AWS Cloud Operations Blog
Query and visualize Microsoft SQL Server license utilization using Amazon Athena and Amazon QuickSight
In part 1 of this two-part series, I showed you how to deploy a solution to centrally track Microsoft SQL Server licenses in AWS Organizations across multiple AWS accounts and Regions. In this post, I will show you how to query and visualize the aggregated Inventory data using Amazon Athena and Amazon QuickSight to centrally manage your SQL Server licenses. With the right visualization in place your organization can gain a deeper insight into your license consumption across the business in a much quicker timeframe which in turn can help you improve license governance and optimise license utilization.
Solution overview
In this post, I will focus on steps 9 and 10 in the solution architecture shown in Figure 1. Athena provides an interactive query service to analyze the Inventory data in Amazon S3 using standard SQL. QuickSight makes it possible to create and publish interactive BI dashboards with insights powered by machine learning.

Figure 1: Solution architecture
Prerequisites
To complete the steps in this walkthrough, deploy the solution described in part 1 of this two-part series.
Walkthrough
Athena will help us query the aggregated data in the centralized S3 bucket that we created in the ‘resource data sync’ step from part 1.
- In the Athena console, copy and paste the following statement into the query editor and then choose Run Query.
CREATE DATABASE ssminventory
The console creates a database named ssminventory, a logical grouping for the three tables you will be creating:
-
AWS_InstanceDetailedInformation: Consists of an instance’s metadata such as CPU and cores.AWS_Tag: Consists of all the tags defined for an instance.Custom_SQLServer: Consists of the SQL Server metadata, including edition and version, running on an instance.
For more information, see Metadata collected by inventory in the AWS Systems Manager User Guide.
If you want to set up more inventory tables in Athena, see Walkthrough: Use resource data sync to aggregate inventory data.
- Copy and the following statement and paste it into the query editor. Replace
DOC-EXAMPLE-BUCKETandbucket_prefixwith the name and prefix of the central Amazon S3 bucket created in part 1. Choose Run Query.
- To partition the table, copy the following statement, paste it into the query editor, and then choose Run Query.
MSCK REPAIR TABLE ssminventory.AWS_InstanceDetailedInformation
Note: You will need to run this statement again as the partition changes (for example, for new accounts, regions, or resource types). Depending on how often these change in your organization, consider using the AWS Glue crawler to automate this step.
- To preview your data, choose … and then next to the
AWS_InstanceDetailedInformationtable, choose Preview table. - Run the following queries individually in the Athena console to set up the
AWS_TagandCustom_SQLServertables.
Visualize the data using QuickSight
Now that the data is available to access using Athena, you will use QuickSight to visualize it.
Prepare the dataset
Amazon QuickSight provides out-of-the-box integration with Athena. For more information, see Creating a Dataset Using Amazon Athena Data.
For this step you can use the ssminventory database that you created in the previous step. To try out different combinations for analysis and visualization, we will create three datasets in QuickSight as described below. To simplify the experience of visualizing data in QuickSight, you can build views in Athena.
- In the Amazon QuickSight console, select custom_sqlserver and then choose Edit/Preview data.
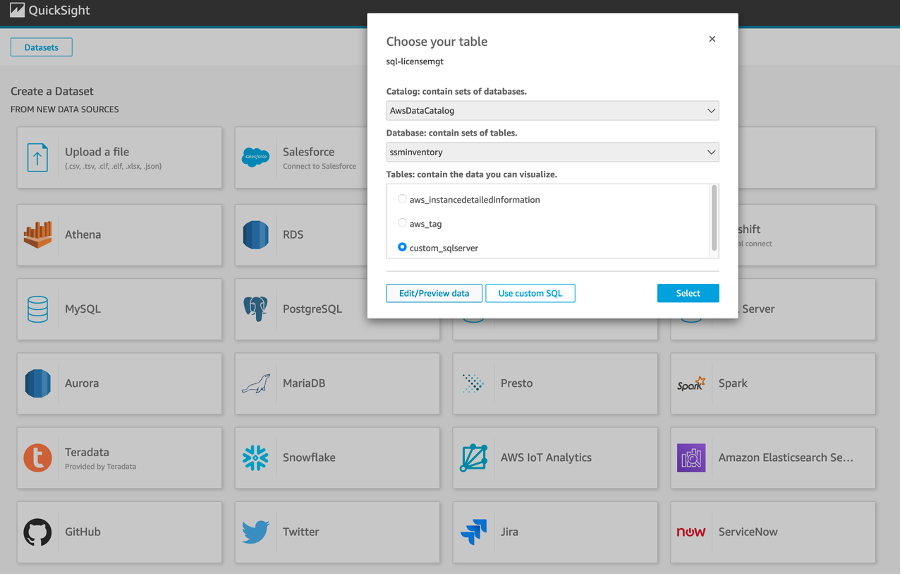
Figure 2: Creating a dataset in QuickSight
- In the editor view, choose Add data, and then select the other tables as shown in Figure 3.
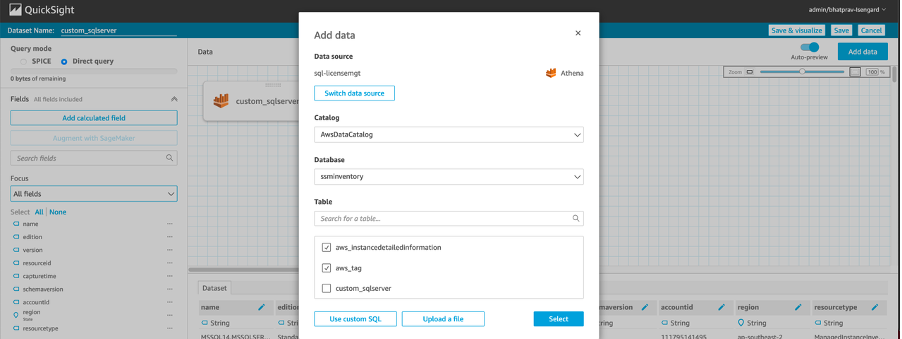
Figure 3: QuickSight dataset editor
- Update the join configuration using resourceid as the join clause, as shown in Figure 4.

Figure 4: Specifying the join configuration
- Before you apply the changes, exclude all duplicate fields and update the data types as shown in Figure 5.
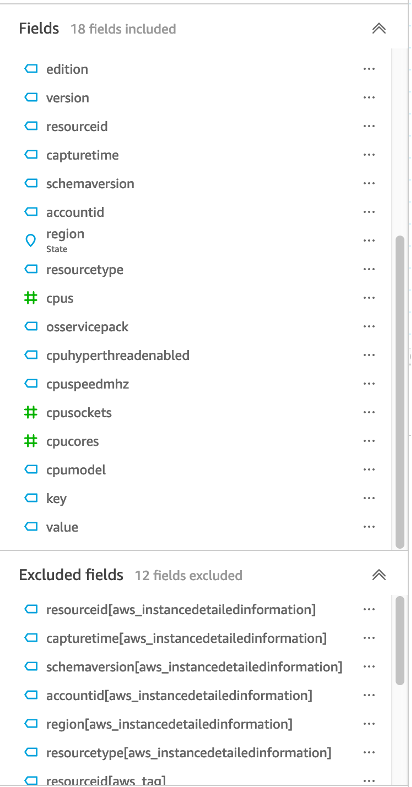
Figure 5: Excluded fields
You can use the dataset you just created to build your own analysis and create visualizations as shown in Figure 6. To stay informed about important changes in your data, you can create threshold alerts using KPI and Gauge visuals in an Amazon QuickSight dashboard. For information, see Working with Threshold Alerts in Amazon QuickSight. With these alerts, you can set thresholds for your data and be notified by email when your data crosses them.
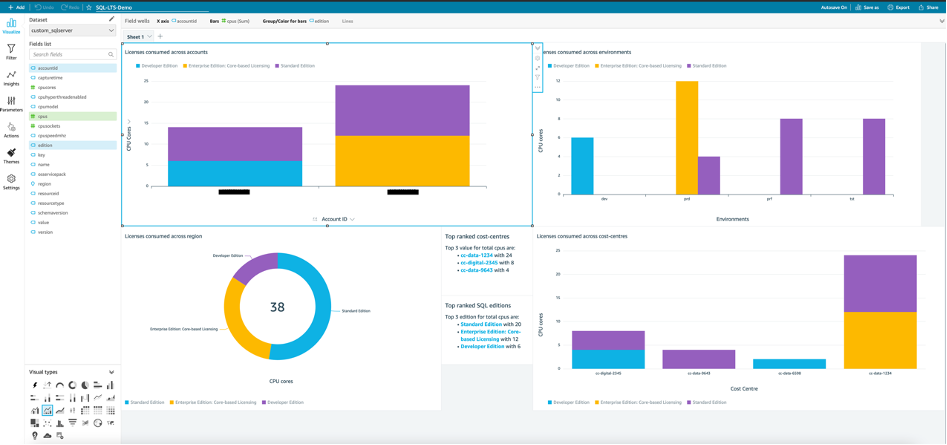
Figure 6: QuickSight analysis
Conclusion
In this two-part blog series, I showed how you can use AWS License Manager and AWS Systems Manager to automate the process of tracking your Microsoft SQL Server licenses across multiple accounts and Regions that are part of AWS Organizations. I also showed you how to use Amazon Athena and Amazon QuickSight to visualize the aggregated license consumption data across your AWS accounts. You can easily expand on the analysis and dashboards described in this post to meet your organization’s needs. With improved visibility of your license consumption across your organization, you can ensure you are compliant with your commercial licensing agreements and avoid steep penalties. Go to the documentation to learn more about AWS Organizations.