AWS Architecture Blog
Scaling up a Serverless Web Crawler and Search Engine
Introduction
Building a search engine can be a daunting undertaking. You must continually scrape the web and index its content so it can be retrieved quickly in response to a user’s query. The goal is to implement this in a way that avoids infrastructure complexity while remaining elastic. However, the architecture that achieves this is not necessarily obvious. In this blog post, we will describe a serverless search engine that can scale to crawl and index large web pages.
A simple search engine is composed of two main components:
- A web crawler (or web scraper) to extract and store content from the web
- An index to answer search queries
Web Crawler
You may have already read “Serverless Architecture for a Web Scraping Solution.” In this post, Dzidas reviews two different serverless architectures for a web scraper on AWS. Using AWS Lambda provides a simple and cost-effective option for crawling a website. However, it comes with a caveat: the Lambda timeout capped crawling time at 15 minutes. You can tackle this limitation and build a serverless web crawler that can scale to crawl larger portions of the web.
A typical web crawler algorithm uses a queue of URLs to visit. It performs the following:
- It takes a URL off the queue
- It visits the page at that URL
- It scrapes any URLs it can find on the page
- It pushes the ones that it hasn’t visited yet onto the queue
- It repeats the preceding steps until the URL queue is empty
Even if we parallelize visiting URLs, we may still exceed the 15-minute limit for larger websites.
Breaking Down the Web Crawler Algorithm
AWS Step Functions is a serverless function orchestrator. It enables you to sequence one or more AWS Lambda functions to create a longer running workflow. It’s possible to break down this web crawler algorithm into steps that can be run in individual Lambda functions. The individual steps can then be composed into a state machine, orchestrated by AWS Step Functions.
Here is a possible state machine you can use to implement this web crawler algorithm:
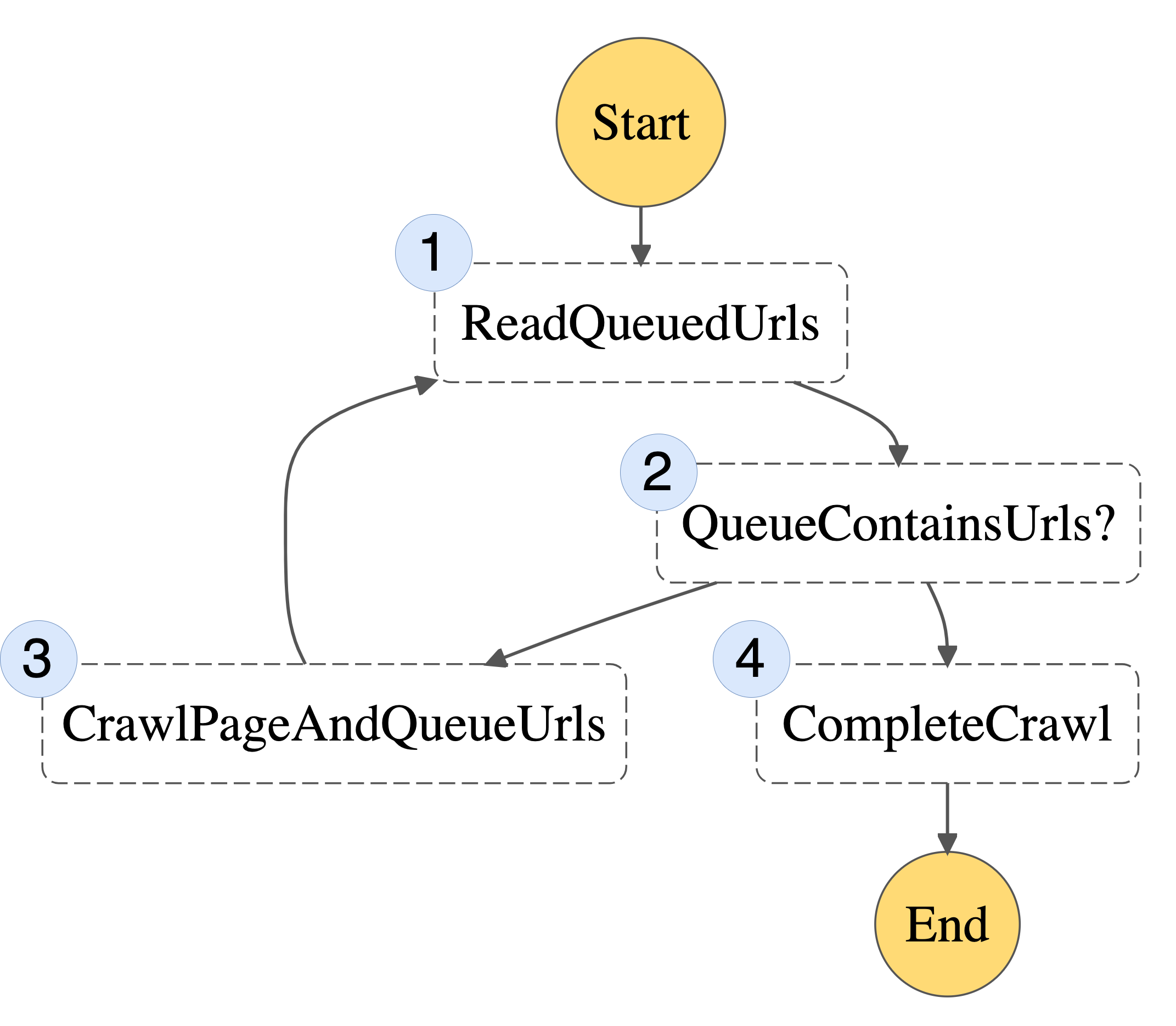
Figure 1: Basic State Machine
1. ReadQueuedUrls – reads any non-visited URLs from our queue
2. QueueContainsUrls? – checks whether there are non-visited URLs remaining
3. CrawlPageAndQueueUrls – takes one URL off the queue, visits it, and writes any newly discovered URLs to the queue
4. CompleteCrawl – when there are no URLs in the queue, we’re done!
Each part of the algorithm can now be implemented as a separate Lambda function. Instead of the entire process being bound by the 15-minute timeout, this limit will now only apply to each individual step.
Where you might have previously used an in-memory queue, you now need a URL queue that will persist between steps. One option is to pass the queue around as an input and output of each step. However, you may be bound by the maximum I/O sizes for Step Functions. Instead, you can represent the queue as an Amazon DynamoDB table, which each Lambda function may read from or write to. The queue is only required for the duration of the crawl. So you can create the DynamoDB table at the start of the execution, and delete it once the crawler has finished.
Scaling up
Crawling one page at a time is going to be a bit slow. You can use the Step Functions “Map state” to run the CrawlPageAndQueueUrls to scrape multiple URLs at once. You should be careful not to bombard a website with thousands of parallel requests. Instead, you can take a fixed-size batch of URLs from the queue in the ReadQueuedUrls step.
An important limit to consider when working with Step Functions is the maximum execution history size. You can protect against hitting this limit by following the recommended approach of splitting work across multiple workflow executions. You can do this by checking the total number of URLs visited on each iteration. If this exceeds a threshold, you can spawn a new Step Functions execution to continue crawling.
Step Functions has native support for error handling and retries. You can take advantage of this to make the web crawler more robust to failures.
With these scaling improvements, here’s our final state machine:
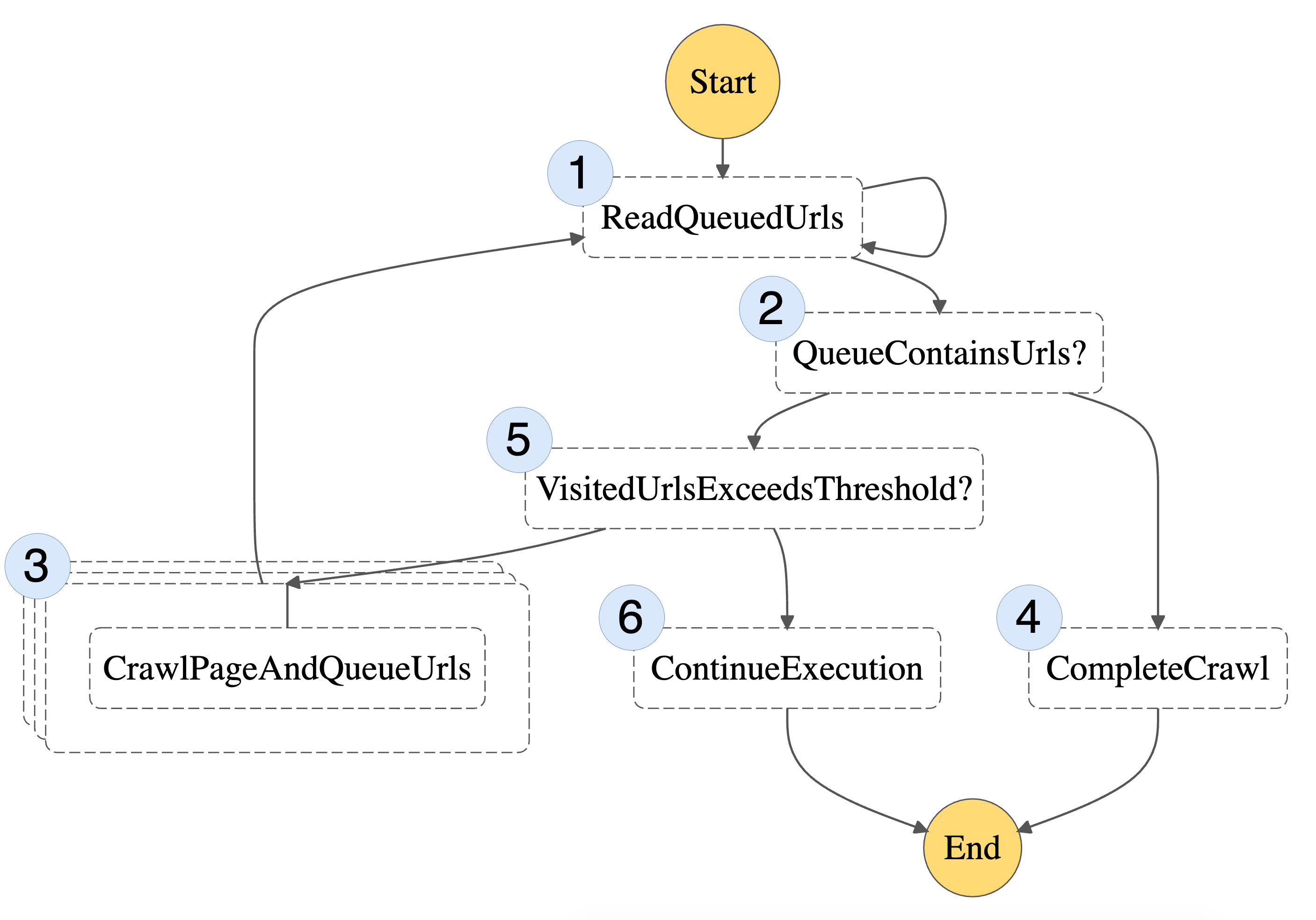
Figure 2: Final State Machine
This includes the same steps as before (1-4), but also two additional steps (5 and 6) responsible for breaking the workflow into multiple state machine executions.
Search Index
Deploying a scalable, efficient, and full-text search engine that provides relevant results can be complex and involve operational overheads. Amazon Kendra is a fully managed service, so there are no servers to provision. This makes it an ideal choice for our use case. Amazon Kendra supports HTML documents. This means you can store the raw HTML from the crawled web pages in Amazon Simple Storage Service (S3). Amazon Kendra will provide a machine learning powered search capability on top, which gives users fast and relevant results for their search queries.
Amazon Kendra does have limits on the number of documents stored and daily queries. However, additional capacity can be added to meet demand through query or document storage bundles.
The CrawlPageAndQueueUrls step writes the content of the web page it visits to S3. It also writes some metadata to help Amazon Kendra rank or present results. After crawling is complete, it can then trigger a data source sync job to ensure that the index stays up to date.
One aspect to be mindful of while employing Amazon Kendra in your solution is its cost model. It is priced per index/hour, which is more favorable for large-scale enterprise usage, than for smaller personal projects. We recommend you take note of the free tier of Amazon Kendra’s Developer Edition before getting started.
Overall Architecture
You can add in one more DynamoDB table to monitor your web crawl history. Here is the architecture for our solution:
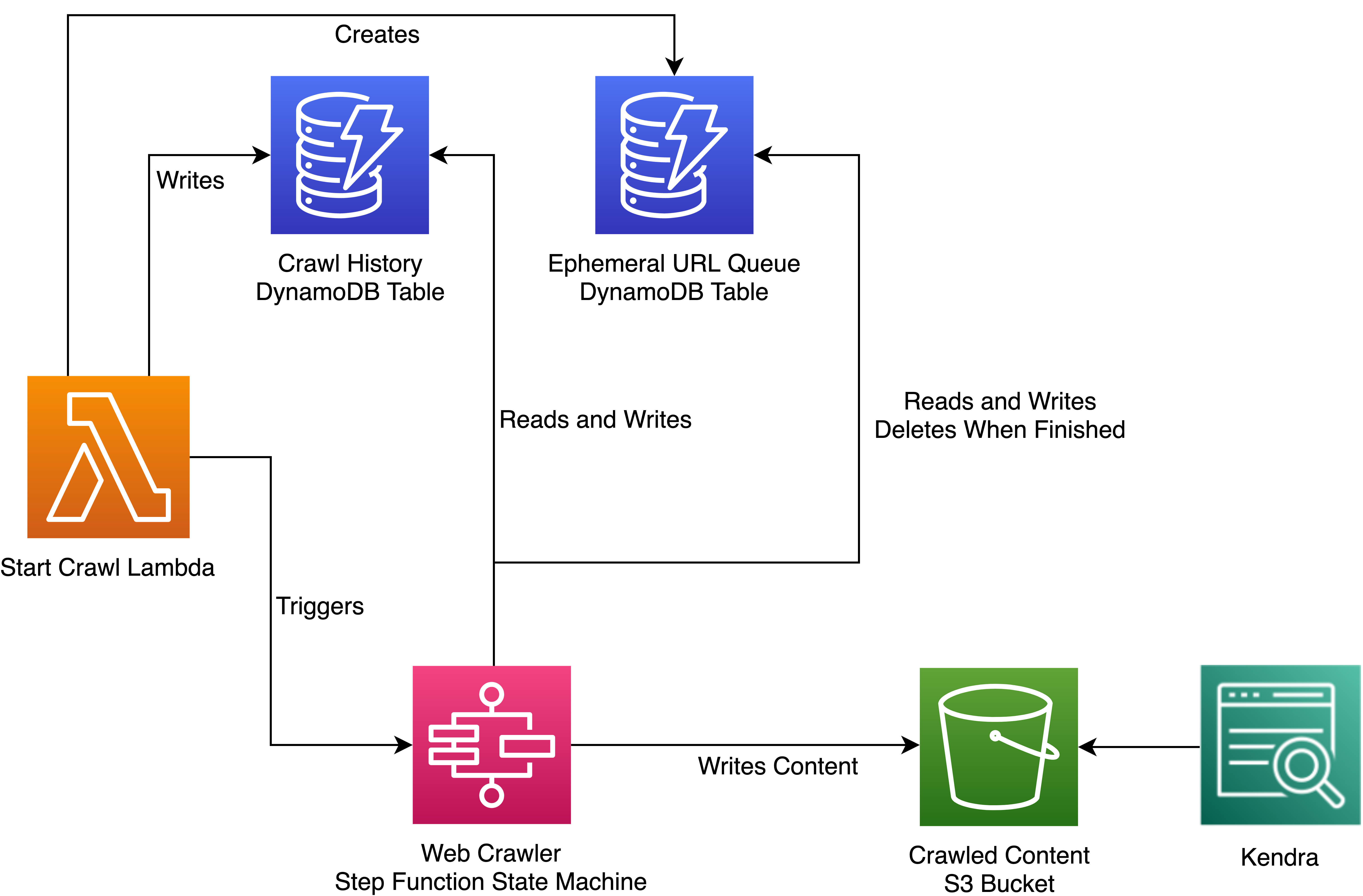
Figure 3: Overall Architecture
A sample Node.js implementation of this architecture can be found on GitHub.
In this sample, a Lambda layer provides a Chromium binary (via chrome-aws-lambda). It uses Puppeteer to extract content and URLs from visited web pages. Infrastructure is defined using the AWS Cloud Development Kit (CDK), which automates the provisioning of cloud applications through AWS CloudFormation.
The Amazon Kendra component of the example is optional. You can deploy just the serverless web crawler if preferred.
Conclusion
If you use fully managed AWS services, then building a serverless web crawler and search engine isn’t as daunting as it might first seem. We’ve explored ways to run crawler jobs in parallel and scale a web crawler using AWS Step Functions. We’ve utilized Amazon Kendra to return meaningful results for queries of our unstructured crawled content. We achieve all this without the operational overheads of building a search index from scratch. Review the sample code for a deeper dive into how to implement this architecture.