AWS Architecture Blog
Tag: Web scraping

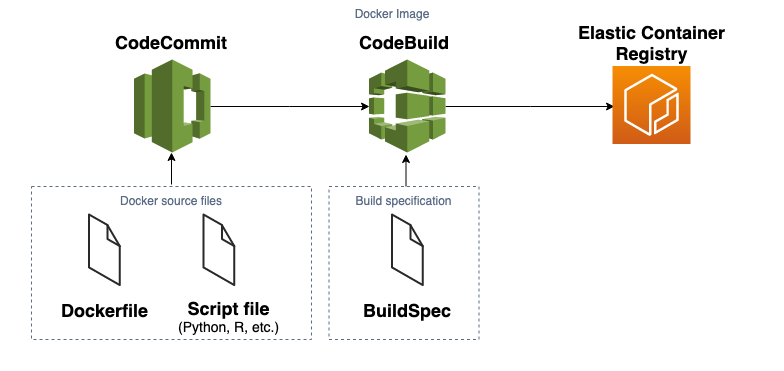
Scaling up a Serverless Web Crawler and Search Engine
Introduction Building a search engine can be a daunting undertaking. You must continually scrape the web and index its content so it can be retrieved quickly in response to a user’s query. The goal is to implement this in a way that avoids infrastructure complexity while remaining elastic. However, the architecture that achieves this is […]
Serverless Architecture for a Web Scraping Solution
If you are interested in serverless architecture, you may have read many contradictory articles and wonder if serverless architectures are cost effective or expensive. I would like to clear the air around the issue of effectiveness through an analysis of a web scraping solution. The use case is fairly simple: at certain times during the […]