解决方案概述
随着人们生活水平的逐步提高,对于生活环境的标准也日益提高。近年来,利用传感器、物联网技术,实现空气污染指数采集,并进行空气污染指数预报的技术已经日趋成熟。
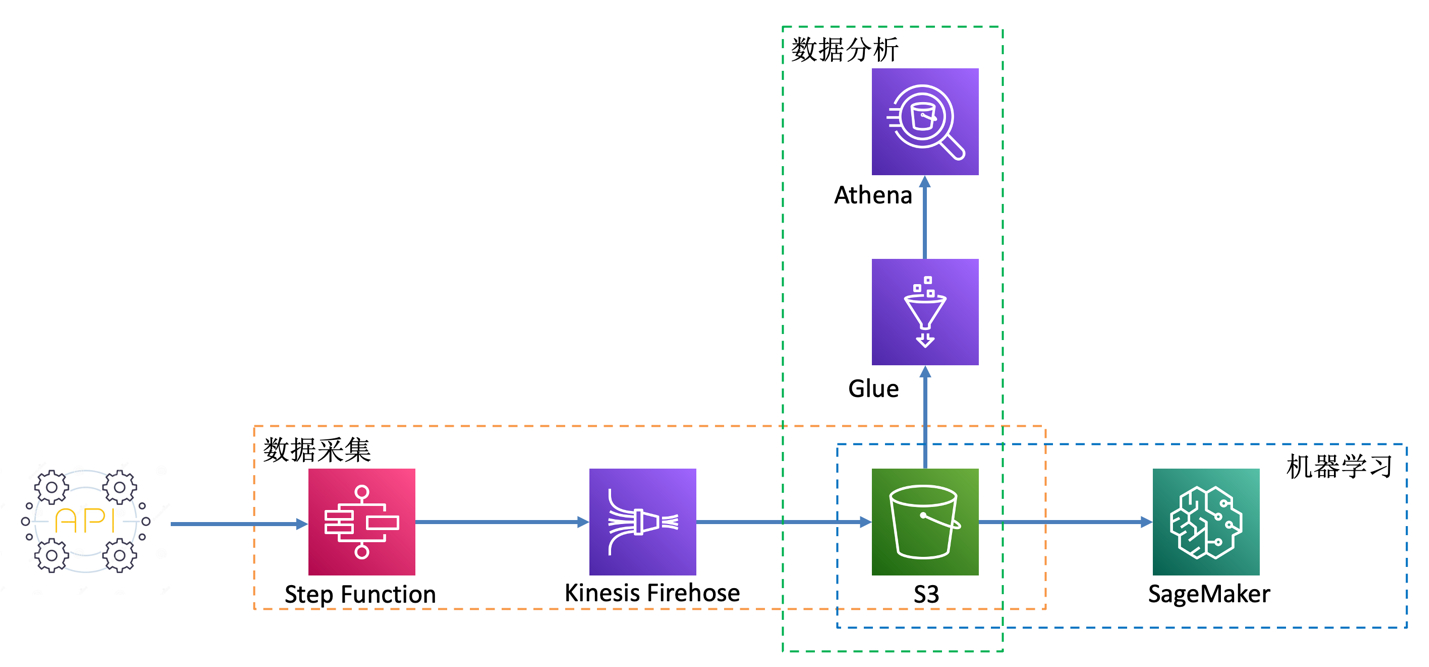
本文以伦敦空气质量数据集为例,为各位读者介绍一种基于亚马逊云科技服务快速实现空气质量数据采集,数据清洗,并进行预测的解决方案。总体方案拓扑示意图如下所示,可划分为三部分:
1.通过Step Function编排并调度Lambda,对公开数据集API实现数据采集
2.通过Glue爬取采集到数据的元数据到数据目录,以便通过Athena进行数据分析
3.通过SageMaker对数据进行进行处理,并通过时间序列算法LSTM进行预测

数据源说明
本方案示例使用的数据源为伦敦市空气质量监测数据。API接口和调用请参见以下链接:
https://api.erg.ic.ac.uk/AirQuality/help
通过调用API,可以获得伦敦空气质量相关小时级历史数据信息,用于后面的数据分析和预测。
利用无服务器架构实现低成本数据采集
考虑到API服务的可靠性与承载能力,通常在获取数据时,需要对数据请求进行限流操作,包括限制请求时间范围和限制请求发起频率,从而提高数据请求的成功率。
考虑到数据抽取为一次性功能,因此需要尽可能减少研发投入,压缩开发周期。考虑到开发工作量与数据抽取成本之间的平衡,本方案选择使用亚马逊云科技无服务器架构完成数据采集,从而尽可能压缩开发成本。
数据采集涉及服务与主要功能:
- Lambda – 具体API接口调用与数据采集。
- SQS – 解耦站点和采集时间段。由于限流需要,每次采集时间段不能超过1个月的数据,因此使用SQS实现站点清单,启用、弃用时间段与数据采集时间段解耦。
- Kinesis Firehose – 将采集到的结果传输到S3存储 ,为下一步数据分析奠定基础。
- S3 – 数据存储
业务流程如下图所示:

通过访问主站点,获取所有监测站点信息列表。该列表包含站点名称,代码,启用时间,弃用时间等关键信息。
生成站点列表代码如下:
1. import json
2. import boto3
3. import os
4. import urllib3
5.
6. format = str(os.environ['TARGET_FORMAT'])
7. sqs = boto3.resource('sqs')
8. queue = sqs.get_queue_by_name(QueueName=str(os.environ['TARGET_QUEUE']))
9. http = irllib3.PoolManager()
10.
11. def lambda_handler(event, context):
12.
13. url = 'http://api.erg.kcl.ac.uk/AirQuality/Information/MonitoringSites/GroupName=London/'
14.
15. response = http.request('GET', url)
16.
17. r = json.loads(response.data)
18.
19. for site in r['Sites']['Site']:
20. queue.send_message(MessageBody=str(site))
21.
22. return {
23. 'statusCode': 200,
24.
25. }
26.
获取的站点信息以Json格式,被发送给目标SQS队列进行处理。
通过从站点列表队列(SQS)中获取站点清单,可以获得所有站点,以及每个站点的启用和弃用时间(”DateOpened”和”DateClosed”)。若当前站点不再使用,则弃用时间包含具体日期。若当前站点仍然在使用,则该字段为空,在设置获取数据时间点时,使用调用Lambda函数的时间戳作为数据采集结束时间。
考虑到API站点承载能力和访问压力,在采集过程中,以月为单位进行数据采集,从而避免海量数据查询导致API压力过大,响应时间过长。同时,使用单一进程进行采集,避免多个查询相互影响,从而造成响应时间过长。
生成采集时间时,根据站点启用时间,将该站点生命周期内数据拆分成以月为单位的数十至数百采集任务,之后将任务发送给采集时间队列。从而将任务分解与任务执行解耦。
生成采集时间的代码如下:
1. import json
2. import time
3. import boto3
4. import os
5.
6. from datetime import datetime, timedelta
7. from dateutil.relativedelta import relativedelta
8.
9. sqs = boto3.resource('sqs')
10. print(sqs)
11. target = sqs.get_queue_by_name(QueueName=str(os.environ['TARGET_QUEUE']))
12. print(target)
13. sqs = boto3.resource('sqs')
14. print(sqs)
15. source = sqs.get_queue_by_name(QueueName=str(os.environ['SOURCE_QUEUE']))
16. print (source)
17.
18. def lambda_handler(event, context):
19.
20. messages = source.receive_messages(WaitTimeSeconds = 20)
21. print (messages)
22.
23. more = False
24. if len(messages) > 0:
25. more = True
26. body = eval(messages[0].body)
27.
28. cur_time = datetime.now();
29.
30. open_time = datetime.strptime(body['@DateOpened'],"%Y-%m-%d %H:%M:%S")
31.
32. if '' == body['@DateClosed'].strip():
33. close_time = cur_time
34. else:
35. close_time = datetime.strptime(body['@DateClosed'], "%Y-%m-%d %H:%M:%S")
36.
37. target_time = open_time + relativedelta(months=1)
38. print(target_time)
39.
40. while(target_time < close_time):
41. item_to_send= {}
42. item_to_send['site'] = str(body['@SiteCode'])
43. item_to_send['start'] = open_time.strftime("%Y-%m-%d")
44. item_to_send['end'] = target_time.strftime("%Y-%m-%d")
45.
46. open_time = target_time
47. target_time = open_time + relativedelta(months=1)
48.
49. target.send_message(MessageBody=str(item_to_send))
50.
51. item_to_send = {}
52. item_to_send['site']: = str(body['@SiteCode'])
53. item_to_send['start'] = open_time.strftime("%Y-%m-%d")
54. item_to_send['end'] = target_time.strftime("%Y-%m-%d")
55. target.send_message(MessageBody=str(item_to_send))
56.
57. response = source.delete_messages(
58. Entries=[
59. {
60. 'Id': messages[0].message_id,
61. 'ReceiptHandle': messages[0].receipt_handle
62. },
63. ]
64. )
65.
66. print(response)
67.
68. return {
69. 'statusCode' : 200,
70. 'stateInput' : {
71. 'more': more
72. }
73.
74. }
75.
由于站点列表来自于SQS队列,因此在生成具体采集时间任务后,需要从SQS中删除对应站点信息。如此设计的优势是通过SQS作为队列,当Lambda异常退出后,数据仍然保留在SQS中,从而可以实现自动重试的效果。在实际采集数据时,此项功能也格外有用。
在完成了采集时间生成之后,就需要实际运行数据采集任务了。考虑到网络访问过程中,请求可能因为API可用性和压力等问题,而导致失败。需要引入重试机制,确保在偶然发生请求失败时,可以自动重试请求。同时,对于连续重试若干次的请求,可以将数据送至死信队列,用于未来进行问题排查和分析。
SQS任务队列可以完美的解决失败任务重试,并可以在配置的重试次数后,将数据送至死信队列用于未来进一步分析。
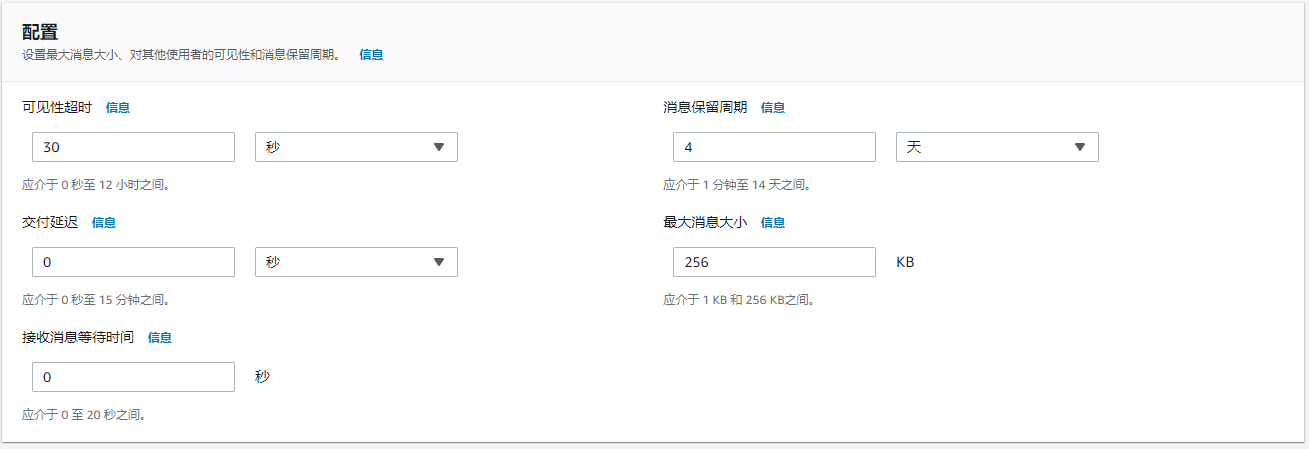
创建SQS时,可以选择可见性超时属性。当队列中数据被Lambda获取后,该计时器开始计时,确保数据不会重复分发给其他Lambda函数。通常超时时间配置为略长于Lambda最长运行时长。从而在Lambda运行失败后,确保该数据在队列中重新可见,并能够被其他Lambda函数获得,进而实现重试功能。

死信队列可以用于处理一些问题数据。部分数据由于各种原因,有可能无法被目标API正常处理,而如果放任这些数据存在于正常数据队列中,会导致这部分数据反复被尝试,从而占用计算资源,甚至阻塞正常数据的执行。因此通过配置死信队列,可以将该部分问题数据转移到专门的队列中,方便后续排查使用。示例中配置的重试次数为10次。

具体采集数据代码如下:
1. import json
2. import boto3
3. import os
4. import urllib3
5.
6. sqs = boto3.resource('sqs')
7. print(sqs)
8. source = sqs.get_queue_by_name(QueueName=str(os.environ['SOURCE_QUEUE']))
9. print(source)
10. http = urllib3.PoolManager()
11. firehose = boto3.client('firehose')
12.
13. base_url = 'http://api.erg.kcl.ac.uk/AirQuality/Data/Site/SiteCode='
14.
15. def lambda_handler(event, context):
16.
17. cnt = 0
18. if 'iterator' in event:
19. cnt = event['iterator']
20.
21. messages = source.receive_messages(WaitTimeSeconds = 20)
22. print(messages)
23.
24. more = False
25. if len(messages) > 0:
26. more = True
27. body = eval(messages[0].body)
28. print(body)
29.
30. url = base_url + str(body['site'])
31. url += '/StartDate=' + str(body['start']) + '/EndDate=' + str(body['end']) + '/json'
32. print(url)
33.
34. response = http.request('GET', url)
35. print(response.status)
36.
37. if response.status != 200:
38. return {
39. 'statusCode': 200,
40. 'stateInput': {
41. 'more': True
42. },
43. 'iterator': cnt + 1
44. }
45.
46. response_data = json.loads(response.data.decode('utf'));
47. site_id = response_data['AirQualityData']['@SiteCode']
48. records []
49.
50. for data_item in response_data['AirQualityData']['Data']:
51. put_item={}
52. put_data = {}
53. put_data['site'] = site_id
54. put_data['speciescode'] = data_item['@SpeciesCode']
55. put_data['measurementdategmt']= data_item['@MeasurementDateGMT']
56. put_data['value']= data_item['@Value']
57. put_item['Data'] = (str(put_data) + '\n').encode('Utf-8');
58. print(put_item['Data'])
59. records.append(put_item)
60.
61. if len(records) == 200:
62. response - firehose.put_record_batch(
63. DeliveryStreamNName=os.environ['FIREHOSE_STREAM'],
64. Records=records
65. )
66.
67. print(len(records))
68. print(response)
69. records = []
70.
71. if len(records) > 0:
72. response = firehose.put_record_batch(
73. DeliveryStreamName=os.environ['FIREHOSE_STREAM'],
74. Records=records
75. )
76.
77. print(response)
78.
79. response = source.delete_messages(
80. Entries=[
81. {
82. 'Id': messages[0].message_id,
83. 'ReceiptHandle': messages[0].receipt_handle
84. },
85. ]
86.
87. )
88.
89. print(response)
90.
91. return {
92. 'statusCode': 200,
93. 'stateInput': {
94. 'more': more
95. },
96. 'iterator': cnt + 1
97. }
98.
通过按照指定格式调用API接口,获得指定时间范围内的数据信息,并交由Kinesis Data Firehose缓存后转存到S3中。
使用Step Function组织采集流程
由于Lambda函数最长仅能运行15分中,因此需要使用编排框架将上述Lambda函数按照依赖关系和执行顺序进行组织。从而确保Lambda函数被有序调度。
亚马逊云科技提供Step Function用于实现Lambda函数调度功能。
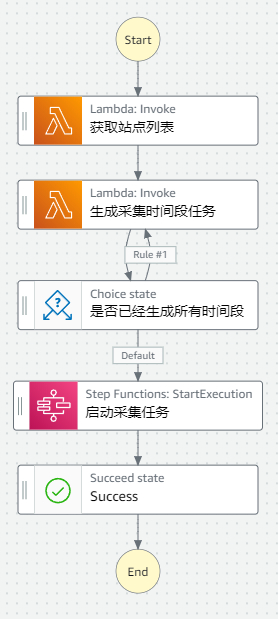
本解决方案使用2组Step Function完成数据采集任务。第一组Step Function用于编排和调度获取站点与生成数据采集时间范围。其配置如下:

Step Function内部通过调用Lambda,并根据返回输出,不断调整内部状态机和执行路径,从而将解耦后的Lambda有序的调度为一个整体。第一个Step Function中实现了站点获取和采集时间段生成的功能。当Lambda完成上述功能后,会启动第二个Step Function,实现具体采集工作。
第二个Step Function内容如下:

第二个Step Function的本质是循环执行Lambda函数,直至所有SQS中存储的待采集信息全部处理完成。但由于Step Function的限制(每个Step Function最多处理25000状态变化),因此需要对Step Function执行过程进行拆分。当单次执行接近系统允许的上限时,通过启动全新的Step Function并终止当前Step Function的方式,实现长时间循环直至SQS中所有数据处理完成。
关于Kinesis Data Firehose将数据存储到S3的部分,本文不再赘述,有兴趣的读者可以参考Kinesis Data Firehose文档介绍:
https://docs.aws.amazon.com/zh_cn/firehose/latest/dev
数据采集成本效益分析
在使用托管服务后,数据采集的开发时间被显著压缩。笔者仅用了1天时间即完成了整个数据采集架构的搭建工作,并且在3天内完成测试和生产部署。而包含测试、迭代,生产使用的总成本不到30美元。其中Kinesis Data Firehose约22美元,Step Function约4.5美元,Lambda约0.5美元,SQS约0.3美元。
考虑到开发一整套编排框架,并完成Debug等所需的时间带来的人力成本,使用无服务器架构和托管服务在数据采集任务中极大的提速了上线进程,并有效降低了总体成本。
使用Glue爬网程序生成数据表
亚马逊云科技Glue服务作为托管的ETL工具,使得用户可以轻松高效的完成数据分类,清理和扩充。而其爬网程序可以自动清点数据存储中的数据,并将元数据添加到数据目录之中。用户可以通过包括Athena编写SQL快速查询存储于S3中的数据。
爬网程序的配置也非常简单。
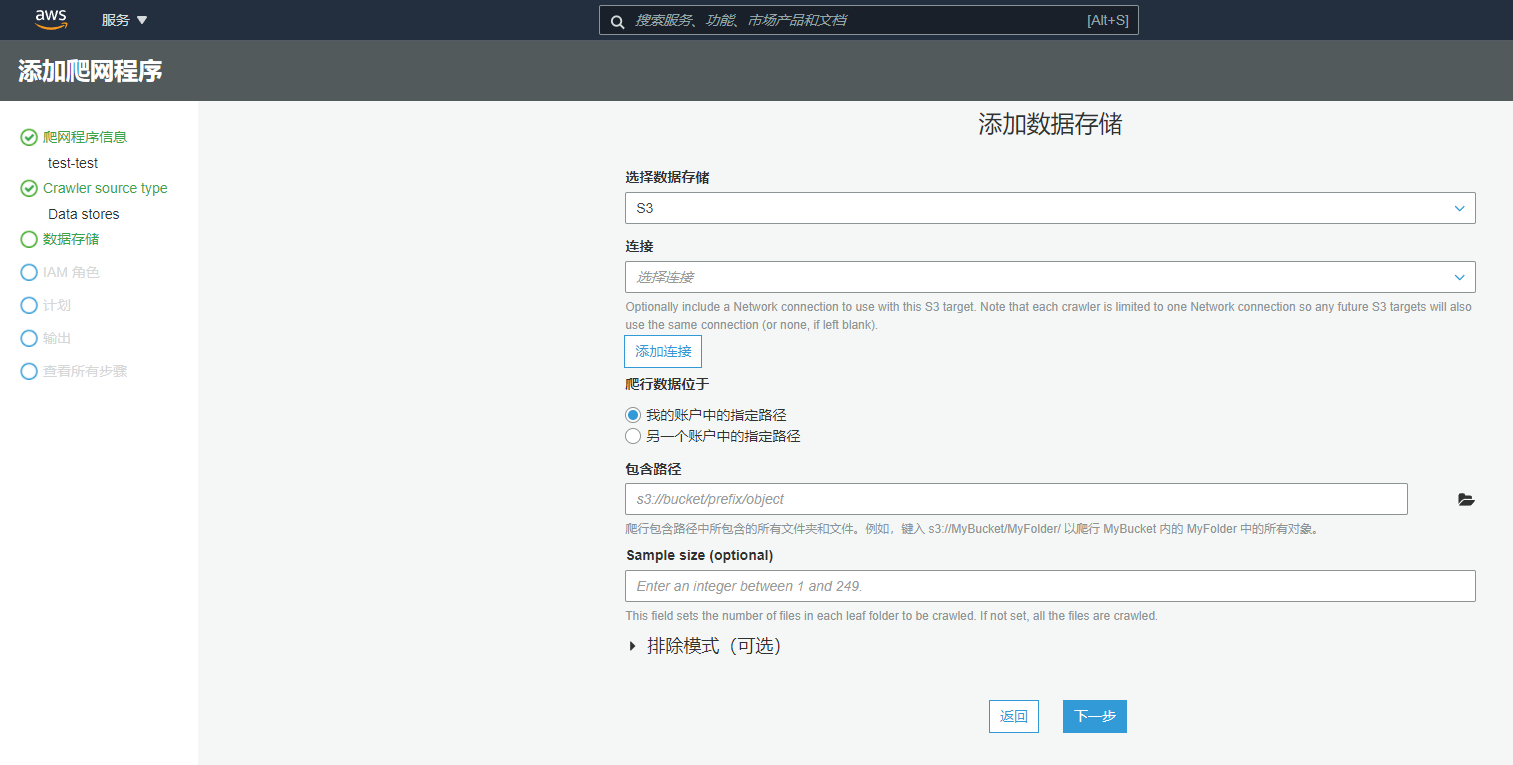
在Glue页面中选择爬网程序->添加爬网程序。

输入程序名称,单击下一步继续。
保留默认配置,单击下一步。

配置S3链接,并指定需要爬网程序执行清点的S3路径,单击下一步。

保留默认配置,单击下一步。

为准备创建的IAM角色输入角色名称。单击下一步。

选择按需运行,单击下一步。

单击“添加数据库”,并根据向导填写数据库名称和信息,完成数据库创建。选择刚刚创建的数据库,并单击下一步。

单击完成,创建爬网程序。

选择刚刚创建的爬网程序,并单击运行爬网程序,等待运行结果。
爬网程序成功运行后,会看到以下内容:

该内容跟说明爬网程序已经成功根据输入信息,在数据目录中创建了对应条目。用户可以使用Athena对存储在S3中的数据进行检索了。
登录Athena界面后,在左侧数据源、数据库中选择之前配置的数据库,即可看到已经创建完成的数据表。用户可以通过SQL对数据库内容进行查询和检索。

使用Sagemaker从Athena获得分析数据源
数据工程师和数据科学家可以通过亚马逊云科技Sagemaker服务,对采集到的数据进行数据探索,模型训练等工作。
使用Sagemaker托管的Jupyter Notebook实例,数据工程师和数据科学家可以通过编写Python脚本,利用Athena提供的查询能力,对采集的数据进行探索。以下代码示例提供了使用Athena,在采集的数据中检索站点“HF4”,指标“NO2”的数据信息。
代码首先创建Athena客户端,并启动查询任务。然后循环等待,直至查询任务结束。Athena会将查询结果存储到指定的输出位置。因此可以直接使用Pandas读取S3输出位置的CSV文件,即可获得详细数据。
1. import boto3
2. import pandas as pd
3.
4. # initialize client and start execution
5. athena_client = boto3.client ('athena')
6. execution_id = athena_client.start_query_execution(
7. QueryString='SELECT distinct measurementdategmt, value FROM 'aaa'.'step_function2021' where site=\'HF4\'' + 'and speciescode=\'NO2\' order by measurementdategnt ASC',
8. ClientRequestToken='client-request-sample-token-xxxx',
9. QueryExecutionContext={
10. 'Database': 'aaa',
11. 'Catalog': 'AwsDataCatalog'
12. },
13. ResultConfiguration={
14. 'OutputLocation' : 's3://aq-test-tokyo/source/'
15. })
16.
17. # wait until execution is complete
18. execution_state = athena_client.get_query_execution(QueryExecutionId = execution_id['QueryExecutionId']z
19. output_location = execution_state['QueryExecution']['ResultConfiguration']['OutputLocation']
20. print(output_location)
21.
22. while execution_state['QueryExecution']['Status']['State'] in ('QUEUED','RUNNING'):
23. execution_state = athena_client.get_query_execution (QueryExecutionId = execution_id['QueryExecutionId'])
24.
25. # print execution result
26. print(execution_state['QueryExecution']['Status']['State'])
27.
28. # print error messages if result is failed
29. if 'FAILED' == execution_state['QueryExecution']['Status']['State']:
30. print(execution_state)
31.
32. # plot data
33. original_data = pd.read_esv(output_location, sep=",", index_col=
34. 0, parse_dates=True, decimal=".")
35. original_data.plot()
36.

在上面截图中不难看出,该站点在2013年下半年至2014年年底前曾经关闭。因此该部分数据无法正常使用。而其他时间段也存在部分数据缺失的情况。为了能够准确的进行预测,需要在一定范围内对缺失的数据进行补充。
数据清洗与补值
物联网数据收网络链接质量,边缘设备工作状态,缓存等影响,时常发生数据丢失等情况。因此在使用数据进行分析预测前,需要检查数据是否存在缺失,并对缺失数据进行填补。
在本方案中,考虑到过长时间的数据缺失会导致难以准确填补。因此本方案选择填补缺失4小时内的数据。
1. import numpy as np
2. hours_can_fill = 4
3. def write_to_file(file_start, fragment):
4. with open('data-hf4/' + str(file_start) + '.csv', "wb") as fp:
5. fp.write(("\"measurementdategmt\",\"value\",\"filled\"\n").encode('utf-8'))
6. for d in fragment:
7. str_to_write = "\"" + str(d['time']) + "\",\"" +str(d['value']) + "\",\"" + (str(True) if 'fill' in d else "") + "\"\n"
8. fp.write( str_to_write.encode("utf-8"))
9. print('data-hf4/' + str(file_start) + '.csv')
10.
11. last_data = None
12. last_value = None
13. file_start = None
14. fragment = []
15. for i, line in original_data.iterrows():
16. if not np.math.isnan(line['value']):
17. if not file_start:
18. file_start = i
19.
20. if last_data:
21. delta = i - last_data
22. if delta <= pd.Timedelta(hours=hours_can_fill):
23. item_filled =0
24. while last_data < i - pd.Timedelta (hours=1):
25. item_filled=iten_filled+l
26. last_data = last_data + pd.Timedelta(hours=1)
27. item = {}
28. item['time'] = str(last_data)
29. item['value'] = round((last_value + (line['value'] - last_value) (pd. Timedelta(hours=item_filled)/delta)), 1)
30. item['fill'] = True
31. fragment. append(item)
32. else:
33. write_to_file(file_start, fragment)
34. fragment = []
35. file_start = i
36.
37. last_data = i
38. last_value = line['value']
39.
40. item={}
41. item['time'] = str(last_data)
42. item['value'] = last_value
43. fragment. append(item)
44.
45. write_to_file(file_start, fragment)
46.
根据之前从Athena中获得的数据,通过过滤value值为“NaN”,即空值的数据,实现精准查找缺失值,并根据缺失值前后范围是否超过4小时,进行判断。若缺失值在4小时内,则按照前后值差做4等分的方式,补充缺失的数据。如果超过4小时,则将输出数据切分成不同的数据分段,用于在后续选择数据量充足,可以进行预测的分段,生成预测数据。
通过对生成数据进行预览,带有“True”字段的部分即为填充数据内容。如下图所示:

选择训练数据,并分割训练集与测试集
考虑到训练需要有一定的数量基础,因此需要在数据集中寻找相对数据量较为充足的数据集。在兼顾数据时效性的角度下,本案例选择了“2017-06-01 13_00_00.csv”作为训练集和测试集使用。
首先完成训练数据加载工作。然后选取前2000条数据用于训练和测试。将数据标准化到0-1之间,再通过数据移位的方式为时间序列数据增加一些新的特征字段,从而转换为Tensorflow监督学习任务。最后将数据分割为训练集和测试集,并将训练集保存成文本文件并上传到S3供训练使用。
具体代码如下:
1. import pandas as pd
2. import boto3
3. import numpy as np
4.
5. from pandas import DataFrame
6. from pandas import concat
7. from sklearn.preprocessing import MinMaxScaler
8.
9. #序列转换为LSTM结构
10.
11. def timeseries_to_supervised(data, lag=1):
12. df = DataFrame(data)
13. columns = [df.shift(i) for i in range(1, lag+1)]
14. columns.append(df)
15. df = concat(columns, axis=1)
16. df.fillna(0, inplace=True)
17. return df
18.
19. #数据归一化
20. def scale (train, test):
21. # fit scaler
22. scaler = MinMaxScaler(feature_range=(0, 1))
23. scaler = scaler.fit(train)
24. # transform train
25. train = train.reshape (train. shape[0], train.shape[1])
26. train_scaled =scaler.transform(train)
27. # transform test
28. test = test.reshape(test.shape[0], test. shape[1])
29. test_scaled = scaler.transform(test)
30. return scaler, train_scaled, test_scaled
31.
32. source_file = "2017-06-01 13:00:00.csv"
33. training_scaled = "training_scaled.npy"
34.
35. df = pd.read_csv("data-hf4/" + source_file)
36. df['measurementdategnt'] = pd.to_datetime(df['measurementdategnt'])
37. df = df.sort_values('measurementdategmt')
38. series = df['value'][0:2000]
39. raw_values = series.values
40. supervised = timeseries_to_supervised(raw_values, 3)
41. supervised_values = supervised.values
42. train, test = supervised_values[0:-1400], supervised_values[-200:]
43. scaler, train_scaled, test_scaled = scale(train, test)
44. print(train_scaled)
45. print()
46. print(test_scaled)
47. np.savetxt(training_scaled, train_scaled)
48. np.savetxt('test.npy', test_scaled)
49. s3_client = boto3.client('s3')
50. s3_client.upload_file(training_scaled, "sagemaker-ap-northeast-1-808242303800", "sagemaker/lstm/" + training_scaled)
51. s3_client.upload_file("test.npy", "sagemaker-ap-northeast-1-808242303800", "sagemaker/lstm/test.npy")
52.
利用Sagemaker BYOS功能使用自定义脚本训练LSTM模型
LSTM并非Sagemaker内置模型。因此再训练时需要通过Notebook手写代码,或者使用BYOS的方法完成训练工作。
考虑到模型训练代码通常在不同使用环境下具有一定复用性,因此选择使用BYOS模式训练LSTM。
BYOS需要提前准备用于执行训练过程的脚本,并通过Sagemaker框架将该脚本发送到训练使用的虚拟机上。
本案例中直接使用基于Keras的LSTM模型训练脚本lstm.py文件作为训练脚本。
启动训练任务
仅需要几行代码,就可以启动训练任务。
首先,从当前Sagemaker记事本中获得角色信息,然后配置训练参数,包括用户提供的训练脚本(Bring Your Own Script,即BYOS),运行使用的IAM角色,用于训练的示例数量和大小,运行使用的TensorFlow框架版本,Python版本,以及是否启用分布式训练等。
在完成以上配置后,即可启动训练过程。
1. import os
2. import sagemaker
3.
4. from sagemaker import get_execution_role
5. from sagemaker.tensorflow import TensorFlow
6.
7. role = get_execution_role()
8.
9. training_data_uri = "s3://sagemaker-ap-northeast-1-808242303800/sagemaker/lstm/"
10.
11. lstm_estimator= TensorFlow(
12. entry_point="lstm.py",
13. role=role,
14. instance_count=1,
15. instance_type="ml.m5.xlarge",
16. framework_version="2.1",
17. py_version="py3",
18. distribution={"parameter_server": {"enabled": False}},
19. )
20. lstm_estimator.fit(training_data_uri)
21.
在训练时,Sagemaker会在后台启动一个训练任务。该任务可以通过控制台查看详细信息。任务执行日志和信息也会打印到Jupyter Notebook中。
当看到“Reporting training SUCCESS”字样时,即训练完成。Sagemaker还会提供训练实例使用时间和计费时间等信息。

部署模型
当完成模型训练后,仅需要一行代码,即可以使用Sagemaker直接部署模型到生产。
predictor = lstm_estimator.deploy(initial_instance_count=1, instance_type=’ml.m5.xlarge’)
调用模型
2. predictions = list()
3. fox i in range (len(test_scaled)):
4. # make one-step forecast
5. X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
6. X_reshaped = X.reshape(1, 1, len(X))
7. yhat = predictor.predict(X_reshaped)['predictions'][0][0]
8. # invert scaling
9. yhat = invert_scale(scaler,X, yhat)
10. predictions.append(yhat)
11. expected = raw_values[len(train) +i + 1]
12. #print('Month=%d, Predicted=%f, Expected=%f' % (i+1, yhat, expected))
通过调用已经部署的模型终端,可以对测试数据进行预测,利用预测获得的结果与实际测试数据进行对比,模型预测效果参见下图:
1. from math import sqrt
2. from sklearn.metrics import mean_squared_error
3. from matplotlib import pyplot
4. rmse = sqrt(mean_squared_error(raw_values[-200:], predictions))
5.
6. print('Test RMSE: %.3f' % rmse)
7. # line plot of observed vs predicted
8. pyplot.plot(raw_values[-200:], '-r', label = 'Test data', linewidth = 2)
9. pyplot.plot(predictions, '-k', label = 'LSTM predicitons', linewidth = 2)
10. pyplot.legend()
11. pyplot.xlabel ('Time count', fontweight = 'bold')
12. pyplot.ylabel('Pollutant concentration', fontweight = 'bold')
13. pyplot.show()
14.

小结:
在云计算时代,业务成本核算往往不再能够通过将系统拆分为开发、购买、运维等若干费用模块分别计算并汇总。而是对业务需求进行分解后,在此消彼长的成本之间寻求最优化的平衡。
在本方案中,通过应用无服务器系统架构,极大的缩短了软件开发所需的时间,加快了系统上线的过程。而服务产生的额外成本相比节省下来的开发成本、部署成本、运维成本可谓是微乎其微。
因而在系统原型搭建,业务压力较小,或对系统容量需求不明确,且上线时间周期紧张的情况下,使用无服务器架构可以有效应对相关挑战。
同时,在大数据时代,物联网方案最终均需要落地到一个具体的业务场景之中。本案例中利用物联网传感器技术,结合机器学习算法,有效实现了控制质量高精度预测场景。相似的系统架构对于给予传感器的时间序列预测也具有参考意义。
参考文献:
Scaling up a serverless web crawler and search engine:
https://aws.amazon.com/blogs/architecture/scaling-up-a-serverless-web-crawler-and-search-engine/
Deploy trained Keras or TensorFlow models using Amaozn Sagemaker
https://aws.amazon.com/blogs/machine-learning/deploy-trained-keras-or-tensorflow-models-using-amazon-sagemaker/
本篇作者