AWS Physical AI Blog
Putting Dexterous Robots to Work: How RLWRLD Builds Physical AI with AWS
For robots to see, understand, and physically handle objects in human-centered work environments, they need to learn from real operational settings, not just controlled lab demonstrations. RLWRLD, a Physical AI company founded in 2024, is building RLDX, a robotics foundation model designed to train on real-world industrial data and enable robots to perform dexterous manipulation tasks with human-like five-finger hands.
In this post, we show how RLWRLD uses AWS compute and high-performance storage to train RLDX and how the team combines Amazon Elastic Compute Cloud (Amazon EC2) instances with NVIDIA H200 GPUs, AWS ParallelCluster for distributed training orchestration, and Amazon FSx for Lustre for high-speed data access, processing hundreds of terabytes of real-world robot data collected from actual factory and service floors.
The opportunity: Dexterity demands real-world data at scale
The last mile of industrial automation is the human hand. Even at today’s frontier of robotics, McKinsey estimates that robot-capable tasks account for only 13% of U.S. work hours, as most physical work still demands fine motor skills, dexterity, and situational awareness that technology cannot yet replicate reliably. Robots long ago mastered simple repeatability, but not dexterity, often cited as one of the hardest unsolved problems in robotics.
Through deployments and direct customer feedback, RLWRLD has found that real worksite workflows demand precise tasks that parallel grippers — or even three-finger hands — simply cannot perform without redesigning the entire business process around them. Five-finger dexterity is a hard requirement, not a nice-to-have. Solving this means training a single foundation model on real-world skill data captured on actual factory and service floors.
RLWRLD’s engagements begin with RX (Robotics Transformation), its on-site assessment program: before any data is collected at scale, an RX team goes into the actual worksite to film the work, break it down task by task, and score where human-like dexterity is the real bottleneck — turning a vague “automate this site” into a concrete, ROI-ranked map of where dexterity data is worth capturing.
From that diagnosis, RLWRLD identifies the specific dexterity gaps where intervention will have the greatest impact, then moves into execution through Robotics Deployment (RD) – taking solutions from proof-of-concept all the way to production deployment. This end-to-end commitment, from assessment to live operation, has been the foundation for deep partnerships with conglomerates across Korea and Japan, two of the world’s most robotics-intensive markets, with expansion now underway in the US and Europe. These partnerships also allow RLWRLD to gather new data generated through each collaboration and shared under mutual agreement, flowing directly back into the foundation model and forging a compounding flywheel in which every deployment makes the next model smarter.
As this approach is demanding on infrastructure, it requires two things at once: large volumes of high-quality data from real robots and human work, and the large-scale GPU compute needed to run training and simulation over days or weeks. RLWRLD collects data across multiple tracks, including teleoperation and high-precision multi-camera capture feeding its 4D+ (spatial, temporal, and physics interaction) pipeline, with a training dataset that reaches hundreds of terabytes. Feeding data of this size to GPUs quickly, while running large model training reliably over long periods, demands purpose-built infrastructure. Training inside real enterprise sites, not lab mockups, means RLDX is validated against the messiness of genuine commercial operations from day one.
The Solution: Training RLDX- 1 on AWS
RLDX is RLWRLD’s robot foundation model family, and RLDX-1 is their first model, publicly launched in May 2026 — an 8.1B-parameter, open-source foundation model that fuses vision-language understanding with proprioception, tactile, and torque sensing. It ships hardware-agnostic, supporting single-arm, dual-arm, and humanoid embodiments with five-finger dexterity, and introduces pluggable feature modules (motion, memory, and physics) that sharpen task performance without sacrificing generality. On public simulation benchmarks, it achieves state-of-the-art results across RoboCasa, LIBERO, and SIMPLER.
AWS plays a central role in RLWRLD’s training stack, powering core stages from large-scale data storage to distributed GPU training. Three design principles set RLDX-1 apart:
- Five-finger dexterity. RLDX-1 targets true five-fingered, human-like hand manipulation for the fine, contact-rich tasks that real industry work demands.
- Hardware-agnostic. The same model adapts to many robot bodies and hand types with only fine-tuning, no platform lock-in.
- 4D+ data pipeline. RLWRLD centers its work on a rich 4D+ data pipeline, from real-world teleoperation data to synthetic robot data and real human-hand data capturing spatial, temporal, and physics interaction, to teach the model how the physical world actually moves and behaves.
The following diagram shows the overall training and deployment pipeline.
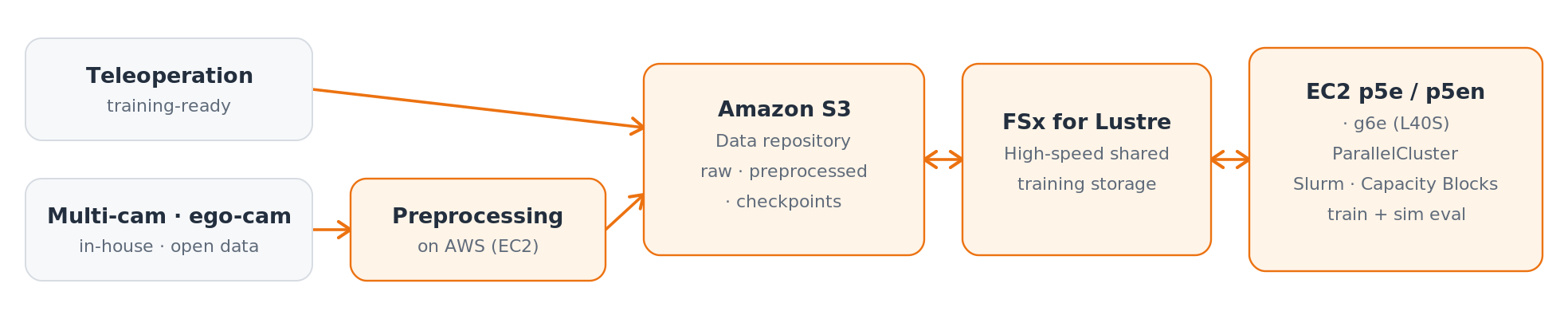
Figure 1: Teleoperation data is training-ready; multi-camera / ego-camera datasets are preprocessed on AWS first. Amazon S3 and Amazon FSx for Lustre stay in sync as the data repository, and datasets and checkpoints move between Lustre and the cluster.
Compute
RLWRLD relies on Amazon EC2 p5e and p5en instances, each equipped with eight NVIDIA H200 GPUs, for model training and uses Amazon EC2 g6e instances (powered by NVIDIA L40S GPUs) for simulation evaluation. GPU availability for planned training runs is secured through Amazon EC2 Capacity Blocks for ML, which guarantee access to high-performance instances on a defined schedule. The broad AWS GPU portfolio matters here: g6e capacity is readily available for evaluation workloads, and high-performance GPUs are reserved in a planned way for training.
Distributed training
Training is orchestrated with AWS ParallelCluster. Because the team can keep using the Slurm scheduler it already knows, RLWRLD moved existing training workflows to the cloud with minimal changes. The cluster scales to the needs of each training stage; pre-training, mid-training, and post-training each call for a different node count, so capacity matches the workload at hand.
Data pipeline and storage
Teleoperation data feeds training as soon as it is collected, while multi-camera and egocentric datasets, both in-house and open, are preprocessed on AWS before entering the training set. Storage is split by role:
- Amazon Simple Storage Service (Amazon S3) serves as the durable repository for original datasets, preprocessed data, and model checkpoints.
- Amazon FSx for Lustre provides the high-speed shared file system that many GPU nodes read from concurrently during training.
Datasets and checkpoints move between Amazon FSx for Lustre and the cluster as training runs progress, with Amazon S3 and Amazon FSx for Lustre staying in sync. RLWRLD co-designs its training and data architecture with AWS solutions architects.
Benchmark results
RLDX-1 achieves state-of-the-art performance across major simulation benchmark platforms, including RoboCasa, LIBERO, and SIMPLER, using approximately 20% of the training compute of comparable frontier models, according to RLWRLD’s published benchmarks. This efficiency comes from its architecture and data engine rather than sheer scale. On SIMPLER Google-VM, RLDX-1 reaches 81.5% success rate; on RoboCasa GR-1 Tabletop, 58.7%, outperforming the next-best frontier model by up to 18%.
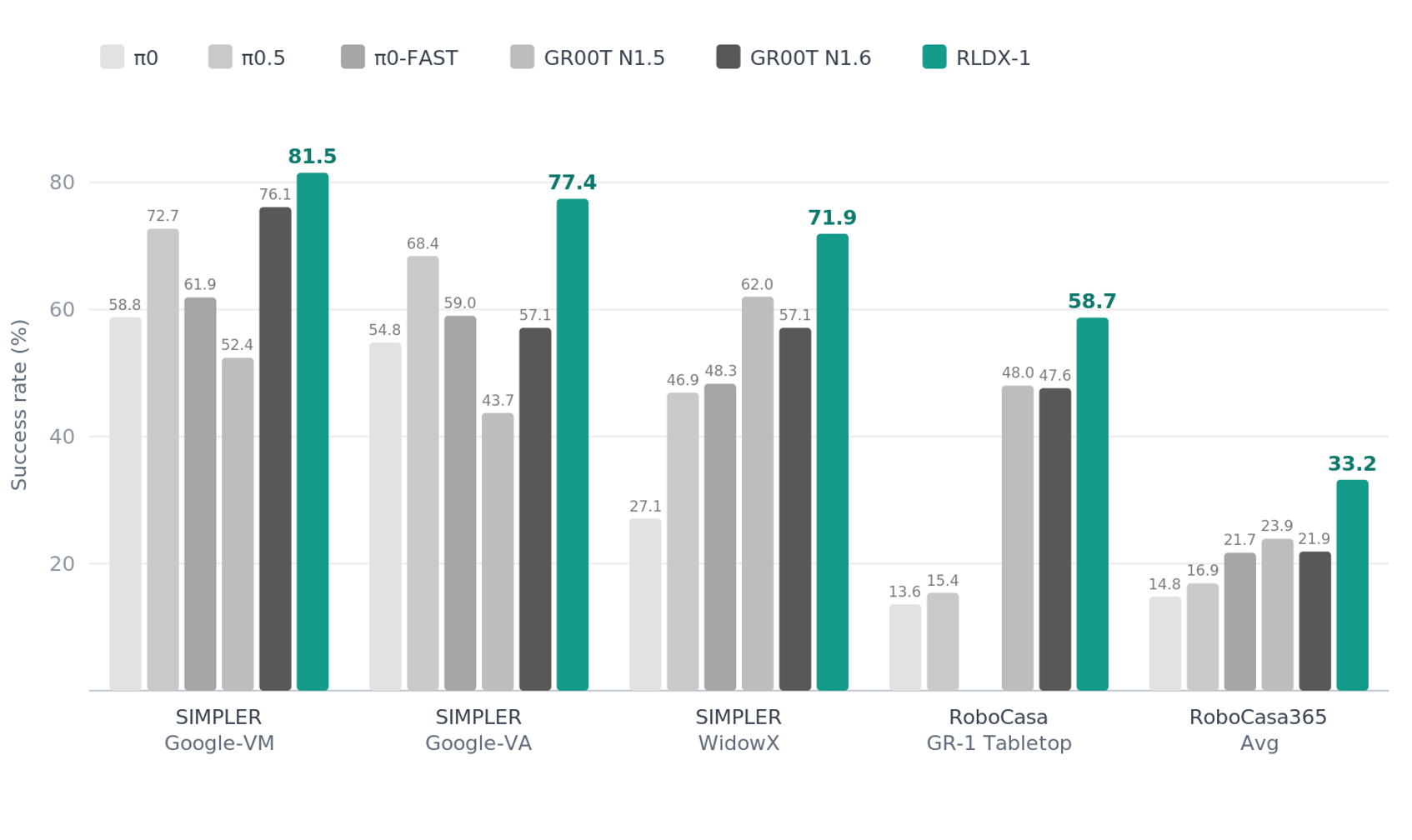
Figure 2: Public benchmark – RLDX-1 vs. comparable frontier robotics foundation models – success rate (%); higher is better. Source: RLWRLD, May 2026. All results use published benchmark protocols. Third-party model results sourced from their respective published papers and model cards.
Deployment in action: Capturing five-star service skills at LOTTE HOTEL & RESORT
LOTTE HOTEL & RESORT is South Korea’s largest hotel group, running flagship five-star properties across the country and abroad. Like many operators in the region, LOTTE HOTEL & RESORT faces a growing workforce challenge: South Korea crossed the “super-aged” threshold in 2025, with more than 20% of the population aged 65 or older, as the working-age population contracts. For operations as labor-intensive as a luxury hotel’s, securing enough skilled workers in the years ahead is a pressing concern.
To pinpoint where robots could realistically augment hotel operations, RLWRLD ran RX across LOTTE HOTEL & RESORT’s food and beverage, banquet, and housekeeping operations. The team filmed and decomposed the work into roughly 40+ job groups, 400+ tasks, and 4,500+ atomic actions, scoring each for difficulty and automation potential, and surfacing the fine, contact-rich tasks (folding linens, handling delicate glassware, plating and serving) where five-finger dexterity, not a two- or three-finger gripper, is the real requirement.
That assessment is now turning into data. At LOTTE HOTEL & RESORT in Seoul, staff periodically become teachers: wearing body cameras on the head, chest, and hands, each precise hand motion is captured on the actual service floor, not in a lab, and streamed into RLWRLD’s 4D+ data pipeline, building a library of real human skill that teaches RLDX’s five-finger dexterous hands to replicate the human touch these tasks demand. LOTTE HOTEL & RESORT has assigned RLWRLD a dedicated on-site space for this work and is in discussion for a multi-year data partnership, making the property a standing source of real service-skill data.
RLWRLD and LOTTE HOTEL & RESORT are now developing RLDX toward full-scale deployment in live hotel operations, aiming for 2030, subject to successful safety validation and operational testing. Based on the RX assessment, RLWRLD estimates that a humanoid could take on approximately 30–40% of repetitive, physically demanding work, freeing staff to spend more time with guests. Because RLDX is a hardware-agnostic foundation model, the dexterity learned at LOTTE HOTEL & RESORT becomes part of a model that transfers beyond hospitality, to customers across Korea and Japan, including logistics work at CJ Group, retail handling at Japan’s Lawson convenience stores, and assembly tasks at global automotive manufacturers.
AWS Services Used
| Service | How RLWRLD uses it |
|---|---|
| Amazon EC2 | Secure, resizable compute. RLWRLD runs large-scale model training on p5e and p5en instances (NVIDIA H200 GPUs) reserved via Capacity Blocks for ML, and g6e instances (NVIDIA L40S GPUs) for simulation evaluation. |
| AWS ParallelCluster | Provisions and manages Slurm-based HPC clusters for large-scale distributed training across multiple GPU nodes. |
| Amazon S3 | Durable object storage for original datasets, preprocessed data, and model checkpoints. |
| Amazon FSx for Lustre | High-performance shared file system accessed concurrently by many training nodes, feeding datasets to GPUs at high speed. |
What’s next
RLWRLD and AWS are deepening the collaboration across the full robotics lifecycle, from training to fleet deployment and cloud-based inference. RLDX-1 is open source today: read the tech report on arXiv, explore the code on GitHub, and download checkpoints on Hugging Face.
To learn how to run robotics and Physical AI workloads on AWS, explore Amazon EC2 accelerated computing or connect with your AWS account team. To learn more about RLWRLD, visit rlwrld.ai.