Artificial Intelligence
Author: Chaitanya Hazarey
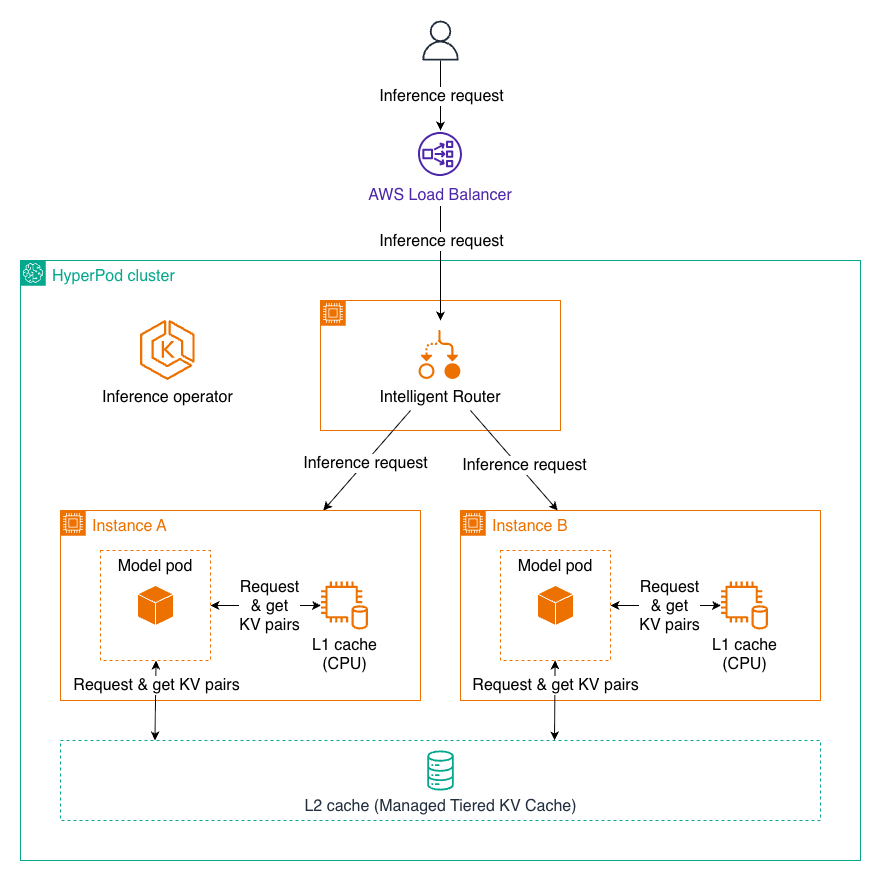
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod
In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead.

Maximize TensorFlow performance on Amazon SageMaker endpoints for real-time inference
Machine learning (ML) is realized in inference. The business problem you want your ML model to solve is the inferences or predictions that you want your model to generate. Deployment is the stage in which a model, after being trained, is ready to accept inference requests. In this post, we describe the parameters that you […]
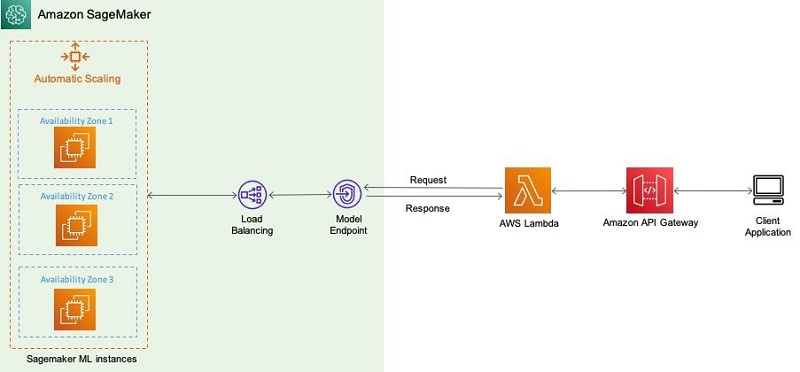
Configuring autoscaling inference endpoints in Amazon SageMaker
August 2025: This post was reviewed and updated for accuracy. Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to quickly build, train, and deploy machine learning (ML) models at scale. Amazon SageMaker removes the heavy lifting from each step of the ML process to make it […]