Artificial Intelligence
Author: Thomas Hughes

Ensure consistency in data processing code between training and inference in Amazon SageMaker
In this blog post, we’ll show you how to deploy an inference pipeline consisting of pre-processing using SparkML, inferences using XGBoost, and post-processing using SparkML. For this particular example, we are using the Car Evaluation Data Set from UCI’s Machine Learning Repository and training an XGBoost model to predict the condition of a car (i.e. unacceptable, acceptable, good, or very good).
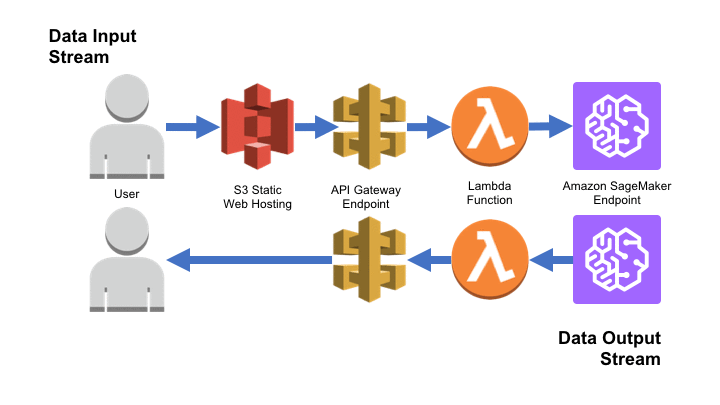
Build a serverless frontend for an Amazon SageMaker endpoint
Amazon SageMaker provides a powerful platform for building, training, and deploying machine learning models into a production environment on AWS. By combining this powerful platform with the serverless capabilities of Amazon Simple Storage Service (S3), Amazon API Gateway, and AWS Lambda, it’s possible to transform an Amazon SageMaker endpoint into a web application that accepts […]
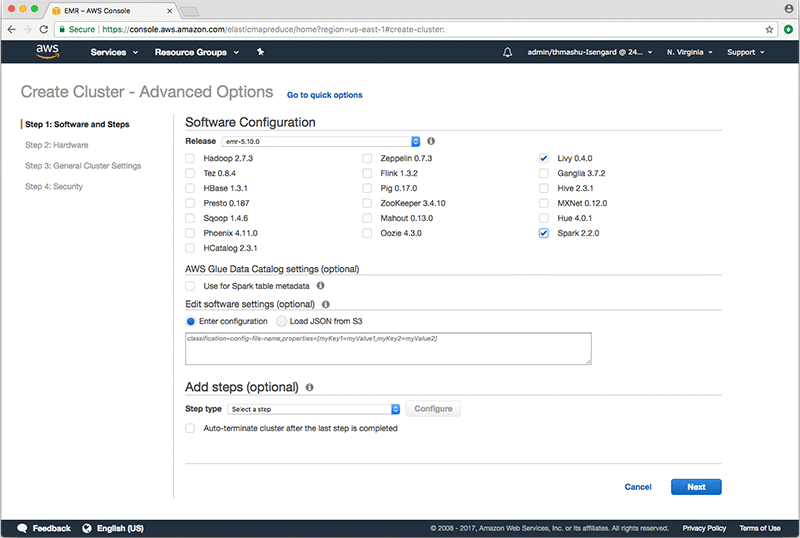
Build Amazon SageMaker notebooks backed by Spark in Amazon EMR
This blog post was last reviewed August, 2022. Introduced at AWS re:Invent in 2017, Amazon SageMaker provides a fully managed service for data science and machine learning workflows. One of the important parts of Amazon SageMaker is the powerful Jupyter notebook interface, which can be used to build models. You can enhance the Amazon SageMaker […]