AWS Web3 Blog
Building a blockchain indexer on AWS
Decentralized finance (DeFi) trading decisions require blockchain pricing and liquidity data. However, direct blockchain node queries are inefficient and resource-intensive creating a bottleneck for timely decision-making. Blockchains are not optimized for efficient data queries, with data being stored sequentially (block by block). Retrieving specific information often requires scanning the entire blockchain.
Indexers offer a solution to this problem. Indexers monitor new blocks and transactions and can be architected to store data in optimized secondary databases (like relational databases). These databases include indexes for direct access which applications can query directly. Indexers offer the benefit of faster response times compared to direct blockchain queries, and enhanced user experience for DeFi applications with efficient access to historical and current blockchain data.
While blockchain indexers are widely available, custom indexers built on AWS may be necessary when existing solutions don’t support your blockchain or required data. This blog describes the critical role and architecture of blockchain indexers that transforms blockchain’s sequential data structure into an efficiently query-able format for DeFi applications. This post provides architecture guidance to build a blockchain indexer on AWS.
Indexing modes
The blockchain indexer has two different modes, which are bound by different sets of requirements:
- Back filling – On initial startup, the indexer processes all historical blocks from genesis to the current head using parallel processes to maximize ingestion speed. Since blockchain data is immutable, chain reorganizations don’t require consideration during backfill.
- Forward filling – In this mode, the indexer ingests new blocks immediately upon discovery. However, blockchain tip changes from reorgs can invalidate previous blocks, requiring mechanisms to ensure the secondary data store remains consistent with the actual blockchain data.
Solution overview
If indexers extract directly from the blockchain node and if transformation logic changes, they must re-index the entire blockchain (and this is time-consuming). Instead, we propose a single extraction followed by multiple transformations: extract once, transform and load as needed. We create an intermediary storage layer which stores the blockchain data, allowing transformers to operate on local copies rather than querying the node repeatedly. The following image shows the high-level components of the indexer:
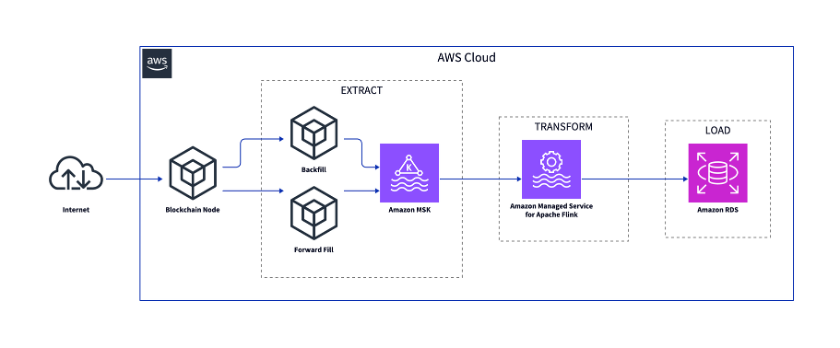
The blockchain node is connected to the Ethereum blockchain. The back fill and the forward fill components retrieve data from the blockchain node. After extraction, the data is loaded to the intermediary storage in Amazon Managed Streaming for Apache Kafka (Amazon MSK). The data is transformed with Amazon Managed Service for Apache Flink and loaded to a database like Amazon Relational Database Service (Amazon RDS).
In the following sections, we discus the extract, transform, and load (ETL) process in more detail.
Extract
The blockchain node is the gateway to the blockchain itself. It holds a local copy of all blocks and receives new ones as they are propagated through the blockchain network. The blockchain node can be queried using standardized JSON-RPC calls.
Blockchain indexing requires either a full node or an archive node. Full nodes retain all transactions but prune historical state data, while archive nodes retain complete state history. Our proposed architecture assumes an archive node since using a full node will require us to verify it contains all necessary data.
Back filling
The first step of the data ingestion is the back filling of data from the start of the blockchain (its genesis block) up to the current head of the chain. This back filling component processes historical blocks, extracts the relevant data, and pushes them to an Apache Kafka topic. Amazon MSK acts as intermediary storage. It can hold data and have several independent consumers process the data. For this example, we’ll use three different topics: blocks, transactions, and logs, which hold the respective data.
In theory, the back filling component needs to run only once when the indexer starts from scratch. After it has ingested all historical data, only the forward filling components are required to keep the Kafka topics in sync with the head of the chain.
However, there might be various reasons why the back filling component needs to run again: some data might have been missed initially, changes to data schema in the destination chains, or bugs in the ETL logic that have been fixed. Because of the potential need to re-run the back filling component, we put some emphasis on making it fast.
The general architecture for the back filling component looks like the following diagram:
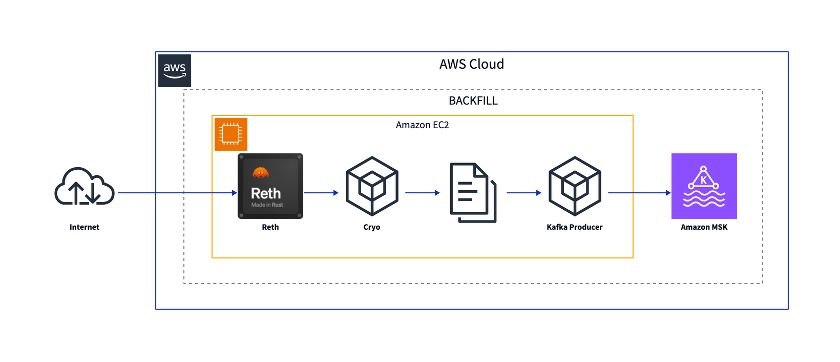
For data extraction, we use an open source extraction engine cryo, developed by Paradigm. It extracts data from a blockchain node using parallel RPC calls and stores them as local files which can then be pushed to Kafka topics.
During back filling, the indexer will send queries to the blockchain node. We recommend using a dedicated node to avoid getting throttled and ensure response to queries. To reduce network latency, we recommend placing this node near the indexer. In the example architecture, we are using a single Amazon Elastic Cloud Compute (Amazon EC2) instance to both host the node and run the indexing logic.
Forward filling
After backfilling, the indexer switches to forward filling mode. The front filling runs continuously and sequentially, monitoring the node for new blocks. This component performs two functions: 1/ monitors the blockchain node and ingests new blocks as they arrive, and 2/ stays aware of block reorganization (reorg). Since many block builders are creating new blocks simultaneously, a minted block can become invalid (if there is a longer fork of the chain). An indexer must be reorg aware: if a block reorg happens, it needs to trace back to the origin of the fork. Block reorgs are detected by verifying that: 1/ each new block contains the hash of the previous block, and 2/ block numbers increase sequentially. If either condition fails, a reorg has occurred, and the indexer must rewind to the last block before the fork.
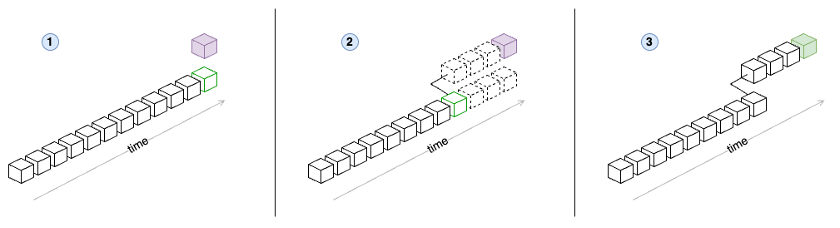
The workflow has three steps (illustrated in the diagram above):
- A new block (purple) appears that doesn’t follow the current canonical head (green).
- The indexer rewinds from the new block to the common ancestor (green).
- The indexer deletes the previously stored blocks up to the common ancestor. The indexer ingests the new blocks from the new canonical branch.
The following diagram illustrates the architecture of the forward filling component. It relies on the blockchain node’s capability to process re-orgs correctly.
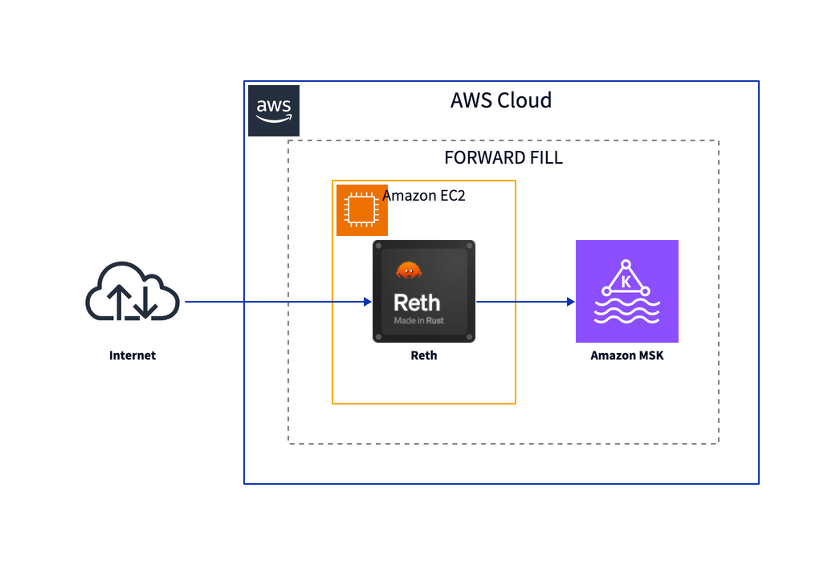
To achieve this, we use the Reth client’s Execution Extensions (ExEx) feature. The client notifies the ExEx of each new block (and reorgs), and the ExEx can send the data to a custom sink. To handle reorgs, the ExEx pushes both the reverts and the newly committed blocks to Kafka. The Kafka topics store these blocks sequentially, and then the transformation logic runs to update or remove data from the final data sink.
Transform
With Apache Flink, we can then run consumers on the Kafka topics which filter and transform the data. Flink applications are written in Java which is well suited to apply filters and perform transformations to the data. It can perform filtering for specific smart contracts either by address or decoding event data. The transformed data can then be stored as Kafka topics again, databases such as Amazon RDS, or files on Amazon Simple Storage Service (Amazon S3).
It is important to note that the consumers don’t modify the original data. When a change occurs in the transformation logic, it will only require restarting the consumer to re-index from the first Kafka messages and doesn’t need to go back to the node itself. Depending on how the data is structured, multiple consumers can potentially run in parallel.
Load
The consumers can load the data to a custom sink. For the Uniswap example, we store the data in a custom PostgreSQL table. A frontend can then query the table to get the right data. The final architecture of the full solution is represented in the following diagram:
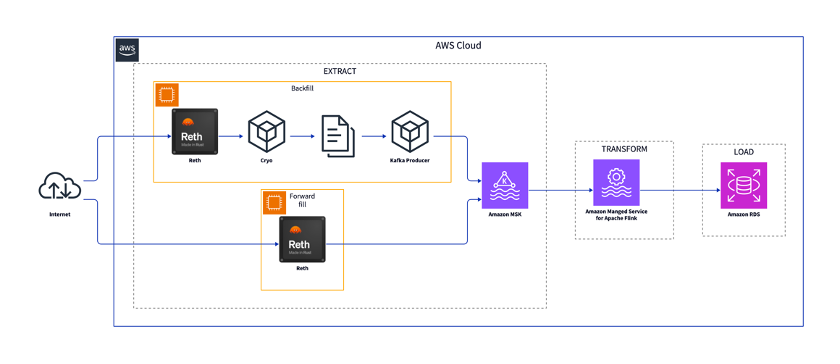
Conclusion
Our AWS-based blockchain indexer delivers optimized data access through unidirectional data flow and separation of extraction from transformation processes. This architecture enables efficient historical data processing via backfilling while maintaining real-time data consistency through forward filling with reorg awareness. The solution leverages AWS services including MSK, Managed Flink, and RDS to create a scalable, reliable foundation that transforms blockchain’s sequential structure into efficiently query-able formats. By deploying this solution, developers can unlock valuable blockchain insights while avoiding the performance limitations of direct node queries.
Learn more
To deploy this solution yourself, follow the detailed deployment guide on GitHub. For the demo of the indexer, we use the reth execution client with an archive node by default and provides a way to stream data to custom sinks, which will be uses for the forward filling process. The solution extracts historical data efficiently using cryo for backfilling, captures real-time data through a custom reth ExEx, processes and transforms this data using Flink, and stores structured data in a relational database for analysis. This solution provides a reliable foundation for blockchain indexing and analytics that can handle the scale and complexity of on-chain data, helping you to derive valuable insights from blockchain data.
To extend it, consider the following:
- Adding more Flink applications for different protocols or tokens
- Implementing data visualization dashboards
- Setting up alerts for specific on-chain events
- Integrating with machine learning models for predictive analytics