亚马逊AWS官方博客
让 Amazon Quick 操作飞书:构建远程 MCP 服务的设计实践
摘要:当 AI 助手需要操作飞书完成多步任务时,200+ 工具的上下文膨胀、多步编排的准确性和 Token 安全是三大挑战。本文分享如何基于 AWS Bedrock AgentCore 构建一套远程 MCP 服务,通过 Meta Tool 实现按需编排、分层注册平衡可用性与上下文效率,以及 OAuth PKCE + HMAC 域分离签名确保 Token 安全。
目录
一、概述
飞书是许多团队日常协作的核心平台,但 Amazon Quick 目前尚未内置飞书集成。本文分享如何利用 Amazon Quick 的远程 MCP Connector 能力,基于 AWS Bedrock AgentCore 构建一套托管 MCP 服务,让 Quick 用户直接通过对话完成飞书日程安排、消息发送、文档创建等跨域操作。文章重点解析构建过程中的三项设计决策:4 个 Meta Tool 实现 200+ 工具的按需编排、Tier1/Tier2 分层注册平衡可用性与上下文效率,以及 OAuth 2.0 PKCE + HMAC 域分离签名确保 Token 安全。这些方法可复用到任何需要通过 MCP 为 AI 扩展第三方服务能力的场景。
二、为什么 Amazon Quick 需要飞书集成
2.1 Amazon Quick 缺少飞书能力
截至本文撰写时(2025 年 6 月),Amazon Quick 尚未内置飞书集成。但 Amazon Quick 提供了远程 MCP Connector 能力——允许通过标准 MCP 协议接入第三方服务。这意味着我们可以自行构建一套飞书 MCP 服务,让 Quick 用户无缝操作飞书,而不需要等待官方集成。
2.2 lark-cli:为个人使用设计的本地工具
官方项目 lark-cli 是飞书的命令行工具,将飞书开放平台 2500+ API 封装为 200+ 命令,并提供 20+ Skill(即 Markdown 格式的多步操作编排指南)。用户通过 shell 调用 lark-cli 命令来操作飞书,对于个人使用非常高效。
但在团队场景下,本地 CLI 的部署模式带来额外挑战:
- 每台机器独立安装:需要 shell 执行环境,非技术人员有门槛
- 飞书应用分散:每人各建一个应用,IT 难以统一管控权限和可见性范围
- 审计分散:权限分布在各个独立应用中,缺少集中审计视角
2.3 设计目标
基于团队场景的需求,我们确定了三个设计目标:
- 管理员部署一次,全团队共用一个飞书应用
- 用户无需本地安装,授权后即可使用
- IT 集中管控权限,统一审计
核心思路是把 lark-cli 的全部能力从本地 CLI 形态封装为标准 MCP 协议,暴露为远程托管服务。
| 对比维度 | lark-cli 本地 | 远程 MCP 服务 |
| 协议 | Shell 命令调用 | 标准 MCP 协议 |
| 部署 | 每台机器装 | 管理员部署一次 |
| 飞书应用 | 各自配置 | IT 集中管控 |
| 飞书应用数量 | 每人各建一个 | 全团队共用一个 |
| Skill | 本地 md 文件 | MCP 工具形态(按需加载) |
三、方案概览
3.1 效果演示
在 Amazon Quick 的对话界面中,用户直接说:
“帮我查一下今天的飞书日程;发一条消息给 Agent Studio 开发群:明天下午3点对齐需求;查一下最近 3 天的群聊记录,有哪些事情需要我跟进”
Amazon Quick 一次性处理三件事,返回结构化结果:
- 今天的飞书日程:以表格展示时间和事项
- 消息已发送:确认已在指定群发送消息
- 最近 3 天需要跟进的事项:从群聊记录中提取待办、提醒和关键信息
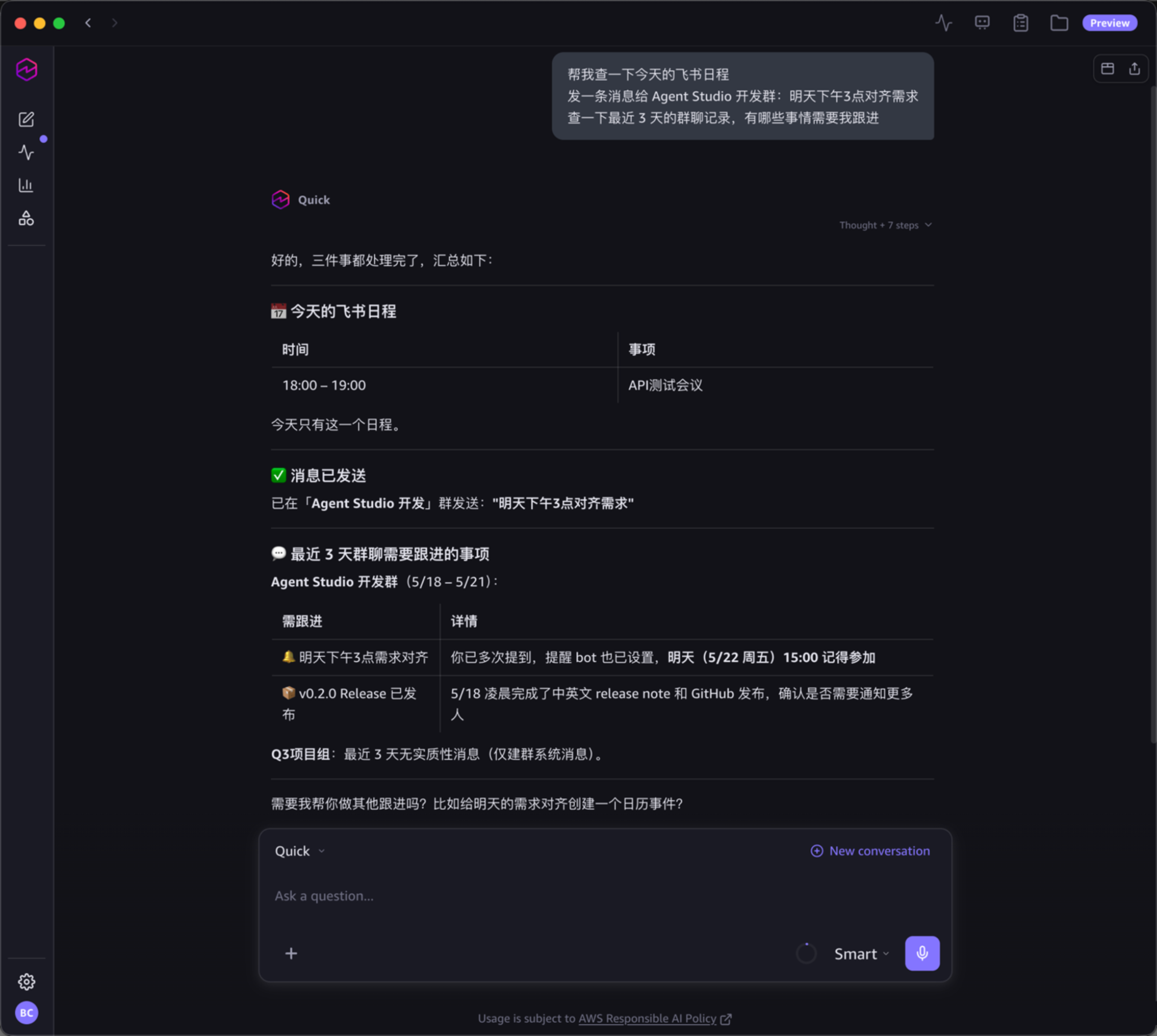
[图1:Amazon Quick 操作飞书的演示效果] |
这个看似简单的交互,背后涉及日历查询、IM 消息发送、消息搜索与内容分析等多个飞书 API 的编排调用。每一步的参数格式、调用顺序和前置约束,均由 Skill 编排指南约束——AI 不是“猜着调”,而是“按规矩来”。
3.2 整体架构
系统由以下组件构成:
- Edge 层:CloudFront(HTTPS 入口,可选 WAFv2 限速)
- API 层:API Gateway → MCP Middleware Lambda(Token 验证 + SigV4 签名)
- Runtime 层:AWS Bedrock AgentCore(无状态 MCP 容器,自动伸缩)
- Auth 层:OAuth Lambda(授权流程 + 30 分钟自动刷新)
- State 层:Secrets Manager(加密 Token)、DynamoDB、SSM Parameter Store
- 可观测性:CloudWatch Dashboard(5 大板块、12 图表、10 告警)
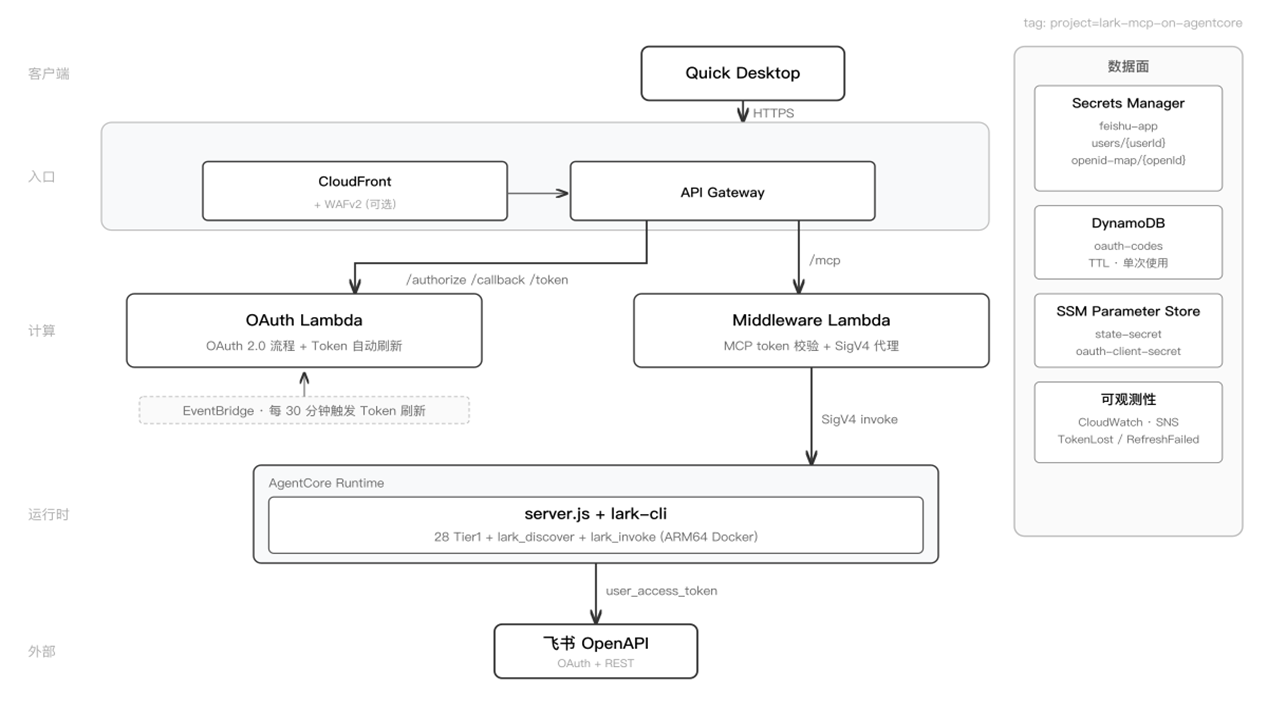
[图2:系统整体架构] |
四、核心设计 ①——按需编排:4 个 Meta Tool 如何撑起 200+ 工具
4.1 问题:200+ 工具全注册会怎样
构建这套服务时,第一个设计决策是:200+ 工具怎么暴露给 AI?
一个直觉方案是全部注册。但 MCP 工具定义本身占用 context 窗口——每个工具的 name + description + parameters schema 平均占用数百 token。200+ 工具全注册意味着数万 token 的固定开销,不仅浪费上下文窗口,还会导致 AI 在大量工具中“选择困难”,降低调用准确率。
4.2 解法:4 个 Meta Tool + 按需加载
我们的做法是只向 AI 注册 32 个工具(28 Tier1 + 4 Meta),通过 4 个 Meta Tool 实现其余 200+ 工具的按需发现和调用:
| Meta Tool | 职责 | 类比 |
| lark_list_skills | 浏览 20+ 业务域 Skill 列表 | 图书馆目录 |
| lark_get_skill | 按需加载某个域的编排指南(参数格式/顺序/约束) | 取出某本操作手册 |
| lark_discover | 搜索 200+ Tier2 工具,首次使用时发现 | 搜索引擎 |
| lark_invoke | 调用任何已发现的 Tier2 工具,统一入口执行 | 通用执行器 |
核心原则:操作前先加载编排指南,按需发现工具——以正确的参数、顺序、前置条件完成多步操作。
这种模式可以推广到任何工具数量超过 AI 上下文承载能力的场景:用少量 Meta Tool 作为“入口”,让 AI 自行按需探索和加载。
4.3 Skill 编排实例:预约会议的完整流程
以“约产品评审会”为例,AI 的实际调用序列:
注意第 5-6 步:AI 在 Skill 指南中得知“时间模糊时应先调用推荐接口”,通过 lark_discover 找到该工具,再通过 lark_invoke 执行。整个过程中,Skill 指南作为“操作手册”按需加载,不占固定 context。
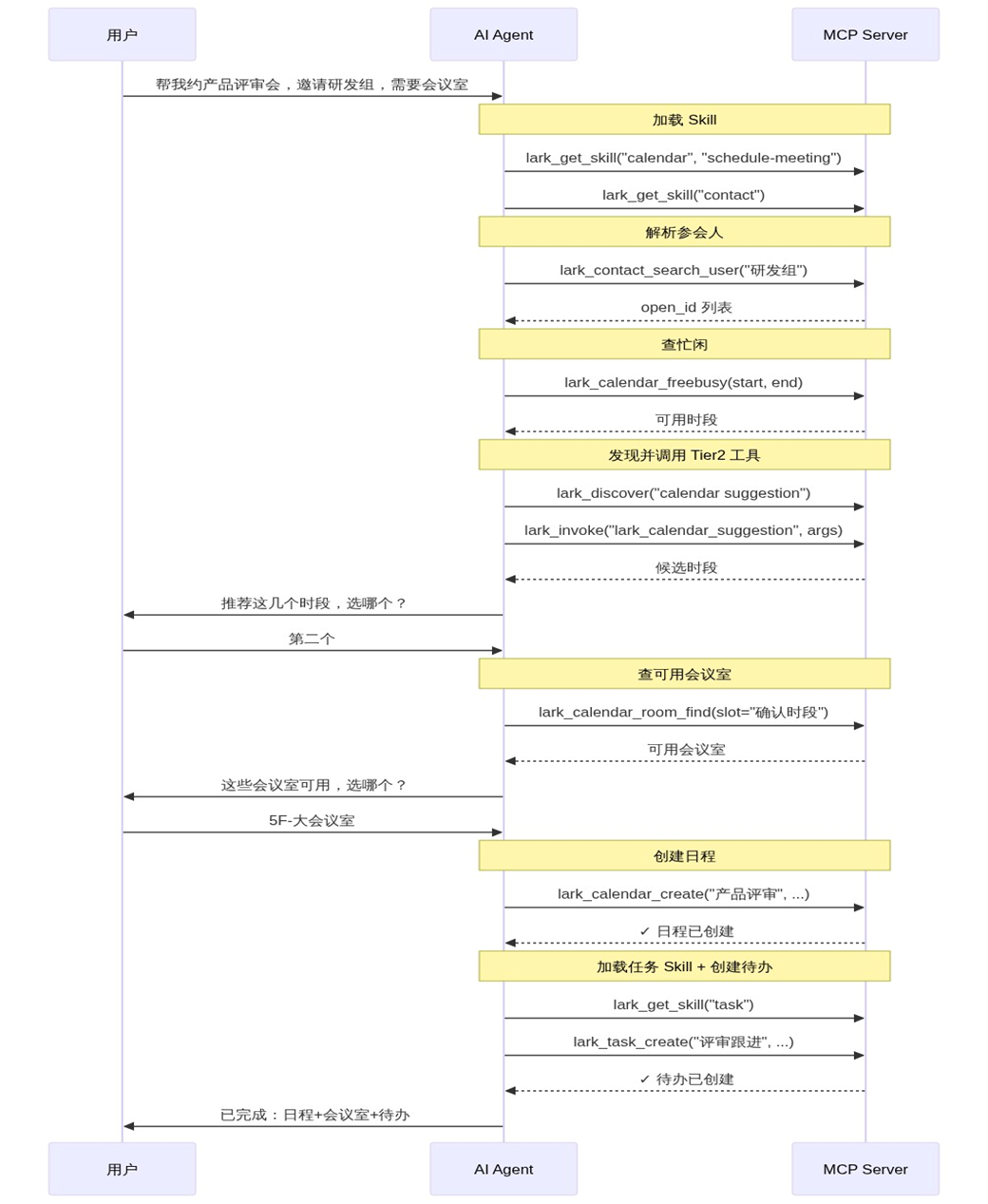
[图3:预约会议的完整 MCP 调用序列] |
4.4 编排域覆盖
目前已实现 20+ 业务域 Skill(覆盖 300+ 编排规则文件),涵盖日历、IM、文档、多维表格、云盘、任务、邮件、知识库、视频会议等核心场景,以及 OKR、审批、考勤、妙记、幻灯片、白板等扩展场景。
五、核心设计 ②——分层注册:Context 窗口的算术题
5.1 为什么要分层
如第三节所述,200+ 工具全量注册会撑爆 context 窗口并降低调用准确率。但注册太少,AI 又无法完成用户请求。分层注册的本质是在可用性和上下文效率之间找平衡。
5.2 分层策略
Tier1——直接注册(28 个高频工具)
AI 启动即可见,无需 discover。覆盖日常最高频操作:
| 域 | Tier1 工具 |
| IM | messages_send, messages_search, chat_list, chat_messages_list, chat_search |
| Calendar | agenda, create, freebusy, room_find |
| Docs | create, fetch, search, update |
| Base | base_get, data_query, record_batch_create, record_search |
| Drive | search, upload, download |
| Task | create, get_my_tasks, complete |
| Contact | search_user, get_user |
| Sheets | read, write |
| send |
Tier2——按需发现(200+ 工具)
通过 lark_discover 搜索后使用,不用时零 context 占用。覆盖 OKR、审批、考勤、妙记等低频场景,通过 lark_invoke 统一调用。
5.3 决策依据
工具进入 Tier1 的标准:
- 调用频率:日常使用中被调用频率最高的操作
- 编排必要性:多步操作中的常见“积木”(如
contact_search_user几乎是所有涉及人的操作的前置步骤) - 独立性:不需要通过 discover 就能理解用途
这一比例(约 15% 直注册、85% 按需加载)在实际使用中取得了较好的平衡,可供类似场景参考。
六、核心设计 ③——安全:Token 不出客户 AWS 账号
对于远程 MCP 服务,客户 IT 最关心的问题是:Token 安全吗?谁能访问?以下是我们在安全架构上的五层设计。
6.1 OAuth 2.0 PKCE——防止授权码截获
MCP 服务的 OAuth 端点采用 Authorization Code + PKCE(Proof Key for Code Exchange)双重验证:
1. 客户端生成随机 code_verifier,计算 SHA-256 得到 code_challenge
2. 授权请求携带 code_challenge(仅支持 S256 方法)
3. 换 Token 时必须同时提供 code_verifier + client_secret
4. 服务端重算 SHA-256 并比对
client_secret 验证客户端身份,PKCE 将授权码绑定到发起会话——即使授权码被截获,没有原始 code_verifier 也无法换取 Token。两层防护互为补充。
6.2 HMAC 域分离签名——防止跨域伪造
系统从一个根密钥通过 HKDF 派生 3 个独立的 HMAC-SHA256 签名密钥:
| 密钥 | 用途 | 格式 | 有效期 |
| stateKey | OAuth state 参数签名 | base64url(payload).timestamp.hmac_hex | 5 分钟 |
| tokenKey | MCP Token 签名 | base64url(userId:expiresAt:hmac_hex) | 30 天 |
| incrKey | 增量授权 Token 签名 | 同 tokenKey 格式 | 短期 |
域分离的意义:即使攻击者获得某一类 Token 的签名,也无法跨域伪造另一类 Token。管理员可通过轮换根密钥立即使所有已签发 MCP Token 失效,实现紧急吊销。
6.3 Token 存储——Secrets Manager + 不出内网
- 所有用户 Token 加密存储在 AWS Secrets Manager(AWS 托管 KMS 加密)
- 读写操作通过 CloudTrail 审计
- Token 在 AWS 内部通过 TLS + SigV4 传输,不经过公网
- 容器内注入,不经客户端
6.4 Write-Probe 预检——保护一次性 refresh_token
飞书的 refresh_token 是一次性的(刷新后旧 token 失效)。Write-Probe 机制:
1. 刷新前,先读取当前 Secret 值
2. 将同一个值原样写回(验证写入权限)
3. 写入成功才执行实际的 Token 刷新
4. 若写入失败,跳过本次刷新,refresh_token 保持未消耗状态
并发安全:Token 刷新由 EventBridge 定时规则统一触发,每个用户的刷新操作通过 DynamoDB 条件写实现分布式锁,避免 TOCTOU 竞态。
这是一个通用的防丢 token 模式——适用于任何 refresh_token 一次性消耗的第三方 OAuth 场景。
6.5 日志自动脱敏
- 用户标识仅记录 SHA-256 哈希的前 16 位
- Token 不出现在日志或 argv 中
以上五层设计确保敏感数据不离开客户 AWS 账号,便于 IT 安全团队进行合规评审。
七、平台与部署
7.1 为什么选 Bedrock AgentCore
选择运行时平台时,我们对比了自建容器编排(ECS/EKS)和 Bedrock AgentCore:
| 能力 | AgentCore 提供 | 自建容器编排需要 |
| 空闲零成本 | 无请求时容器自动回收 | 自行配置 Scale-to-Zero |
| 免运维 | 无需 Task Definition、Scaling Policy | 编写完整 ECS/EKS 配置 |
| 秒级就绪 | 容器按需启动 | 预热 + Health Check |
| 注册 Runtime | 一行代码 | 搭建完整编排基础设施 |
AgentCore 让开发者专注于 MCP Server 逻辑,省去容器编排、扩缩容的运维复杂度。对于 MCP 服务这种请求稀疏、响应时间要求不高的负载模式,Scale-to-Zero 是决定性优势。同时,AgentCore 与 Amazon Quick 同属 Bedrock 生态,天然支持 MCP Connector 接入,无需额外的协议适配。
7.2 部署设计
部署脚本采用以下设计原则:
- 交互式引导:中英双语,逐步收集飞书凭证、区域、WAF、告警等配置
- 合理默认值:所有选项预填推荐值,按回车即可跳过
- 配置记忆:重复部署自动填入上次配置,无需重复输入
- 幂等设计:CDK 编排所有 AWS 资源,重跑不会产生重复资源
- 可销毁:提供一键销毁脚本,删除所有已创建的资源
整个部署流程约 10 分钟完成,最终产出包括 MCP Endpoint、OAuth 回调地址和 CloudWatch Dashboard 链接。
八、接入 Amazon Quick
得益于 Amazon Quick 原生的 MCP Connector 机制,接入极为轻量——管理员配置一次,用户一键授权:
管理员操作(一次性):
1. 在 Amazon Quick 中创建 MCP Connector
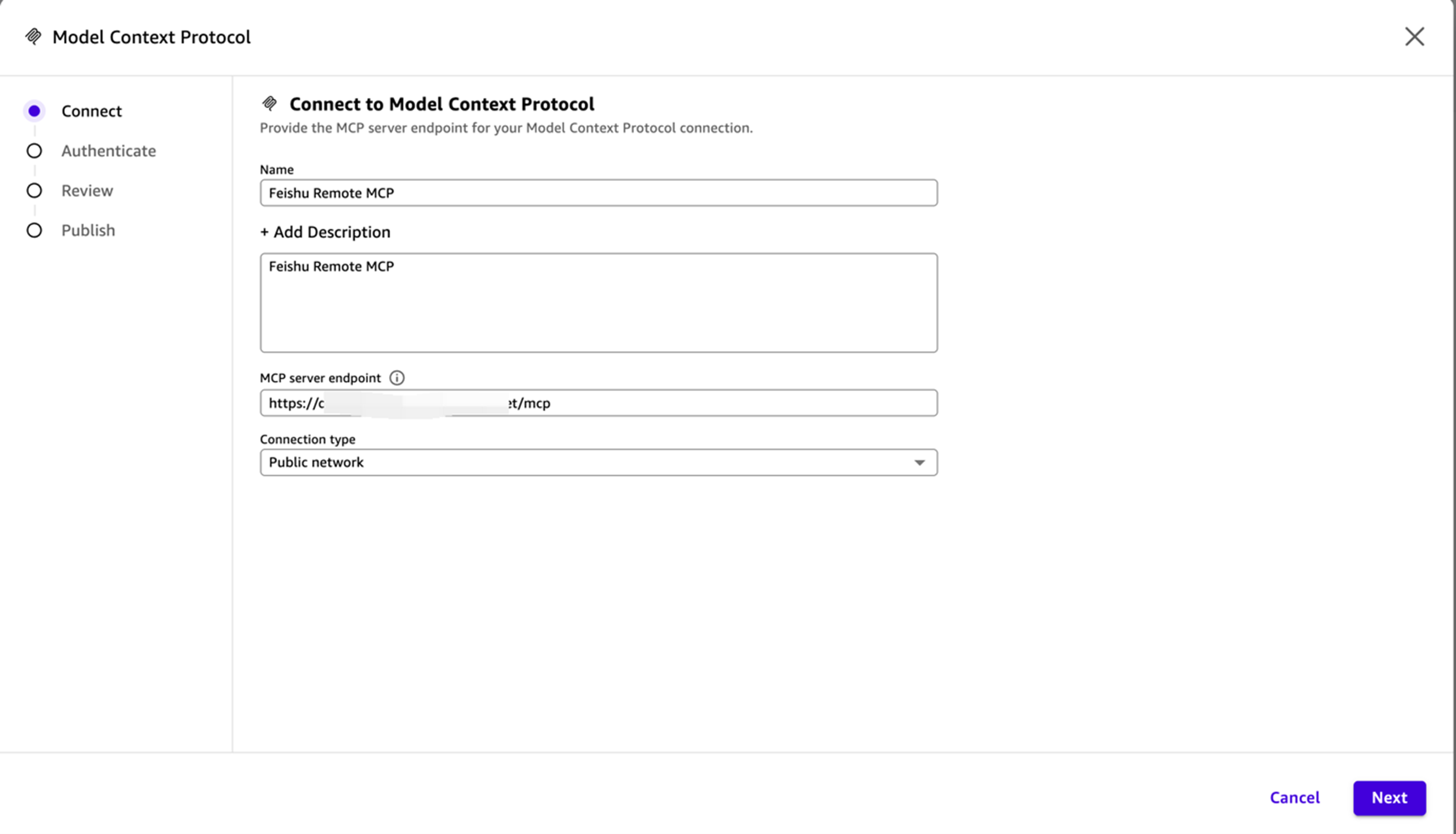
[图4] |
2. 配置 OAuth 认证信息(部署输出中提供)
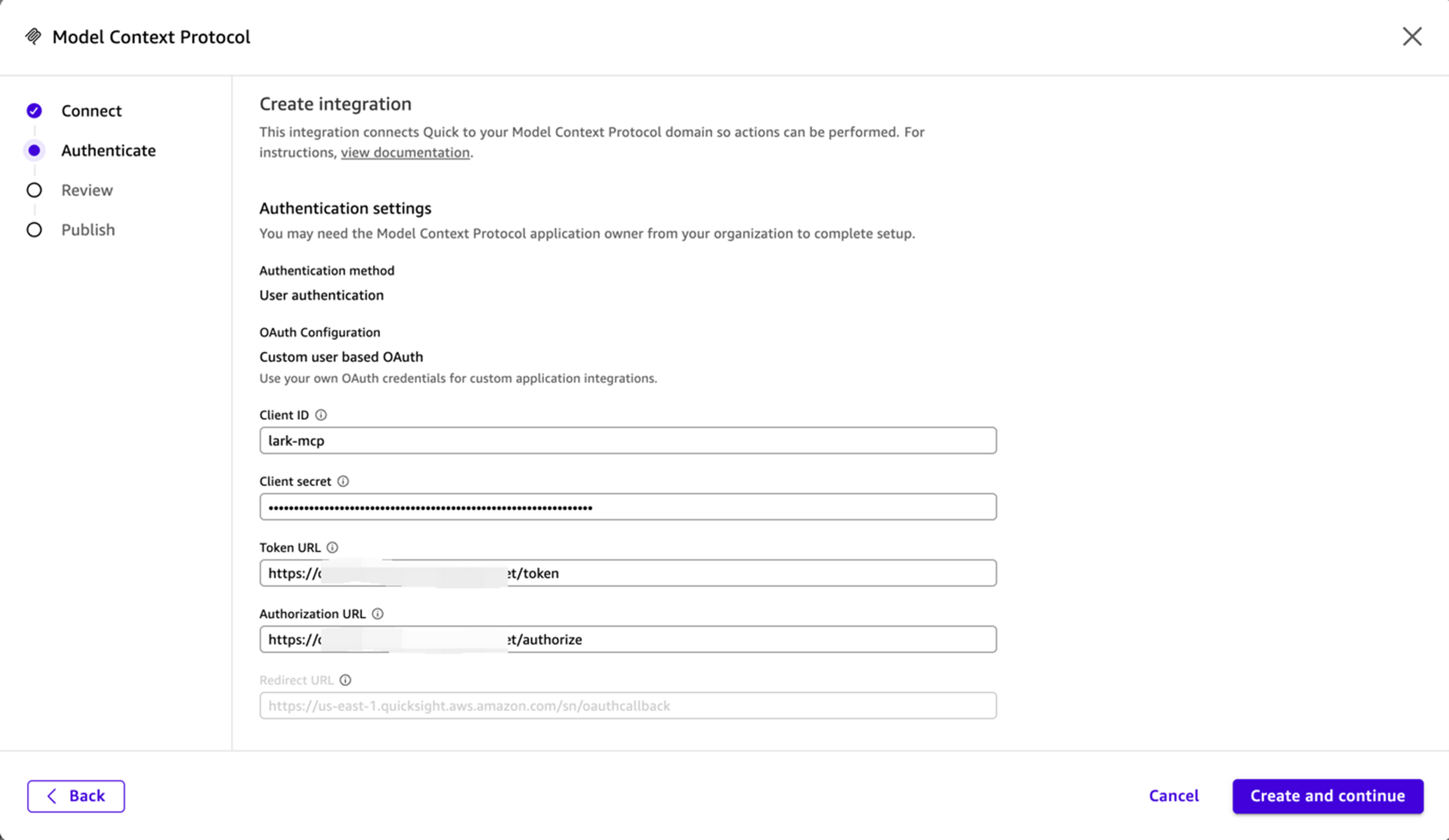
[图5] |
用户操作:
搜索 “feishu” → 点击 “Sign in” → 飞书授权 → 完成
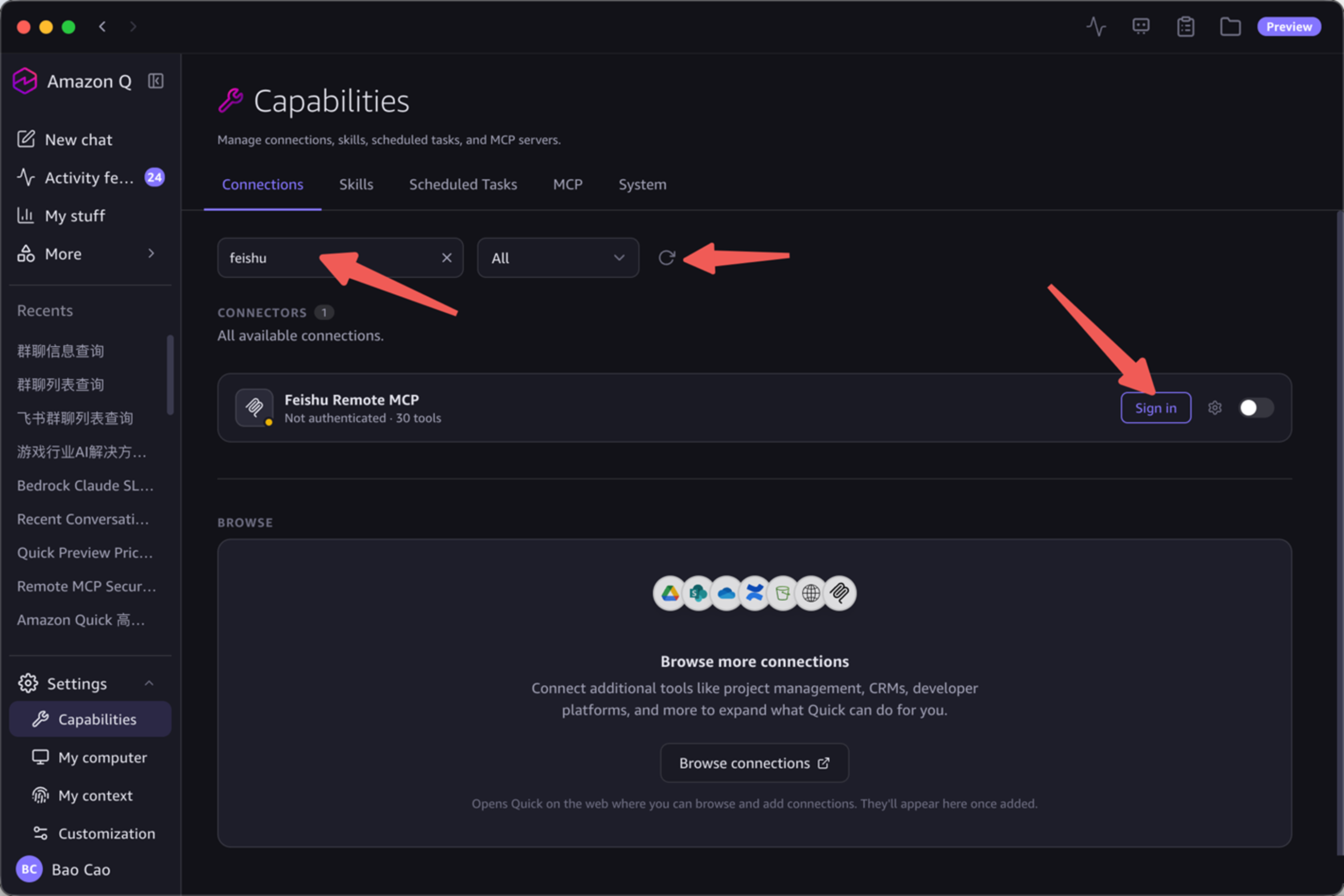
[图6:用户在 Quick Desktop 中搜索并登录飞书] |
无需本地安装,授权后立即可用。
九、成本估算
| 团队规模 | 月成本 |
| 10 人试用 | < $10 |
| 100 人 | < $50 |
| 500 人 | < $250 |
主要成本构成:
- Secrets Manager:每用户 1 个 Secret,$0.40/个/月
- AgentCore Runtime:按实际使用计费,空闲超时后不计费
- 大部分 AWS 组件有免费额度
十、总结
本文分享了为 Amazon Quick 构建飞书远程 MCP 服务的完整设计过程。面对“200+ 工具如何暴露给 AI”这一核心挑战,我们总结了三条可复用的设计经验:
- 当工具数量膨胀时,用 Meta Tool + 按需加载代替全量注册——让 AI 自行探索,而非一次性塞满
- 当 context 成为瓶颈时,按调用频率和编排依赖做分层——高频直注册、低频按需发现
- 当 Token 涉及第三方 SaaS 时,域分离签名 + Write-Probe 预检保障安全——尤其注意一次性 refresh_token 的防丢设计
Amazon Quick 的远程 MCP Connector 能力让这一切成为可能——它提供了标准化的扩展接口,开发者无需等待官方集成,即可为 Quick 增加任意第三方服务的操作能力。而本文的设计方法不限于飞书场景,任何需要将大规模工具集通过 MCP 暴露给 AI 的服务,都会面对相同的 context 预算、编排准确性和 Token 安全问题。希望本文的设计思路能为读者提供参考。
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon Bedrock AgentCore — 加快代理投入生产的速度
- Amazon Connect — AI 客户体验解决方案
- Amazon Secrets Manager — 密钥管理
- Amazon ECS — 完全托管的容器编排服务
相关文章:
- (上篇)基于 AWS Bedrock AgentCore 构建企业级航空客服智能体 —— 基于AIDLC方法从需求分析到生产部署的完整实践
- 用 Kiro构建 AI:基于 AWS 基础设施快速构建企业级 Agentic AI 平台
- (下篇)Solutions Memory:让 AI Agent 从成功案例中持续学习 —— 双 Memory 架构实践
- 以Kiro快速部署云上Agent:只需几个小时,从业务需求到部署于Amazon Bedrock Agentcore落地
- 基于 AWS DevOps Agent 构建 AI 驱动的运维分析系统
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
