亚马逊AWS官方博客
Atlassian 在生产中持续使用 Amazon CodeGuru Profiler 进行程序优化
这个是由Atlassian 的 Jira Cloud Performance团队发布的一片帖子。用他们自己的话说,Atlassian 的使命是释放每个团队的潜力。我们的产品帮助团队组织、讨论和完成他们的工作。 团队所做的事情可以改变世界。我们帮助美国宇航局团队设计了 Mars Rove,Cochlear团队开发听力植入物,数十万其他团队也做着惊人的事情。我们拥有令人难以置信的机会,帮助几乎每个行业的组织中数以百万计的团队。团队合作是很难的,但我们让它更容易。 我们在 Atlasian 构建的产品,当前有数百名开发人员在开发这些产品,这些产品包括单体应用程序和微服务程序。当出现突发事件时,由于代码库中的代码变更很频繁,这样很难对问题进行快速根因诊断。通过代码剖析可以显著加快根因诊断,代码剖析是识别应用程序中的运行时问题和延迟问题的有效技术。如果不采用代码剖析,通常需要自定义代码和临时延迟检测,这种方式容易出错而且会引起其他副作用。 在 Atlassian,我们一直有工具用于剖析生产中的服务,例如使用 Linux perf或async-profiler,虽然这些工具非常有价值,但我们的方法仍有一些限制:
- 需要人员(或系统)的干预,才能在正确的时间捕获配置文件,这意味着经常错过一些暂时性问题
- 临时剖析,无法提供要与之前比较的基线信息
- 出于安全性和可靠性的考虑,在生产环境中运行这些工具的情况并不多
这些限制促使我们研究 持续剖析( continuous profiling)。 除了帮助诊断服务花费的CPU 周期(或时间)外,我们还希望找到一种分析解决方案,提供火焰图等可视化效果,这些可视化效果对于我们后续问题诊断有很大的帮助,比如这样可以更快的通过调用路径理解复杂动态应用程序的调用关系, 还可以用于帮助开发人员了解系统。 我们现有的内部剖析的解决方案是由与们的服务一起部署的脚本构成的,这些脚本可以使用 Linux perf 或async-profiler 生成剖析报告。一部分有权限的开发人员(和 SREs)可以使用 AWS System Manager 在生产节点上运行这些脚本。我们使用 Linux perf 和async-profiler 具有以下几个优点::
- 我们可以可视化为火焰图(易于解释)的格式数据
- 分析单个进程或整个节点的能力
- 跨不同维度(如 CPU、内存和 I/O)进行分析
我们最初的连续剖析(continuous profiling )解决方案包括定期运行 async-profiler(或 Linux perf)的预定作业,将原始结果发送给一个微服务,该微服务用于将数据转换为列式数据(Parquet),然后将结果写入 Amazon 简单存储服务 (Amazon S3)中。 然后我们在 AWS Glue 中定义了一个架构(Schema),允许开发人员使用 Amazon Athena 查询特定服务的性能剖析数据。Athena 使开发人员能够通过编写复杂的 SQL 查询的方式,筛选一定时间范围内和堆栈帧等维度上的性能剖析数据。我们还构建了一个 UI 来运行Athena查询,并使用 SpeedScope 将结果可视化为火焰图。即使我们已经为这个解决方案付出了努力,但是我们仍有大量工作要做,以构建最佳解决方案。 同时,Amazon CodeGuru Profiler的发布引起了我们的注意 ,该服务产品与我们的需求高度相关,并且在很大程度上与我们现有的能力重叠。经过我们深入的评估后,最终决定停止构建我们的解决方案,转而集成 CodeGuru Profiler。 我们选择为每个较小的服务定义一个分析组(profiling group)。对于较大的服务,我们将其被划分为多个分片(每个分片都有单独的自动缩放组),然后为每个分片创建一个分析组。 您可以通过两种可用模式集成 Java Profiler:代理模式和代码模式。为了能够与我们现有的性能剖析功能集成,同时更好的控制代理,我们决定使用代码模式,从应用程序代码中启动代理。这使我们能够通过现有的功能标志机制控制何时启动(或停止)代理。 现在,我们在平台级别集成了 CodeGuru 探查器,使任何Atlassian服务团队都能够轻松利用此功能。
检查和延迟
我们使用 CodeGuru Profiler 的第一种场景是识别代码调用路径,这些代码调用路径可以直观的看到 CPU 利用率或延迟方面的问题。我们在采集的性能数据中查找不同的形式的同步调用,一个有趣的事情是由Collections.synchronizedMap构成的 EnumMap类 . 以下截图显示此部分代码在 24 小时中的堆栈帧线程状态监控。 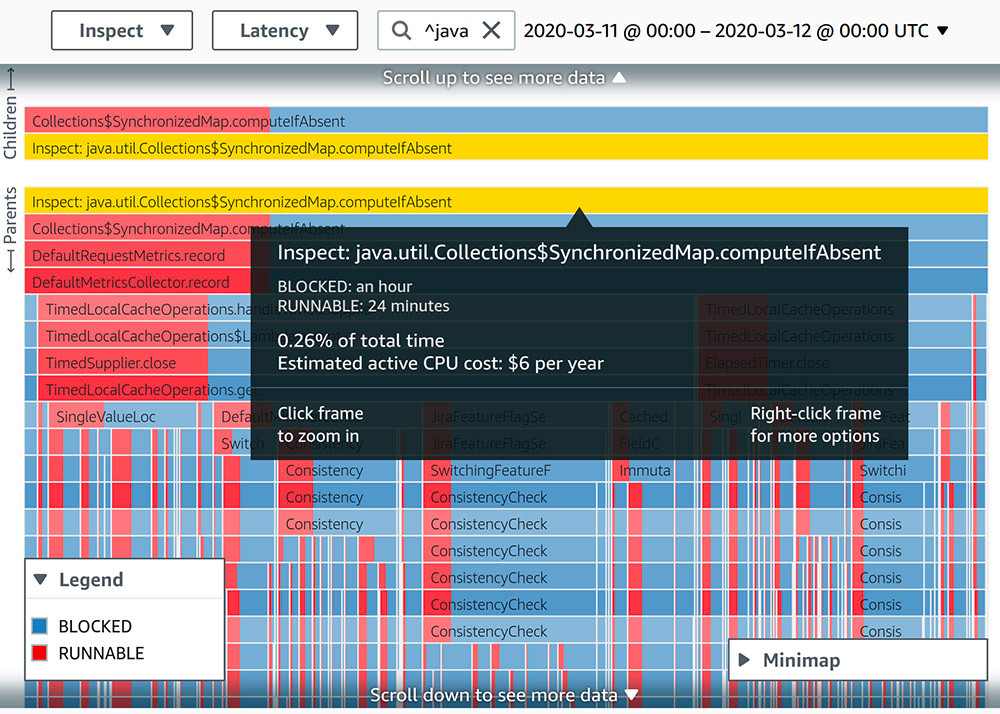 尽管所涉及的堆栈跟踪消耗的运行时间不到 0.5%,但当我们进一步观察线程状态的延迟时,我们看到它在BLOCKED状态下花费的时间是 RUNNABLE状态的两倍。为了增加在 RUNABLE状态下花费的时间比例,我们从使用 EnumMap 转向使用 ConcurrentHashMap 的实例 提示: 如果大量线程处于BLOCKED说明CPU一直在等待一些资源的释放才能继续处理,这样造成了CPU的浪费,比如EnumMap 由 Collections.synchronizedMap 构成的,它是通过同步的方式实现的,这样会产生大量的锁从而引起线程的BLOCKED。这里我们将其替换为ConcurrentHashMap类来实现,ConcurrentHashMap是通过分段式锁来实现的,相较于Collections.synchronizedMap更高效。 下面的截图显示了类似的 24 小时内的性能数据。实现更改后,相关的堆栈跟踪现在全部处于 RUNABLE 状态。
尽管所涉及的堆栈跟踪消耗的运行时间不到 0.5%,但当我们进一步观察线程状态的延迟时,我们看到它在BLOCKED状态下花费的时间是 RUNNABLE状态的两倍。为了增加在 RUNABLE状态下花费的时间比例,我们从使用 EnumMap 转向使用 ConcurrentHashMap 的实例 提示: 如果大量线程处于BLOCKED说明CPU一直在等待一些资源的释放才能继续处理,这样造成了CPU的浪费,比如EnumMap 由 Collections.synchronizedMap 构成的,它是通过同步的方式实现的,这样会产生大量的锁从而引起线程的BLOCKED。这里我们将其替换为ConcurrentHashMap类来实现,ConcurrentHashMap是通过分段式锁来实现的,相较于Collections.synchronizedMap更高效。 下面的截图显示了类似的 24 小时内的性能数据。实现更改后,相关的堆栈跟踪现在全部处于 RUNABLE 状态。
建议报告
CodeGuru Profiler 还为每个分析组提供了相关的建议报告,从性能角度识别常见的反模式(anti-patterns),并给出已知的建议解决方案。我们收到的一份这样的报告(见下面的截图)强调了我们如何使用 JacksonObjectMapper。 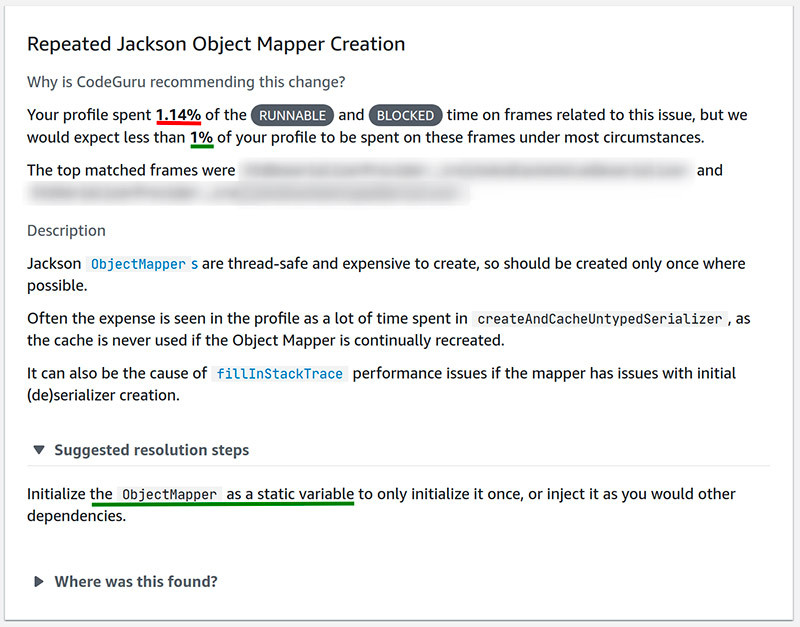 收到此报告后,我们能够快速的识别问题,并对代码问题进行解决。
收到此报告后,我们能够快速的识别问题,并对代码问题进行解决。
结论
通过与 CodeGuru Profiler 的集成,对我们来说是向前迈出的重要一步,使Atlassian内部的每个开发人员都具备了发现和处理应用性能问题的能力。 自启用 CodeGuru Profuler以来,我们已获得以下收益:
- 任何 Atlasian 开发人员都可以从任何时间点查找性能状况,从而快速的了解生产中进行的调用路径,以便分析和发现线上的问题。这有助于开发人员了解复杂的应用程序,并在调查性能问题时帮助我们。
- 大大减少了诊断生产中性能问题的时间,同时我们的开发人员在诊断问题时不再需要注入自定义检测代码。
- 整个组织中性能监测数据的开放,有助于提高开发人员自行处理性能优化的主动性。
我们对 CodeGuru Profiler 团队构建的功能感到兴奋,并期待他们接下来将构建的探查技术和功能。
本篇作者
|
Behrooz Nobakht 高级软件工程师 |
Matthew Ponsford 工程技术经理 |
Narayanaswamy Anandapadmanabhan 高级软件工程师 |
我们是Atlassian公司的Jira云性能团队。我们开发出Jira及Trello等工具,供全球成千上万的团队使用。我们致力于为团队用户创造出色的产品、实践与开放的工作成果。Jira云性能团队是一个专项工作组,致力于让Jira与Atlassian团队能够更好地了解、监控并增强自有产品及服务的性能表现。