Integration & Automation
Optimize message delivery to third-party services using AWS Lambda and AWS Step Functions
This post is written with Matteo Pierangeli from YOOX and external consultant Domenico Moreschini.
YOOX is the leading online store for long-lasting fashion, design and art. Since 2000, YOOX has offered previous seasons’ finds from the world’s leading designers. The one-stop fashion and lifestyle destination inspires people to express their true selves through style, with an expansive selection of clothing for men, women, kids, art and design. YOOX pushes boundaries through its forward-thinking brand collaborations and wide product catalogue.
The product details of items up for sale, such as item availability, can vary several times a day and providing up-to-date data to third-party integrations within minutes is of great importance for the business. The need to send hundreds of millions of updates to external services in tens of minutes has led us to adopt adaptive scaling strategies to not compromise the stability of communication and the result of operations.
In this post, we describe how we used AWS Serverless services to adapt the data update flow based on the business needs and optimize message delivery to third-party services.
How we started
In our initial approach, each product update was published to an Amazon Simple Queue Service (Amazon SQS) queue read by an AWS Lambda function with a specific batch size and maximum concurrency to fine-tune the number of number of concurrent executions at the event source mapping (ESM) level. We chose Lambda for this task because it lets us focus on the actual business logic of our application while delegating the management and scaling of the underlying infrastructure to AWS.
When a large number of messages was sent to the queue, the Lambda service automatically spawned a large number of concurrent executions. Each execution made HTTP calls to send updates to an external service. When the external service could not keep up with the rate of updates we sent, it would respond with an error. By default, when Lambda detects an execution error, the entire batch processed by that execution is marked as failed and messages are re-enqueued. Executions are retried for a fixed number of times before messages are moved into a dead-letter queue, as shown in the following figure.
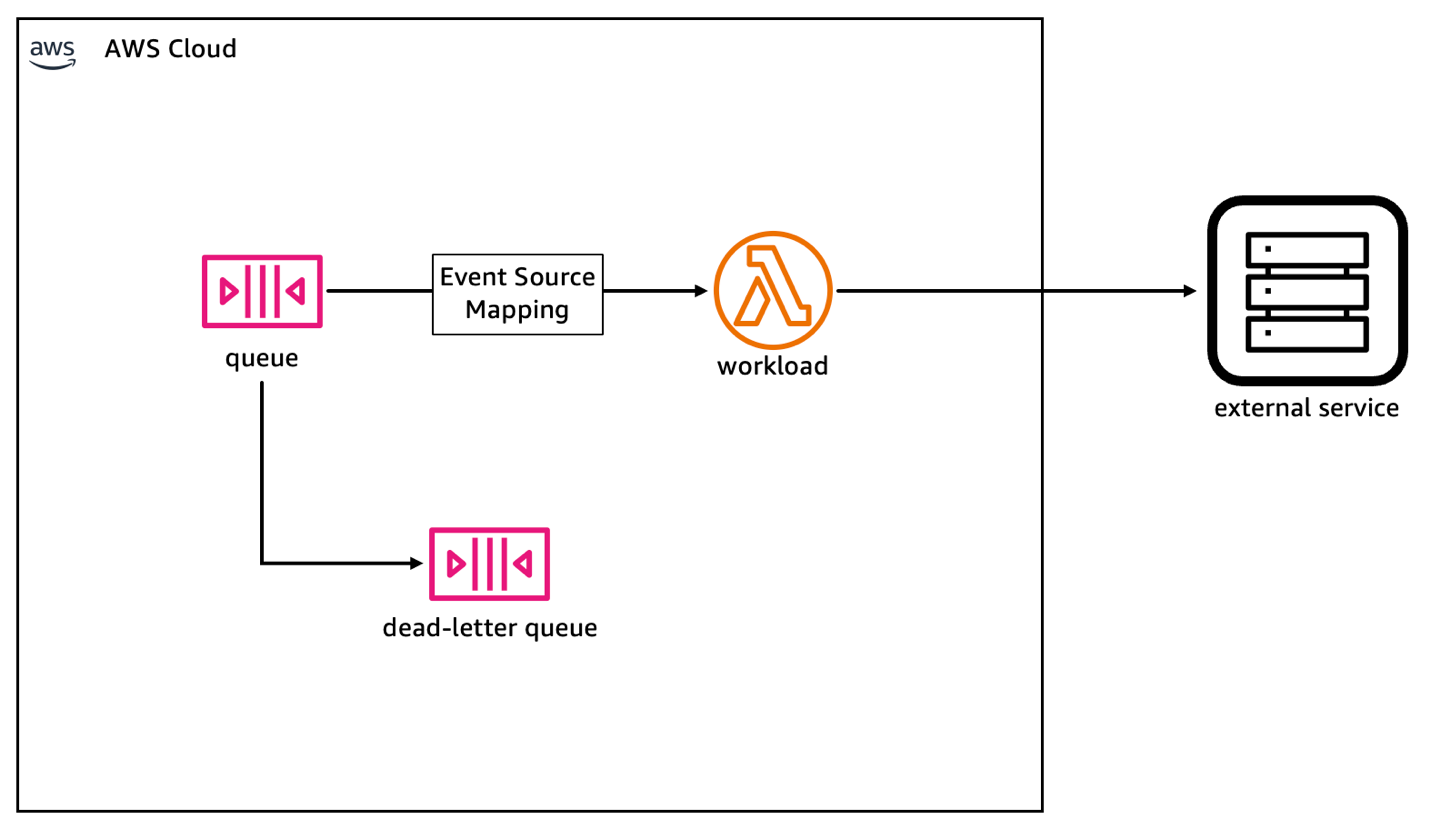
We treated all execution errors in the same way and this led to a series of problems.
First, the total number of Lambda executions was far more than they should have been because every unsuccessful batch needed to be retried. This was amplified by the fact that the whole batch was re-enqueued upon failure, instead of re-enqueuing only the individual failed messages.
This led the external service to become further overloaded because it had to process more calls than necessary.
Lastly, each retry is a new function execution, so costs also increased proportionally.
Before we dive into how we approached this issue, let’s take a step back and see how Lambda scaling works.
How Lambda scaling works with Amazon SQS
When a Lambda function is subscribed to an SQS queue, Lambda automatically polls the queue for incoming messages. The initial processing begins with five concurrent batches, each handled by a separate function instance.
For queues experiencing sudden message volume increases, Lambda can rapidly scale its processing capacity. It can add up to 300 concurrent function executions every minute, until reaching the SQS ESM maximum concurrency or the Lambda concurrent execution quota, whichever is lower.
If an error occurs during batch processing, all messages in that batch will automatically return to the queue after their visibility timeout period ends. On a side note, this means that Lambda functions must be designed with idempotency in mind—the ability to safely process the same message multiple times without causing unintended consequences.
To better manage message processing and avoid duplicate processing, it’s possible to set up the SQS ESM to record specific batch item failures in the function’s response. Partial batch responses are outside the scope of this post, but you can learn more about them in the AWS Prescriptive Guidance on the topic.
Lambda also automatically reduces the concurrency upon failure, implementing a back-off strategy to reduce invocations that would most probably fail. Partial batch responses and the maximum concurrency parameter allow for more precise control over message retry behavior and helps ensure more reliable and efficient message processing.
Our testing in a lab environment revealed that the default scaling behavior of Lambda was able to maintain function execution success rates from 80–90%, as shown in the following figure, delivering 1 million messages in 190 minutes. The rate of delivery was driven by the ingestion speed of the external service.
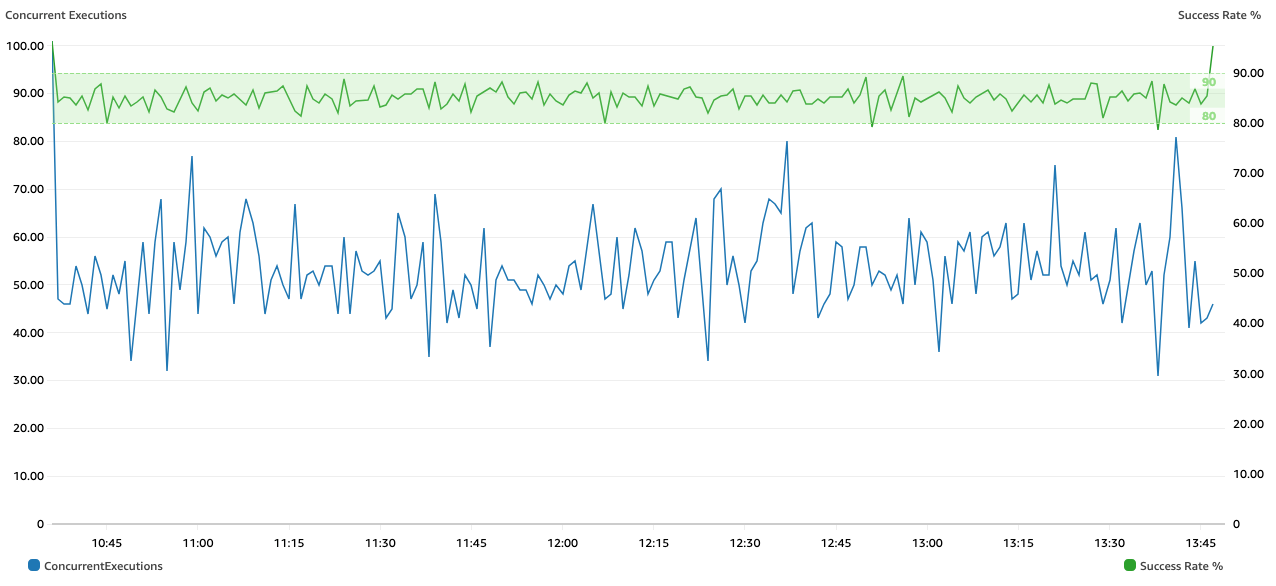
The goal was to increase the success rate, given the retry behavior of Lambda functions configured with SQS, so we looked at ways to do it.
Implementation details
The following approach demonstrates how to instrument Lambda functions to track HTTP 429 responses and automatically adjust concurrency based on throttling patterns. We walk through the code implementation, metrics collection strategy, and the automated scaling workflow that responds to throttling events.
HTTP services implement rate limiting by responding with HTTP status code 429 – Too Many Requests when they receive requests at a rate higher than they can handle.
We decided to track HTTP status codes received from the external service by logging them directly to Amazon CloudWatch Logs.
By using the built-in logging capabilities of Lambda to write these responses asynchronously instead of creating a CloudWatch custom metric and explicitly putting data into it through code, we can eliminate the need to call the cloudwatch:PutMetricData API and avoid its related costs and increased execution time. This approach reduces complexity, minimizes dependencies, and keeps costs low.
AWS provides Powertools for AWS Lambda, which is a developer toolkit to implement Serverless best practices that you can use to create custom metrics automatically using the Embedded Metric Format.
Powertools for AWS Lambda is available for multiple programming languages as a Lambda layer. The following example Python code uses the AWS Powertools library to publish the custom metric ThrottledRequests.
The beauty of this approach is that no setup is required to get custom metrics from your code apart from adding the Powertools library as a layer to the Lambda function .
After we instrumented our code to emit throttling metrics, we wanted to take action based on throttling levels. To do so, we implemented a workflow in AWS Step Functions that is invoked whenever the throttling percentage breaches a threshold defined by us. The throttling percentage is the ratio between the ThrottledRequests custom metric described previously and the Invocations metric associated with the function.
Because CloudWatch Alarms cannot directly trigger the workflow execution, we defined an Amazon EventBridge rule based on the event of the CloudWatch alarm state change to trigger it. The workflow is shown in the following figure.
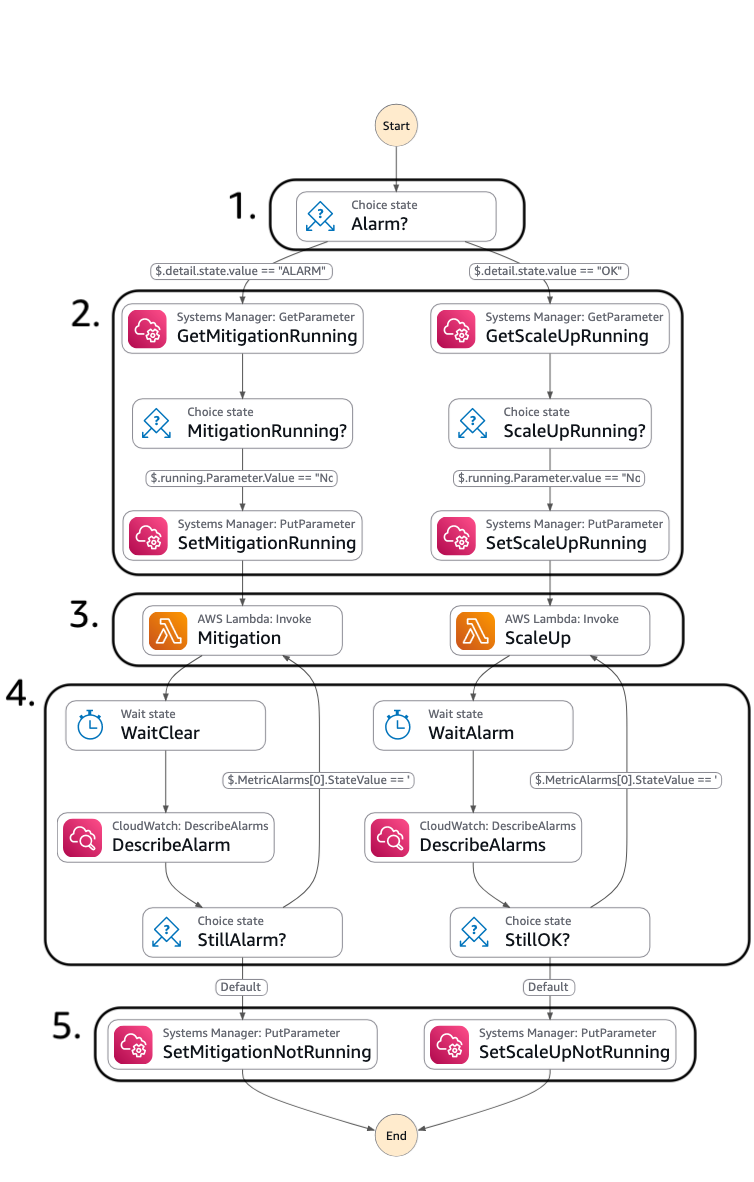
The workflow starts by checking the state of the CloudWatch alarm [1]. It then checks if another instance of itself is already running by looking at the value of a parameter in AWS Systems Manager Parameter Store. If it’s not, it sets the parameter value to running [2] and then executes either the scale down or the scale up [3], depending on the CloudWatch alarm state. It then waits for 2 minutes and checks the alarm state again [4]. The workflow loops until the CloudWatch alarm state changes and then exits [5].
We want to be aggressive in scaling down while scaling up more gradually, so in our tests we implemented the scale down logic to reduce maximum concurrency by at least 50% at each iteration and the scale up logic to increase maximum concurrency by at least 30%, up to a predefined concurrency upper limit.
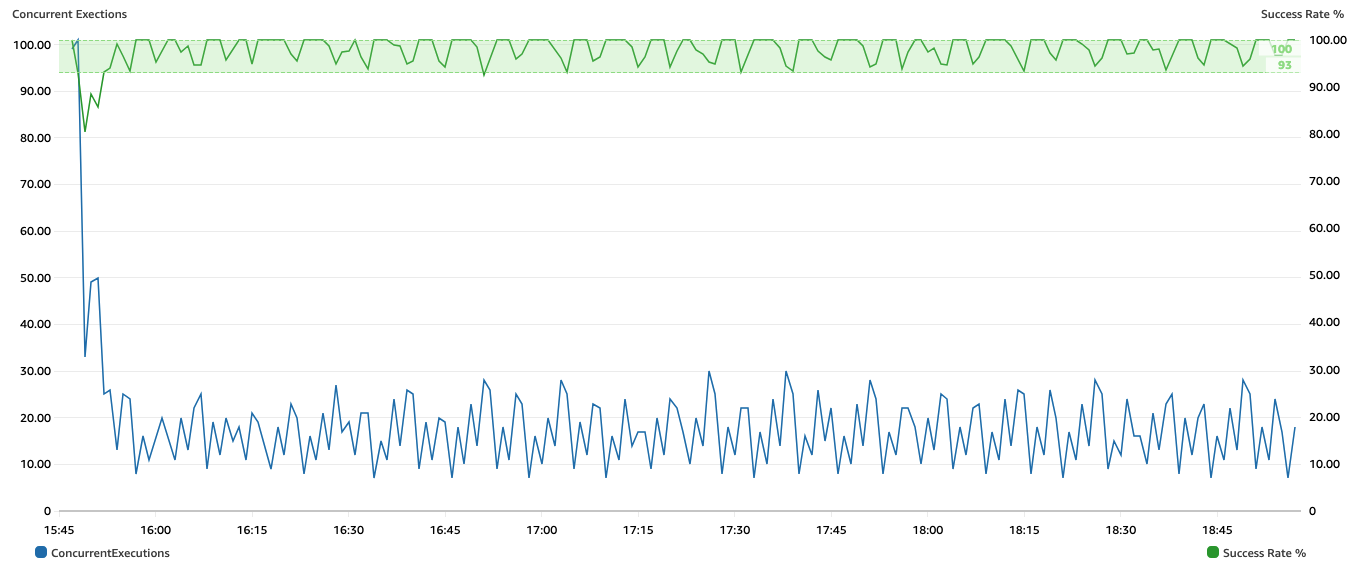
Let’s say we can tolerate around 5% of throttling; we will set up the CloudWatch alarm to trigger the Step Functions workflow whenever throttling is greater than 5% for one evaluation period (1 minute). The test results are shown in the following figure: target execution success rate of 95% is achieved within 10 minutes of the job start and is then kept within 93% and 100% throughout the job run. The job still delivers 1 million messages in 190 minutes, the rate of delivery being driven by the ingestion speed of the external service.
Solution overview
The overall design of the solution is shown in the following figure:
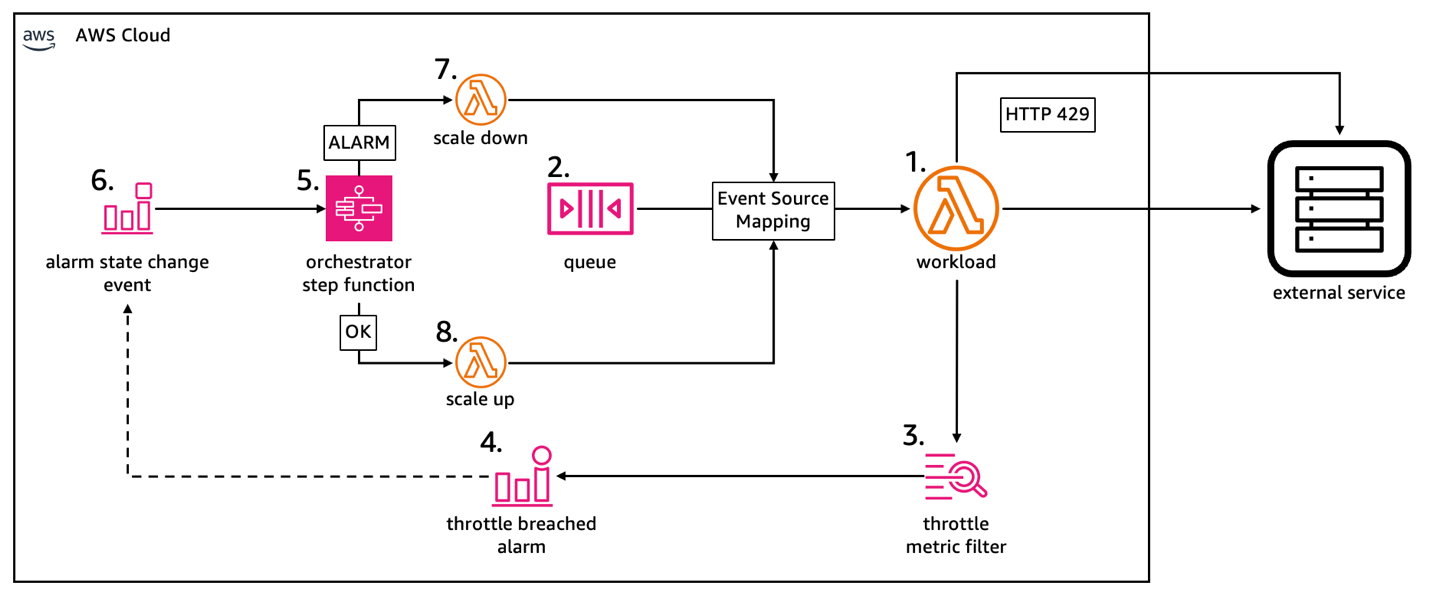
The workload Lambda function [1] processes messages from the source SQS queue [2] and sends them to the external service. The function logs any HTTP 429 response it receives from the external service using the EMF which automatically creates a CloudWatch custom metric [3]. An alarm [4] is defined on this custom metric, which triggers a Step Functions workflow [5] when its state changes [6]. This Step Functions workflow orchestrates Lambda functions [7 and 8] to fine-tune the maximum concurrency parameter of the ESM associated with the SQS queue and the workload Lambda function when the throttling alarm status changes.
For ease of understanding, in this post we omitted details of the implementation that we deployed in production to focus on the solution design as a pattern. The Step Functions workflow implements error handling, which isn’t shown in preceding figure for readability. Our scaling mechanism also controls the batch size to fine-tune the number of messages to retry with each invocation and the scaling behavior is more gradual than the one shown.
Best practices
Lambda enforces a default concurrency limit of 1,000 concurrent executions per AWS Region across all functions within your account. Functions dynamically share this concurrency pool, competing for available execution slots on demand. When the aggregate concurrent executions exceed this limit, Lambda begins throttling requests and executions will fail.
The service provides two concurrency control mechanisms to address different operational requirements:
Reserved concurrency allocates a dedicated portion of your account’s concurrency limit to specific functions. This allocation establishes both maximum and minimum concurrency boundaries: the function cannot exceed the reserved amount, and other functions cannot consume the reserved capacity. Reserved concurrency prevents resource contention between functions while ensuring critical workloads maintain consistent execution capacity.
Provisioned concurrency pre-initializes execution environments before function invocation occurs. Lambda maintains warm instances ready to process requests immediately, eliminating cold start latency for latency-sensitive applications. Provisioned concurrency operates independently of reserved concurrency settings and incurs additional charges for pre-warmed capacity.
The ESM level parameter maximum concurrency that we discussed in this post, on the other hand, provides granular scaling control for SQS integrations, limiting concurrent function instances that a specific SQS queue can invoke. This setting applies independently for each ESM; functions with multiple SQS triggers can configure different maximum concurrency values per queue.Maximum concurrency and reserved concurrency work as independent controls with critical interdependencies. Setting maximum concurrency above a function’s reserved concurrency creates a configuration conflict that results in message throttling.Make sure that reserved concurrency, if set, meets or exceeds the aggregate maximum concurrency across all SQS ESMs for a function. For example, if Function A has three SQS triggers with maximum concurrency settings of 50, 30, and 20 respectively, configure reserved concurrency to at least 100 concurrent executions to prevent throttling.
Conclusion
Well-architected services implement mechanisms to avoid failing because of overload. Rate limiting, or throttling, is one of the strategies that are usually adopted to protect services from excessive load.
Well-architected clients, on the other hand, should respond to rate limiting by implementing a retry with back-off pattern, for example by scaling down the rate of retries, closing the back pressure loop.
The solution we adopted implements a custom retry with a back-off strategy by reacting to the external service throttling, adjusting the Lambda function concurrency at the SQS ESM level to dynamically and continuously find the optimal value at which the external service is able to keep up with our rate of calls. The unique combination of event-driven execution, built-in concurrency controls, and seamless AWS service integration found in Lambda makes this throttling response pattern particularly effective. Unlike traditional compute solutions that require custom scaling logic and infrastructure management, Lambda provides native mechanisms for concurrency adjustment and automatic resource allocation, enabling a more responsive and cost-effective approach to handling external service rate limits.
About the authors
 Gabriele Postorino is a Principal Cloud Operations Architect at Amazon Web Services (AWS), where he has been working for over 10 years in various roles. He focuses on guiding customers to optimize their applications to improve their resiliency and performance efficiency.
Gabriele Postorino is a Principal Cloud Operations Architect at Amazon Web Services (AWS), where he has been working for over 10 years in various roles. He focuses on guiding customers to optimize their applications to improve their resiliency and performance efficiency.
 Matteo Pierangeli is a Software Architect at YOOX, with 15 years of experience in software development, primarily focused on backend systems. Passionate about distributed systems, he has solid experience in designing and evolving complex, high-performance architecture with an emphasis on scalability and long-term maintainability. Matteo is naturally curious and driven by a desire to understand how things work, with a broad interest in all things tech.
Matteo Pierangeli is a Software Architect at YOOX, with 15 years of experience in software development, primarily focused on backend systems. Passionate about distributed systems, he has solid experience in designing and evolving complex, high-performance architecture with an emphasis on scalability and long-term maintainability. Matteo is naturally curious and driven by a desire to understand how things work, with a broad interest in all things tech.
 Domenico Moreschini is a Software Developer and consultant with 10 years of experience mostly on backend software with a strong focus on .NET ecosystem. In recent years he directed his expertise and curiosity towards the challenges and opportunities of cloud development, helping organizations design and build scalable and modern solutions.
Domenico Moreschini is a Software Developer and consultant with 10 years of experience mostly on backend software with a strong focus on .NET ecosystem. In recent years he directed his expertise and curiosity towards the challenges and opportunities of cloud development, helping organizations design and build scalable and modern solutions.