亚马逊云科技正式推出 Amazon Nova 多模态嵌入模型(Amazon Nova Multimodal Embeddings)——这是一款最先进的多模态嵌入模型,专为智能体增强检索生成(Agentic RAG) 和语义搜索应用而设计,现已在 Amazon Bedrock 上提供。
它是首个支持文本、文档、图像、视频和音频的统一嵌入模型,可实现高精度的跨模态检索。
本文将介绍:
- Nova Multimodal Embeddings (简称Nova MME)模型核心特性
- API使用介绍和代码示例
- 检索链路构建
- 实际应用场景
- 可用性与定价
模型核心特性
什么是嵌入模型
嵌入模型会将文本、图像、音频等输入转换为数值表示,称为嵌入(Embedding)。
嵌入是大型语言模型(LLM)理解语义的基础,使其能在下游任务中表现出色,比如聚类、分类、排名等。在检索场景,如检索增强生成(RAG)中,嵌入可用于改进提示词的召回精度。
如何使用嵌入模型
下表总结了嵌入模型的主要使用方法:
| 用例 |
代表示例 |
数据 |
嵌入模型使用 |
下游算法 |
评估方法 |
| 检索 |
用户在知识库中检索相关文档 |
千条已有文档(每个查询也准备“正对”(相关文档)和“负对”(不相关文档)) |
对所有文档 + 查询生成嵌入,存到向量数据库或内存矩阵中 |
对每个查询,计算其与数据库中每条文档嵌入的相似性(如余弦相似度);取 top-K 最近邻。检查是否检出相关文档 |
定性:手工查看 top-K 检索结果好坏。
定量:Recall@K、NDCG@K 等指标 |
| 聚类 |
将大量用户反馈按主题自动分类 |
千条用户反馈 (未标注或部分标注类别) |
为所有项目生成嵌入并存储 |
对嵌入向量执行聚类算法(如 k-means、DBSCAN);查看聚类是否反映自然类别 |
定性:检查每个聚类内部项目是否语义一致。
定量:Silhouette 分数、ARI(Adjusted Rand Index)等 |
| 分类 |
工单自动分类(bug/需求/账单等) |
几千条工单 + 标签 |
为每条数据生成嵌入,作为特征输入 |
在嵌入上训练一个简单分类器(如逻辑回归、SVM、MLP)→ 预测标签 |
定性:查看错误分类的案例。
定量:Accuracy、F1 分数等指标 |
| 排名 |
电商平台中,根据用户查询对商品按相关度排序 |
查询日志 + 商品集合 + 标注(是否购买的规则性标注或人工标注的 “更相关” vs “次相关”) |
为查询 + 商品描述生成嵌入 |
对每个查询,计算查询嵌入与各商品嵌入的相似度,得到排序;评估排序效果 |
定性:查看用户点击最高的是否在排序前列。
定量:平均排序位置(Mean Reciprocal Rank, MRR)、NDCG@K 等 |
Nova MME模型可以在广泛的业务场景发挥作用。下面的表格和案例提供了典型用例以供您构思:
| 模态 |
内容类型 |
应用领域 |
典型查询示例 |
| 视频检索 |
短视频搜索 |
素材库/媒体管理 |
“儿童拆开圣诞礼物的画面”、”蓝鲸从海面跃起的瞬间” |
| 长视频片段查找 |
影视娱乐、广播媒体、安防监控 |
“电影中特定场景”、”新闻中的特定画面”、”监控中的特定行为” |
| 重复内容识别 |
媒体内容管理 |
相似或重复视频识别 |
| 图像检索 |
主题图像查找 |
素材库/存储/媒体管理 |
“敞开天窗的红色汽车沿海岸行驶” |
| 图像参考搜索 |
电商、设计 |
“与此类似的鞋子” + <图像> |
| 反向图像搜索 |
内容管理 |
基于上传图像查找相似内容 |
| 文档检索 |
特定信息页面 |
知识检索增强 |
文本信息、数据表格、图表页面定位 |
| 跨页面综合信息 |
知识检索增强 |
多页面的文本/图表/表格综合信息提取 |
| 文本检索 |
主题信息检索 |
知识检索增强 |
“反应堆退役后操作流程的下一步骤” |
| 文本相似度分析 |
媒体内容管理 |
标题重复检测 |
| 主题自动聚类 |
金融、医疗健康 |
症状分类归纳 |
| 上下文关联检索 |
金融、法律、保险 |
“企业检查意外事件违约的最高索赔额” |
| 音频/语音检索 |
短音频搜索 |
素材库/媒体资产管理 |
“圣诞节音乐铃声”、”自然宁静音效” |
| 长音频片段查找 |
播客、会议记录 |
“播客主讲人讨论神经科学与睡眠对大脑健康影响” |
高光案例速览
无论是复杂的跨模态查询(如文搜图与文搜音频等),还是高精度单模态检索(如人脸识别),Nova MME 都能应对。以下是部分高光案例的视觉效果预览,详细代码和实现机制请参阅下方“业务案例”章节。
电商商品分类:精准细粒度识别
人脸识别:精准人脸匹配高鲁棒性
文搜图:语义理解深度匹配
文档检索:复杂文档结构化理解
听歌识曲:高准确率音频指纹识别
文搜音频:文本音频深度语义关联
为什么需要多模态嵌入
如今,组织越来越需要从大量分散在不同形式(文本、图像、文档、视频、音频)中的非结构化数据中挖掘洞见。例如,一个企业可能同时拥有:产品图片,含有图文信息的宣传册,用户上传的视频片段。虽然嵌入模型可以帮助释放这些数据的价值,但传统模型往往只擅长处理某一种模态的数据。这种限制迫使客户要么构建复杂的跨模态嵌入解决方案,要么只能局限在单一模态的应用场景中。同时,对于混合模态内容(例如带插图的文档,或同时包含视觉、音频和字幕信息的视频),现有模型也难以有效捕捉模态之间的关联。
Nova Multimodal Embeddings 的优势
Nova 多模态嵌入模型提供了一个统一的语义空间,支持以下模态:
- 文本(Text)
- 文档(Document)
- 图像(Image)
- 视频(Video)
- 音频(Audio)
典型应用包括:
- 针对混合模态内容的跨模态搜索
- 以图搜图(使用参考图片进行搜索)
- 检索包含视觉信息的文档等。
技术支持:
- 上下文长度:最长支持 8K tokens
- 语言支持:可处理多达 200 种语言的文本
- 接口类型:支持同步和异步 API
- 分段处理(Segmentation/Chunking):可将长文本、视频或音频划分为多个可管理片段,为每部分生成嵌入
- 输出维度:提供 4 种嵌入维度选项(3072/1024/384/256),采用 Matryoshka Representation Learning(MRL) 技术训练,在保持精度的同时实现低延迟的端到端检索。
- 输入方法:您可以通过指定S3 URI或作为base64编码内联传递要嵌入的内容。
- 图像 Embedding 的低和高细节选项:对于文档 Embedding 用例或当图像包含文本时,使用DOCUMENT_IMAGE(高细节)。对于其他类型的视觉内容,选择STANDARD_IMAGE(低细节)以降低成本。
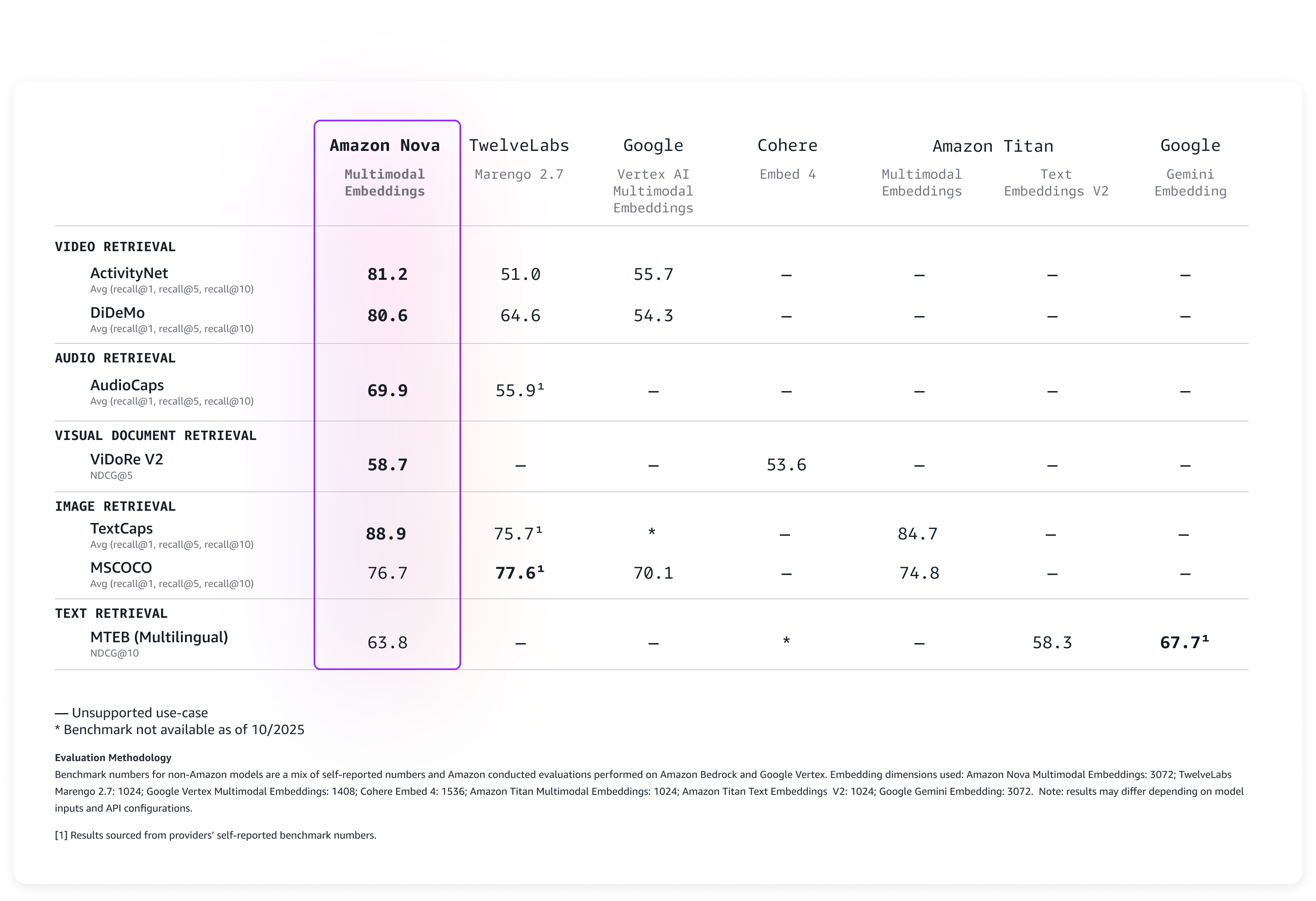
性能评估
我们在多项权威基准测试上对该模型进行了评估,结果显示 Nova Multimodal Embeddings 在开箱即用的情况下已具备业界领先的准确率,如下表所示:
Amazon Nova Embeddings 基准测试结果
API使用介绍和代码示例
下面的示例展示了如何使用 AWS SDK for Python(Boto3) 调用Nova MME的同步和异步嵌入API。
同步Embedding生成
对于较小的内容项,您可以使用Bedrock Runtime InvokeModel API实时生成。这是为文本、图像或短音频/视频文件快速生成embeddings的好选择。
Payload及参数说明(见备注)
request_body = {
"schemaVersion": "nova-multimodal-embed-v1", # 模型请求架构版本(默认 nova-multimodal-embed-v1)
"taskType": "SINGLE_EMBEDDING", # 嵌入任务类型:同步调用时必须为 SINGLE_EMBEDDING
"singleEmbeddingParams": {
# embeddingPurpose: 嵌入用途(根据使用场景优化效果)
# 可选值:
# - GENERIC_INDEX 建立索引(index)
# - GENERIC_RETRIEVAL 搜索混合模态存储库
# - TEXT_RETRIEVAL 搜索仅含文本嵌入
# - IMAGE_RETRIEVAL 搜索仅含图像嵌入(STANDARD_IMAGE)
# - VIDEO_RETRIEVAL 搜索视频或音视频联合嵌入
# - DOCUMENT_RETRIEVAL 搜索文档(DOCUMENT_IMAGE)嵌入
# - AUDIO_RETRIEVAL 搜索音频嵌入
# - CLASSIFICATION 分类任务
# - CLUSTERING 聚类任务
"embeddingPurpose": "GENERIC_INDEX",
# embeddingDimension: 向量维度(默认 3072)
# 可选值: 256 | 384 | 1024 | 3072
"embeddingDimension": 3072,
# text: 文本内容输入(text、image、video、audio 中必须且只能有一个)
"text": {
# truncationMode: 当文本超出最大长度时的截断策略
# START - 从开头截断
# END - 从结尾截断
# NONE - 超出则报错
"truncationMode": "END",
# value: 要生成嵌入的文本内容(最大 8192 字符)
# 可与 source 互斥(必须二选一)
"value": "string",
# source: S3 文件引用(SourceObject 类型,参见通用对象定义)
"source": "SourceObject"
},
# image: 图像内容输入
"image": {
# detailLevel: 图像分辨率层级(默认 STANDARD_IMAGE)
# STANDARD_IMAGE 低分辨率
# DOCUMENT_IMAGE 高分辨率,更适合含文本图像
"detailLevel": "STANDARD_IMAGE",
# format: 图像格式
# 可选值: png | jpeg | gif | webp
"format": "png",
# source: 图像文件来源(SourceObject 类型)
"source": "SourceObject"
},
# audio: 音频内容输入(最大长度 30 秒)
"audio": {
# format: 音频格式
# 可选值: mp3 | wav | ogg
"format": "mp3",
# source: 音频文件来源(SourceObject 类型)
"source": "SourceObject"
},
# video: 视频内容输入(最大长度 30 秒)
"video": {
# format: 视频格式
# 可选值: mp4 | mov | mkv | webm | flv | mpeg | mpg | wmv | 3gp
"format": "mp4",
# source: 视频文件来源(SourceObject 类型)
"source": "SourceObject",
# embeddingMode: 视频嵌入模式
# AUDIO_VIDEO_COMBINED - 生成一个结合音频与视觉内容的嵌入
# AUDIO_VIDEO_SEPARATE - 分别生成音频与视觉的两个嵌入
"embeddingMode": "AUDIO_VIDEO_COMBINED"
}
}
}
InvokeModel Request
import json
import boto3
# 创建Bedrock Runtime客户端
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1",
)
try:
# 调用Nova Embeddings模型
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body, indent=2), # 上面定义的payload
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
accept="application/json",
contentType="application/json",
)
except Exception as e:
print(e)
print("Request ID:", response.get("ResponseMetadata").get("RequestId"))
response_body = json.loads(response.get("body").read())
print(json.dumps(response_body, indent=2))
InvokeModel Response
当 InvokeModel 返回成功结果时,响应(response)将具有以下结构:
{
"embeddings": [
{
# embeddingType: 嵌入向量类型
# 可选值: TEXT | IMAGE | VIDEO | AUDIO | AUDIO_VIDEO_COMBINED
"embeddingType": "TEXT",
# embedding: 生成的向量(浮点数数组)
"embedding": [0.123, -0.456, ...],
# truncatedCharLength: (可选)若文本被截断,则返回被截断的字符位置
"truncatedCharLength": 8120
}
]
}
异步嵌入生成
对于较大的内容文件,您可以使用Bedrock Runtime StartAsyncInvoke函数异步生成嵌入。您可以提交作业并稍后检索结果,结果会保存到Amazon S3。以下是视频文件异步嵌入生成作业的示例:
request_body = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": 3072,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": "s3://<source-bucket>/path/to/video.mp4"}
},
"segmentationConfig": {
"durationSeconds": 15 # 分段为15秒块
},
},
},
}
import boto3
# 创建Bedrock Runtime客户端
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1",
)
try:
# 调用Nova Embeddings模型
response = bedrock_runtime.start_async_invoke(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
modelInput=request_body,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": "s3://<destination-bucket>"
}
},
)
except Exception as e:
print(e)
print("Request ID:", response.get("ResponseMetadata").get("RequestId"))
print("Invocation ARN:", response.get("invocationArn")) # 打印调用ARN
输出将如下所示:
Request ID:07681e80-5ce0-4723-cf52-68bf699cd23e
Invocation ARN:arn:aws:bedrock:us-east-1:<account-id>:async-invoke/g7ur3b32a10n
启动异步作业后,您可以使用 invocationArn 定期调用 [GetAsyncInvoke] 函数检查作业状态。您也可以使用 [ ListAsyncInvokes] 函数获取最近的异步调用及其状态列表。
异步嵌入生成完成后,生成的结果将写入您指定的 S3 存储桶。文件结构如下:
<destination-bucket>/
<job-id>/
segmented-embedding-result.json
embedding-audio.jsonl
embedding-image.json
embedding-text.jsonl
embedding-video.jsonl
manifest.json
embeddingPurpose参数解释
Amazon Nova Embeddings 的 embeddingPurpose 参数用于优化两种不同的向量化策略:检索系统模式和ML任务模式。
检索系统模式(包含 GENERIC_INDEX 和各种 *_RETRIEVAL 参数)针对的是信息检索场景,它区分了“存储/INDEX”和”查询/RETRIEVAL”两个非对称的阶段——存储时需要完整保留文档信息,查询时需要优化查询与文档的匹配度,因此同一个检索系统中会使用两种不同的嵌入策略。检索系统类别与参数选择参考下表:
| 阶段 |
参数选择 |
原因 |
| 存储阶段(所有类型) |
GENERIC_INDEX |
优化用于作为索引存储 |
| 查询阶段(混合模态库) |
GENERIC_RETRIEVAL |
在混合内容中搜索 |
| 查询阶段(纯文本库) |
TEXT_RETRIEVAL |
在纯文本中搜索 |
| 查询阶段(纯图片库) |
IMAGE_RETRIEVAL |
在纯图片中搜索(照片、插图等) |
| 查询阶段(纯文档图像库) |
DOCUMENT_RETRIEVAL |
在文档图像中搜索(扫描件、PDF截图等) |
| 查询阶段(纯视频库) |
VIDEO_RETRIEVAL |
在纯视频中搜索 |
| 查询阶段(纯音频库) |
AUDIO_RETRIEVAL |
在纯音频中搜索 |
而ML任务模式(包含 CLASSIFICATION 和 CLUSTERING 参数)针对的是机器学习场景,这个参数使模型能够灵活适应不同类型的下游任务需求。这两个参用于将数据转换为适合特定ML任务的向量,不区分”存储”和”查询”阶段。对所有相关数据(无论是训练集、测试集还是新数据)都使用相同的参数。
CLASSIFICATION:生成的向量更适合分类边界的区分,便于下游训练分类器或直接进行分类。
CLUSTERING:生成的向量更适合聚类中心的形成,便于下游聚类算法。
更多代码样例可参考AWS博客(https://aws.amazon.com/cn/blogs/aws/amazon-nova-multimodal-embeddings-now-available-in-amazon-bedrock/)和官方Github示例代码(https://github.com/aws-samples/amazon-nova-samples/tree/main/multimodal-embeddings)
检索链路构建
Amazon Nova多模态嵌入模型专为Agentic RAG与语义搜索量身打造。在典型的检索系统中,首先将文本、图像、音频或视频等原始内容通过嵌入模型转换为向量表示,从而捕捉其语义特征。然后将这些向量构建索引或存入向量数据库(如 FAISS、Amazon OpenSearch Service,更多亚马逊云科技向量数据库选型请见博客)。用户查询也被转换成同一向量空间的查询向量,通过计算查询向量与索引中向量的相似度来获得 Top-K 最相关项。最后,可通过融合关键词检索、投票机制等策略,对结果进行重排序或整合,以输出精确且符合业务需求的检索结果。下表总结了检索链路的常见模块:
| 模块 |
说明 |
常见工具/技术 |
| Embedding 生成 |
将输入(文本、图像、音频、视频等)转换为向量表示 |
闭源模型(如Nova MME模型)
/开源模型 |
| 索引构建(向量存储) |
将生成的向量存入向量数据库或存储结构,以便后续检索 |
FAISS, ChromaDB,
Amazon OpenSearch Service,
Amazon S3 Vectors |
| 相似度检索算法 |
使用查询向量与索引中的向量计算相似度/距离,并检索最接近的项 |
常用距离:余弦相似度、内积、欧氏距离;数据库支持 k-NN、ANN,如 AWS OpenSearch k-NN |
| Top-K 检索 & 投票机制 |
从检索结果中选取 top-K 最近邻,然后可能结合多种策略(投票、重排序、融合) |
例如 top-K 最近邻、融合关键词检索+向量检索(混合搜索) |
| 整合策略/混合检索 |
将多种检索机制或模态结果结合,如关键词 + 向量、文本 + 图像检索融合 |
混合搜索(如 OpenSearch hybrid) |
| 重排序/后处理 |
在初步检索结果基础上做进一步排序、过滤、聚合等 |
重排序可用模型打分、用户反馈、元数据过滤 |
| 评估/监控 |
检查检索链路效果,包含定性与定量指标 |
定量指标:Recall@K、NDCG@K、Accuracy、F1、Silhouette 等;定性检查 |
可以发现,让检索链路效果更好,构建更简单,落地更快取决于选用强大的的嵌入模型,维度、语言、模态等多方面的支持需符合用例。而Nova MME的跨模态多语言能力很好地支撑了这一需求。下表总结了Nova MME模型在同步和异步嵌入模式下对不同模态的支持情况:
| A |
同步嵌入生成 |
异步嵌入生成 |
| API接口 |
Amazon Bedrock的 InvokeModel |
Amazon Bedrock Runtime API 的 StartAsyncInvoke、GetAsyncInvoke 和 ListAsyncInvokes |
| 文件类型 |
文本、图像、视频 |
文本、图像、视频 |
| 输入大小限制 |
inline内联(任何模态):25MB
S3 文本:最大值(50,000 字符, 2GB)
S3 图像:64MB
S3 视频:最大值(30秒, 2GB) |
S3 文本:2GB
S3 图像:100MB
S3 视频:2GB |
| 输入方法 |
inline内联块和 S3 |
S3 |
| 图像格式 |
png, jpeg, gif, webp |
png, jpeg, gif, webp |
| 视频格式 |
mp4, mov, mkv, webm, flv, mpg, wmv, 3gp |
mp4, mov, mkv, webm, flv, mpg, wmv, 3gp |
| 音频格式 |
wav, mp3, flack, ogg, m4a |
wav, mp3, flack, ogg, m4a |
| 输出 |
inline内联响应 |
S3 |
如上,Nova MME模型可以基于文本、图像、视频、音频和语音生成embedding,以实现单模态、跨模态和多模态向量检索。根据Nova MME模型在检索中的查询模态 → 目标模态,梳理典型使用方式和业务场景如下:
(优先级依据实际业务价值与工程实现难度及成本推荐,实际请根据具体场景测试评估)
| 查询模态 |
目标模态 |
使用方法 |
商用场景/行业 |
优先级 |
| Text |
Text |
文本 搜 文本—从文本库检索最相关文本 |
经典语义检索,知识库检索,客服自动回复 |
1 |
| Text |
Image |
文本 搜 图像—根据文字描述查找符合的图片 |
相册智能云存,电商商品搜图,营销设计图库检索 |
1 |
| Text |
Video |
文本 搜 视频—根据文字说明检索视频片段 |
如”如何做披萨”→教程(在线教育),内容营销视频库,安防检查 |
1 |
| Text |
Audio |
文本 搜 音频—如”雨声背景音乐”→音频素材 |
媒体制作/广告音效库 |
1 |
| Text |
Doc |
文本 搜 文档—如”2025年财务预测数据” |
知识检索增强 |
1 |
| Image |
Text |
图像 搜 文本—以图片查找对应文字/文章 |
媒体新闻图像逆向检索(版权/出版) |
2 |
| Image |
Image |
图像 搜 图像—找相似/重复图片,用于图库清理 |
图库管理,社交媒体去重,摄影机构 |
1 |
| Image |
Video |
图像 搜 视频—图片查找对应或类似视频 |
电商(产品图片→演示视频)、制造业产品说明,监控关键帧提取 |
2 |
| Image |
Audio |
图像 搜 音频—图片查找相关音频(如背景音乐) |
旅游影音内容整合、广告创意库 |
3 |
| Video |
Text |
视频 搜 文本—视频片段→相关文章/说明文 |
媒体内容归档/教育课件索引/视频自动打标 |
2 |
| Video |
Image |
视频 搜 图像—从视频检索关键帧/物品 |
监控/安防关键内容查找,小视频产品引流 |
2 |
| Video |
Video |
视频 搜 视频—找相似或重复视频片段 |
社交媒体/短视频平台去重、版权审查 |
1 |
| Video |
Audio |
视频 搜 音频—视频→纯音频版本或相关音频 |
播客/视频转音频服务、媒体重用(审查) |
3 |
| Audio |
Text |
音频 搜 文本—如一段录音→对应文字稿/文章 |
语音转写+内容检索、法律证据音频检索 |
2 |
| Audio |
Image |
音频 搜 图像—音频查找视觉相关 |
(如音乐专辑封面、演唱会照片)音乐内容管理,音乐书签生成 |
3 |
| Audio |
Video |
音频 搜 视频—听一段音频→找到对应MV/视频 |
音乐流媒体、视频剪辑 |
2 |
| Audio |
Audio |
音频 搜 音频—听歌识曲/找相似音效/重复音频 |
音乐识别服务、音效库管理,版权检查 |
1 |
以下是一个简单的案例代码展示Nova MME集成的检索链路—-创建AWS OpenSearch索引,Nova MME生成嵌入,用OpenSearch支持的k-NN算法实现文本到文本检索:
# 仅展示核心代码,省略 0. 创建OpenSearch集群和索引
# 1. 用Nova MME生成文本嵌入
def get_nova_embedding(text):
request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "TEXT_RETRIEVAL",
"text": {"truncationMode": "END", "value": text}
}
}
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(request)
)
return json.loads(response['body'].read())['embeddings'][0]['embedding']
# 2. 索引文档,存储到AWS OpenSearch
docs = [{"title": "机器学习基础", "content": "机器学习是人工智能的核心技术,包括监督学习、无监督学习和强化学习等方法。"}]
for i, doc in enumerate(docs):
text = f"{doc['title']} {doc['content']}"
embedding = get_nova_embedding(text)
opensearch_client.index(
index=INDEX_NAME,
id=i+1,
body={
"title": doc["title"],
"content": doc["content"],
"embedding": embedding
},
refresh=True
)
# 3. query文字用Nova MME生成嵌入,基于Opensearch的K-NN算法基于向量相似度排序返回topK结果
def search_text(query, top_k=3):
query_embedding = get_nova_embedding(query)
search_query = {
"size": top_k,
"query": {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "knn_score",
"lang": "knn",
"params": {
"field": "embedding",
"query_value": query_embedding,
"space_type": "cosinesimil"
}
}
}
},
"_source": ["title", "content"]
}
response = opensearch_client.search(body=search_query, index=INDEX_NAME)
for i, hit in enumerate(response["hits"]["hits"]):
print(f"{i+1}. {hit['_source']['title']} (相似度: {hit['_score']:.4f})")
print(f" {hit['_source']['content']}")
return response["hits"]["hits"]
# demo:演示搜索链路
search_text("人工智能算法") # 返回:"机器学习基础 (相似度: 1.6373) 机器学习是人工智能的核心技术...."
上面案例中介绍的AWS OpenSearch Service 负责存储和检索向量嵌入(embeddings),从而实现基于语义或相似性的快速检索;尤其是当该服务部署在 Graviton 2 架构的实例上时(AWS OpenSearch Service 使用手册与支持实例),得益于 ARM-架构的高吞吐、高缓存、低功耗特性,检索链路的索引速度、查询延迟和成本效率均可显著提升,进一步优化嵌入检索链路。
本文重点介绍模型能力,如需进一步探索向量检索技术,与数据库集成方案等,可阅读:https://aws.amazon.com/blogs/big-data/cost-optimized-vector-database-introduction-to-amazon-opensearch-service-quantization-techniques/
业务案例
视频检索
Amazon Nova Multimodal Embeddings 模型支持MP4、MOV、MKV、WEBM、FLV、MPG、WMV、3GP等主流视频格式,可以通过 Base64 编码或 Amazon S3 URI 两种方式输入视频。使用 Base64 编码时,单个文件最大支持 25MB。模型提供同步和异步两种API,同步API(invoke_model)适合短视频或实时场景,将整个视频生成单个Embedding,响应速度快;异步API(start_async_invoke):适合长视频处理和批量场景,支持视频分段(segmentation)功能,可将长视频自动切分为可管理的片段(如15秒),每个片段独立生成Embedding,便于精细化内容定位。通过 embeddingMode 参数设置为 AUDIO_VIDEO_COMBINED 可同时处理视觉和音频信息,生成融合了两种模态的统一向量。
将视频内容映射到向量空间,就可以支持文本查询→视频检索的技术。这项技术在多个场景中展现出强大能力,比如:
在素材库与媒体管理领域,当内容创作者输入像“儿童拆开圣诞礼物的画面”或“蓝鲸从海面跃起的瞬间”这样自然语言描述时,系统能够理解其语义意图并在视频素材库中检索出相应的片段;
在影视娱乐和广播媒体行业,编辑可以快速定位“电影中的特定场景”或“新闻中的特定画面”,通过将视频分片生成 Embedding、并结合时间戳或语音/字幕信息建立索引,从而使后期制作大幅提速;
在安防监控领域,安保人员能够搜索“监控中的特定行为”,例如“进入禁区”、“人员群聚”等画面,通过对监控视频做视觉+动作特征的 Embedding,再结合检索系统实现事件回溯;
此外,在媒体内容管理中,平台能够利用视频 embedding 的相似度计算来识别重复或高度相似的视频内容,从而有效防止内容重复上传、提高版权保护效果。
实战案例:体育赛事精彩片段检索
让我们通过一个体育视频检索的案例来展示 Nova Multimodal Embeddings 的实际应用。假设某体育媒体平台拥有大量的比赛录像,需要让编辑能够快速找到特定的比赛片段,例如”新英格兰爱国者队多名球员对踢球手施压并阻挡,球滚出界外,进攻未果,失去球权”这样复杂的多动作场景。
 |
# 1. 用Nova MME 读取视频并生成 embedding
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
with open('game_highlight.mp4', 'rb') as f:
video_bytes = base64.b64encode(f.read()).decode('utf-8')
video_request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": 1024,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {"bytes": video_bytes}
}
}
}
response = bedrock.invoke_model(
modelId='amazon.nova-2-multimodal-embeddings-v1:0',
body=json.dumps(video_request)
)
video_embedding = json.loads(response['body'].read())['embeddings'][0]['embedding']
# 2. 生成查询文本的 embedding
query_text = "新英格兰爱国者队多名球员对踢球手施压并阻挡,球滚出界外,进攻未果,失去球权"
text_request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": 1024,
"text": {"truncationMode": "END", "value": query_text}
}
}
response = bedrock.invoke_model(
modelId='amazon.nova-2-multimodal-embeddings-v1:0',
body=json.dumps(text_request)
)
text_embedding = json.loads(response['body'].read())['embeddings'][0]['embedding']
# 3. 计算余弦相似度
similarity = np.dot(text_embedding, video_embedding) / (
np.linalg.norm(text_embedding) * np.linalg.norm(video_embedding)
)
print(f"相似度分数: {similarity:.4f}") #相似度分数: 0.6295
通过这种方式,编辑可以在海量的比赛录像中快速定位到包含特定动作序列的视频片段,无需逐帧查看。系统不仅理解了文本描述中的比赛信息(队伍、比分、时间),还能将其与视频中的实际画面进行语义匹配,大幅提升了内容检索的效率和准确性。这项技术同样适用于新闻视频的事件检索、教育视频的内容导航、以及监控录像的智能分析等多个场景。
图像分类
用Nova MME 模型将图片生成embedding向量后,这个向量保留了该图片在视觉/语义层面的特征。我们可以把很多图像任务转化为“在向量空间里看哪些图片是彼此靠近的”“哪些图片和历史案例最相似”,从而可以做检索、聚类、分类、异常检测等。比如:
在客户报错图片检索场景中,当用户上传错误或异常图片时,我们可以将其转换为 embedding 向量并与历史故障图片库做最近邻比对,从而快速识别相似案例,并返回对应的错误原因与解决方法;
在电商商品分类或标签化场景中,商品图片通过 embedding 映射为向量后,可直接用于类别判定、属性识别或近似商品推荐,从而减少人工标注和模型重训成本;
在制造业或装配线上进行质量检测和缺陷识别时,我们可以先收集大量正常产品图片生成 embedding 分布,然后对每个新产品图片生成向量并判断其是否偏离正常分布,从而发现异常或缺陷;
在用户上传图片进行内容检索或推荐体验场景中,用户上传一张图片后,通过 embedding 检索出视觉或语义上最接近的商品/图片,从而提供“和你上传的这张类似的款式”或“同款推荐”服务。
实战案例:商品检索
下面,我们将用一个简单的案例代码展示Nova MME集成的检索链路—-采用Amazon Nova MME模型提取图像特征,结合FAISS向量检索和投票机制实现图像分类:
假设商品库中有3个类别的商品,标签为“laptop_computer”,“office_and_school_supplies”与“smart_home_products”,每个类别分别有2张图片构建索引库。
(图片来源:https://huggingface.co/datasets/iarbel/amazon-product-data-sample/viewer/default/train?views%5B%5D=train&row=13)
构建完成后分别用如下2张商品进行测试:
 |
 |
# 0. 配置
EMBEDDING_DIMENSION = 1024
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
REGION = "us-east-1"
bedrock = boto3.client('bedrock-runtime', region_name=REGION)
# 1. 用Nova MME生成图像嵌入
def get_nova_embedding(image_path):
with open(image_path, 'rb') as f:
image_bytes = base64.b64encode(f.read()).decode('utf-8')
img_format = "jpeg" if image_path.endswith('.jpg') else "png"
request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": img_format,
"detailLevel": "STANDARD_IMAGE",
"source": {"bytes": image_bytes}
}
}
}
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(request)
)
return json.loads(response['body'].read())['embeddings'][0]['embedding']
# 2. 索引图像,存储到FAISS
gallery_images = ["gallery/category_A/image_001.jpg"] # ... 更多图像
gallery_embeddings = []
gallery_metadata = []
for img_path in gallery_images:
embedding = get_nova_embedding(img_path)
gallery_embeddings.append(embedding)
gallery_metadata.append(img_path.split('/')[-1])
index = faiss.IndexFlatL2(EMBEDDING_DIMENSION)
embeddings_array = np.array(gallery_embeddings, dtype=np.float32)
index.add(embeddings_array)
# 3. query图像用Nova MME生成嵌入,基于FAISS的L2距离算法检索top-K最相似图片
def search_image(query_image_path, top_k=10):
query_embedding = get_nova_embedding(query_image_path)
query_vector = np.array([query_embedding], dtype=np.float32)
distances, indices = index.search(query_vector, top_k)
retrieved_labels = [gallery_metadata[idx] for idx in indices[0]]
for i, (distance, idx) in enumerate(zip(distances[0], indices[0])):
print(f"{i+1}. {gallery_metadata[idx]} (距离: {distance:.4f})")
label_counts = Counter(retrieved_labels) # 投票机制选择最高票标签作为query图片的预测标签,实现图片分类
predicted_label = label_counts.most_common(1)[0][0]
return predicted_label, retrieved_labels
# demo:演示搜索链路
predicted_label, results = search_image("query/test_image.jpg") # 返回:预测标签和检索结果
分类结果:
模型在第一次检索办公用品时,最相似两张图片来自同类(距离 0.9950),第三张不同类但距离跳至 1.7225;第二次检索笔记本电脑时,前两张同类距离均极小(0.4207 / 0.4366),第三张不同类距离 1.6214。由此可见:同类别图像在 embedding 空间聚集度高,不同类别之间特征边界明显,模型在类别一致性强的产品上检索精度更高。
总体而言,模型能够有效提取图像语义特征,实现准确的相似度计算和分类预测,为电商产品图像检索提供了技术支撑。
图像检索
在图像检索领域,Amazon Nova Multimodal Embeddings 模型支持 PNG、JPEG、GIF 和 WebP 等常见图像格式,可以通过 Base64 编码或Amazon S3 URI 两种方式输入。对于本地上传的图片,单个文件最大支持25MB,而通过 S3 存储的图片则可达1GB。在生成 embedding 时,开发者可以选择256、384、1024或3072四种维度以平衡精度和成本。
这项技术在多个行业场景中展现出巨大价值。在素材库和媒体管理领域,设计师可以使用自然语言描述来搜索图片,例如”敞开天窗的红色汽车沿海岸行驶”,系统能够理解语义并返回视觉上匹配的图片。在电商和设计行业,用户可以上传参考图片来查找相似商品或设计元素,这种”以图搜图”的方式让购物体验更加直观便捷。此外,在内容管理场景中,平台可以利用反向图像搜索技术检测重复内容、保护版权,或追溯图片来源。
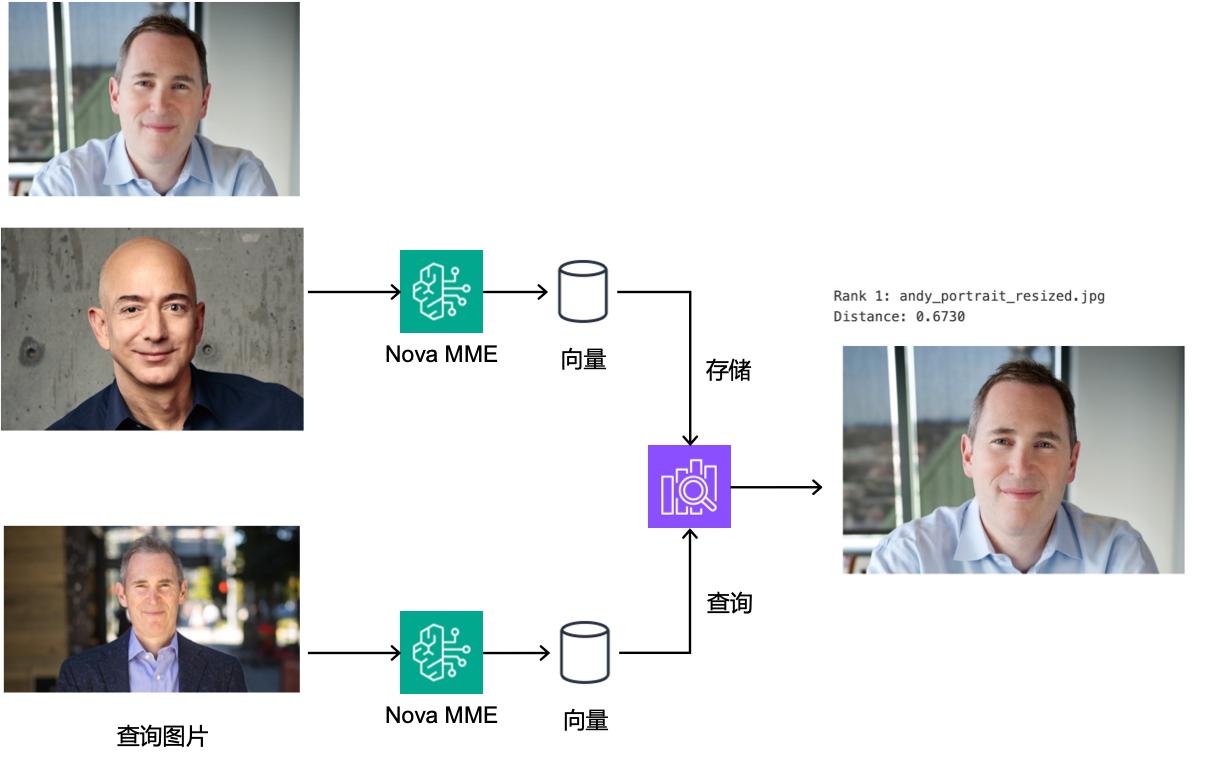
实战案例:人脸对比
在这个案例中,凭借Nova MME的多模态能力,将人脸图像转换为高维向量表示,然后通过FAISS高效的向量相似度计算快速匹配最相似的人脸,实现快速精准的人脸匹配搜索。相较于传统的像素级比较匹配,这种搜索方式能够在人物姿态,拍摄方式等因素变化下仍然保持较高的准确率。
jeff_portrait.jpg andy_portrait_resized.jpg
(图片来源:Amazon Rekognition/Face comparison) (图片来源:Amazon Rekognition/Face comparison)
将如上Andy与Jeff的两张人脸照片构建向量库。接下来,用andy_portrait_2.jpg在向量库中进行搜索:
andy_portrait_2.jpg(图片来源:Amazon Rekognition/Face comparison)
关键代码:
# 1. 用Nova MME生成人脸嵌入
def get_nova_embedding(image_path):
with open(image_path, 'rb') as f:
image_bytes = base64.b64encode(f.read()).decode('utf-8')
img_format = "jpeg" if image_path.lower().endswith(('.jpg', '.jpeg')) else "png"
request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": EMBEDDING_DIMENSION,
"embeddingPurpose": "GENERIC_INDEX",
"image": {
"format": img_format,
"detailLevel": "STANDARD_IMAGE",
"source": {"bytes": image_bytes}
}
}
}
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(request)
)
return json.loads(response['body'].read())['embeddings'][0]['embedding']
# 2. 索引人脸图像,存储到FAISS
gallery_images = [
"sample_assets/images/andy_portrait_resized.jpg",
"sample_assets/images/jeff_portrait.jpg"
]
embeddings_list = []
metadata = []
for i, img_path in enumerate(gallery_images):
embedding = get_nova_embedding(img_path)
embeddings_list.append(embedding)
metadata.append({
'filename': os.path.basename(img_path),
'index': i
})
index = faiss.IndexFlatL2(EMBEDDING_DIMENSION) # 构建FAISS索引
embeddings_array = np.array(embeddings_list, dtype=np.float32)
index.add(embeddings_array)
# 3. query人脸图像用Nova MME生成嵌入,基于FAISS的L2距离算法进行人脸检索
def search_portrait(query_image_path, top_k=2):
query_embedding = get_nova_embedding(query_image_path)
query_vector = np.array([query_embedding], dtype=np.float32)
k = min(len(metadata), top_k)
distances, indices = index.search(query_vector, k)
for i, (distance, idx) in enumerate(zip(distances[0], indices[0])):
print(f"{i+1}. {metadata[idx]['filename']} (距离: {distance:.4f})")
return distances, indices
# demo:演示人脸检索链路
distances, indices = search_portrait("sample_assets/images/andy_portrait_2.jpg") # 返回:Andy最相似
搜索结果如下,distance值越小表明图片越相似:
可以看到尽管用来搜索的照片andy_portrait_2.jpg与库中andy_portrait_resized.jpg在拍摄角度、光照条件、表情等方面存在差异,其embedding间的距离仍然是小于与jeff_portrait.jpg之间的距离,说明捕捉到了人脸的本质特征。
文档检索
在文档检索领域,Amazon Nova Multimodal Embeddings 模型支持 PDF、DOCX 的主流文档格式。对于包含图表、表格或图像的文档,推荐采用页面级图像嵌入策略:将 PDF 每一页转换为高分辨率图像后生成 Embedding,通过 detailLevel 参数设置为 DOCUMENT_IMAGE 来优化文档理解效果。这种方法能完整保留页面的视觉布局、表格结构和图表细节,避免传统 OCR 识别错误,特别适合处理财务报表、技术规格书等复杂文档。在生成 Embedding 时,需要配置两个关键参数:embeddingPurpose 在建立索引时设置为 GENERIC_INDEX,查询时设置为 DOCUMENT_RETRIEVAL;embeddingDimension 支持 256、384、1024 和 3072 四种维度,可根据应用场景在精度和性能间权衡。
这项技术在多个场景中展现出强大能力。在企业知识管理领域,员工可以使用自然语言查询来搜索内部文档,例如”2024年第三季度财报中的营收增长图表”或”产品规格文档中关于技术参数的表格”,系统能够理解文档中的文本描述和视觉元素,精确定位相关内容。在金融分析行业,分析师可以快速检索”包含资产负债表的年度报告”或”显示现金流趋势的财务图表”,大幅提升研究效率。在法律合规领域,法务人员可以搜索”合同中的赔偿条款”或”包含签名和日期的协议页面”,实现智能化的文档审查。此外,在医疗健康场景中,医生可以利用文档 embedding 查找”包含类似病理图像的病例报告”或”具有相似检验数据表格的医学文献”,辅助临床诊断和研究。
实战案例:亚马逊 Q2 2025 财报智能检索
让我们通过一个真实的财报分析案例来展示 Nova Multimodal Embeddings 的页面级文档检索能力。假设某投资机构需要从亚马逊的季度财报中快速查找特定财务指标,例如”AWS Q2的运营利润贡献了多少,相比去年变化如何”,系统需要能够理解文档中的文本说明、财务表格和趋势图表。
下面代码展示 Nova MME 如何处理 PDF 文档的页面级检索——将 PDF页面转为图像,生成embedding,实现文档内容的语义检索:
# 1. 用 Nova MME 生成文档页面的 embedding
def get_document_page_embedding(image_base64):
request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": 3072,
"image": {
"format": "png",
"detailLevel": "DOCUMENT_IMAGE", # 文档图像专用模式
"source": {"bytes": image_base64}
}
}
}
response = bedrock_runtime.invoke_model(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
body=json.dumps(request)
)
return json.loads(response['body'].read())['embeddings'][0]['embedding']
# 2. 索引文档页面,存储到向量数据库
pages = convert_from_path("AMZN-Q2-2025-Earnings-Release-1.pdf", dpi=200)
for page_num, page_image in enumerate(pages, start=1):
buffered = BytesIO()
page_image.save(buffered, format="PNG")
image_base64 = base64.b64encode(buffered.getvalue()).decode("utf-8")
embedding = get_document_page_embedding(image_base64)
collection.add(
ids=[f"page_{page_num}"],
embeddings=[embedding],
metadatas=[{"page_number": page_num, "document": "AMZN-Q2-2025"}]
)
# 3. 查询文本用 Nova MME 生成 embedding,基于向量相似度检索文档页面
def search_document(query_text, top_k=3):
query_request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "DOCUMENT_RETRIEVAL", # 文档检索专用
"embeddingDimension": 3072,
"text": {"truncationMode": "END", "value": query_text}
}
}
response = bedrock_runtime.invoke_model(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
body=json.dumps(query_request)
)
query_embedding = json.loads(response['body'].read())['embeddings'][0]['embedding']
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
for i, (page_id, distance) in enumerate(zip(results["ids"][0], results["distances"][0])):
metadata = results["metadatas"][0][i]
similarity = 1 - (distance / 2) # 余弦距离转相似度
print(f"{i+1}. 页码: {metadata['page_number']} (相似度: {similarity:.4f})")
return results
# Demo:演示文档检索链路
search_document("AWS Q2的运营利润贡献了多少,相比去年变化如何?")
# 返回: 1. 页码: 11 (相似度: 0.6829) 2. 页码: 10 (相似度: 0.6725) 3. 页码: 1 (相似度: 0.6617)
页码11 页码10 页码1
在这次检索中,Nova MME 提供的结果(页码 11 和 10 的核心财务报表、以及页码1 新闻稿摘要的相似度最高)充分证明了其对文档结构的卓越理解能力,这一结果有力地表明:Nova MME 不仅能进行文本匹配,更能理解查询背后的数据意图并将其映射到文档中的结构化数据源(即表格)。对于构建 RAG 系统而言,检索到包含全面、原始数据的页面作为上下文,能够极大地提升后续 LLM 生成答案的准确性和权威性,满足企业级应用对数据真实性的严苛要求。
文本检索
在文本检索领域,Amazon Nova Multimodal Embeddings 模型支持多种文本输入方式,包括直接inline文本和Amazon S3存储的文本文件。模型提供同步和异步两种处理模式:同步模式适合短文本的实时处理,异步模式则专为长文本设计,具备强大的分段(segmentation)功能。通过设置segmentationConfig参数中的maxLengthChars,可以将长文本自动切分为指定字符数的片段(如1000字符),分段过程会智能地在词边界处切分以保持语义完整性。开发者可以通过embeddingPurpose参数区分使用场景,设置为”GENERIC_INDEX”用于构建索引,”DOCUMENT_RETRIEVAL”用于文档检索。此外,truncationMode参数支持”END”模式,确保超长文本从末尾截断,而embeddingDimension参数允许自定义向量维度(如256、384、1024、3072维)以平衡性能和精度需求。
这项技术在多个场景中展现出强大能力。在知识检索增强领域,研究人员可以使用自然语言查询来搜索复杂的技术文档,例如”反应堆退役后操作流程的下一步骤”,系统能够理解上下文语义并返回精准的技术指导。在媒体内容管理场景中,编辑可以通过文本相似度分析快速识别”标题重复检测”,有效避免内容冗余和提升发布质量。在金融和医疗健康行业,平台可以利用主题自动聚类功能进行”症状分类归纳”,实现智能化的数据组织和分析。此外,在金融、法律、保险等专业领域,系统支持上下文关联检索
,能够准确回答复杂查询如”企业检查意外事件违约的最高索赔额”,为专业决策提供可靠的信息支撑。
实战案例:知识检索增强
在研究机构、能源企业和技术密集型行业中,专业技术文档往往数量庞大、内容复杂,传统的关键词搜索难以满足精准检索需求。Nova MME驱动的知识检索增强系统通过深度语义理解技术,可以实现了从”关键词匹配”到”语义理解”的提升。
关键代码参考“检索链路构建:Nova MME集成的检索链路—-创建AWS OpenSearch索引,Nova MME生成嵌入,用OpenSearch支持的k-NN算法实现文本到文本检索”部分。
应用领域: 研究机构、能源、技术行业
# 技术文档数据库
technical_docs = [
"反应堆退役程序包括系统隔离、燃料移除、设备拆除和场地清理四个主要阶段",
"反应堆退役后的下一步骤是进行详细的环境影响评估和制定废料处理计划",
"核设施退役需要获得监管部门批准并建立长期监测体系",
"反应堆拆除工作需要专业团队使用远程操作设备进行辐射防护",
"退役完成后必须进行土壤修复和地下水监测工作",
"操作流程要求建立应急响应机制和人员培训计划"
]
结果:
Query: '反应堆退役后操作流程的下一步骤'
Knowledge Retrieval Results:
==================================================
Rank 1 (Relevance: 0.7829): 反应堆退役后的下一步骤是进行详细的环境影响评估和制定废料处理计划
Rank 2 (Relevance: 0.7444): 反应堆退役程序包括系统隔离、燃料移除、设备拆除和场地清理四个主要阶段
Rank 3 (Relevance: 0.6781): 核设施退役需要获得监管部门批准并建立长期监测体系
在技术文档管理中,系统能够理解复杂的自然语言查询。如示例中的”反应堆退役后操作流程的下一步骤”查询,模型成功识别出最相关的文档内容,相似度达到0.7829,准确返回”进行详细的环境影响评估和制定废料处理计划”的专业指导。
实战案例:文搜图
本案例展示了Amazon Nova Multimodal Embeddings在跨模态检索中的强大能力,实现了文本查询图像的语义搜索功能。通过将图像和文本映射到统一的语义空间,系统能够理解”日落海滩”等自然语言描述,并在图像库中找到最匹配的视觉内容。在免费素材库中挑选如下5张进行简单测试:
图片来源:https://pixabay.com/zh/
核心代码如下:
# 0. 配置(略,参考前述章节“图像分类”或“图像检索”)
# 1. 用Nova MME生成图像嵌入与文本嵌入
def get_image_embedding(image_path):
#(略,参考前述章节“图像分类”或“图像检索”)
pass
def get_text_embedding(query_text):
#(略,参考前述章节“知识检索增强”)
pass
# 2. 索引风景图像,构建图像库
gallery_images = [
"sample_assets/images/scenery1.webp",
"sample_assets/images/scenery2.jpg",
"sample_assets/images/scenery3.webp",
"sample_assets/images/scenery4.webp",
"sample_assets/images/scenery5.jpg"
]
image_embeddings = []
image_metadata = []
for img_path in gallery_images:
embedding = get_image_embedding(img_path)
image_embeddings.append(embedding)
image_metadata.append(img_path.split('/')[-1])
print(f"Generated {len(image_embeddings)} image embeddings")
# 3. 跨模态文本查询,基于文本描述检索相似图像
def search_images_by_text(query_text, top_k=3):
# 生成文本嵌入,优化图像检索
text_embedding = get_text_embedding(query_text)
# 计算跨模态相似度
similarities = []
for i, img_embedding in enumerate(image_embeddings):
similarity = np.dot(text_embedding, img_embedding) / (
np.linalg.norm(text_embedding) * np.linalg.norm(img_embedding)
)
similarities.append((similarity, i))
# 排序并返回top-k结果
similarities.sort(reverse=True)
for i, (similarity, idx) in enumerate(similarities[:top_k]):
print(f"{i+1}. {image_metadata[idx]} (相似度: {similarity:.4f})")
return similarities[:top_k]
# demo:演示跨模态检索链路
results = search_images_by_text("日落海滩") # 返回:最相似的风景图像
结果分析:
从结果可以看出,仅通过”日落海滩”这一文本查询,能较为精准地识别出最相关的图像内容。Top-2结果的相似度得分分别为0.4005和0.3468,显著高于其他图像,体现了Nova MME的跨模态语义理解能力。
音频/语音检索
对于音频和语音检索领域,Amazon Nova Multimodal Embeddings 模型支持WAV、MP3、FLACK、OGG、M4A等主流音频格式,可以通过 Base64 编码或 Amazon S3 URI 两种方式输入音频文件。使用 Base64 编码时,单个音频文件最大支持 25MB,同步模式下音频时长限制为30秒。模型提供了分段(segmentation)功能,仅在异步模式下可用,可以将长音频自动切分成可管理的片段,每个片段独立生成embedding。在异步生成音频 embedding 时,开发者可以通过 segmentationConfig 参数中的 durationSeconds 设置分段时长(有效范围1-30秒,默认值5秒),例如将音频切分为 5 秒或 15 秒的片段,以便更精细地定位特定音频内容。此外,embeddingPurpose 参数允许开发者根据应用场景优化:设置为”GENERIC_INDEX”用于构建音频索引库,”AUDIO_RETRIEVAL”用于音频检索任务。异步模式支持更大的音频文件处理,输出结果保存到指定的S3存储桶中。
这项技术在多个场景中展现出强大能力。在素材库和媒体资产管理领域,内容创作者可以使用自然语言描述来搜索音频片段,例如”圣诞节音乐铃声”或”自然宁静音效”,系统能够理解语义并返回匹配的音频素材。在播客和会议记录场景中,用户可以快速定位”播客主讲人讨论神经科学与睡眠对大脑健康影响”的特定片段,大幅提升内容检索效率。在音乐流媒体和版权管理领域,平台可以利用音频 Embedding 的相似度计算来实现”听歌识曲”功能,识别相似音效或检测重复音频内容,有效防止版权侵权。此外,在
跨模态应用中,系统支持文本搜索音频(如”雨声背景音乐”查找对应音效)、音频搜索视频(音频片段匹配对应MV或演示视频)等复合检索场景,为媒体制作、广告创意和音乐内容管理提供了全新的智能化解决方案。
接下来两个案例展示了Amazon Nova Multimodal Embeddings在音频领域的双重应用能力:音频片段检索和跨模态文字搜索音频。通过将音频和文本映射到统一的语义空间,系统能够实现音频指纹识别和自然语言音乐发现功能。
实战案例:听音识曲
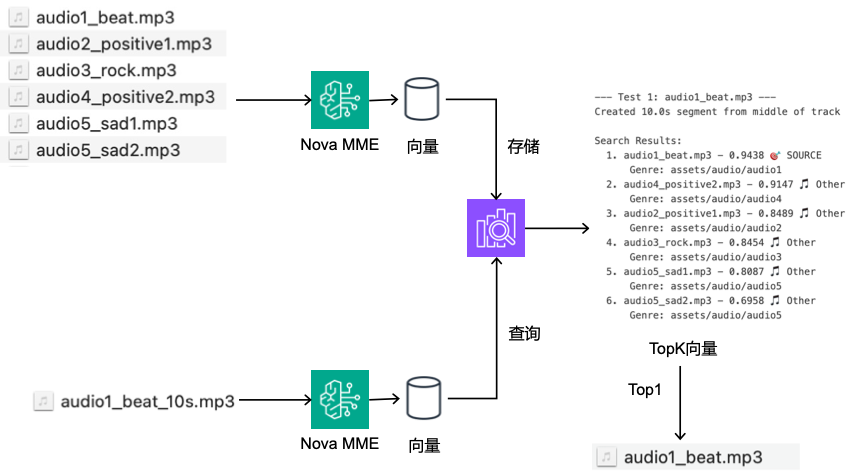
本测试案例使用6个不同风格的音频文件进行嵌入构建索引库,音频涵盖电子、积极、摇滚和悲伤等多种音乐类型。然后使用pydub加载音频文件,从中间位置(10秒处)提取10秒片段导出为临时WAV文件用于嵌入生成,作为查询。核心代码如下:
# 0. 配置
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
REGION = "us-east-1"
EMBEDDING_DIMENSION = 1024
MAX_AUDIO_DURATION_MS = 30000 # 30秒限制
bedrock = boto3.client('bedrock-runtime', region_name=REGION)
# 1. 用Nova MME生成音频嵌入
def get_audio_embedding(audio_path, purpose="GENERIC_INDEX"):
with open(audio_path, 'rb') as f:
audio_bytes = base64.b64encode(f.read()).decode('utf-8')
audio_format = os.path.splitext(audio_path)[1][1:].lower()
request = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": purpose,
"embeddingDimension": EMBEDDING_DIMENSION,
"audio": {
"format": audio_format,
"source": {"bytes": audio_bytes}
}
}
}
response = bedrock.invoke_model(modelId=MODEL_ID, body=json.dumps(request))
return json.loads(response['body'].read())['embeddings'][0]['embedding']
# 2. 索引音频文件,构建音频库
audio_library = [
"sample_assets/audio/audio1_beat.mp3",
"sample_assets/audio/audio2_positive1.mp3",
"sample_assets/audio/audio3_rock.mp3",
"sample_assets/audio/audio4_positive2.mp3",
"sample_assets/audio/audio5_sad1.mp3",
"sample_assets/audio/audio5_sad2.mp3"
]
audio_embeddings = []
audio_metadata = []
for audio_path in audio_library:
embedding = get_audio_embedding(audio_path, "GENERIC_INDEX")
audio_embeddings.append(embedding)
audio_metadata.append({
'filename': os.path.basename(audio_path),
'genre': audio_path.split('_')[1] if '_' in audio_path else 'unknown'
})
print(f"Generated {len(audio_embeddings)} audio embeddings")
# 3. 音频片段检索,基于音频片段查找相似音频
def search_audio_by_segment(source_audio_path, start_ms=10000, duration_ms=10000, top_k=3):
if duration_ms > MAX_AUDIO_DURATION_MS: # 创建音频片段
duration_ms = MAX_AUDIO_DURATION_MS
audio = AudioSegment.from_file(source_audio_path)
segment = audio[start_ms:start_ms + duration_ms]
temp_file = tempfile.NamedTemporaryFile(suffix='.wav', delete=False)
segment.export(temp_file.name, format='wav')
segment_embedding = get_audio_embedding(temp_file.name) # 生成片段嵌入
similarities = [] # 计算相似度
for i, audio_emb in enumerate(audio_embeddings):
similarity = np.dot(segment_embedding, audio_emb) / (
np.linalg.norm(segment_embedding) * np.linalg.norm(audio_emb)
)
similarities.append((similarity, i))
similarities.sort(reverse=True) # 排序并返回top-k结果
print(f"Audio segment from {os.path.basename(source_audio_path)}:")
for rank, (sim, idx) in enumerate(similarities[:top_k], 1):
meta = audio_metadata[idx]
print(f" {rank}. {meta['filename']} - {sim:.4f}")
os.unlink(temp_file.name)
return similarities[:top_k]
# demo:演示音频片段检索链路
for audio_path in audio_library[:3]: # 测试前三个音频
search_audio_by_segment(audio_path) # 返回:最相似的音频文件
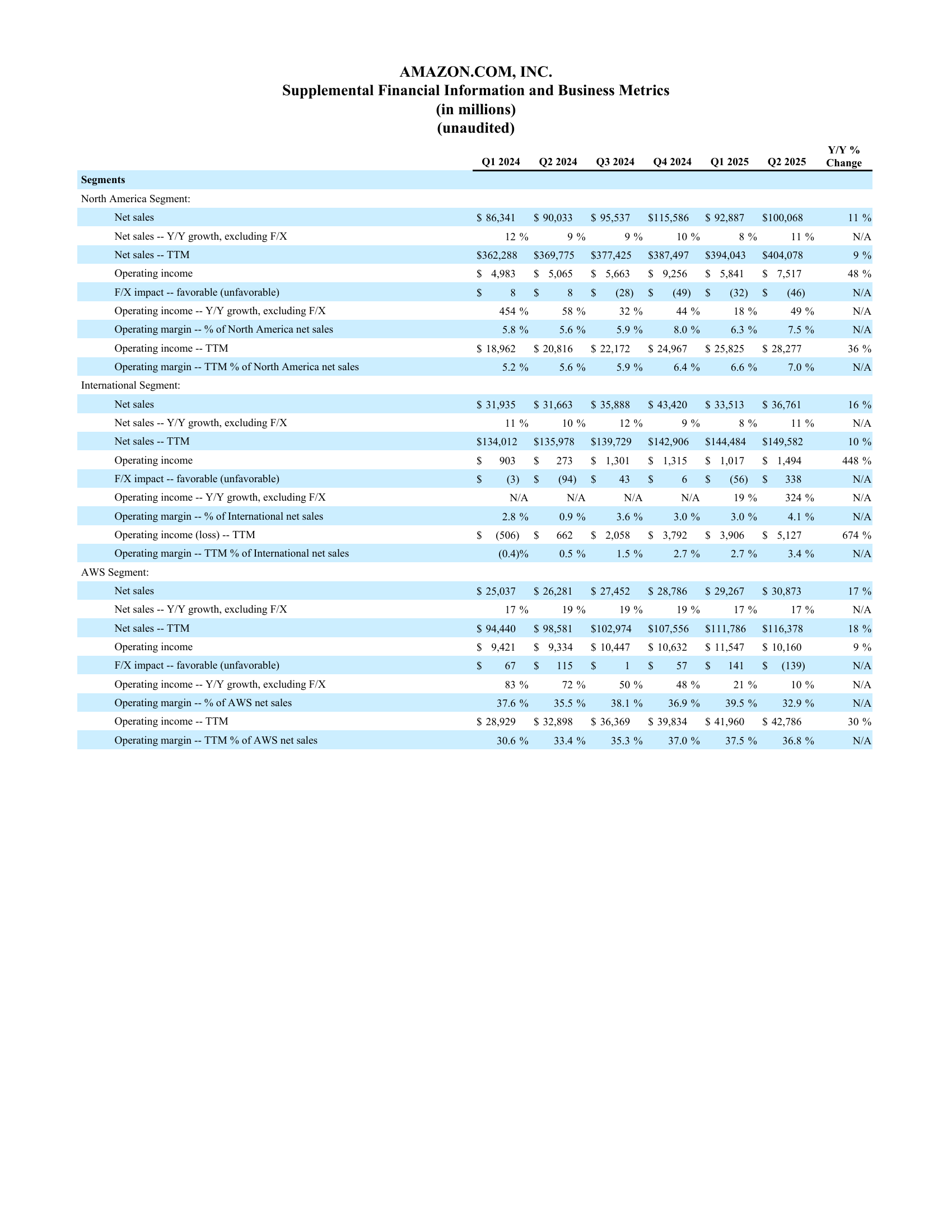
前三个音频测试结果如下:
从音频片段检索的前3个测试结果可以看出,Amazon Nova Multimodal Embeddings在音频指纹识别方面表现卓越。每个测试都从原始音频的中间位置提取10秒片段作为查询,系统均能准确识别出片段的来源音轨:audio1_beat.mp3片段的最高相似度为0.9438,audio2_positive1.mp3为0.9439,audio3_rock.mp3为0.9311,这些源文件的相似度分数都显著高于其他音频文件。而且不仅能精确匹配源文件,相似风格的音频(如positive类型音频之间)往往具有较高的相似度,而差异较大的音乐类型(如rock与sad)则相似度较低。这种10秒片段即可实现较高准确率的音频指纹识别能力,为音乐版权检测、内容识别和音频管理等应用场景提供了技术支撑。
实战案例:文字搜索音频
# 0. 配置
#(略,参考“音频/语音检索-1.听音识曲”部分)
# 1. 用Nova MME生成音频嵌入和文本嵌入
def get_audio_embedding(audio_path, purpose="GENERIC_INDEX"):
#(略,参考“音频/语音检索-1.听音识曲”部分)
pass
def get_text_embedding(query_text):
#(略,参考前述章节“检索链路构建-Nova MME集成的检索链路----创建AWS OpenSearch索引,Nova MME生成嵌入,用OpenSearch支持的k-NN算法实现文本到文本检索”
pass
# 2. 索引音频文件,构建音频库
#(略,参考“音频/语音检索-1.听音识曲”部分)
# 3. 跨模态文本查询,基于中文描述检索相似音频
def search_audio_by_text(query_text, top_k=3):
text_embedding = get_text_embedding(query_text)
similarities = [] # 计算跨模态相似度
for i, audio_emb in enumerate(audio_embeddings):
similarity = np.dot(text_embedding, audio_emb) / (
np.linalg.norm(text_embedding) * np.linalg.norm(audio_emb)
)
similarities.append((similarity, i))
similarities.sort(reverse=True) # 排序并返回top-k结果
print(f"查询: {query_text}")
for rank, (sim, idx) in enumerate(similarities[:top_k], 1):
print(f" {rank}. {audio_metadata[idx]['filename']} - {sim:.4f}")
return similarities[:top_k]
# demo:演示跨模态文本-音频检索链路
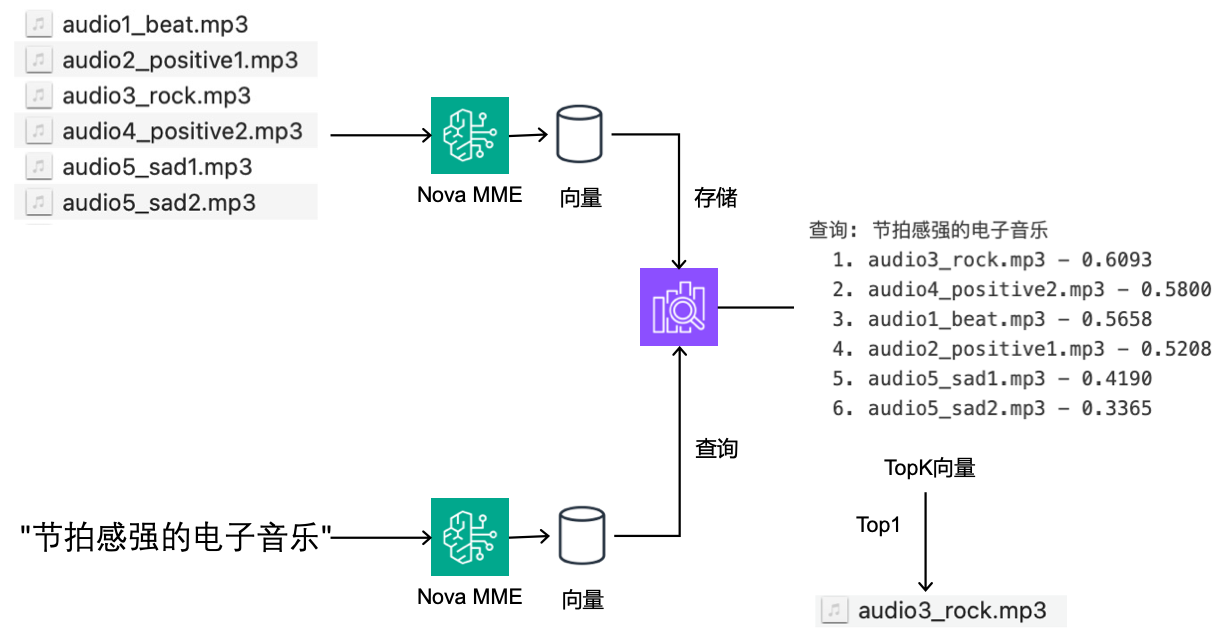
queries = ["节拍感强的电子音乐", "积极快乐的歌曲", "悲伤的音乐"]
for query in queries:
search_audio_by_text(query)
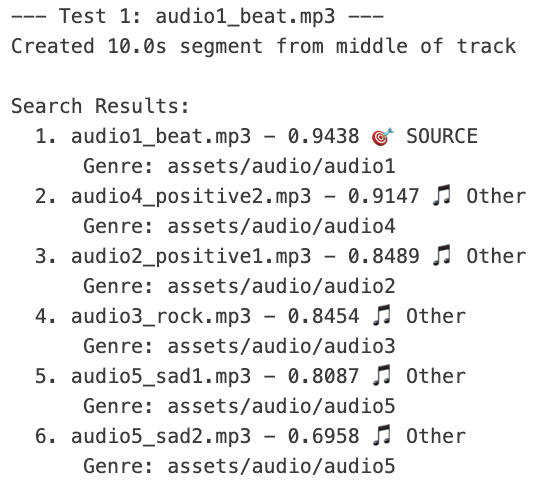
结果:
文字搜索音频功能展现了Nova Multimodal Embeddings强大的跨模态语义理解能力。当查询”节拍感强的电子音乐”时,准确识别出audio1_rock.mp3为最匹配结果,相似度领先于其他音乐片段;查询”积极快乐的歌曲”时,虽然相似度得分整体偏低,但audio2_positive1.mp3相似度得分最高,为最匹配结果,体现了对情感语义的把握;而”悲伤的音乐”查询则成功匹配到sad系列音频文件,相似度分数明显高于其他类型音乐。这种基于中文自然语言描述的音频检索能力,不仅验证了嵌入空间中音频特征与文本语义的有效对齐,更为音乐推荐系统、智能音乐搜索和内容自动标注等应用提供了创新的解决方案,用户只需用简单的文字描述就能找到符合特定风格和情感的音乐内容。
Nova多模态嵌入模型的使用场景不限于此,即刻体验Amazon Nova多模态嵌入模型,开启多模态AI应用构建之旅!
可用性与定价
Amazon Nova多模态嵌入模型现已在Amazon Bedrock上线,可用区域包括美国东部(弗吉尼亚北部)的亚马逊云科技区域。如需详细定价信息,请参阅Amazon Bedrock定价页面(Amazon Bedrock pricing page)。
如需了解更多内容,可参阅《Amazon Nova用户指南》( Amazon Nova User Guide )获取完整文档,或参阅GitHub上的Amazon Nova模型实践手册( Amazon Nova model cookbook on GitHub)获取实用代码示例。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |