Artificial Intelligence
Build Amazon SageMaker notebooks backed by Spark in Amazon EMR
This blog post was last reviewed August, 2022.
Introduced at AWS re:Invent in 2017, Amazon SageMaker provides a fully managed service for data science and machine learning workflows. One of the important parts of Amazon SageMaker is the powerful Jupyter notebook interface, which can be used to build models. You can enhance the Amazon SageMaker capabilities by connecting the notebook instance to an Apache Spark cluster running on Amazon EMR. Amazon EMR is a managed framework for processing massive quantities of data. The combination allows you to build models on large quantities of data.
Spark is an open source cluster-computing framework that allows for fast processing of big data, and includes MLlib for machine learning workloads. To facilitate a connection between an Amazon SageMaker notebook and a Spark EMR cluster, you will need to use Livy. Livy is an open source REST interface for interacting with Spark clusters from anywhere without the need for a Spark client.
In this blog post, we’ll show you how to spin up a Spark EMR cluster, configure the necessary security groups to allow communication between Amazon SageMaker and EMR, open an Amazon SageMaker notebook, and finally connect that notebook to Spark on EMR by using Livy. This setup will work with PySpark, Spark, and SparkR notebooks.
Set up EMR Spark and Livy
Open the AWS Management Console, and from Services menu at the top of the screen, select EMR under the Analytics section. Choose Create Cluster. Go to Advanced Options (at the top, next to where it says Create Cluster – Quick Options) and uncheck everything. Then, specifically check Livy and Spark. Choose Next.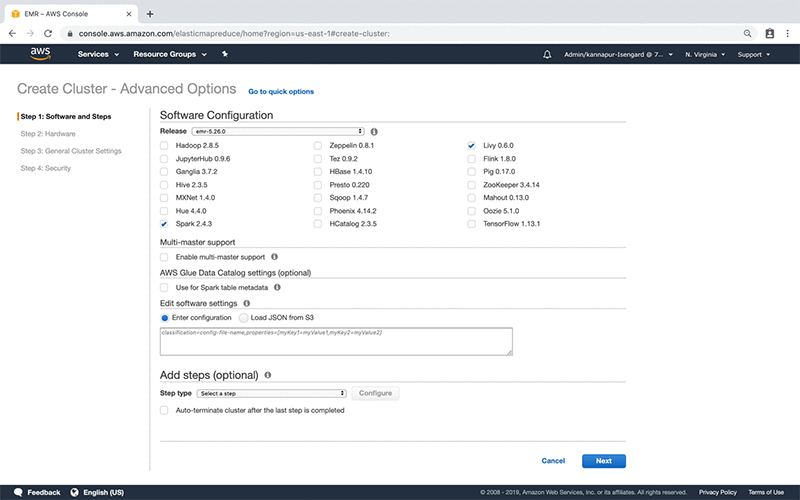
Under Network, select Your VPC. For this blog post example, mine is called sagemaker-spark. You will also want to make a note of your EC2 Subnet because you will need this later.

Choose Next and then choose Create Cluster. Feel free to include any other options to your cluster that you think might be appropriate, such as adding key pairs for remote access to nodes, or a custom name to the cluster.
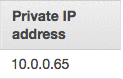
Now, you need to get your Private IP address for the Master node of your Spark cluster.
Choose Services and then choose EMR. Wait until your cluster is marked as Waiting (in green), and then choose the cluster you created. Choose the Hardware tab.

Choose your Master’s ID, and then scroll right to find Private IP Address. Save this for later. In this blog post example, mine is 10.0.0.65, but yours will be different.
Set up security groups and open ports
Next we need to set up a security group and open the relevant ports, so our Amazon SageMaker notebook can talk to our Spark cluster via Livy on port 8998.
In the console, choose Services and then EC2. In the navigation pane at the left, choose Security Groups. Then choose the Create Security Group button.
Set a Security Group Name (mine is sagemaker-notebook), a Description, and the VPC you used for your EMR cluster (mine is sagemaker-spark).
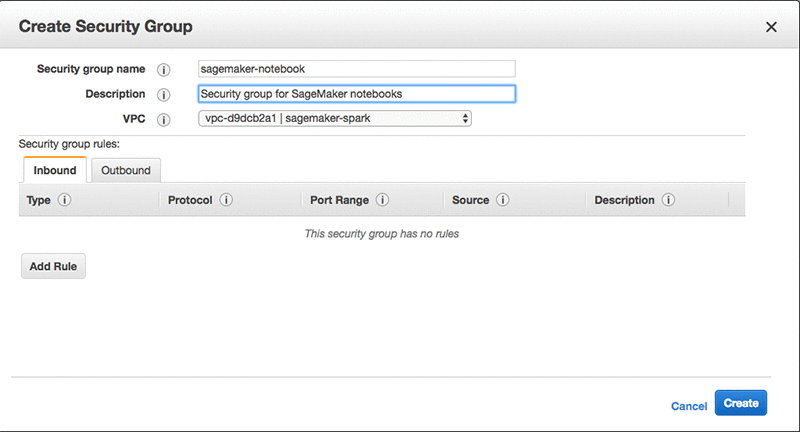
Choose Create.
This creates the security group, making it possible for us to only open the port to instances that are in this group. We still need to open the port in our ElasticMapReduce-master group.
While still in Security Groups, obtain the Group ID of your SageMaker notebook security group. You can see mine is sg-35610640, but yours will be different. Save this value for later.

We need to modify the EMR master security group that was automatically created when we created our EMR cluster. Select your ElasticMapReduce-master group, and then choose the Inbound tab. Choose the Edit button, and then choose the Add Rule button.
We want to create a Custom TCP Rule, on port 8998, and set the Security Group ID to the Group ID from the SageMaker notebook security group that we collected earlier. Remember, mine was sg-35610640. Here’s an example of what the fields look like when completed:

Choose the Save button. You’ve now opened up the important ports, so your SageMaker notebook instance can talk to your EMR cluster over Livy.
Set up SageMaker notebook
We now have our EMR Spark cluster running with Livy, and the relevant ports available. Now let’s get our Amazon SageMaker Notebook instance up and running.
Choose Services and then Amazon SageMaker. Choose the Create Notebook Instance button.
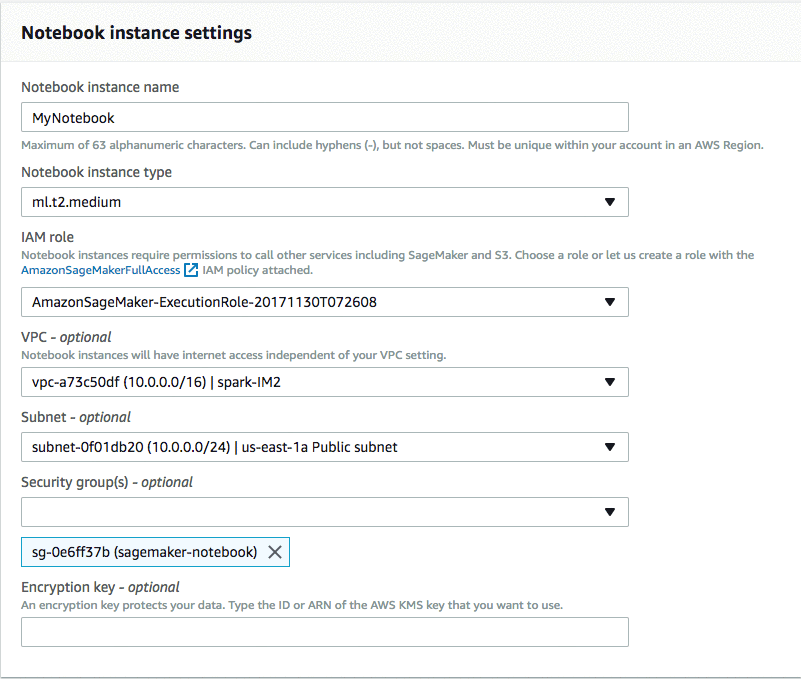
You need to set a Notebook instance name and select a Notebook instance type. Be aware that there are some naming constraints for your Notebook instance name (maximum of 63 alphanumeric characters, can include hyphens but not spaces, and it must be unique within your account in an AWS Region). You also need to set up an IAM role with AmazonSageMakerFullAccess, plus access to any necessary Amazon Simple Storage Service (Amazon S3) buckets. You need to specify which buckets you want the role to have access to, but then you can let Amazon SageMaker generate the role for you.
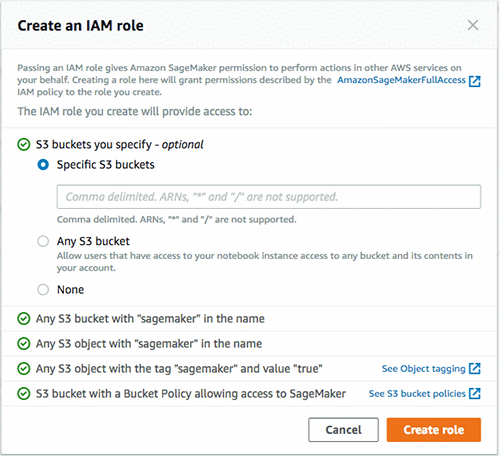
Then you need to make sure that you set up your Notebook instance in the same VPC as your EMR cluster (for me, this was sagemaker-spark). Also select the same Subnet as the EMR cluster (you should have made note of this earlier, when you created your EMR cluster). Finally, set your security group to the group you created earlier for Notebook instances (mine was sagemaker-notebook).
Choose Create Notebook Instance.
Wait until EMR finishes provisioning the cluster and the SageMaker notebook status says InService.
Connect the notebook to Amazon EMR
Now we have our EMR Spark cluster and our Amazon SageMaker notebook running, but they can’t talk to each other yet. The next step is to set up Sparkmagic in SageMaker so it knows how to find our EMR cluster.
While still in the Amazon SageMaker console, go to your Notebook Instances and choose Open on the instance that was provisioned.
Inside your Jupyter console, choose New and then Terminal.
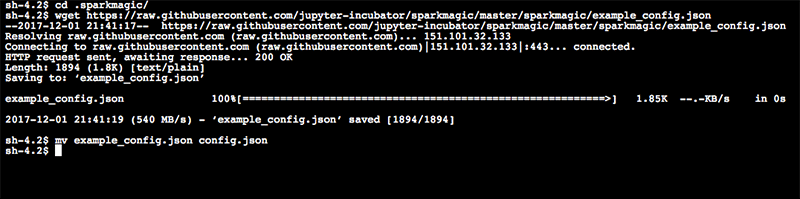
Type the following commands:
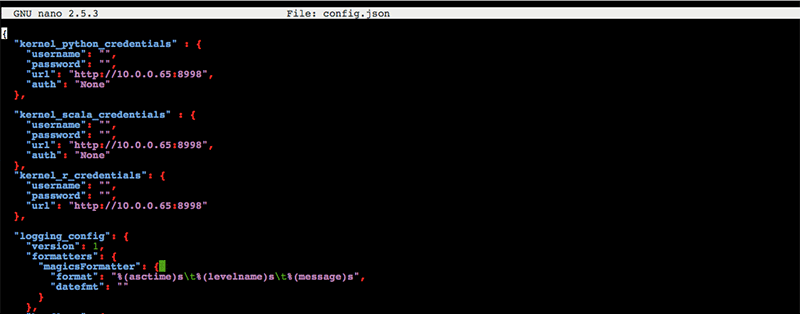
Then you need to edit the config.json, and replace every instance of `localhost` with the Private IP of your EMR Master that you used earlier. Mine is 10.0.0.65, which we saw earlier, but yours will be different!
I used the following commands:
- nano config.json
- ctrl+\
- localhost
- <your EMR Master private IP>
- a
- ctrl+x
- y
- enter
This should replace three instances of localhost in the “url” field of the three kernel credentials. Feel free to use any editor you are comfortable with, and save the changes.
Before moving forward, we should test our connection to EMR over Livy. We can do that by running the following command (replace the EMR Master Private IP with the IP address of your instance):
- curl <EMR Master Private IP>:8998/sessions
Your output should look like the following:

If you get an error, it likely means that your ports have not been opened in the security group, so I would recommend going back and checking those settings!
Let’s close the terminal. Type exit and then close the browser tab with the terminal. Open the tab with Jupyter, and choose New and then Sparkmagic (PySpark) to open a PySpark notebook. Just to be sure, let’s re-start the kernel by choosing Kernel and then Restart.
Let’s test the connection with the following command in the first cell:
- %%info
Type shift and enter at the same time to run the cell, and you should see something like the following output:

Congratulations! You now have a Sparkmagic kernel running in your Jupyter notebook, talking to your EMR Spark cluster by using Livy.
This post was updated August 29, 2019 to include SageMaker integration with the latest Spark kernel.
About the Authors
 Thomas Hughes is a Data Scientist with AWS Professional Services. He has a PhD from UC Santa Barbara and has tackled problems in in the social sciences, education, and advertising. He is currently working to solve some of the trickiest problems that arise when machine learning meets big data.
Thomas Hughes is a Data Scientist with AWS Professional Services. He has a PhD from UC Santa Barbara and has tackled problems in in the social sciences, education, and advertising. He is currently working to solve some of the trickiest problems that arise when machine learning meets big data.
 Stefano Stefani is a Senior Principal Engineer with AWS and served as chief technologist for multiple AWS services: Amazon SimpleDB, Amazon DynamoDB, Amazon Redshift, and Amazon Aurora. Currently he is covering the same position on Amazon AI: Amazon Lex, Amazon Rekognition, Amazon SageMaker, Amazon Transcribe, and others.
Stefano Stefani is a Senior Principal Engineer with AWS and served as chief technologist for multiple AWS services: Amazon SimpleDB, Amazon DynamoDB, Amazon Redshift, and Amazon Aurora. Currently he is covering the same position on Amazon AI: Amazon Lex, Amazon Rekognition, Amazon SageMaker, Amazon Transcribe, and others.
 Daniel Herkert works with Amazon’s Machine Learning Solution’s Lab. He holds a MFin in Financial Engineering from Massachusetts Institute of Technology and has worked for several years as a quantitative analyst in the financial markets. Today he is working with customers to develop and integrate machine learning and AI solutions on AWS.
Daniel Herkert works with Amazon’s Machine Learning Solution’s Lab. He holds a MFin in Financial Engineering from Massachusetts Institute of Technology and has worked for several years as a quantitative analyst in the financial markets. Today he is working with customers to develop and integrate machine learning and AI solutions on AWS.
 Kartik Kannapur is an Associate Data Scientist with AWS Professional Services. He holds a Master’s degree in Applied Mathematics and Statistics from Stony Brook University and focuses on using machine learning to solve customer business problems.
Kartik Kannapur is an Associate Data Scientist with AWS Professional Services. He holds a Master’s degree in Applied Mathematics and Statistics from Stony Brook University and focuses on using machine learning to solve customer business problems.