亚马逊AWS官方博客
Amazon S3 更新 – 强大的写后读一致性
我们在 2006 年推出 S3 时,我讨论了它几乎无限的容量(“… 可轻松存储任意数量的数据块…”)、它旨在提供 99.99% 的可用性以及持久的存储,且数据透明地存储在多个位置。自那次发布以来,我们的客户令人惊奇的以多样化方式使用 S3:备份和恢复、数据存档、企业应用程序、网站、大数据以及(根据最新统计)超过 10000 个湖内数仓。
S3 和其他大规模分布式系统的一个更有趣(有时也有些令人困惑)的方面通常被称为最终一致性。简而言之,在调用存储或修改数据的 S3 API 函数(如 PUT)之后,存在一个很小的时间窗口,在此期间,数据已被接受并持久存储,但尚不对所有 GET 或 LIST 请求可见。下面是我的看法:
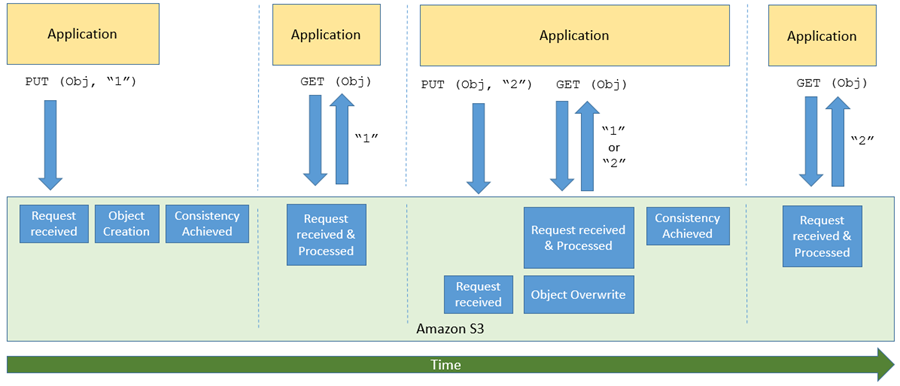
对于大数据工作负载(其中很多使用 Amazon EMR )和湖内数仓来说,S3 的这一方面可能会变得非常具有挑战性,这两个工作负载都需要在写入后立即访问最新的数据。为了帮助客户在云中运行大数据工作负载,Amazon EMR 构建了 EMRFS 一致性视图,开源 Hadoop 开发人员构建了 S3Guard,从而为这些应用程序提供了一层强大的一致性。
S3 现在具有强一致性
在这段过长的介绍之后,我准备分享一些好消息!
所有的 S3 GET、PUT 和 LIST 操作以及更改对象标签、ACL 或元数据的操作现在都具有强一致性,将立即生效。您写入的是什么便会读取什么,LIST 的结果将准确反映存储桶中的内容。这适用于所有现有的和新的 S3 对象,适用于所有区域,并且可以免费供您使用! 对性能没有影响,如果您愿意,您可以每秒更新数百次对象,而且也没有全局依赖项。
这种改进对于湖内数仓来说非常好,但其他类型的应用程序也将受益。由于 S3 现在具有强一致性,因此,将本地工作负载和存储迁移到 AWS 现在应该比以往任何时候都更容易。
我们一直在与 Amazon EMR 团队和开源社区的开发人员合作,以确保客户可以在大数据工作负载中利用此更新。因此,您不再需要使用 EMRFS 一致性视图或 S3Guard,从而进一步降低在 AWS 中运行大数据工作负载的成本。
要了解有关 S3 强一致性的更多信息,请访问此处的功能页面。
Dropbox 有话说
AWS 长期客户 Dropbox 最近将 34PB 分析湖内数仓从本地 Hadoop 集群迁移到 S3。观看此视频,了解更多关于强一致性以及它如何允许 Dropbox 简化湖内数仓的信息:
— Jeff;