AWS Open Source Blog
Ogury Uses Open Source Technologies on AWS to Run Low-Latency Machine Learning
This post was contributed by Thomas Ngue Minkeng, Nathalie Au, Marc Bouffard, and Pierre-Marie Airiau from Ogury
Ogury, the Personified Advertising company, is using open source machine learning (ML) on AWS to deliver a planned 300,000 inferences per second under 10-ms latency. Ogury’s breakthrough advertising engine delivers precision, sustainability, and privacy protection within one technology stack and is built and optimized for mobile. Advertisers working with Ogury benefit from fully visible impactful advertisements, future-proof targeting, and unwavering protection. Publishers enjoy the rewards of a respectful user experience, incremental revenues, and premium demand with Ogury’s solutions. Founded in 2014, Ogury is a global organization with 350+ employees, including 100 engineers across 11 countries. Ogury has been using the AWS cloud for more than 6 years and already presented their experience in a past AWS case study.
The challenges
To serve the right advertisement at the right time, Ogury is considering using ML to estimate click probabilities associated to advertising campaigns. While it is straightforward to research and develop standalone ML models on small-size datasets, it is more challenging to deploy ML features in an existing large-scale production application. In particular, Ogury highlights the following challenges:
- The latency budget for scoring is tight: An ad bid request must be answered within tens of milliseconds, including less than 10 ms for campaign scoring, which contains up to 50 campaigns to evaluate.
- Scale is an additional challenge: Thousands of campaign scoring requests occur per second, and the ML inference solution must be able to scale to and hold this amount of traffic.
- Integration must also be possible with the rest of the ad serving stack. In particular, Ogury needs the ML inference to be callable in a Node.js application.
The solution
The rest of the blog describes the technologies and architecture that enable Ogury to serve hundreds of thousands of predictions per second by their ad scoring model.
Model representation and runtime with ONNX
To model ad conversion patterns, Ogury engineers train a logistic regression model with Apache Spark on Amazon EMR. Apache Spark is a broadly adopted open source framework for distributed batch and streaming computation. At the time of this writing, Spark however has limited support for synchronous, real-time inference on small payloads. For example, it does not have a native inference compiler nor model server, and often needs to be complemented with third-party specialized components, such as MLeap for model serialization and Springboot for request handling.
To run fast prediction on Spark models, Ogury looked for technologies that would optimize the model for low-latency inference while providing a Javascript client to interface with their Node.js backend. The team found Microsoft-developed ONNXRuntime well suited to this task. ONNXRuntime is a cross-platform open source library for ML optimization that can speed-up both training and inference. In particular, ONNXRuntime accelerates inference by rearranging the model graph and leveraging relevant kernels and accelerators available in the inferencing hardware. The Ogury team was able to easily leverage ONNXRuntime via its JavaScript library, ONNX.js (now named ONNXRuntime Web). However, running a loop of single-record predictions did not fit within the latency budget. Consequently, the team brought additional optimizations.
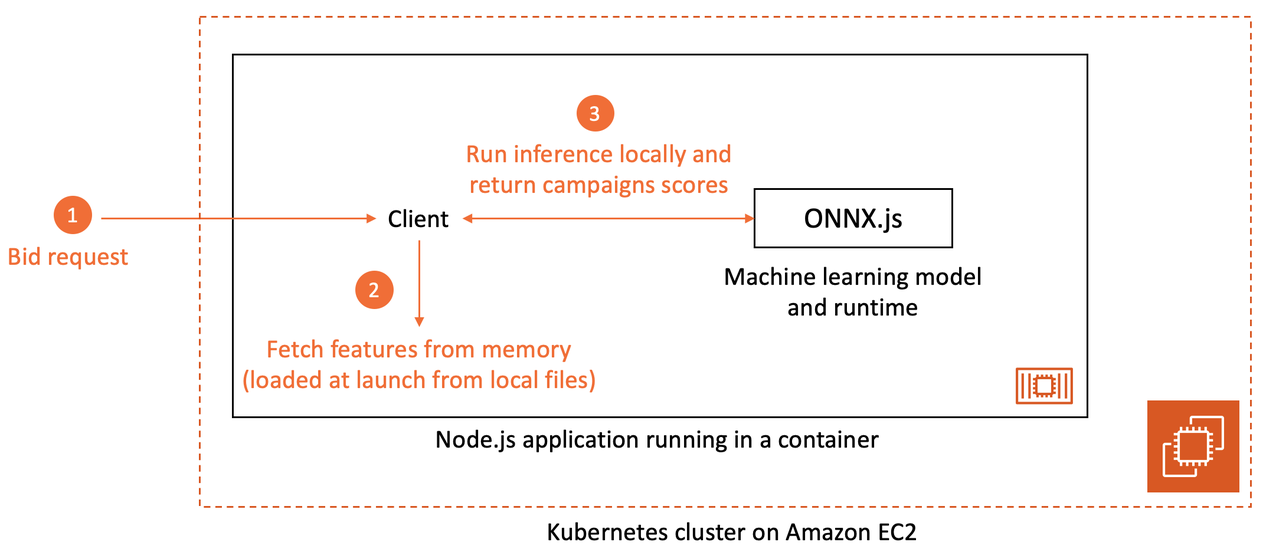
Architecture diagram of the open source ML inference solution
Client-side batching
To reduce the orchestration overhead and let ONNXRuntime leverage parallelism where possible, the team tested client-side batching: Instead of inferring a batch of 50 campaigns with a loop, the client submits an input matrix consisting of a batch of 50 campaigns. This optimization reduces inference latency by 75%, from 40 ms to 10 ms at P95.
Feature fetching with a Node object
Machine learning models learn to model a pattern between an input and a target output. Available input features are necessary to produce predictions on fresh data. To maintain low latency, the Ogury team exposes a local read-only feature store on the client side, from which the Node application builds an input record. Fetching the features from local files must be fast, and the team found that the fastest performance is obtained when the features were represented and accessed via a regular Object instead of an ES6 Map. Indeed, creating plain JavaScript Object and accessing Object’s property with a specific key is faster than creating a map and using it.
Burning the model in the client application
In real-time inference use cases, it is common to architect ML models as standalone representational state transfer (REST) services, with their own compute fleets and web application programming interfaces (APIs). Machine learning models served as microservices have the benefit of enabling modular architectures with clean separation of concerns. In this specific use case however, the Ogury team prioritizes ML inference latency and is ready to make concession on modularity for the sake of minimizing latency. The team deploys the model in the same container as the consuming application. Consequently, traditional ML web serving overhead—including network travel time, serialization, and request handling—is completely suppressed and several extra milliseconds gained.
Deployment on AWS and Next Steps
The ML model will receive several thousand batches per second, representing hundreds of thousands of predictions realized per second. To scale to such a magnitude while maintaining infrastructure management overhead low, Ogury is using self-managed Kubernetes cluster on Amazon Elastic Compute Cloud (Amazon EC2) on which over 300 Kubernetes pods will be deployed at peak. This setup achieves a satisfying performance. As a next step, Ogury will iterate on model science to increase the business value delivered to their customers.
Advertising is rich with ML use cases, and Ogury is evaluating AWS services for several other projects. If you are also interested in running ML projects on AWS or deploying open source technology at scale on AWS, please take a look at our AWS Machine Learning and AWS Open Source pages.

Thomas Ngue Minkeng
Thomas is a Data Engineer with a background in Business Intelligence. At Ogury he focuses on industrializing data science models/algorithms for online service and building data pipelines for Ad Delivery monitoring and experiments.

Nathalie Au
Nathalie Au is Senior Data Scientist in the Ad Choice team at Ogury. She is designing, building and industrializing machine learning solutions in order to improve Ogury algorithms. She loves to travel all around the world and has already visited Argentina among many other countries.

Marc Bouffard
Marc Bouffard is a Data Scientist in the Data Performance Team at Ogury. He is working, among other topics, on finding new ways to characterize users. He is interested in Natural Language Processing and Unsupervised Learning.

Pierre-Marie Airiau
Pierre-Marie Airiau is in charge of defining the algorithmic approaches used by the delivery system at Ogury, where he worked in the past on a variety of other subjects. He focuses mainly on the interactions between the predictive systems and the decisional ones, and the way they can work in couple to build powerful reinforcement learning automates.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.