AWS for Industries
Multi-Agent AI Solution for Vehicle Fleet Data Discovery and Edge Case Classification
Every day, autonomous vehicle (AV) fleets generate terabytes of sensor data—but the rarest, most safety-critical moments often go undetected. Autonomous vehicle manufacturers and Tier 1 suppliers face a specific challenge: identifying which driving scenarios their vehicles encounter and deciding which edge cases require safety validation.
As fleets grow, organizations cannot scale manual review to find these rare events. Traditional analytics often fail to separate safe from risky conditions, resulting in a “Freshness Gap.” This gap delays the delivery of critical safety updates because the most important data remains hidden in massive datasets for weeks.
This blog post shows how to build an automated solution on Amazon Web Services, Inc. (AWS) that enables the autonomous discovery of undefined edge cases. While the current implementation is optimized for high-precision computer vision (CV) analysis, the architecture serves as a foundational “chassis” for full multi-modal sensor fusion. By augmenting manual review with agentic reasoning, the solution may help identify rare scenarios that traditional filtering misses, helping to reduce costs.
Overview of Solution
The solution implements a processing pipeline that transforms raw Robot Operating System (ROS) bag data into fleet intelligence. This architecture is designed as a modular foundation; while the current implementation processes the ROS bag format, the extraction phase is isolated, so developers can adapt it to support other data formats.
The solution addresses the data discovery gap through three technical pillars:
- Workload-Optimized Infrastructure: The solution uses a single Amazon Elastic Container Service (ECS) cluster to manage dual Auto Scaling Groups. By using AWS Graviton-based instances for extraction and GPU instances for inference, this solution is differentiated by helping right-size hardware for cost-efficiency—something simple to orchestrate via Amazon ECS Capacity Providers.
- Dual-Vector Intelligence Layer: Amazon S3 Vectors (S3 Vectors) enables semantic similarity search with a fully managed vector indexing capability. This helps teams working with massive-scale automotive data, allowing teams to use clustering to identify natural scenario groupings like “Urban Night Pedestrian Interactions.”
- Agentic Edge Case Discovery: Amazon Bedrock AgentCore manages the session state and orchestration of the agents, while the open-source Strands Agent SDK (Strands Agent) makes it easy to define a sequential topology. This allows the system to prioritize edge cases using a risk-adaptive formula.
Figure 1 shows the complete six-phase processing pipeline from ROS bag ingestion through Operational Design Domain (ODD) categorization.
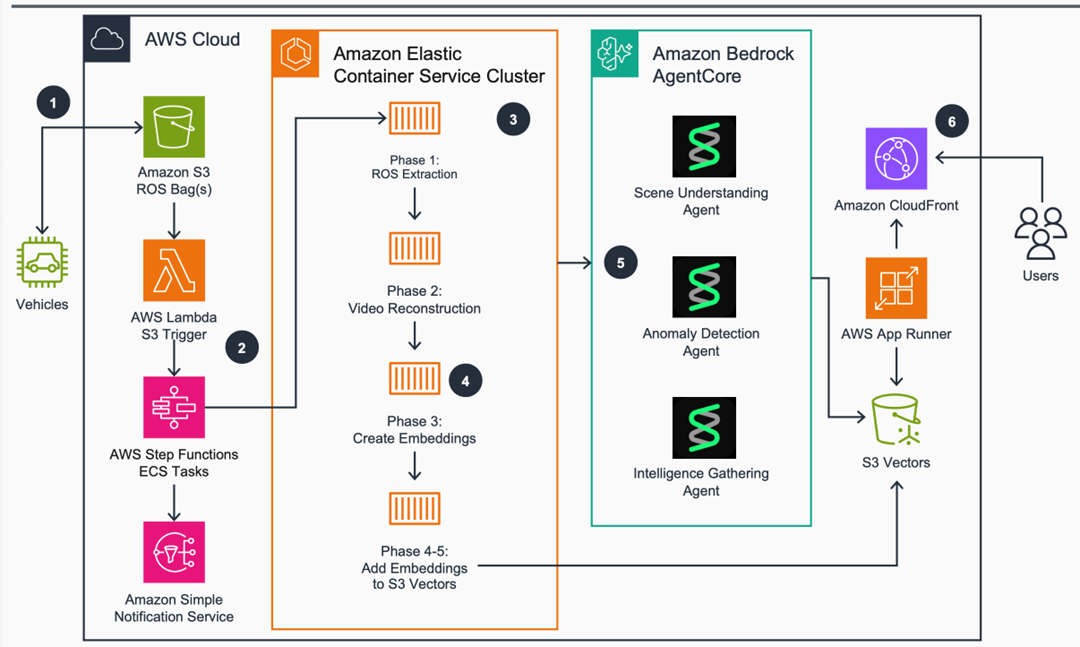
Figure 1: Multi-Agent AI Solution for Vehicle Fleet Data Discovery and Edge Case Classification
Prerequisites
To follow along with this walkthrough, the following is needed:
- An AWS account with permissions for AWS Step Functions, Amazon ECS, Amazon Bedrock, and Amazon S3
- Amazon Bedrock access with Anthropic’s Claude 4.5 Sonnet and Cohere Embed v4 enabled
- Basic understanding of Robot Operating System (ROS) message formats
- Familiarity with containerized applications and Amazon ECS task definitions
- An Amazon S3 bucket containing ROS bag data from an autonomous vehicle fleet.
- External Assets: Access to the NVIDIA NGC Catalog or Hugging Face to retrieve the weights for NVIDIA Cosmos Embed1 and InternVideo 2.5.
- Knowledge of autonomous vehicle sensor data structures and multi-camera systems
- AWS CDK and Python 3.10+ installed for infrastructure deployment
As with all AWS workloads, security and compliance are a shared responsibility between AWS and the customer. Customers are responsible for validating the outputs of this solution against their own safety and regulatory requirements.
Walkthrough
This walkthrough demonstrates how to implement a proactive fleet data discovery solution. To provide a concrete implementation, this solution uses a camera-centric subset of the NuScenes dataset to identify behavioral outliers across a six-camera surround view. A pipeline that ingests raw Robot Operating System (ROS) bag data and uses a sequential topology of three specialized agents to identify edge cases will be deployed.
The following steps walk through the implementation.
Step A: Deploying the Foundation with AWS CDK
The foundation of this solution is a single Amazon ECS cluster that manages two Auto Scaling Groups (ASGs). Matching hardware to the task ensures expensive GPU instances aren’t used for simple data extraction tasks. The solution used the AWS CDK to define a Graviton-based ASG for CPU-intensive extraction (Phases 1-2) and an ASG exclusively for the transformer model inference in Phase 3. The following code from _fleet_discovery_cdk_stack.py shows how to add these distinct capacity providers to the cluster:
Step B: Multi-Sensor ROS Bag Extraction (Phase 1)
Phase 1 focuses on extracting camera feeds, LIDAR point clouds, and vehicle telemetry exclusively from ROS bag format files. The system identifies sensors by their ROS message structure (e.g., CompressedImage, PointCloud2, Imu) to be agnostic of the underlying data structure, regardless of the sensor manufacturers used in the fleet. The following snippet from multi_sensor_rosbag_extractor.py demonstrates this single-pass extraction logic. It uses the rosbags Python library to process binary data without the overhead of a full ROS installation.
Step C: Video Reconstruction and Behavioral Analysis (Phase 2 & 3)
In Phase 2, the solution uses FFmpeg, an industry-standard open-source multimedia framework to reconstruct synchronized video streams from the raw camera frames extracted in Phase 1. This process is critical for multi-camera fleets; the system uses the original ROS timestamps to add synchronization across all camera views (Front, Rear, Left-Front, Right-Front, Left-Side, and Right-Side) and creates an aligned “world view” for forensic review.
In Phase 3, a dual-model analysis pipeline runs on GPU instances:
- InternVideo 2.5: This model performs temporal-spatial analysis to capture the “intent” of the scene. It translates visual data into a structured behavioral metadata format, including temporal metrics (velocity), spatial metrics (following distances), and interaction scores for Vulnerable Road Users (VRU proximity) such as pedestrians and cyclists.
- NVIDIA Cosmos Embed1: After behavioral analysis, the system unloads InternVideo to manage GPU memory and loads Cosmos Embed1 to generate visual embeddings. This model provides the “Visual DNA” of the scene, capturing visual qualities like lighting, color palette, and spatial composition that text descriptions often miss.
These quantified metrics and visual embeddings are the primary input for the Anomaly Detection Agent in Phase 6. By converting “visual blobs” into hard numbers and high-dimensional vectors, it is designed to help identify edge cases that fall into the 95th percentile of behavioral risk.
Step D: Establishing the Vector Intelligence Layer (Phase 4 & 5)
In Phases 4 and 5, the “Memory” of the solution is established by generating dual-vector embeddings and indexing them in S3 Vectors. This step enables natural language “semantic search” across the entire fleet dataset, allowing users to find scenes based on behavioral meaning rather than rigid rules.
The system creates two distinct mathematical representations for every 30-second scene:
- Behavioral Embeddings: Using Cohere Embed v4 via Amazon Bedrock, the dense behavioral descriptions and metrics from Phase 3 are converted into a vector that captures “what the vehicle is doing”.
- Visual Embeddings: Using the NVIDIA Cosmos Embed1 vectors generated in Phase 3, it captures “what the environment looks like”—including rare road geometries or lighting conditions that are difficult to describe in text.
By storing these in a unified index, it enables the Similarity Search Agent in Phase 6 to perform multi-modal queries. For example, the agent can find “scenes where the vehicle brakes late (behavioral) in a construction zone with heavy rain (visual).” The following snippet from _s3_vectors_behavioral_embeddings.py demonstrates how the system extracts these dual vectors from the Phase 3 output and prepares them for the S3 Vectors index:
Step E: Orchestrating Agentic Discovery with Strands SDK (Phase 6)
In Phase 6, the agentic reasoning engine is deployed using Amazon Bedrock AgentCore. The solution uses the Strands SDK to implement a sequential agent topology. This means each agent specializes in a specific layer of the discovery process, passing its findings to the next agent in the chain for “Expert (400)” level analysis.
The three agents coordinate as follows:
- Scene Understanding Agent: Decomposes the raw behavioral metrics and 32-frame video clips into environmental context (e.g., “four-way intersection with non-functioning signal”) and vehicle interaction patterns.
- Anomaly Detection Agent: Uses a detect_statistical_anomaly_tool to compare the current scene’s vectors (from Step 4) against fleet-wide historical baselines. It specifically flags scenarios in the 95th percentile of rarity or risk—identifying true edge cases that do not trigger standard rule-based alerts.
- Intelligence Gathering Agent: Connects flagged anomalies to broader fleet trends and provides context that customers may reference alongside certain regulatory compliance processes. (e.g., NHTSA or ISO 26262) using the query_similar_behavioral_patterns_tool.
The following snippet from the CDK stack shows how to define these agents using the AgentCore runtime, ensuring they are isolated by session for security and scale:
Step F: Natural Category Discovery and Naming
The final stage of the pipeline uses unsupervised machine learning to transform high-dimensional vectors into a structured library of Operational Design Domains (ODDs). Instead of relying on predefined labels, the solution implements HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) to identify natural groupings in the dual-vector space.
HDBSCAN is particularly effective for autonomous driving datasets because it accounts for varying cluster densities and isolates “noise”—the outlier scenarios that often contain the most valuable “previously undefined” edge cases.
The discovery process involves three critical technical innovations:
- Risk-Adaptive Prioritization: Safety-critical scenarios often need more engineering focus than routine ones. The system enforces this by calculating a validation target for each cluster: Target = 50 x (1 + (avg_risk x 2)). With this example formula, a low-risk cluster would require roughly 50 validated samples, while a high-risk cluster pushes toward 150.
- Intelligent ODD Naming: To transform mathematical clusters into interpretable ODDs, the solution uses Amazon Bedrock and Anthropic’s Claude 4.5 Sonnet. The system analyzes the five scenes closest to each cluster’s centroid to generate a concise, 2–4-word category name focusing on road type, weather, or maneuvers.
- Uniqueness Quality Scoring: The service calculates a uniqueness score for each cluster, which is then used by the frontend to estimate the Data Transfer Out (DTO) Value of the data.
The following snippet demonstrates the implementation of the HDBSCAN logic and the subsequent naming call to Amazon Bedrock:
The solution provides a real-time analytics dashboard that translates these clustering results into business value. By calculating a Uniqueness Score and Redundancy Ratio for every discovered ODD, the dashboard provides a DTO Value Estimate. This may help organizations identify and reduce the processing of redundant data—such as repetitive highway cruising with high redundancy ratios— which could potentially reduce data processing and transfer costs while focusing resources on the “excellent” quality edge cases that most impact vehicle safety.
Architecting a Scalable Pipeline for Full-Suite Sensor Data
While the current 6-phase pipeline is optimized for vision-based discovery, the architecture provides clear entry points for enterprise customers with full sensor suites:
- Phases 2 & 3: from video to fusion: to move beyond visual-only analysis, the reconstruction and behavior logic in Phase 2 (rosbag_video_reconstructor.py) would be expanded to process Phase 1’s raw LiDAR and telemetry outputs alongside video frames. This involves adding specialized processors for point cloud analysis and IMU/GPS telemetry to create a temporally aligned, “multi-sensor world view”.
- Enhanced behavioral analysis: in Phase 3 (internvideo25_behavioral_analyzer.py), the GenAI prompts and logic would be enhanced to consume this multi-sensor data. This allows the system to combine visual intent with spatial and motion context—transitioning from estimating velocity to measuring it via physical sensors.
- Phases 4 & 5: multi-sensor embeddings: the vector intelligence layer in Phase 4(s3_vectors_behavioral_embeddings.py) is designed for expansion. By incorporating LiDAR spatial data and vehicle dynamics into the feature extraction process, the solution can generate even higher-fidelity embeddings. This ensures that the Anomaly Detection Agent can identify edge cases based on precise physical deviations—such as 95th-percentile lateral jerk—that may be subtle in video alone.
Cleaning up
To avoid incurring future charges, delete the resources by running “cdk destroy FleetProdStack” from the terminal. The S3 buckets must be manually emptied and deleted for ROS bag storage and vector indexing, as CDK will not delete non-empty buckets by default. Finally, delete any Amazon CloudWatch log groups associated with the fleet-6phase-pipeline to ensure no residual storage costs remain.
Conclusion
This solution is designed to help address the “Manual Review Blindness” that currently bottlenecks autonomous vehicle development. By deploying a 6-phase agentic pipeline, this has created a foundation that can help teams transform raw sensor data into intelligence that may support their safety analysis processes.
The technical foundation built here addresses the primary business pain points of modern fleet operations:
- Reduced data costs: By using HDBSCAN clustering and statistical anomaly detection, the system isolates high-value scenarios and eliminates the overhead of transferring and computing redundant data, lowering Data Transfer Out (DTO) and storage costs.
- Accelerated time-to-insight: Automated scenario discovery replaces weeks of manual curation and is designed to enable near-real-time analysis, allowing safety teams to identify failure modes helping to accelerate the time from upload to insight.
- Scalable analysis to support customer safety validation efforts” or similar: The sequential agent topology powered by Amazon Bedrock is designed to help identify the “normal” behavioral baseline of a fleet and surfaces deviations—such as complex visual interactions at crosswalks—which tend to be difficult to codify with predefined rules.
Ultimately, this solution provides a scalable foundation for any OEM or Tier1 supplier to help organizations answer the most difficult question in autonomous development: “Do we have sufficient training data for the scenarios that actually matter?” By quantifying behavioral rarity and risk, you can systematically close training gaps and help support the data discovery processes that customers may use as part of their regulatory compliance efforts.