AWS Cloud Operations Blog
Gaining more control over Multi-Regional AWS CloudFormation deployments
Routinely deploying resources to multiple regions is increasingly normal for situations like Disaster Recovery (DR), regulatory and compliance, and end-user latency requirements. Keeping multiple environments in sync is challenging and drives Infrastructure as Code (IaC) adoption through services like AWS CloudFormation. This post demonstrates a generic design pattern for orchestrating multi-Regional deployments when you need more control and without more dependencies.
Overview
The AWS cloud is partitioned into Regions and then into Availability Zones (AZs). Workloads spanning Multi-AZ can gracefully maintain high availability even during a data center failure. Several use-cases require even more resiliency to ensure business continuity. These situations necessitate the deployment of data and applications across more partitions (via Multi-Region deployments). Beyond availability, many production workloads must operate within specific geographic areas for regulatory and compliance reasons, such as Europe’s GDRP (General Data Protection Regulation) requirements. Additionally, other applications require low latency for their global end-users.
Customers maintain these multiple environments by using automation through infrastructure and code tools, such as AWS CloudFormation. Previously, CloudFormation Stacks could only deploy into a single Region, so DevOps teams had no choice but to introduce third-party tooling. In 2017, CloudFormation added AWS CloudFormation StackSets to extend the functionality of stacks by enabling you to create, update, or delete stacks across multiple accounts and Regions with a single operation. This feature removes automation complexity by letting customers deploy a central CloudFormation template that orchestrates Regionalized child deployments.
For many situations, StackSets remain the best tool for automating Multi-Regional or Multi-Account environments. However, it isn’t the right tool for every scenario. Perhaps the deployment needs custom retry policies or conditional actions. This post demonstrates a two-phased design pattern for those other situations that require more control and dynamic behaviors.
The procedure begins by deploying resources (e.g., AWS Step Functions) and then leveraging those capabilities during the second phase. CloudFormation exposes primitives for making API calls (e.g., StartExecution) and waiting for long-running operations to complete (e.g., Wait-Conditions). Customers can perform both phases within the same AWS CloudFormation Stack! Furthermore, these capabilities can eliminate complexity within Continuous Integration and Deployment (CI/CD) Pipelines. Additionally, this approach is broadly applicable using other resource types, such as Amazon Fargate.
Approach
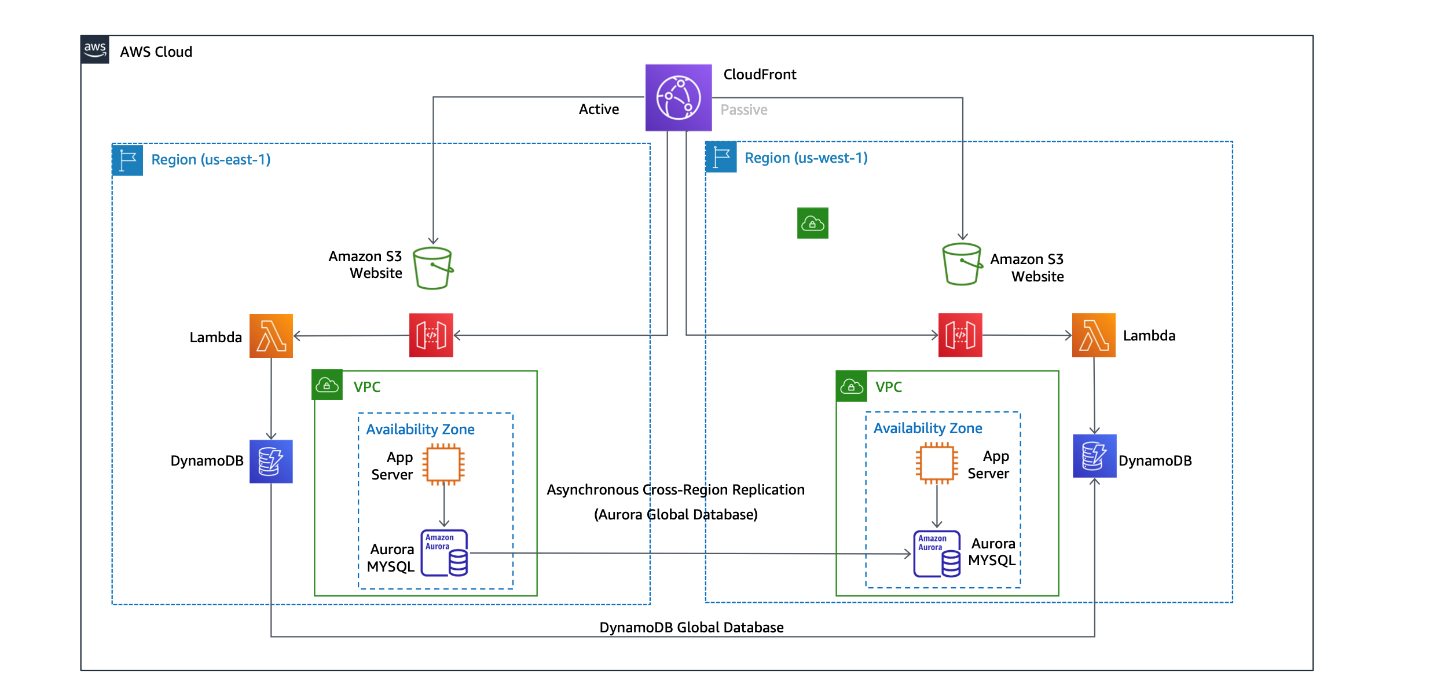
The two-phased deployment approach broadly applies to numerous scenarios. We demonstrate a specific example reusing the Disaster Recovery Hot Standby Disaster Recovery Workshop (as seen in the following image). During that workshop, learners deploy and configure a mock Multi-Region eCommerce site. Afterward, they simulate fail-over scenarios. However, you don’t need to take that training to understand this section.
Our goal is to automate that workshop’s deployment by using the methodology described in the Overview section. A complete implementation is available in this repository. It uses the AWS Cloud Development Kit (CDK) to generate the final CloudFormation Template. AWS CDK lets you build reliable, scalable, and cost-effective applications in the cloud with the considerably expressive power of a programming language. More information regarding the code sample is available on the repository home page.
The workshop’s deployment automation must complete three high-level tasks:
- Define the orchestration AWS Step Function (see the following image)
- Begin executing the Step Function’s state machine
- Wait for the state machine to complete
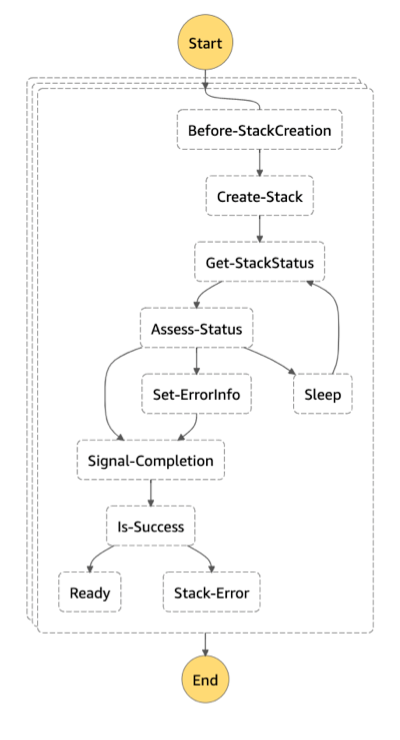
Diagram Description
The Step Function’s state machine begins with a collection of Map tasks. Maps support running a set of steps for each element of an input array, either parallelly or sequentially. In this particular case, each element represents the configuration for a target region. This capability can support sophisticated dependency trees (e.g., create a Primary instance before Secondary Region).
Next, it uses a series of AWS Lambda functions to prepare, create, and monitor a Regional stack deployment. Furthermore, state machines support error handling controls, which can automatically remediate issues instead of failing the entire orchestration.
Lastly, a Lambda function uses an AWS CloudFormation wait condition to signal the Step Function completed. The signal can include metadata for the calling orchestration template for sophisticated deployment state sharing situations.
Executing the Step Function
AWS CloudFormation Custom resources enable the writing of custom provisioning logic by specifying service tokens that stipulate which AWS Resource (e.g., AWS Lambda) implements that logic. For many situations, calling an individual AWS SDK API is sufficient. The AWS CDK makes this easy with the AwsCustomResource construct. Under the hood, AWS CDK will generate a Lambda function and then call that operation.
Conclusion
Customer workloads must leverage Multi-Regional environments for availability, compliance, and latency reasons. Automating those deployments is challenging and creates the need for more control and dynamic behaviors. In this post, we propose a two-phase approach that provisions resources, and then uses them to support the deployment of the remaining resources. See the repository for more information.