AWS Open Source Blog
How AWS and Grafana Labs are scaling Cortex for the cloud
This post was co-authored by Jérôme Decq, Richard Anton, and Tom Wilkie.
When we decided to offer a monitoring solution purpose-built for containers users, supporting Prometheus use-case patterns quickly became necessary. However, using Prometheus at cloud scale is difficult. We studied different architectures such as Prometheus plus a dedicated time series database, Thanos, and Cortex. Cortex quickly stood out as the most appropriate choice for long-term scalability in a multi-tenant environment, given its microservices design running on Kubernetes.
Cortex was started by Tom Wilkie and Julius Volz at Weaveworks, where it is part of their cloud platform. Grafana Labs, who partnered with us to launch AWS Managed Service for Prometheus, employs multiple Cortex maintainers, including Tom, and offer their own Grafana Cloud and Grafana Metric Enterprise services powered by Cortex. Cortex provides remote_write, remote_read, and PromQL query support, has 100% PromQL compatibility, recording rules, Alertmanager support, and is a CNCF project with a healthy community with numerous contributors.
In this post, we will cover some of the work we undertook with Grafana Labs on the path from design to implementation.
Cortex overview
Cortex is designed as a set of microservices that typically run in a Kubernetes cluster as illustrated in this diagram from the blocks storage documentation.
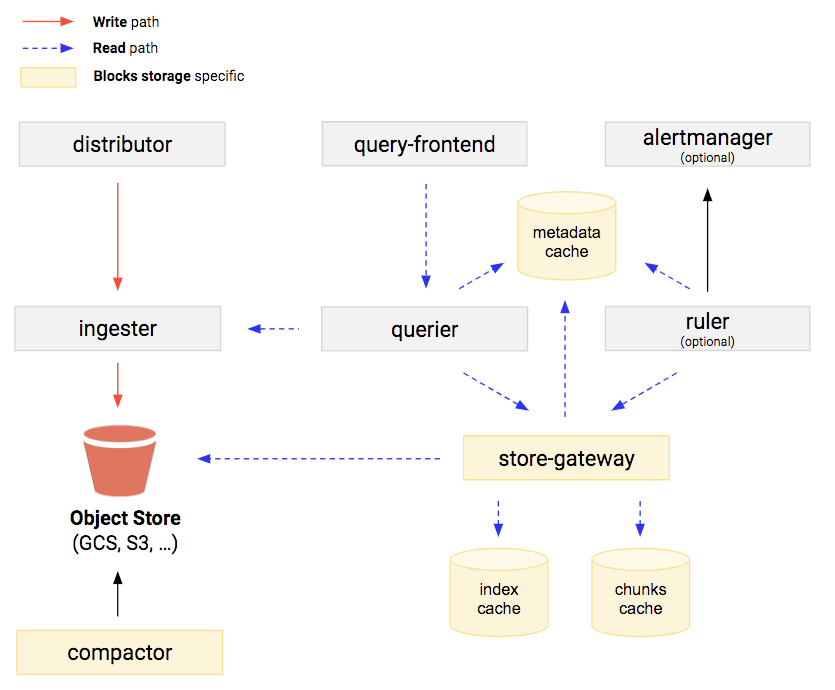
Cortex has an ingestion path from a distributor component to ingesters, which also provide short-term storage of time series sample data, backed by long-term storage on object storage systems.
The Cortex query path goes from the query frontend to the querier to the store-gateway and ingester. The ingesters are on both the ingestion and query path. The store-gateway handles efficient access to blocks storage. The query path utilizes multiple distributed memory caches (i.e., memcached) used by the query frontend and store-gateway.
The compactor runs asynchronously to compact time series database (TSDB) blocks for more efficient storage and query performance.
Performance tests and blocks storage
Because theory and practice don’t always match up, we decided to run a series of performance tests to assess how linearly Cortex could scale. This was particularly important because there are two different storage implementations: chunks storage and blocks storage. Each has its pros and cons.
The chunks storage engine, which was Cortex’s first iteration of backend storage, uses separate storage for index and time series chunk data, whereas blocks storage uses combined storage for time series data and index. Chunks storage does not work well with Amazon Simple Storage Service (Amazon S3) because the small object size of time series stores leads to a large number of S3 GET and PUT API calls needed, which slows the time to first byte. In practice, chunks storage on AWS uses Amazon DynamoDB for both index and time series. The newer iteration of Cortex storage is blocks storage, which is based on TSDB storage, the same blocks format as Prometheus’ own local TSDB store. Although it is partly based on preexisting shared code from Thanos, blocks storage was a relatively new feature of Cortex at the time, so we wanted to vet its reliability as well.
The main idea behind the performance tests was to generate as realistic a scenario as possible. Therefore, instead of using Avalanche to ingest metrics, we decided to run and monitor mock applications, modeled after a Kubernetes cluster with an ingress, a database, a cache, 7 services running on a 10-node cluster, and a traffic generator. For the query side, we based our scenario on popular Grafana dashboards. The actual details of the setup have been shared with the Cortex community, along with the results.
In the end, we selected the blocks storage backend, because it is more cost-efficient (about 40% less infrastructure resource) while delivering similar performance because it uses Amazon S3 more efficiently. Blocks storage also makes it easier to add functionality to individual Cortex tenants, such as per-customer encryption keys, data deletion on demand, custom retention settings, and tiered storage.
Early adjustments
The first iterations of the perf tests revealed a few details that we believed, if resolved, would improve Cortex for all. As a relative newcomer to the Cortex community, we wanted to be sensitive in how we engaged, so we collaborated closely with Cortex committers and maintainers, including Grafana Labs engineers, to report and submit pull requests for the following issues.
First, we confirmed the impact of an open Thanos issue when using the service account AWS Identity and Access Management (IAM) role (the store gateway response times are slow), and resolved this with the help of Grafana Labs. We identified and fixed an issue where the number of S3 uploads was proportionate to the square of the number of tenants in the cluster—in other words, O(n2) where n is tenant count—due to sub-optimal distribution in the ingester subring. We identified a memory leak in ingesters, eventually resolved with the help of the TSDB maintainer on the Grafana Labs team. We added additional gRPC stats to provide better visibility in query behavior. We also related excessive memory usage in the ingesters due to loading idle TSDB files, which required the fix to close TSDB and delete local data when TSDB is idle for a long time.
The tests also revealed the need to implement shuffle sharding for better tenant isolation, to improve query front-end scalability, and to improve resiliency to partition unavailability (a.k.a., an outage in a single Availability Zone [AZ]). Again, because we were relatively new to the Cortex community, we partnered with Grafana Labs engineers to suggest these improvements to the Cortex open source community.
Shuffle sharding
Shuffle sharding is something we use at AWS, and our implementation in several AWS services led us to believe it might be helpful for Cortex. This work is based on Amazon’s Shuffle Sharding article, and the algorithm was inspired by the shuffle sharding implementation in the AWS Route53 Infima library. Grafana Labs built a reference implementation of the proposed algorithm to test the following properties: tenant stability, consistency, shuffling, and fair balance between zones. In particular, we’ve observed that the actual distribution of matching instances between different tenants is close to the theoretical one. Given 2 tenants with 52 instances and each tenant sharded onto 4 instances, the probability is 73%+ of 0 or 1 instances overlapping between 2 tenants, and 93%+ for 2 or fewer instances overlapping.

An additional design proposed for shuffle sharding on the query path was also implemented (PR 3252).
The final implementation required caching of shuffle-sharded subrings and was introduced at several different levels: the ingesters, the queriers in the query frontend, the store gateways in the queriers, the store gateways, the ingesters in the queriers, and the ruler.
AWS validated the design and implementation, and engaged with Grafana Labs on the few bugs introduced by the shuffle sharding, such as global limits not applied correctly.
Along the way, a few performance improvements were added, such as batch series in streaming ingester based on message size. AWS also migrated Cortex CI/CD from CircleCI to GitHub Actions; for more on this, see Migrating Cortex CI/CD workflows to GitHub Actions.
Grafana Labs developed a simulator to model different settings of shard size per tenant, leading to the following recommendation—shardsize = Replication Factor * TimeSeriesCount / 20000—as the optimal strategy to balance the competing expectations of load balancing efficiency and tenant isolation.
Query frontend scalability
Originally, the query frontend was designed to be run as a pair of replicas to prevent the “convoy effect” from having many round-robined queues. More recently, the bound on the number of replicas was increased through analysis, to be equal to the max parallelism of a single querier (by default max_concurrent: 20, but in practical terms Grafana Lab advises setting this lower). In practice this means that you can run 4–8 query frontends.
Query frontend scalability can become a bottleneck, for example when users run queries that return excessive volumes of JSON due to serialization/deserialization and network IO.
We decided to split the control and data path, and split the queue off to a separate service. This improvement can be found in PR 3374 by Grafana Labs.
In the first phase, the query scheduler was split out from the query frontend so that the query frontend can scale horizontally without causing problems with the scheduling logic, and all queriers connect to all schedulers. In the second phase of this change, we will place a cap on the number of schedulers that each querier connects to. At this point, we will be able to horizontally scale the query scheduler above the querier concurrency, and the query scheduler should be “infinitely” scalable.
Based on the existing proposal, a prerequisite will need to be addressed: The readiness of the query frontend component will need to be adjusted to return 200 only when the frontend is ready to receive requests.
Zone awareness
Another AWS customer expectation is that managed services should be resilient to an AZ outage. We therefore needed Cortex to be zone-aware, and to add topology-aware read. We made other changes to better support zone awareness on the ingestion path (PR 3299).
Conclusion
We are excited about the improvements to Cortex’s scalability so far, and by how well the partnership with Grafana Labs has worked toward this end. To further improve scalability, we need the second phase of the Query Frontend Scalability project, which will increase the scalability of the query scheduling component. Important work also is underway to introduce a per-tenant bucket index for blocks storage to improve the performance of Cortex blocks storage clusters with many tenants.
Next steps
- Better scalability of Compactor component to support very large tenants.
- Better observability and operational tooling, such as recent work in improving troubleshooting options for memberlist status. Cortex supports multiple options for handling its distributed hash ring, but we are using the memberlist-based implementation built on a gossip protocol, such as PR 3575 and PR 3581.
- One advantage of blocks storage over chunks storage is to allow for a straightforward deletion of tenant data; however, this feature is currently missing from Cortex and will come through the introduction of a new API.
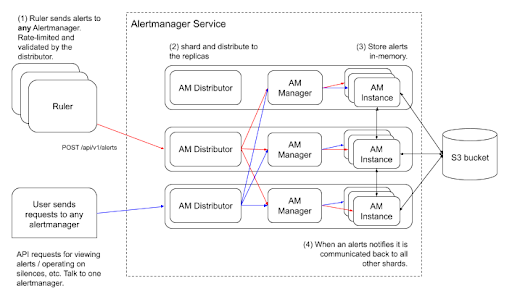
- Alertmanager changes to introduce sharding (proposal) for horizontal scalability. This is the newly proposed architecture:

Tom Wilkie
Tom is VP Product at Grafana Labs, but really he is a software engineer. Tom is a maintainer on the Prometheus project and a maintainer and the original author of Cortex, both CNCF projects. Previously Tom founded Kausal, a company working on Prometheus, and worked at companies such as Google, Acunu, and XenSource. In his spare time, Tom likes to make craft beer and build 3D printers.