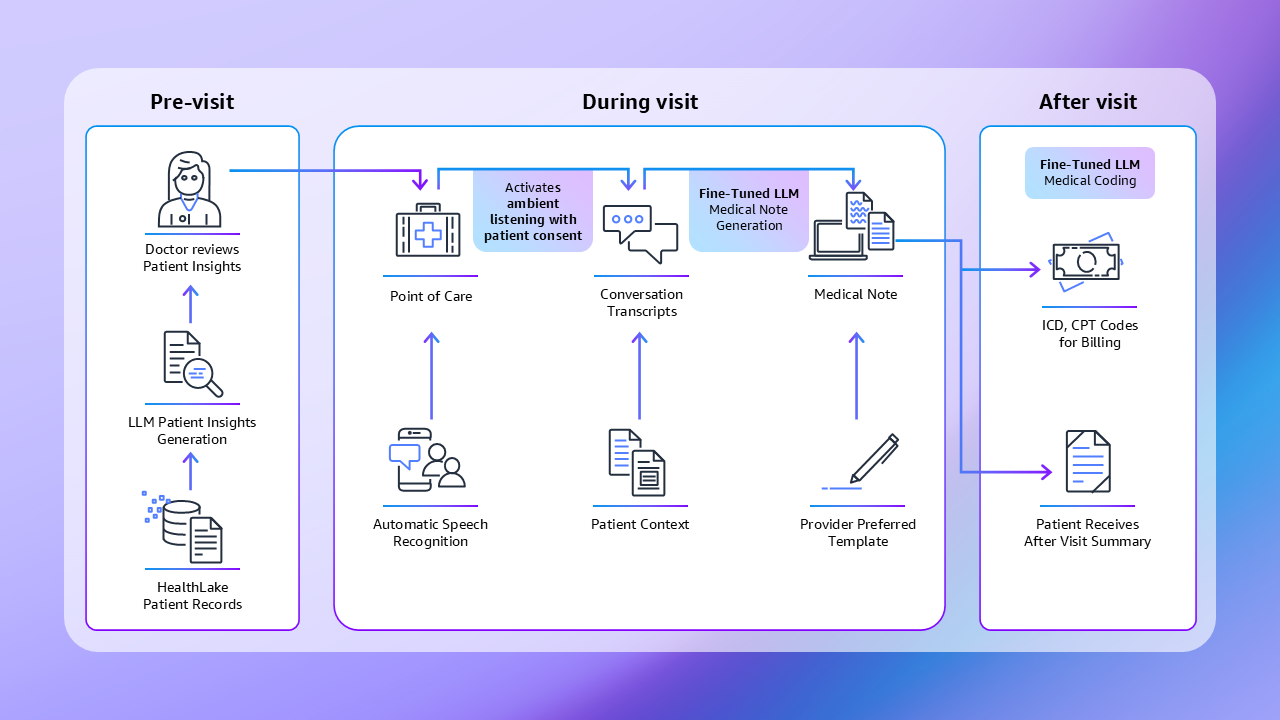
Figure 1. Amazon Connect Health point of care workflows
Pre-visit Patient Insights: Multi-Step Reasoning with Structured Validation
Providers face an overwhelming volume of fragmented patient records with limited time to identify what matters most for the upcoming visit. Patient insights in Amazon Connect Health helps providers review relevant patient conditions before a visit. We summarize the patient’s longitudinal medical history into structured sections covering Patient and Encounter Overview, Since Last Visit Events, Active Conditions, Trends over Time, and Condition Review for Hierarchical Condition Categories (HCC). Patient records can be added to an S3 bucket or FHIR data store like AWS HealthLake to update the insights.
While it is straightforward to use an LLM to summarize a patient’s longitudinal history, generic LLM summarization faced three key challenges:
- Generating duplicate content caused by varied data formats (e.g., structured and unstructured data in PDFs, text, images) and the repetitive nature of patient EHR data.
- Overemphasis on baseline conditions while de-prioritizing action items, recommendations, and recent changes.
- Creating verbose summaries with weak relevance to the upcoming visit and insufficient structure to cover required clinical aspects.
To overcome these challenges, we work with clinical specialists to develop pre-visit summarization templates for various visit types. We built a multi-step, self-critiquing agentic pipeline that processes documents via PDF optical character recognition (OCR), then extracts and deduplicates medical facts across different categories (e.g., care gaps, chronic/active conditions, and trends). Our system self-critiques the output for patient profile accuracy and clinical relevancy, conducts evidence linkage against the raw records, and generates the overall pre-visit summary. This extraction, self-critiquing, and reconstruction process help verify that each sentence in the summary follows visit-type-specific clinical guidelines and minimizes hallucinations. We developed a customized LLM-as-a-Judge evaluation system to compare medical facts between patient records and the generated patient insights following medical ontology structures. Tested with real patient data, our system achieves 99%+ summary sentences backed by source records accurately.
Ambient Medical Documentation: Real-Time Speech Recognition with Multi-Objective Learning
Ambient medical documentation uses ASR to capture patient-provider conversations and generate clinical notes during the visit. Producing high-quality medical notes requires balancing conciseness with completeness, supporting customizable templates for clinician preferences, maintaining low latency, and verifying that notes are billable, with comprehensive patient context reflected in the Assessment and Plan section.
To address these challenges, we developed proprietary evaluation metrics including medical completeness, factuality, note length penalty, A/B testing manual preference voting, section alignment, template layout matching, patient context matching, instruction following, note format validation, and LLM-as-a-Judge style and quality rubrics — confirming that our models are strongly optimized for capturing medical facts and clinician preferences.
We fine-tuned a lightweight LLM on high-quality, manually annotated medical notes to reflect the above requirements and built an automated evaluation pipeline to track all metrics. A key focus of the Supervised Fine-Tuning (SFT) was the Assessment and Plan section. This section drives future treatment decisions and billing, and must be grounded in relevant patient history to justify the provider’s clinical reasoning. To strengthen this section, we combined relevant patient context and history with visit transcripts as training input. For note customization, we support both template customization (e.g., different sections and styles) and Smart Phrase replacement (e.g., filling in a fixed set of questions or phrases) by mapping the generated note to the new template hierarchy. We also generate the patient-facing after-visit summary as a separate section alongside the medical note using the same training pipeline, maintaining documentation coherence.
We had two key learnings while developing ambient documentation in Amazon Connect Health: 1) The domain fine-tuned smaller LLM outperforms larger foundation models using in-context learning by a large margin. Comparing a smaller SFT model against a larger out-of-box model, the SFT model – trained on proprietary clinical note datasets – achieves: 2.2x faster generation, 50% reduction in documentation adherence issues, 180x reduction in cost, and 35% shorter notes while preserving clinical completeness, 2) Adding multi-stage reinforcement learning to SFT enables even small language models to exceed supervised fine-tuned LLM. We tested a small language model (<10b) as the base model using a chained SFT and Group Relative Policy Optimization (GRPO) Reinforcement Learning Fine-Tuning (RLFT) pipeline. A single RL step combining all reward functions did not beat the SFT model. However, separating rewards into sequential RL stages – each optimizing for one objective – outperformed the SFT only model on automatic metrics, minimized reward hacking, and achieved equivalent or higher manual preference scores. This gives us more model choices and helps make our product adaptive to foundation model progress.
Post-visit Medical Coding: Domain Fine-Tuning with Retrieval-Augmented Generation
Medical coding is a time-consuming process for healthcare systems. Medical coders manually review clinical documentation to extract diagnoses and procedures, then translate each into ICD (International Classification of Diseases) and CPT (Current Procedural Terminology) codes with applicable modifiers. For evaluation and management (E/M) visits, coders assess Medical Decision Making (MDM) complexity to determine the appropriate code level. They then verify that diagnoses support the billed procedures (medical necessity) before submitting for reimbursement.
Our post-visit medical coding accelerates the manual process of translating clinical notes into billing codes. The system generates ICD codes for patient diagnoses and CPT codes (with modifiers) for medical procedures, associated with evidence mapping from each code to the source medical note.
Most medical coding research focuses on a single code type (e.g., ICD or CPT only). In real-world billing, ICD and CPT codes are submitted together, and each CPT must be linked to supporting ICD codes. To reflect this, we trained the model jointly on ICD, CPT, and modifiers so that billed codes are accepted for reimbursement.
We combine supervised fine-tuning, reinforcement learning, chain-of-thought reasoning, and retrieval-augmented generation for different scenarios. Our SFT training input data includes patient context, visit type, medical notes, and additional provider input, while the output includes medical codes (ICD, CPT), modifiers, code evidence mapping, and confidence scores. Each code is linked to evidence sentences from the medical note, and the confidence score (ranging from 0 to 1) considers dimensions such as medical necessity, diagnosis – treatment alignment, and code specificity. The RL Fine-Tuning and chain-of-thought reasoning steps use Medical Decision Making (MDM) guidelines to extract the problems, risks, and medical history of the patient to determine MDM levels.
We compare our model output to historical billed medical codes to calculate both ICD and CPT code exact match metrics using real-world primary care proprietary data (Table 1).
| Type | Precision | Recall | F1 |
| ICD | 0.92 | 0.87 | 0.89 |
| CPT | 0.91 | 0.9 | 0.90 |
Table 1. ICD and CPT metrics tested on proprietary data (n=3000 medical notes).
Although our model is trained jointly on ICD and CPT for real-world billing without optimizing for ICD separately, we also benchmarked it on ACI-Bench, a common public ICD-only dataset, to report our ICD performance (Table 2).
| Method | Precision | Recall | F1 |
| LLM Simple Prompt | 0.30 | 0.56 | 0.39 |
| LLM with Chain-of-Thought (CoT) and Extended Thinking | 0.44 | 0.64 | 0.52 |
| Connect Health | 0.80 | 0.61 | 0.69 |
Table 2. ICD only metrics on public ACI-Bench (n=120 medical notes).
Health systems vary in their ICD/CPT code distributions and coding requirements. Customers can share their target code list or past coding samples to adapt the model to their distribution and improve performance.
Clinician Facing Capability Guardrails
All three capabilities share evaluation layers consisting of automated evaluations, manual clinical specialist reviews, source evidence mapping, LLM guardrails through Amazon Bedrock (e.g., toxicity and harmful content guardrails), and output format validations (e.g., if a medical coding output contains content other than codes or modifiers, the output will be blocked) to verify accuracy and safety. We prioritize product quality and clinical guideline adherence for each model release.
Amazon Connect Health Patient Engagement
Traditional interactive voice response (IVR) systems force patients through rigid, menu-driven interactions that cannot adapt to natural conversation. Agentic AI replaces this with natural language understanding that resolves patient needs in real time.
Patient engagement capabilities in Amazon Connect Health support a voice-based agentic system integrated with EHRs, currently focusing on streamlining patient authentication, insurance verification, and appointment scheduling, and escalating to manual assistance when needed. We provide Agent as a Service, so health systems can customize different agents and define their own workflows. We also provide patient-facing after-visit summaries, generated through the point of care documentation pipeline (details in previous sections).
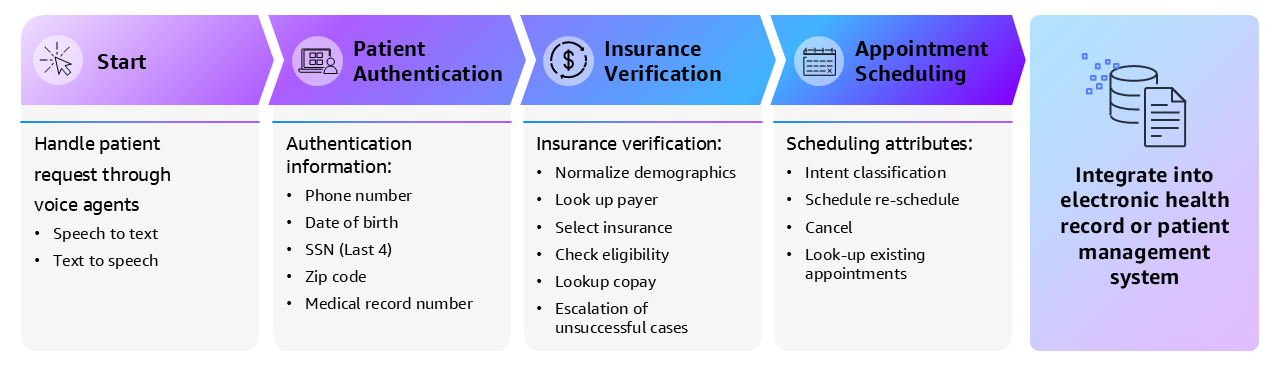
Figure 2. Amazon Connect Health patient facing agent workflows
We developed a speech-to-text (patient request), LLM agents, and text-to-speech (agent response) pipelines. For the patient authentication agent, customers can select at least 3 out of 5 choices (phone number, date of birth, last 4 digits of SSN, zip code, and medical record number) to complete the authentication process. For the insurance verification agent, we standardize patient demographics (e.g., relationship: husband = spouse), look up the specified payors if multiple insurances are available, select insurance, check eligibility, and look up copay. For appointment management, we classify user intents and support scheduling, rescheduling, canceling, and looking up existing appointments. All three agents adopt a decision-tree-style reasoning-action design. When a patient initiates a request, our agent determines whether certain conditions are met to proceed to the next state, calls the corresponding MCP tools, and generates a response. This design supports controlled outcomes at each step while minimizing hallucinations.
We developed specific guardrails and manual escalation paths for each state throughout the agent decision tree. We escalate requests to manual assistance for situations such as medical emergencies, patient-specific requests (e.g., “I want to talk to someone”), detected patient frustration, and complex or out-of-scope situations. Given the large number of special situations, we used DSPy automated prompt optimization on Amazon SageMaker AI to verify desired answers and tune our guardrails. We combine additional Amazon Bedrock customized guardrails to block toxicity, harmful content, prompt and system injection, verification bypass, insurance fraud, and certain keyword-triggered content from input and output data. We also provide customization configurations, so health systems can define their own manual escalation criteria. For system evaluations, we developed an LLM agentic patient role-play evaluation system to interact with the patient facing agents. The LLM patients were given varied profiles, tasks, and complexities. We evaluated goal fulfillment rates, escalation success rates, and instruction following. In our test environment, for patient authentication, we achieved a 92.3% success rate and reduced average handling time by 20%. For insurance verification and appointment scheduling, we achieved an 88.5% and a 78.2% goal fulfillment rate, respectively (benchmarking with IVR manual first call resolution industry average ~70%). Evaluations were conducted across multiple difficulty levels weighted to represent real-world distribution. For the remaining cases, if our agent is unable to complete the task after 3 attempts, we transfer the patient to a human agent to prioritize safety and the patient experience.
Summary
Across AWS Healthcare AI products, we apply a consistent scientific approach: domain-specific model training, multi-method evaluation, and evidence tracing for every output, all grounded in clinical guidelines. Our fine-tuning and reinforcement learning pipelines enable smaller models to match or exceed larger foundation models, keeping our products model-agnostic and adaptive to rapid advances in the field. Our agents work together to provide a holistic service for health systems — spanning data transformation, pre-visit patient insights, ambient documentation, medical coding, after-visit summaries, and patient engagement. We work with clinical specialists to design workflow guidelines and provide manual review for each model release to verify safety and adherence to clinical workflows, because in healthcare, rigor isn’t a phase – it’s continuous. As we continue to expand these capabilities, we welcome feedback and collaboration from the broader community to raise the bar on healthcare AI together.