亚马逊AWS官方博客
Amazon Aurora DSQL 在 IOT 场景下的应用和实践
 |
前言
随着物联网技术的快速发展,智能设备数量呈现爆发式增长,对数据库的弹性扩展和运维管理提出了更高要求。Amazon Aurora DSQL通过自动数据分区和资源动态扩缩容能力,可以轻松应对物联网场景下的数据激增和业务波动。其独特的分布式架构不仅确保了数据的高可用性和一致性,更实现了全自动化运维和无停机升级维护,让企业专注于业务创新而无需担忧基础设施管理。本文将详细介绍 Amazon Aurora DSQL 在物联网场景下的应用实践和最佳实践方案。
DSQL 服务介绍
Amazon Aurora DSQL 架构和实现原理
Amazon Aurora DSQL 支持两种部署架构:单区域部署,可在不停机的情况下处理组件故障或可用区 (AZ) 故障;多区域部署,可以应对 Region 级容灾故障,跨 Reion 实现同步复制,可以做到 RPO=0,其独特的分布式 Active-Active 架构可消除故障转移或切换造成的停机时间,从而轻松实现高可用性和业务连续性。
Amazon Aurora DSQL 提供跨三个可用区的 Active-Active 单 Region 集群,最大限度地减少复制延迟和传统的数据库故障转移操作。如果发生硬件或基础设施故障,它会自动将请求路由到其他可用区,无需人工干预。Amazon Aurora DSQL 中的事务提供ACID 特性(即原子性、一致性、隔离性和持久性),即使跨多个区域,也能将延迟影响降至最低。同时支持快照隔离级别,并为集群端点的读写操作提供了很强的数据一致性。
下图说明了单区域部署中的 Amazon Aurora DSQL 高可用集群拓扑图。
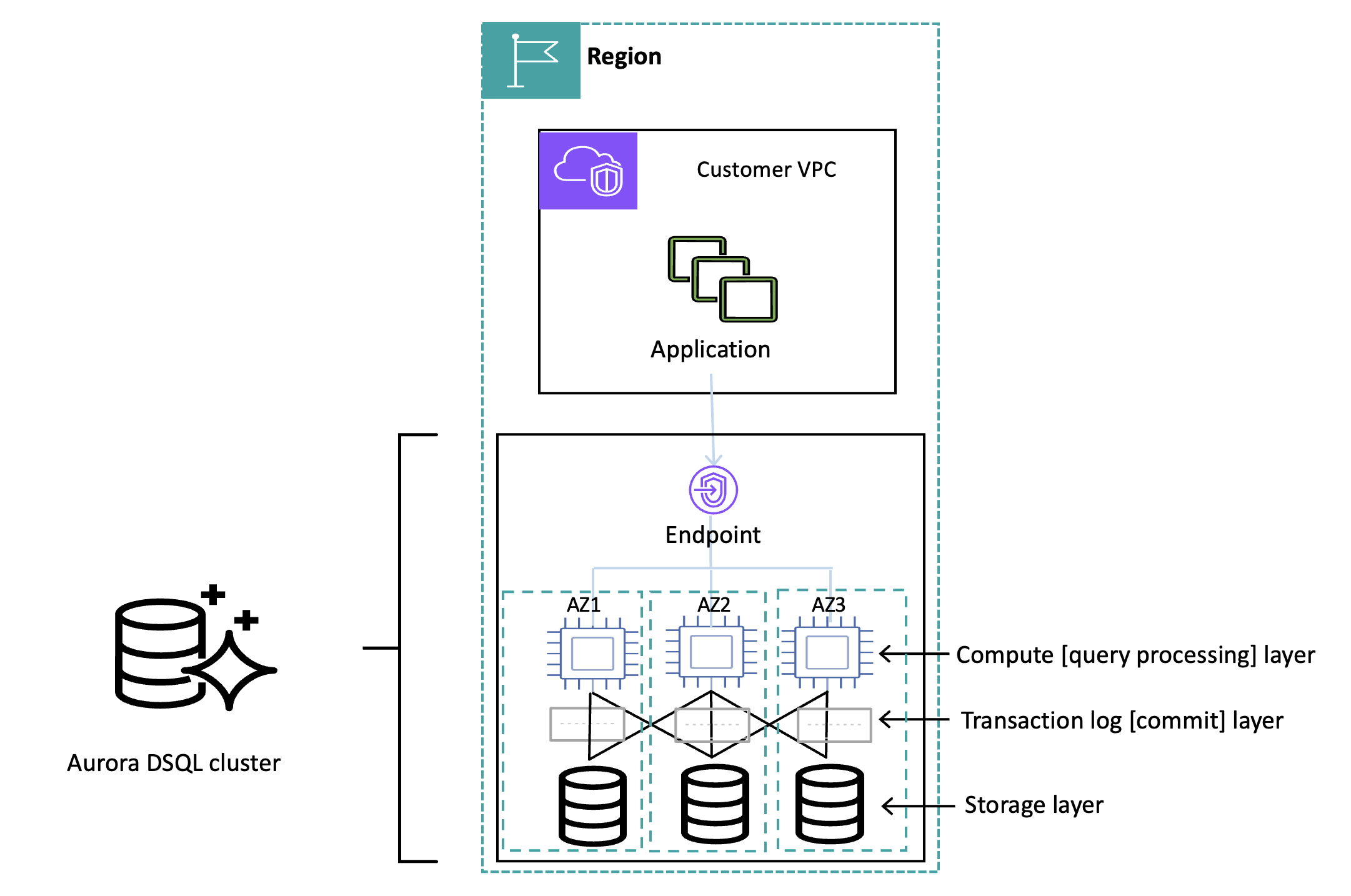 |
在单区域架构中,Amazon Aurora DSQL 将所有写入事务提交到分布式事务日志,并将所有已提交的日志数据同步复制到三个可用区中的日志存储副本。集群存储副本分布在三个AZ中,以实现最佳数据库读取性能。Amazon Aurora DSQL 实现了高度的自动故障转移,当某个组件或可用区出现故障时,它会自动将访问路由到运行正常的组件,并异步修复故障副本。一旦故障副本恢复,Amazon Aurora DSQL 会自动将其重新添加到存储集群中,并使其可供数据库访问。
多区域集群提供与单区域集群相同的事务处理和弹性能力,同时通过两个区域不同的 Endpoint(每个 Region 提供独立的Endpoint)来提高可用性。通过不同 Region 的 Endpoint 可以连接到多 Region 集群的同一个 database,并支持对同一张表并发读写操作,并保证跨区域数据的强一致性。这样,您就可以根据地理位置、性能或弹性来平衡应用程序和连接,确保终端用户始终看到相同的数据。
IOT 场景下客户普遍面临的挑战
在 to C 场景下, 设备需要将日常的设备注册/绑定数据,以及运营活动数据持久化到 Amazon Aurora MySQL 中 ,为了支撑后续的 OLTP 操作, 通常的做法就是采用分库份表的形式来保障业务查询的实效性. 但这样势必会带来以下挑战:
1.数据库结合应用层面对于分库分表的维护量工作量比较大,而且是随着后续的表增加,工作量也不断增加.
2.随着设备量的不断增加,拆分之后的表数据量也会逐渐扩大,某些会过亿行,并且通常下游的查询都伴随着多张表的关联分析.这样情况下给数据库带来非常大的压力,特别是会影响到其他核心业务.
3.在数据库升级的时候如果单表数据量过大,会导致全量数据迁移阶段花费比较长时间。
数据架构演进
在架构演进前,我们的制造数据体系以 Amazon Aurora MySQL(单集群 / 主从架构) 为核心,承载全场景数据存储与查询需求。
[原有架构]
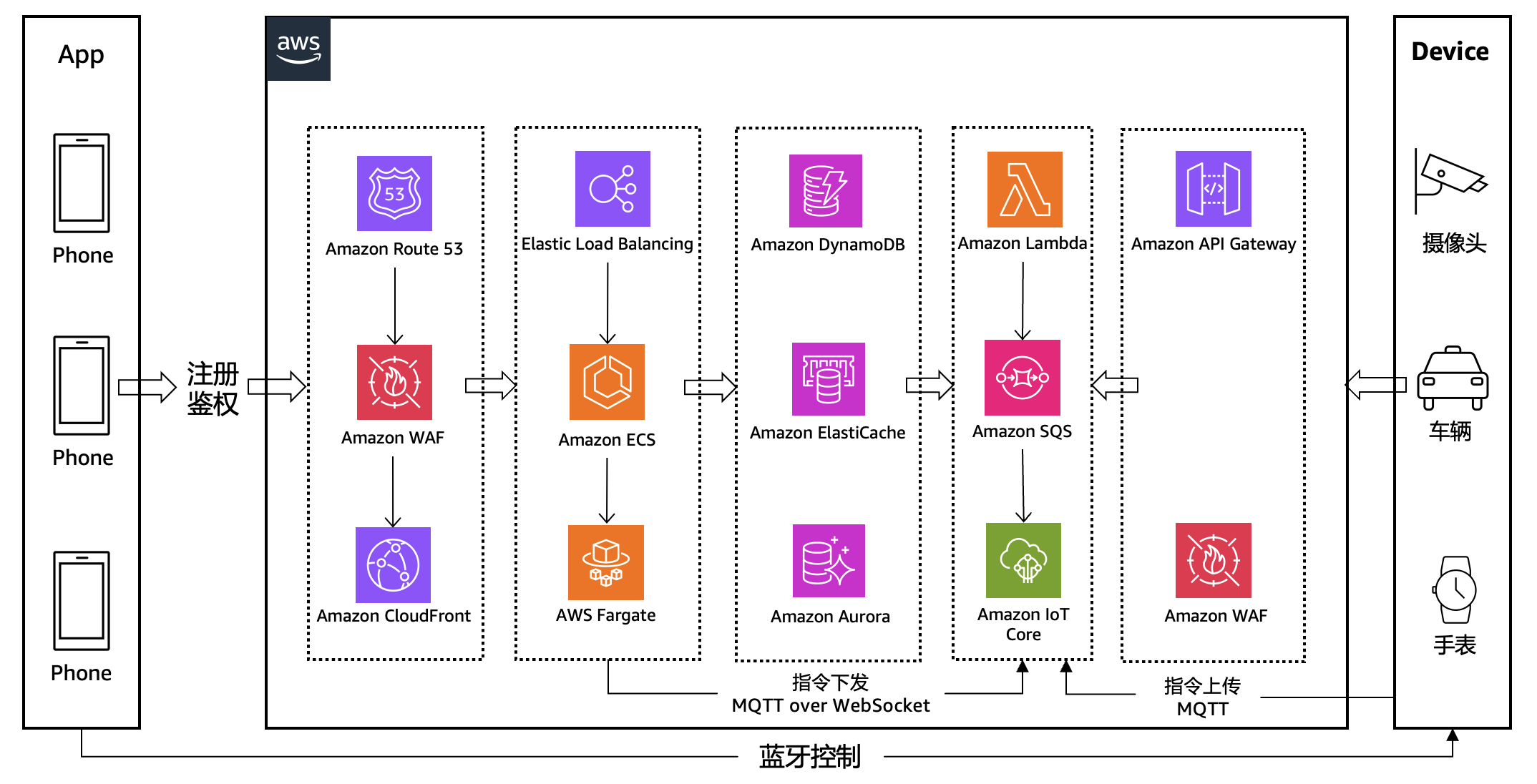 |
数据类型与量级:
接入的智能家居/汽车等事件通知数据以及广告活动数据,日均产生千万级事件数据(如设备启停日志、故障告警、生产节拍数据),同时存储百万级设备静态数据(设备型号、注册时间、维保记录)。
核心业务场景:
业务侧需频繁进行「设备静态信息 + 动态事件」关联分析(如 “查询 2025 年 Q1 某型号 SKU 的故障次数与维保记录关联”“实时统计产线设备在线率与生产合格率联动数据”)。
高并发下查询性能瓶颈:
智能家居高峰时段(如晚 19:00-24:00),设备每秒上报数百条事件数据,同时业务侧有数十个生产监控看板、报表系统并发查询。Amazon Aurora MySQL 虽支持主从分离(主库写、从库读),但面对「多表关联 + 大结果集查询」(如跨设备表、事件表、生产订单表的三表 Join),从库查询延迟常从 100ms 飙升至 3~8s,严重影响生产监控实时性。
针对上述痛点,我们建议将这些场景迁移至 Amazon Aurora DSQL(分布式 SQL 数据库),核心思路是 “以分布式架构匹配制造数据的高并发、大容量特性,通过托管式能力大幅度降低运维成本”,以下是架构设计细节:
[推荐架构]
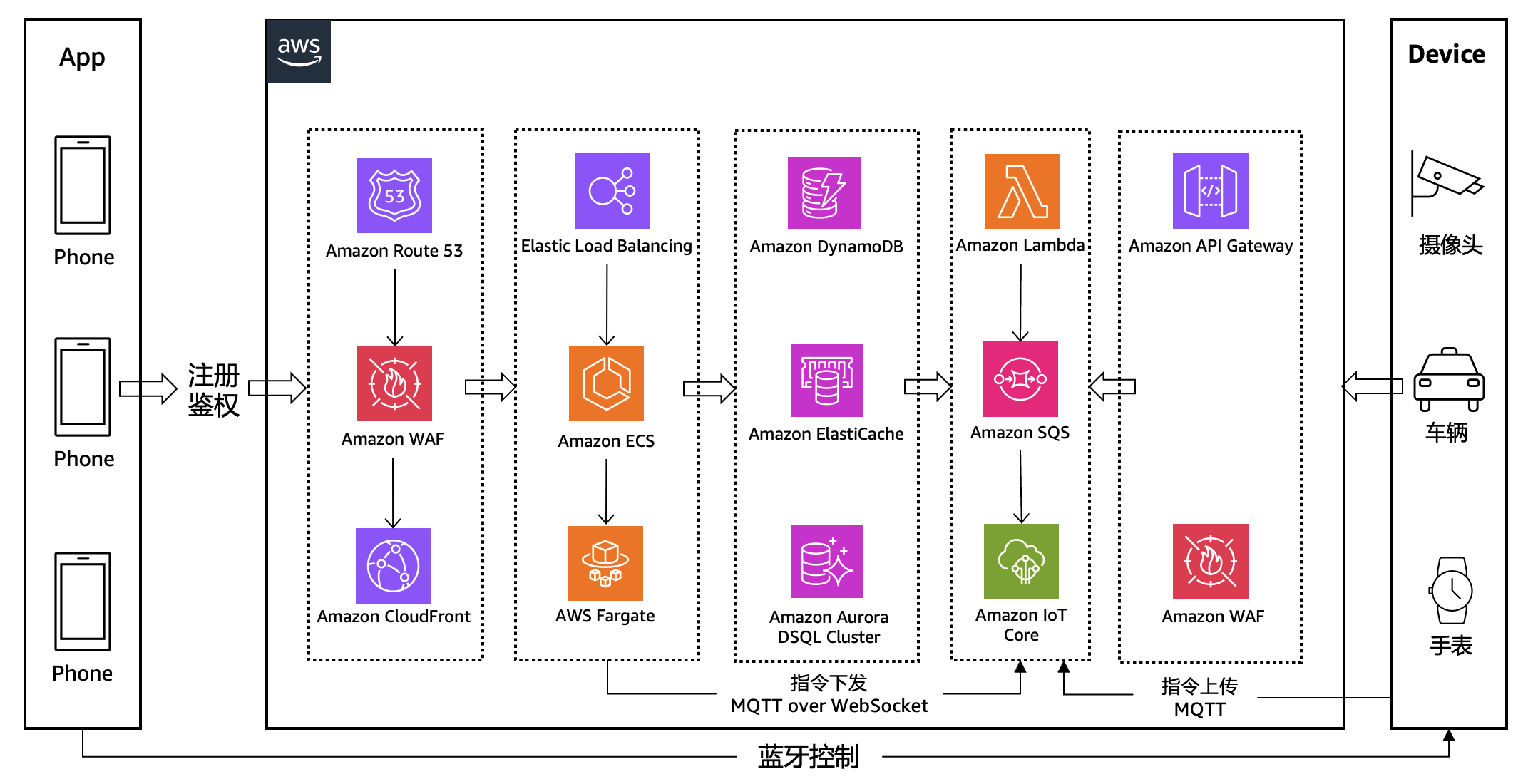 |
计算与存储分离:应对并发查询不降级
Amazon Aurora DSQL 采用 “计算节点独立扩展” 设计:
分片计算节点:负责 SQL 解析、分布式执行(如跨分片 Join、聚合),可根据并发量自动扩缩容资源,无需手动接入修改.而且能实现数据自动分片能力,无需手动进行数据分片设计.
托管式运维:彻底告别手动升级
Amazon Aurora DSQL 作为 AWS 托管的分布式数据库,核心优势在于 “全生命周期自动化”:
版本升级:AWS 自动完成引擎更新、安全补丁,且采用 “滚动升级” 策略(先升级备用分片,再切换流量),无感知 downtime,完全适配制造行业 7×24 小时生产需求;
故障自愈:分片计算节点故障时,元数据服务自动将流量切换至备用节点,存储节点故障则通过多副本自动恢复(RPO=0),无需运维人员介入。
关联分析优化:适配制造业务复杂查询
制造业务常需 “多维度关联”(如 “设备信息 + 故障事件 + 维保记录 + 生产订单” 四表 Join),Amazon Aurora DSQL 通过两项能力优化:
1.分布式 Join 引擎:支持 “分片内 Join + 跨分片 Shuffle Join”,例如 “设备表(按设备 ID 分片)与故障表(同设备 ID 分片)” 可在分片内完成 Join,无需跨节点传输大量数据;
2.列存引擎支持:对设备信息、维保记录等静态数据启用列存(Columnar Storage),分析场景下(如 “统计各型号设备故障率”)扫描效率提升 3-5 倍,满足生产周报、月报的快速生成需求。
Amazon Aurora DSQL 带来的收益
架构迁移不仅解决了技术痛点,更直接赋能制造业务:
实时决策提速:设备故障告警从 “查询延迟 2s” 降至 “实时触发”,运维团队可在 1 分钟内响应故障,生产停机时间减少 30%;
数据价值深挖:支持 “全量设备 + 5 年历史数据” 的关联分析,例如通过分析 “设备使用时长 – 故障频率” 关系,优化维保周期, 国内某智能制造厂商已经将单表亿级别规模的数据表逐步迁移到了 Amazon Aurora DSQL 上;
业务扩展性增强:当前架构已支持接入 千万台设备(原架构上限 百万台),后续新即便是做活动/促销等扩充规模无需重构数据库,满足未来 3-5 年业务增长需求。
场景适配能力: 当前架构无需再为数据量和使用场景去做集群配置的规划,不用再进行各种服务器实例的选择。
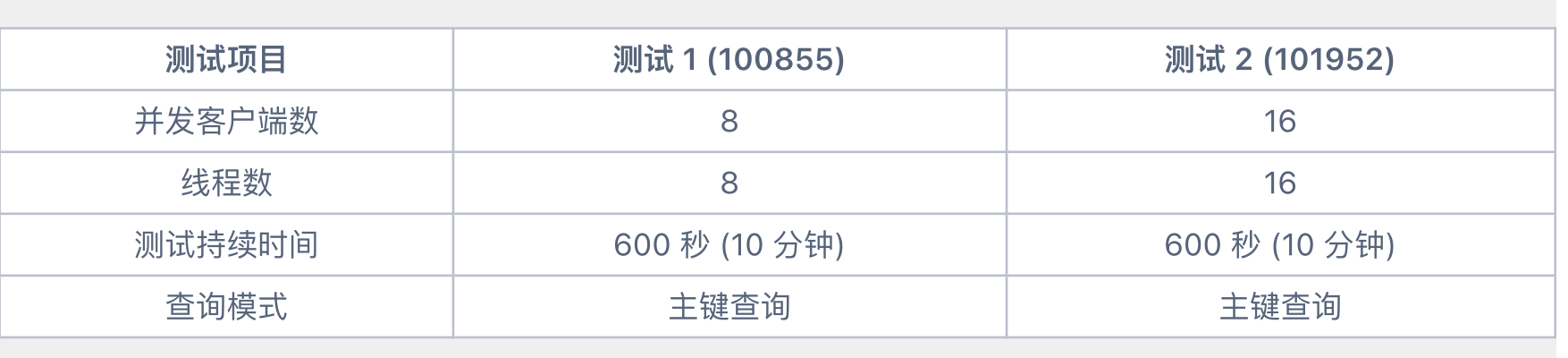
以下是来自真实 IOT 客户的压测报告:
压测环境
数据量: 5 千万条记录
硬件配置: 8 核 Linux 机器
PostgreSQL
版本: 16.10
pgbench 版本: 17.6
测试时间: 2025 年 8 月 20 日
测试场景描述
 |
性能指标对比
吞吐量 (TPS)
 |
延迟性能
 |
测试结论
1. 线性扩展性优秀:从 8 并发到 16 并发, 并发翻倍,性能几乎翻倍。
2. 延迟控制良好: 高并发下延迟增幅控制在可接受范围,标准差控制在较低水平,说明延迟波动不大。
3. 系统稳定性高: 长时间压测无失败事务。
4. 资源利用充分: 8 核机器在 16 并发下仍有扩展空间。
最佳实践
使用建议
1.JAVA应用IAM认证
Amazon Aurora DSQL目前只支持IAM认证登陆,可以直接使用 Amazon Aurora DSQL 提供的 Admin 账号登陆或者使用 custom database role,通过 JAVA 代码在 Druid 连接池配置 IAM 登陆认证的代码如下:
2.连接池参数配置
Amazon Aurora DSQL 目前有最大连接超时时间60 minutes 和token 15 minutes失效的限制 ,所以需要在连接池配置连接最大存活时间在token失效前进行主动刷新。
性能优化
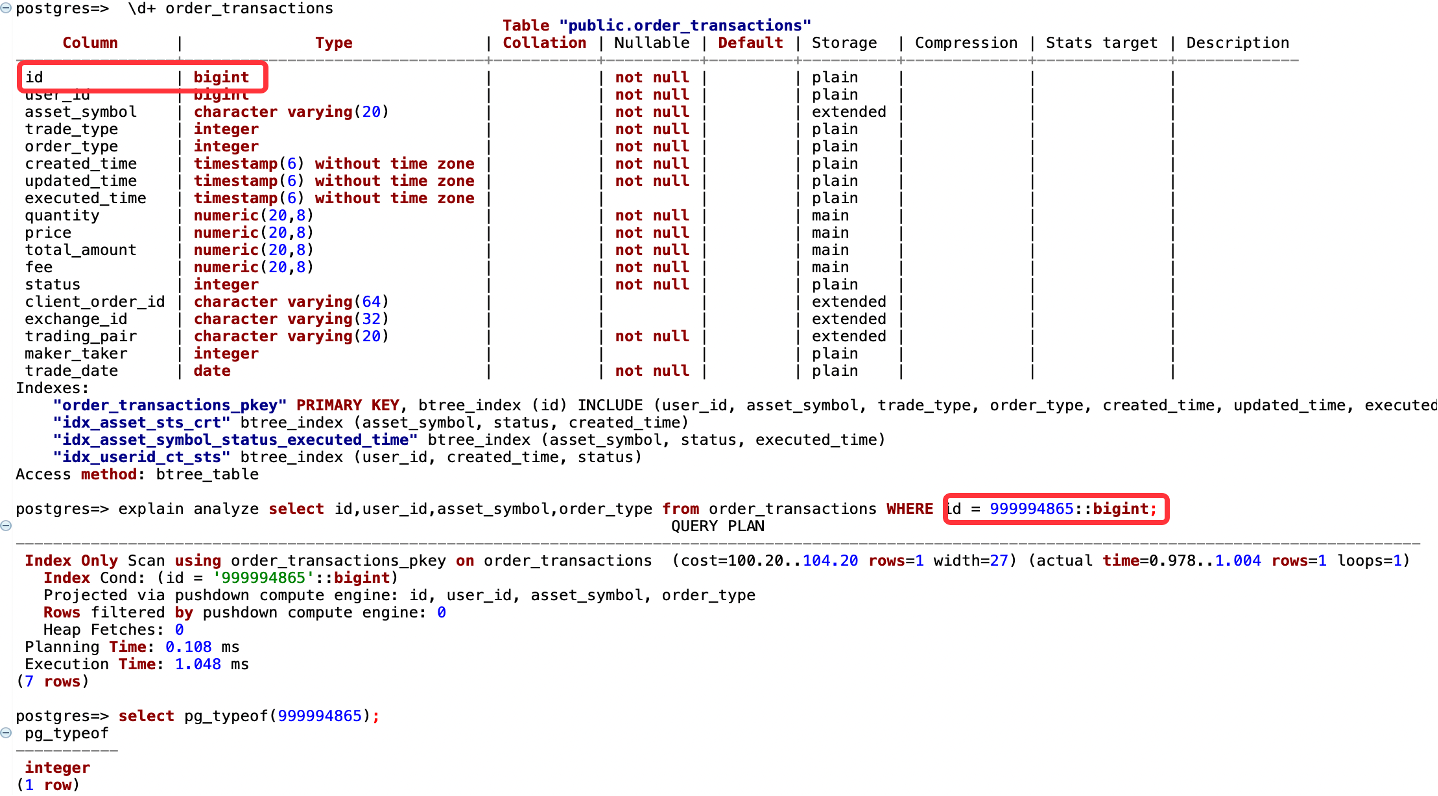
目前 Amazon Aurora DSQL 对数值类型做等值查询也会存在类型一致性要求,比如integer=bigint,索引下推不会生效,需要显示进行一致类型转换,类型自动转换功能已计划支持。
 |
Copy+批量提交提升写入性能, JAVA代码示例:
JAVA代码参考copymanager
https://github.com/pgjdbc/pgjdbc/blob/master/pgjdbc/src/test/java/org/postgresql/test/jdbc2/CopyTest.java#L220
迁移方案
数据库 Schema 的迁移,可以使用 Amazon Q + MCP 的方式进行迁移。
 |
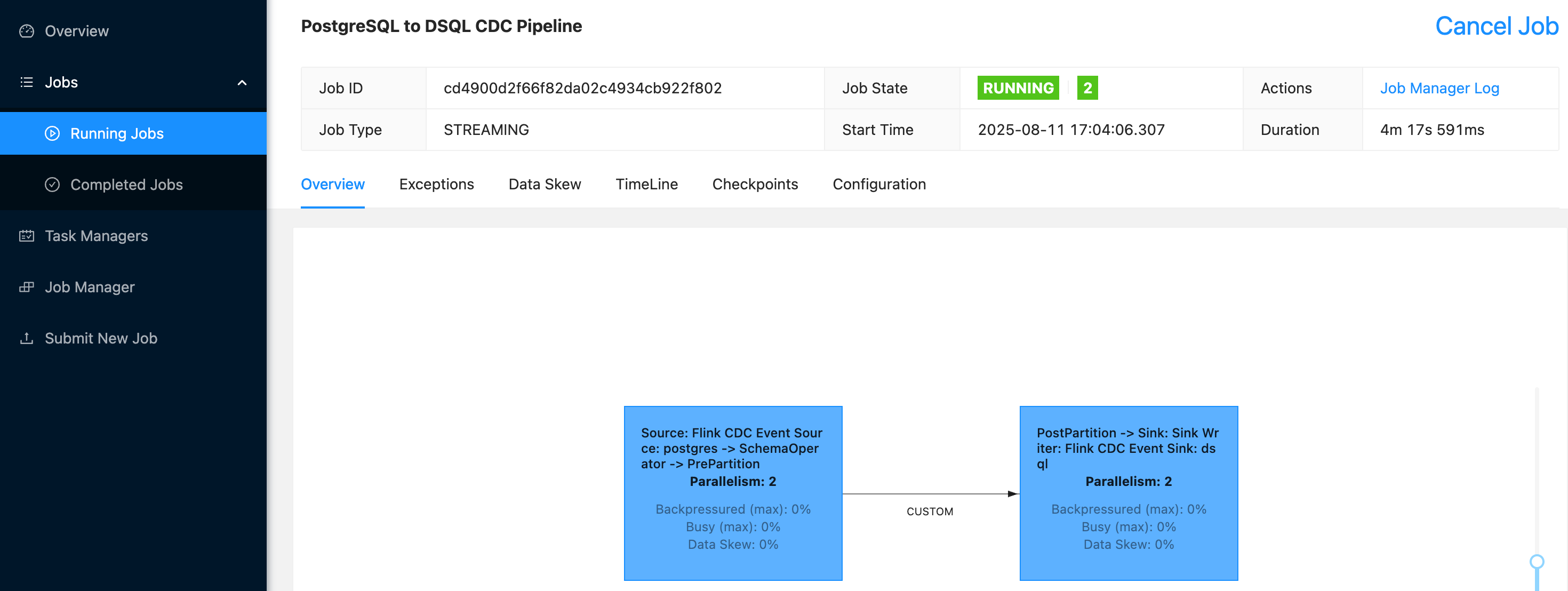
对于数据迁移,通过对Flink CDC进行改造,目前已支持从 MySQL 或者 PostgreSQL 迁移到 Amazon Aurora DSQL,包括表结构迁移,全量数据迁移和 CDC 同步。迁移完 Schema 和全量数据,CDC 同步没有延迟,即满足应用割接的条件,选择业务低峰进行连接地址切换即可。
 |
总结
Amazon Aurora DSQL 通过自动数据分区和资源动态扩缩容能力,成功解决了物联网场景下的数据存储与处理挑战。其分布式Active-Active架构不仅确保了数据的高可用性和一致性,更实现了全自动化运维。这些技术优势不仅适用于物联网领域,对于电商平台的高频交易场景、金融行业的交易系统、游戏行业的在线服务等高可用、跨区域、大规模数据处理场景同样具有重要价值。未来,Amazon Aurora DSQL有望在更多需要弹性伸缩、高可用、强一致性的行业场景中发挥重要作用,助力企业数字化转型。
参考链接
Amazon DSQL 产品概览
Amazon DSQL 产品用户指南
Amazon DSQL 产品常见问题列表
Amazon Aurora DSQL MCP Server | AWS MCP Servers
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。