亚马逊AWS官方博客
增强Amazon EKS 节点自愈方案:基于 NPD 的故障持久化与安全修复探索
摘要:本文介绍了 npd-node-replace 组件的整体架构与实现原理,重点阐述了如何基于该组件对节点问题事件进行采集与分析,并对异常节点状态进行自动化处理。通过对节点异常场景的自动修复机制进行方案设计与实践探索,提升集群的可用性与整体稳定性。
目录
1. 概述
1.1 问题背景
在 Amazon Elastic Kubernetes Service 集群中,节点在运行过程中可能会遭遇多种异常情况,例如内核崩溃、内存不足和底层硬件故障。如果缺乏自动化的检测与处理机制,这些异常节点将会长时间保留在集群中,从而带来以下潜在风险:
- Pod调度失败导致应用程序不可用
- 级联故障影响其他工作负载
1.2 npd-node-replace 组件简介
节点问题检测器(Node Problem Detector) 是Kubernetes 官方提供的节点问题发现组件,旨在使集群管理栈的上游层能够感知到各种节点问题,它通过在每个节点上运行 Daemonset 程序,对节点问题进行收集,并报告给 API server。但是 Node Problem Detector组件仅提供集群问题发现功能,无法实现问题节点的自动化处理。
在之前的博客文章《基于节点问题检测器(Node Problem Detector)监视和报告 Amazon EKS 节点的健康状况和自动恢复》中介绍了基于 Node Problem Detector + Karpenter 的节点问题检测与自动恢复方案。本次方案参考该文章的思想,在实践上进行了全面优化与增强,通过npd-node-replace组件在以下方面实现了显著提升:
- 支持更多节点形态,npd-node-replace 组件同时适用于托管节点组和自管理节点组,不依赖 Karpenter 提供的节点回收或替换能力,从而能够覆盖更多常见的集群数据平面计算资源的部署模式
- 增强节点问题的可观测性与数据留存能力,通过引入 NodeIssueReport 自定义资源,对节点问题事件及其发生时间进行持久化记录。这使得运维人员可以对历史问题进行查询和汇总分析,并为后续的问题定位和根因分析提供数据基础
- 提供可配置的节点问题容忍策略,通过 Tolerance 配置,用户可以针对不同类型的节点问题,定义触发条件(时间窗口与发生次数)以及对应的处理动作(Reboot 或 Replace),以满足不同场景对可用性和稳定性的要求
- 在节点替换过程中保留问题现场,在执行节点替换操作时,方案仅从集群中移除对应的 Node 对象,而不会终止底层的 Amazon Elastic Compute Cloud 实例。相关实例仍可在控制台中查看,便于集群管理员登录实例、收集日志并开展进一步排查
- 覆盖更多节点异常状态,除节点异常事件外,该方案还能够识别并处理 Node 状态为 NotReady 或 Unknown 的情况,从而扩大自动恢复机制的适用范围
- 管理员通知机制更加清晰及时,npd-node-replace 组件集成了 Amazon Simple Notification Service,在发现节点问题,触发自动恢复操作时发送事件通知,帮助管理员及时了解集群状态变化
- 提升自动恢复流程的可靠性,在实现中引入重试机制、错误处理等设计,以降低临时故障或边缘场景对自动恢复流程的影响,提升方案在实际环境中的稳定性
- 支持渐进式启用以降低风险,通过标签白名单机制(使用 npd-node-replace-enabled=true 标签进行节点筛选)控制处理操作生效范围,默认不会对所有节点启用。用户可以先在少量非关键节点上进行验证,再逐步扩展至整个集群,以降低对生产工作负载的潜在影响
2. npd-node-replace组件架构与原理
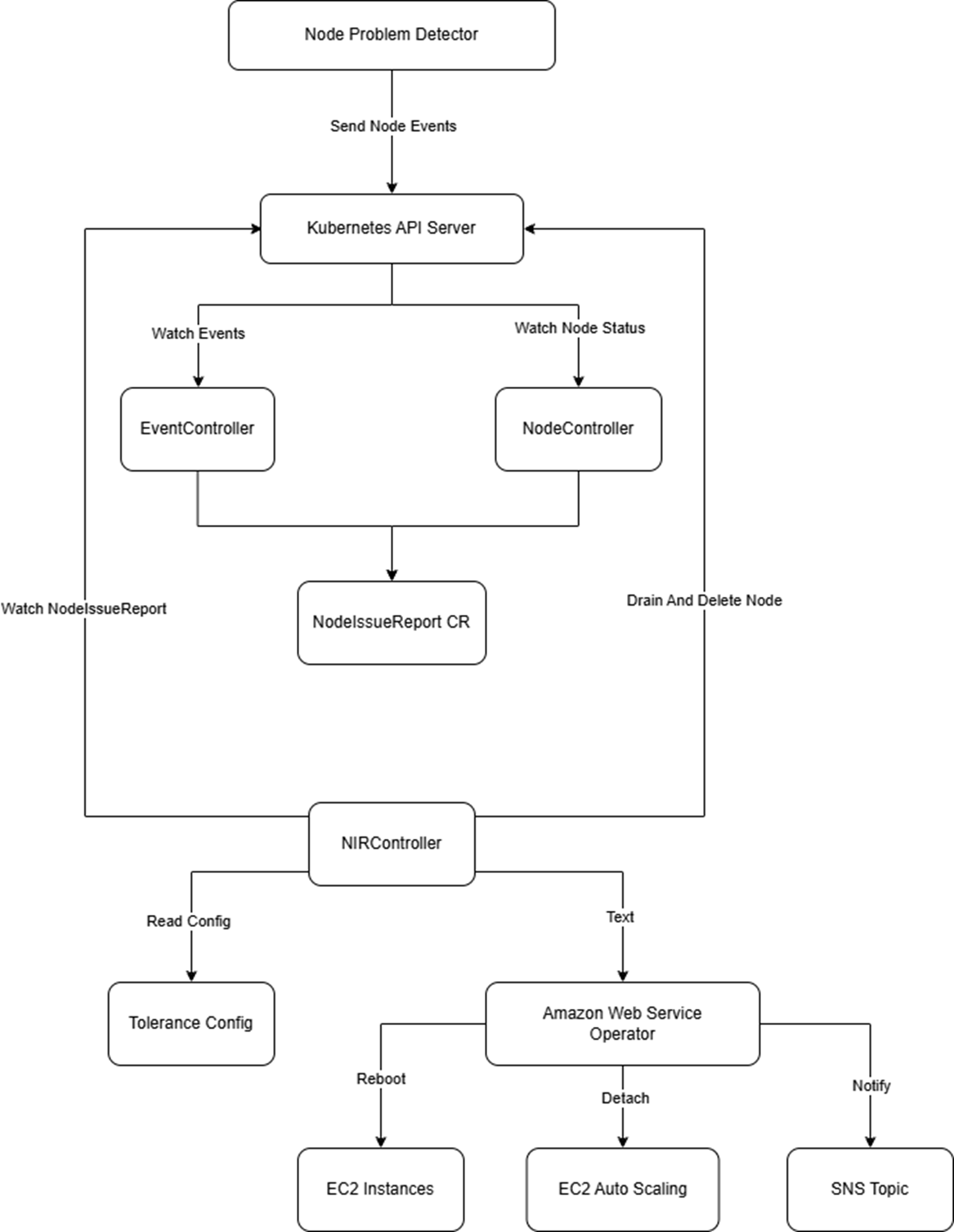
[Pic 1 npd-node-replace 组件架构图] |
- 节点问题检测器(Node Problem Detector)组件在发现节点问题之后,会向 API Server 上报事件,用来报告节点问题
- npd-node-replace 组件的 EventController从 API server 接收来自 Node Problem Detector 组件的事件,将其记录在自定义资源 NodeIssueReport 中
- NIRController 在接收到 NodeIssueReport 资源的变更之后,通过与用户的 Tolerance 配置作对比,判断是否要进行 Reboot 或 Replace 操作
- npd-node-replace 组件的 NodeController 对节点状态监控,当发现节点状态从 Ready 转变为了 NotReady 或 Unknown 状态之后,记录在 NodeIssueReport 资源中,基于 Double Check 和白名单机制判断是否替换节点
2.1节点误处理防护机制
2.1.1 Tolerance 中的时间窗口配置
节点异常事件在实际运行环境中往往具有偶发性,且可能分布在较长的时间跨度内,并不会导致严重的节点问题,因此,npd-node-replace 组件在评估节点异常状态时,并非简单地基于节点历史异常事件的累计次数,而是引入了时间窗口机制,根据异常事件在特定时间范围内的发生频率进行判断。
Tolerance 配置中 timewindowinminutes 用于配置时间窗口的大小,若历史发生的事件不在 Tolerance 配置的时间窗口之内,则仅会做记录,而不会被认为是当前有效的节点问题事件。
2.1.2 节点状态异常的 Double Check
当节点被发现状态异常时,为了防止误操作,并不会立刻开始节点替换。而是会等待一段可配置的时间之后,再次检查状态,只有在第二次节点状态检查仍为 NotReady 或 Unknown 之后才会开始节点替换。该 Double Check 时间间隔可通过 npd-node-replace Pod 的 “NODE_DOULBE_CHECK_GRACE_TIME” 环境变量进行配置,如下为示例配置,节点状态二次检查时间间隔为 15 分钟。
ℹ️ 注意:
NODE_DOULBE_CHECK_GRACE_TIME 要大于新节点启动和节点重启的所需的时间。
2.1.3 白名单机制
在默认的节点配置下,仅会对节点问题进行监控和收集,并不会对节点 Replace 或 Reboot。若管理员确认 npd-node-replace 可以对节点操作,可以使用命令 kubectl label nodes <node name> npd-node-replace-enabled=true 为节点打上标签,启用 npd-node-replace 对节点操作。
2.2 NodeIssueReport 资源生命周期
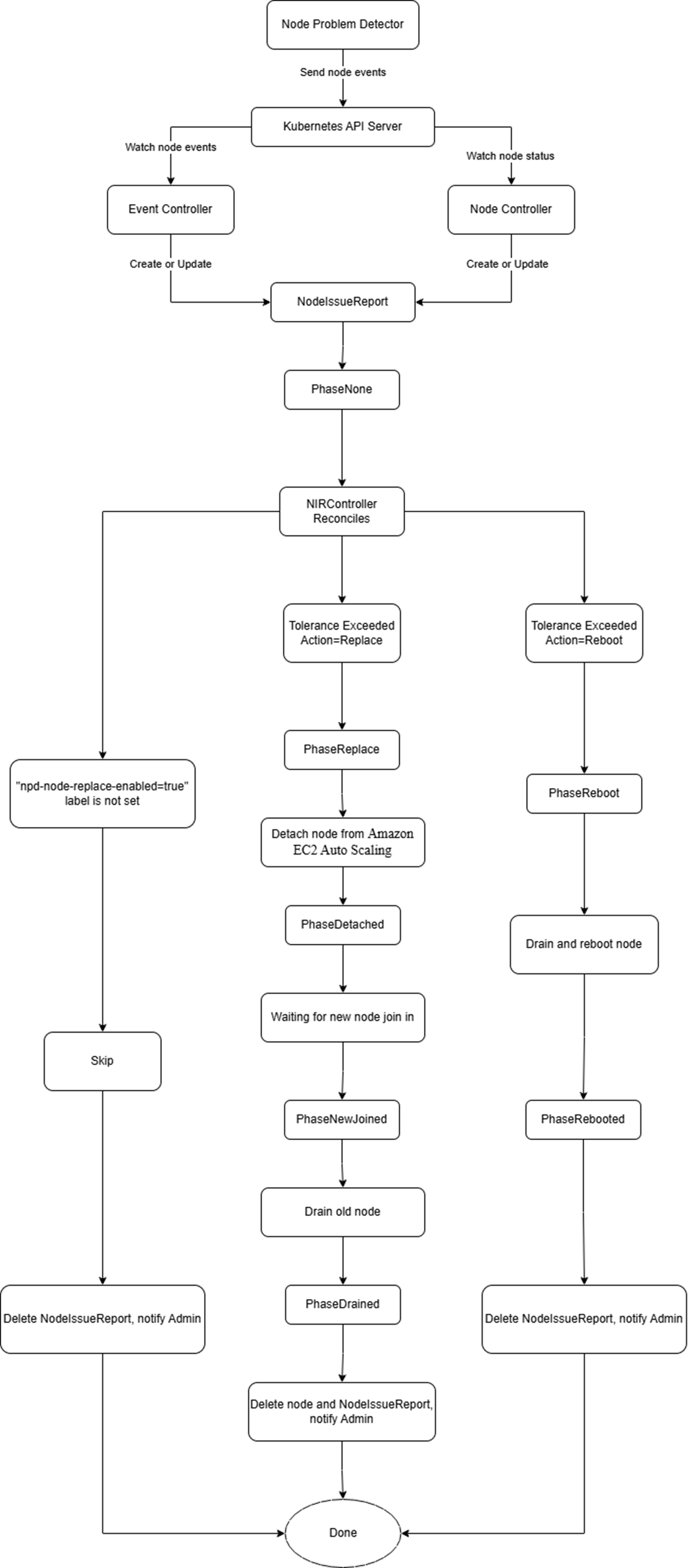
[Pic 2 NodeIssueReport 生命周期] |
1. 当 EventController 接收到 NPD 组件上报的节点问题 Event 时,或 NodeController 检测到节点 Ready 状态为 NotReady 或 Unknown 时,将创建或更新对应的 NodeIssueReport 自定义资源
2. 在 NIRController 的协调过程中,会统计 NodeIssueReport 中特定事件类型在时间窗口内的发生次数,并与 Tolerance 配置中对应事件类型的阈值进行比较。若发生次数达到阈值,则根据该事件的 Tolerance 配置中指定的操作类型,触发节点的 Reboot 或 Replace 自愈流程
Replace 流程:
- 将问题节点从其所属的Amazon EC2 Auto Scaling中分离
- Amazon EC2 Auto Scaling 为了维持副本数会拉起新的节点,等待新节点加入集群并转为 Ready 状态
- Drain 旧节点
- 通过 Amazon Simple Notification Service 主题向集群管理员发送通知事件,告知节点问题及自愈动作,同时从 Kubernetes 集群中删除旧节点。旧节点不会被终止,而是保留在 Amazon Elastic Compute Cloud 控制台用于进一步的问题排查
Reboot 流程:
- 将节点设置为不可调度状态,并 Drain 该问题节点
- 重启节点
ℹ️ 注意:
上述 Replace 和 Reboot 操作仅会对带有 “npd-node-replace-enabled=true” 标签的节点有效,若节点没有该标签,则不会对节点进行操作,此时 npd-node-replace 组件仅会对问题进行收集和报告。
2.3 支持的事件类型
npd-node-replace 组件并不会产生节点问题事件,其本质仍是依赖于节点问题检测器( Node Problem Detector )进行问题的发现和事件的产生,所有支持的事件类型可以参考 Node Problem Detector config。
3. npd-node-replace 组件部署
3.1 先决条件
- 运行稳定的 Amazon Elastic Kubernetes Service 集群,使用托管或自管理节点组作为计算资源,并为集群创建 IAM OIDC 提供商
- 鉴于运行在 Amazon Fargate 上的 Pod 具有独占 Amazon Fargate 节点的特性,为避免 npd-node-replace 组件在处理其自身所在节点时引发中断,需要在集群中创建 Amazon Fargate 配置文件。后续步骤中,我们将把 npd-node-replace 组件部署到 Amazon Fargate 命名空间中,使其运行在 Amazon Fargate 节点上
- npd-node-replace 组件依赖 Node Problem Detector 实现节点问题发现,需要首先部署Node Problem Detector
- 已经存在或创建新的 Amazon Simple Notification Service 主题,并使用邮件订阅
- 已经存在或创建新的 Amazon Elastic Container Registry 容器镜像仓库,用于存储 npd-node-replace 组件容器镜像
3.2 部署步骤
Amazon Identity and Access Management 角色的最小权限如下,将其保存为 iam_policy.json
创建 IAM 策略:
aws iam create-policy –policy-name NPDNodeReplacePolicy –policy-document file://iam_policy.json
使用 eksctl 创建 IAM role 和 serviceaccount
2. 使用 helm 部署:
推送到 Amazon Elastic Container Registry:
添加 helm repo:
helm repo add <alia> https://normalzzz.github.io/npd-node-replace/
更新 values.yaml:
- “snsTopicArn“ 部分为您的 Amazon Simple Notification Service 主题arn,用于接收 npd-node-replace 发布的message,以通知管理员
- “nodeDoubleCheckGraceTime“ 为 UnReady 和 Unknown 状态节点的Double Check 时间间隔,为了防止节点被误处理,需要大于节点重启与新节点加入所需时间,默认为15 mins
- “repository” 填写用于存储 npd-node-replace 容器镜像的 ECR repository 链接
- “IRSA IAM role arn“为第1步” Amazon Identity and Access Management 配置”中用于 IRSA 授权的 Amazon IAM 角色 arn,若您希望使用不同的角色,可以更改该值
- “toleranceJson“ 为您的Tolerance 配置 ,该配置仅为示例,您需要根据自己的需求进行更改
部署 helm chart,其中 –set serviceAccount.create=false 选项代表不再创建 service account 资源,service account 在第1步 “Amazon Identity and Access Management 配置”中已经创建
helm install <release name> <alias>/npd-node-replace --namespace <fargate namespace> --set serviceAccount.create=false -f values.yaml
验证 npd-node-replace 组件是否安装成功,检查 Deployment 资源状态,确保其已正常运行
kubectl get deployment -n <fargate-namespace> | grep npd-node-replace
4. 测试
4.1 测试方式
1. 参考 Node problem detector 的 problem maker 的实现,通过登录节点并向节点中输入问题日志的方式,模拟节点异常场景:
例如通过如下命令,可以在节点上模拟 OOMKilling 事件:
通过如下命令可以模拟节点 KernelOops 问题:
2. 之后通过如下命令查看 npd-node-replace 组件收集到的节点问题事件:
4.2 测试流程与结果
1. 首先登录到节点运行如下命令,模拟节点问题
2. 查看该节点相关的 NodeIssueReport 资源中的问题记录
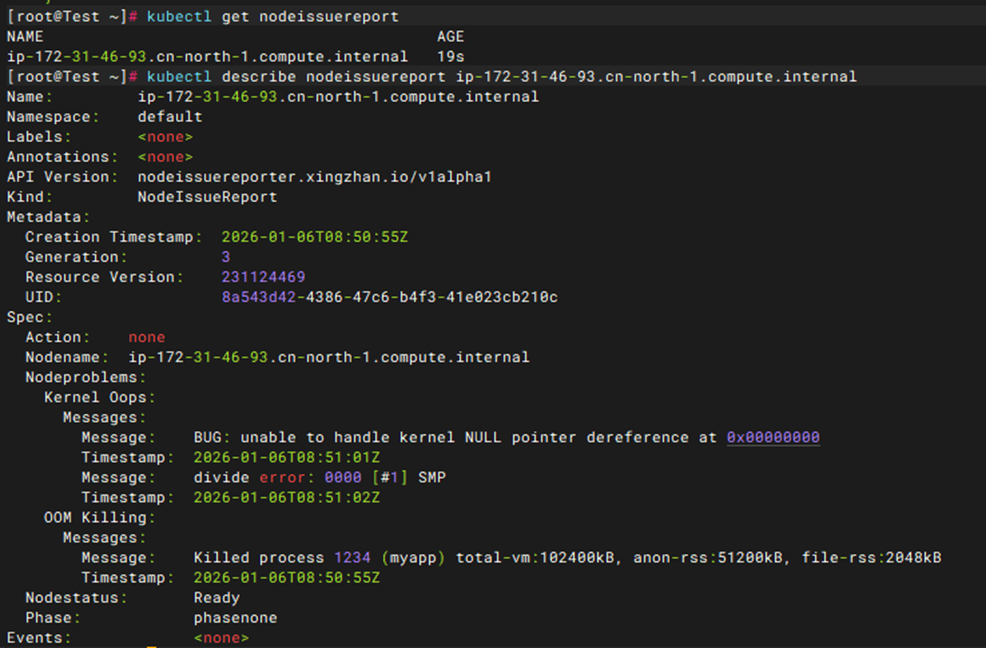
[Pic 3 示例 NodeIssueReport] |
3. 再次运行 echo "Killed process 1234 (myapp) total-vm:102400kB, anon-rss:51200kB, file-rss:2048kB" | sudo tee /dev/kmsg 命令,使 OOMKilling 事件发生次数达到 Tolerance 中配置的阈值
4. 当节点问题事件发生次数达到 Tolerance 容忍度配置的阈值之后,触发 Reboot Action,但是由于节点未被标签 “npd-node-replace-enabled=true“,未列入白名单,npd-node-replace 没有对节点实行操作
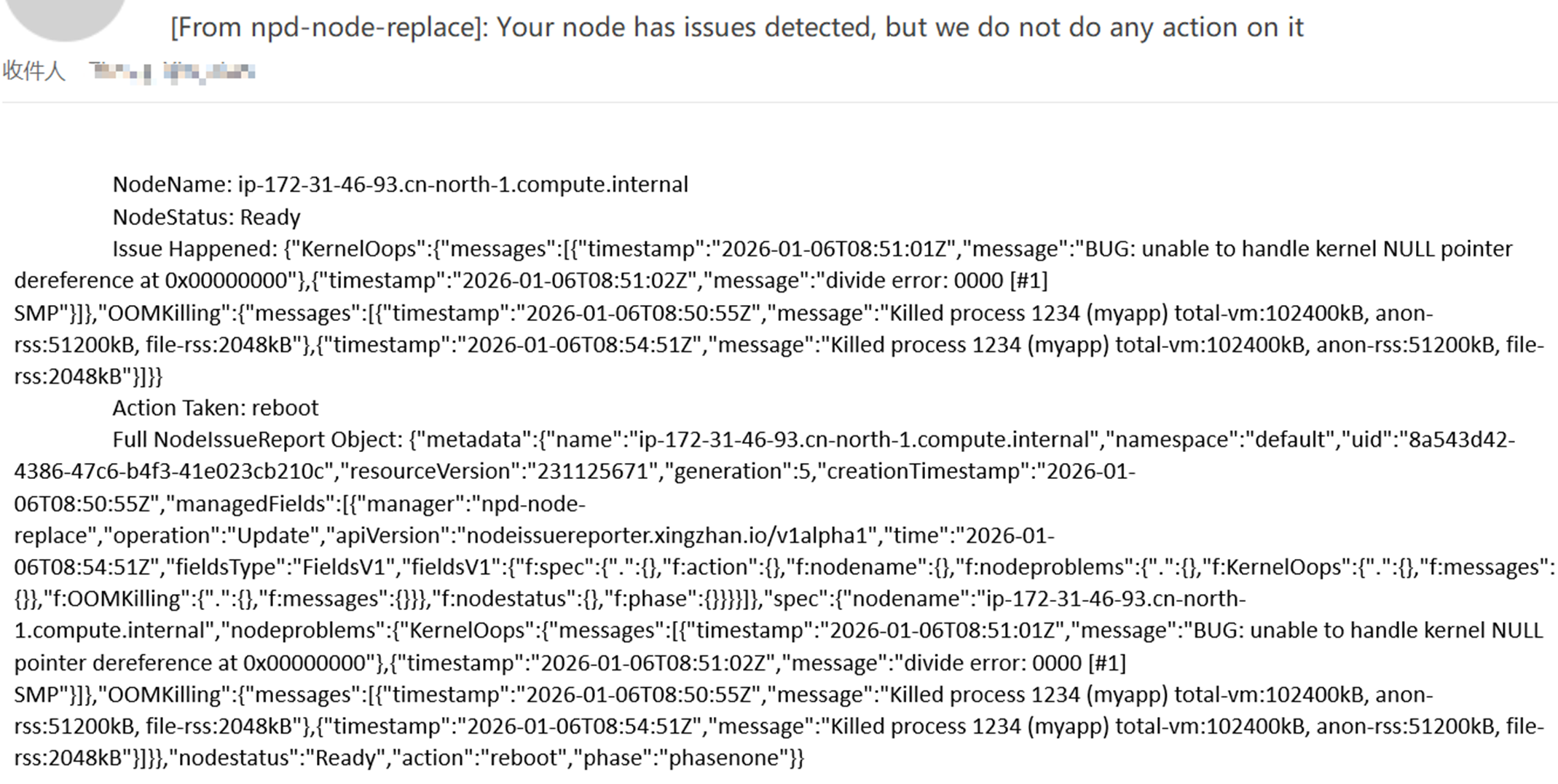
[Pic 4 示例邮件通知] |
5. 为节点启用 npd-node-replace 再次进行测试:
为节点添加 “npd-node-replace-enabled=true” 标签,将节点纳入 npd-node-replace 组件的白名单,启用 npd-node-replace 操作
kubectl label nodes <node name> npd-node-replace-enabled=true
模拟问题触发节点 Reboot 操作,基于上述配置过程中的 Tolerance 配置,两次 OOMKilling 事件即可触发节点重启,日志输出如下,从日志中可以观察到节点重启的工作流程为:
- 将节点设置为不可调度状态,并 Drain 该问题节点
- 重启节点
- 将节点重新设置为可调度状态
- 通知管理员
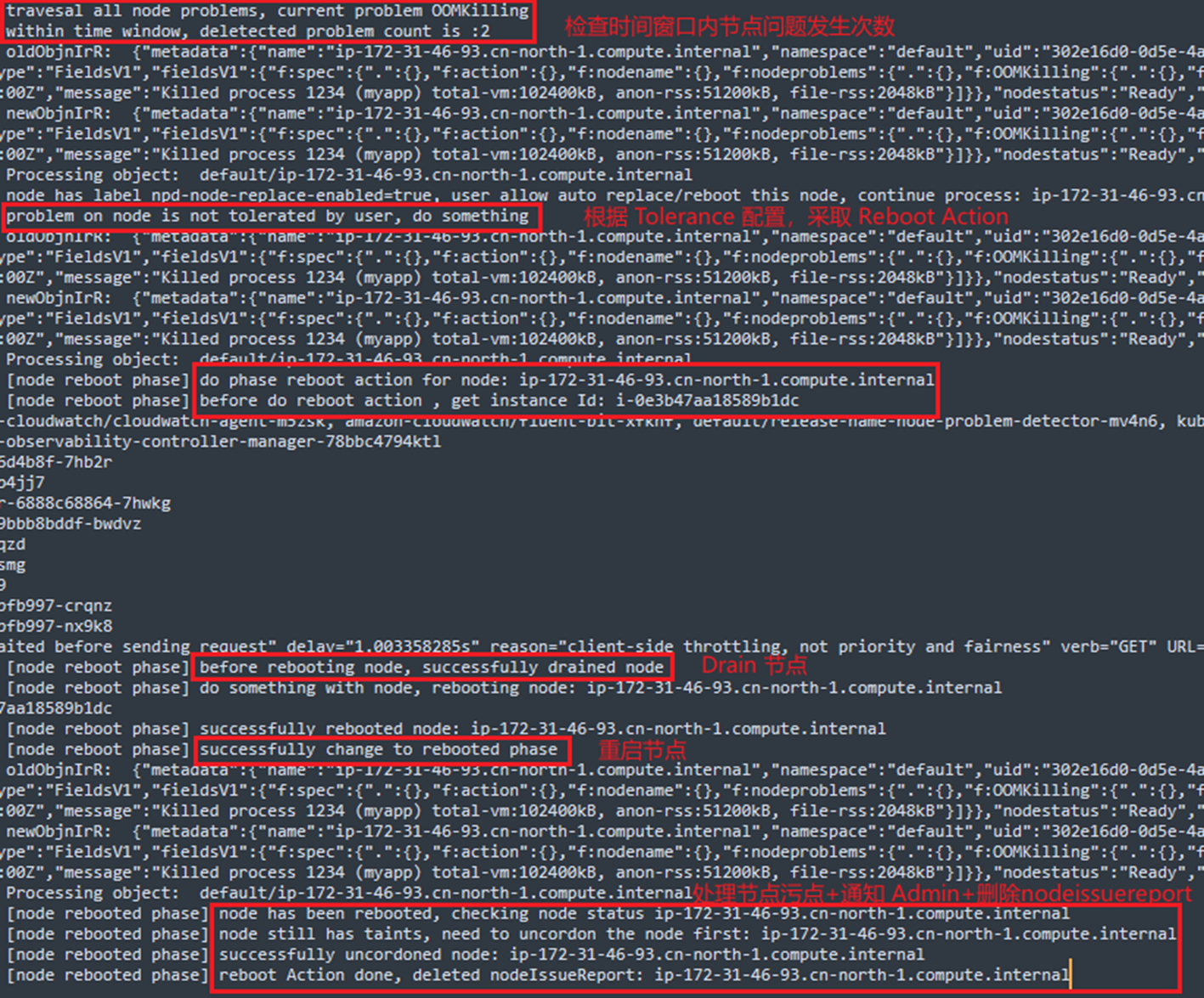
[Pic 5 Reboot Action 日志] |
模拟问题触发 Replace 操作,基于上述 Tolerance 配置,三次 KernelOops 事件会触发节点替换,日志输出如下,从日志中可以观察到节点替换的工作流程为:
- 从 Amazon EC2 Auto Scaling中分离节点
- 等待新节点成功加入集群并处于 Ready 状态
- Drain 旧节点
- 通知管理员并删除旧节点
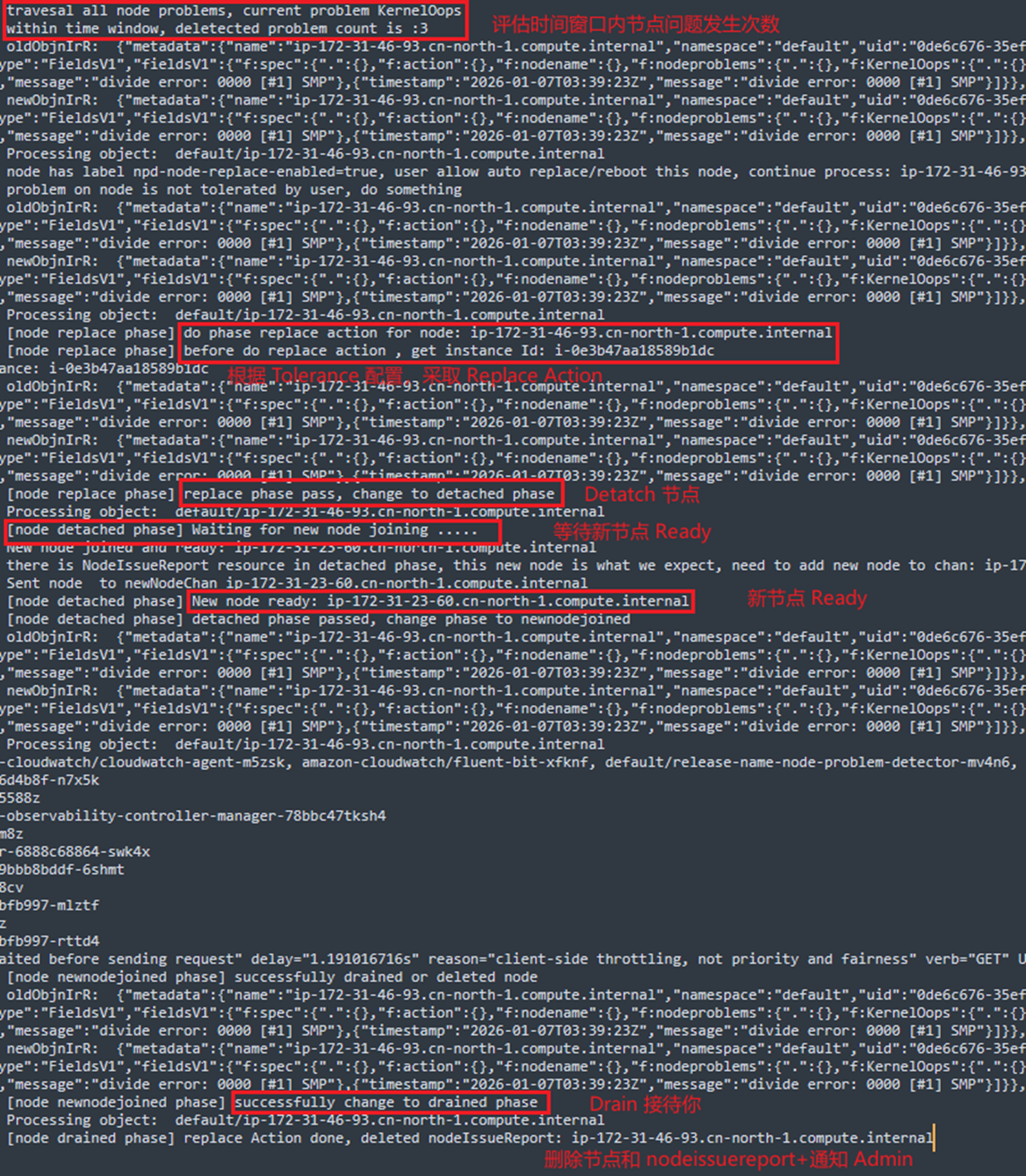
[Pic 6 Replace Action 日志] |
模拟节点状态异常触发节点替换,通过在节点上执行 systemctl stop kubelet 命令停止 kubelet 进程,这时候由于节点 kubelet 进程被停止,节点无法向 API server 上报信息,状态会转为 Unknown,进而触发节点强制替换操作,日志记录如下,从日志中可以观察到异常状态节点的处理流程为:
- 检测到节点转为 NotReady 或 Unknown 状态
- 等待 15 分钟(NODE_DOUBLE_CHECK_GRACE_TIME)后再次检查,若节点仍未达到 Ready 状态,则对该节点执行 Replace 操作
- 从 Amazon EC2 Auto Scaling中分离节点
- 等待新节点加入集群并状态转变为 Ready
- Drain 旧节点
- 通知管理员并从集群中删除旧节点
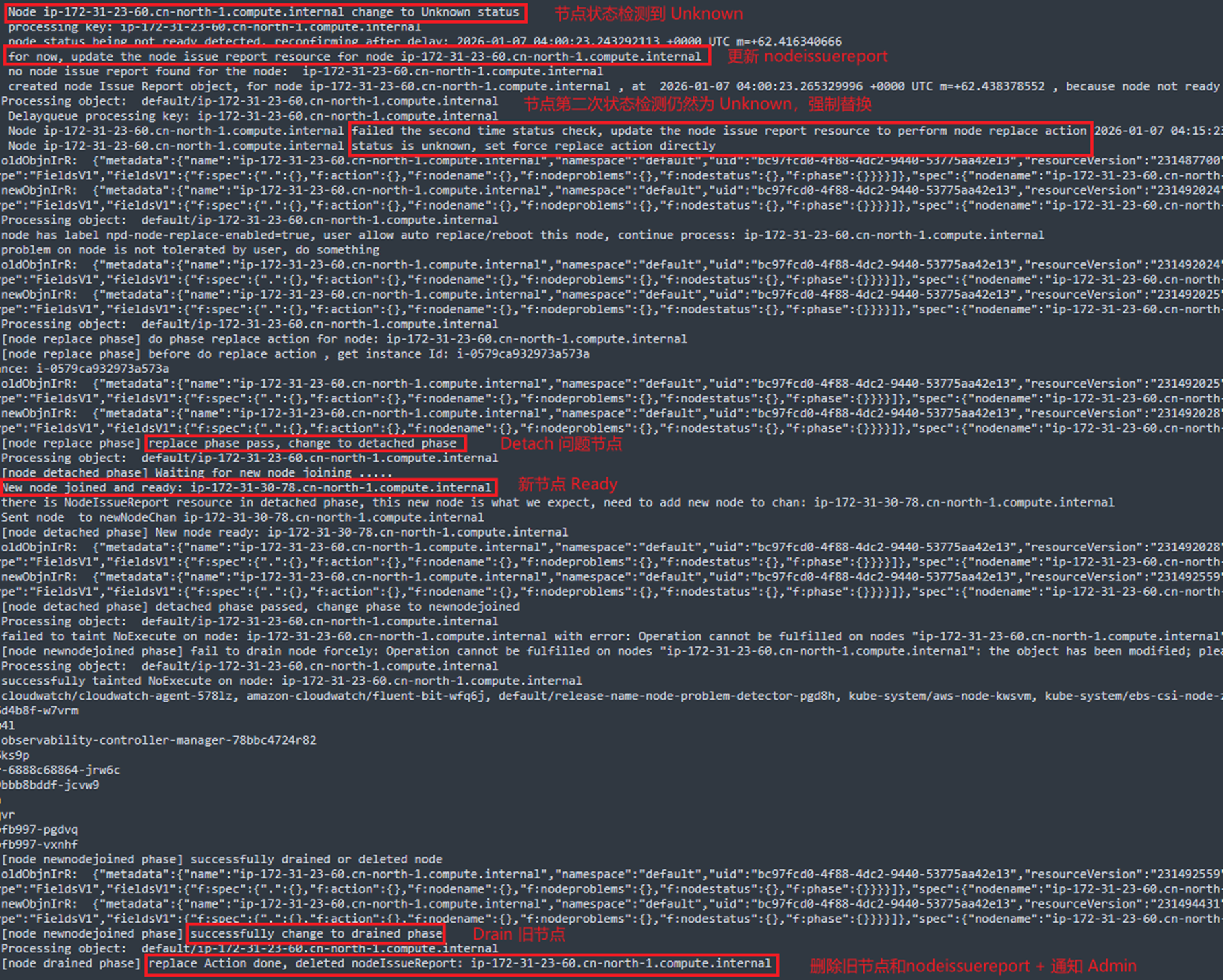
[Pic 7 节点 Unknown 状态强制替换日志] |
5. 最佳实践
阶段1:部署观察
先部署相关组件,但暂不为任何节点添加 npd-node-replace-enabled=true 标签;随后观察邮件通知,确认 NPD 能正常检测到集群中的节点问题以及 npd-node-replace 可以通知管理员。
阶段2:测试节点验证
为集群中部分非关键应用所处节点添加 npd-node-replace-enabled=true 标签,启用 npd-node-replace 操作,验证Reboot 和Replace 处理流程可以正常工作。
阶段3:测试节点扩展
为所有测试节点添加 npd-node-replace-enabled=true 标签,启用 npd-node-replace 操作,并观察 npd-node-replac 组件工作是否符合预期。
日志记录与收集:
npd-node-replace 组件的日志中会包含详细的工作流程信息,建议配置Amazon Fargate 日志记录并输出到 Amazon Cloudwatch便于问题监控与后续排查。
npd-node-replace镜像 dockerhub 地址:
https://hub.docker.com/layers/zxxxxzz/npd-node-replace/v1.2/
npd-node-replace 组件代码仓库:
https://github.com/normalzzz/npd-node-replace
若您在使用过程中遇到任何问题,欢迎您提交 Issue,您的问题会被及时看到并处理。
6. 结语
➡️ 下一步行动:
相关产品:
- Amazon Fargate — 适用于容器的无服务器计算
- Amazon EC2 — 安全且可调整大小的计算容量
- Amazon IAM — 身份管理和访问权限
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon ECS — 完全托管的容器编排服务
相关文章:
- 在 AWS 上实现 DolphinScheduler 工作流的自动化跨环境部署
- 基于亚马逊云科技 Mac 实例部署 OpenClaw,深度苹果生态自动化的最佳选择
- DX 维护通知全球自动化处理方案 — 基于 Severless 的跨账号/跨区域实践
- 如何实现AWS账户登录活动自动化告警和响应(二)
- 如何实现AWS账户登录活动自动化告警和响应(一)
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
