亚马逊AWS官方博客
基于 Amazon CloudFront 和 Lambda@Edge 实现失败请求的完整记录与异步重放
摘要:本文介绍了一种基于 Amazon CloudFront 双 Lambda@Edge的架构方案,在不修改源站代码的前提下,完整记录被 WAF 拦截及源站返回错误的请求(含 headers 和 body),并通过 CloudWatch Logs + Kinesis Data Firehose 汇聚至 S3,支持异步补数重放。
一、引言
在使用 Amazon CloudFront 进行全球加速并配合 AWS WAF 进行安全防护的架构中,企业客户经常面临一个运维挑战:如何完整记录所有失败请求的详细信息(包括 request headers 和 request body),以支持后续的异步数据补偿和请求重放。本文将介绍在 AWS 上实现这一需求的完整方案,包括技术选型过程中的关键技术细节、最终架构设计以及详细的实施步骤。
二、概览
2.1 业务场景
在典型的企业架构中,动态站点的源站可能部署在非 AWS 环境(如第三方云平台),前端通过 Amazon CloudFront 进行全球加速,并挂载 AWS WAF 提供安全防护。业务方需要记录所有失败请求的完整信息,用于后续异步补数重放。
这里的”失败请求”包括两类:
- 被 AWS WAF 拦截的请求:触发了安全规则(如 XSS、SQL 注入检测),直接返回 403 响应
- 源站响应 4xx/5xx 的请求:请求到达了源站,但处理失败(如 500 内部错误、502 网关超时)
成功请求(2xx/3xx)不记录,以控制成本和存储量。
为什么需要补数重放? AWS WAF 规则可能误拦截正常业务请求,源站也可能因临时故障返回 500。如果能记录这些失败请求的完整信息,后续可以通过脚本从 Amazon S3 读取日志,异步重放恢复数据。
2.2 方案收益
| 维度 | 收益 |
|---|---|
| 信息完整性 | 记录失败请求的完整 headers 和 body,支持精确重放 |
| 零侵入性 | 无需修改源站代码,完全在 Amazon CloudFront 层实现 |
| 成本可控 | 仅对失败请求执行日志记录逻辑,成功请求零额外开销 |
| 架构简洁 | 日志自动汇聚到 Amazon S3,便于后续分析和重放 |
三、方案架构
该方案采用双 Lambda@Edge 函数架构,部署在 Amazon CloudFront 的 origin-request 和 origin-response 两个阶段,配合 Amazon CloudWatch Logs、Amazon Kinesis Data Firehose 和 Amazon S3 实现完整的日志采集链路。
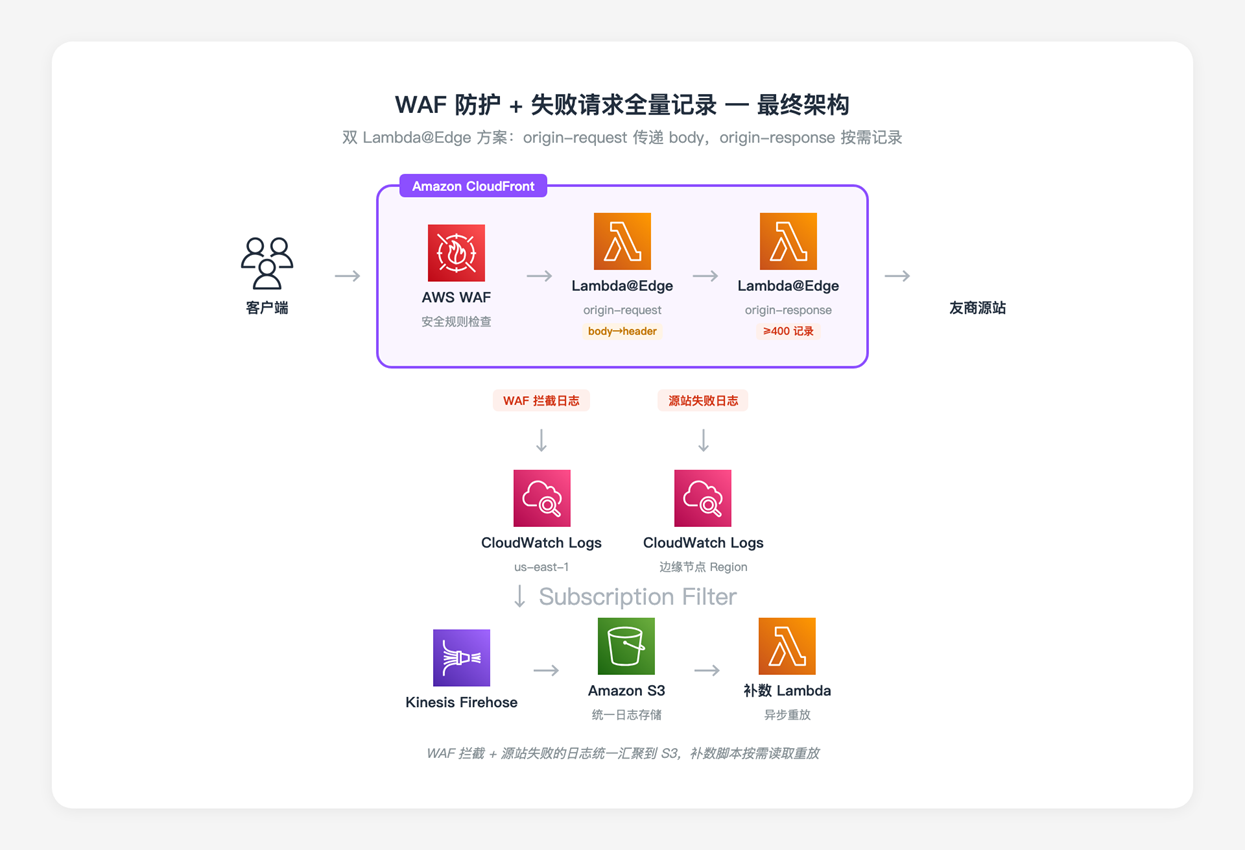
[图1:失败请求记录方案整体架构] |
3.1 核心组件
| 组件 | 功能 | 说明 |
|---|---|---|
| Amazon CloudFront | 全球加速与请求分发 | 作为流量入口,关联 AWS WAF 和 Lambda@Edge |
| AWS WAF | 安全防护 | 拦截恶意请求,自动记录拦截日志 |
| Lambda@Edge (origin-request) | 请求体暂存 | 将 request body 写入自定义 header,传递给下游阶段 |
| Lambda@Edge (origin-response) | 失败请求记录 | 检测响应状态码,对 4xx/5xx 请求记录完整日志 |
| Amazon CloudWatch Logs | 日志存储 | 接收 Lambda@Edge 和 AWS WAF 的日志输出 |
| Amazon Kinesis Data Firehose | 日志传输 | 通过 Subscription Filter 将日志投递到 Amazon S3 |
| Amazon S3 | 日志归档 | 统一存储所有失败请求日志,供补数脚本读取 |
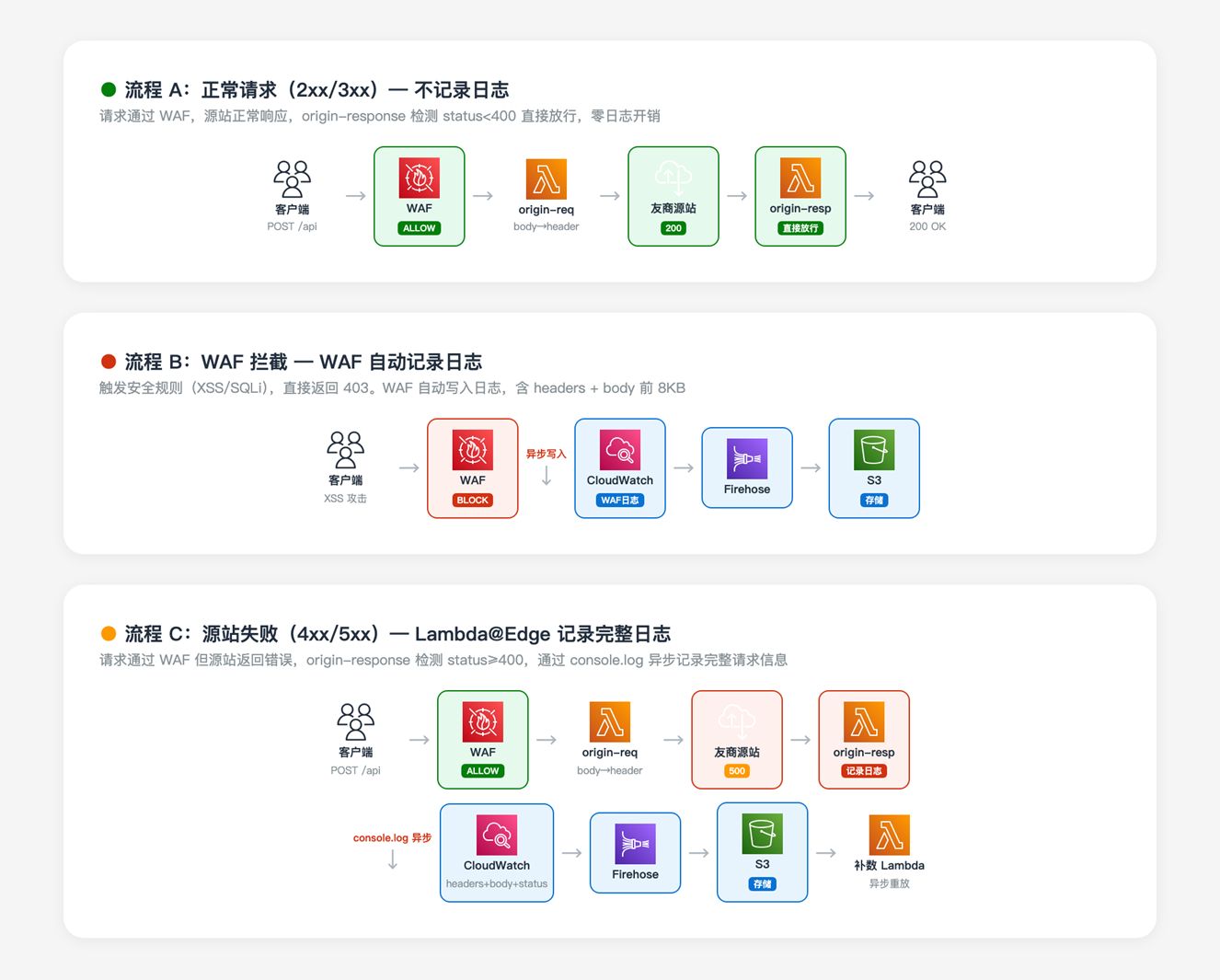
3.2 工作流程
整体工作流程分为两条日志采集路径:
3.2.1 路径一:AWS WAF 拦截的请求
- 请求到达 Amazon CloudFront,AWS WAF 检测到安全威胁并拦截
- AWS WAF 自动将拦截日志(包含 headers、body 前 8KB、触发规则)写入 Amazon CloudWatch Logs
- 通过 Subscription Filter 将日志投递至 Amazon Kinesis Data Firehose
- Amazon Kinesis Data Firehose 将日志写入 Amazon S3
3.2.2 路径二:源站返回错误的请求
- 请求通过 AWS WAF 检查后,到达 origin-request 阶段
- origin-request Lambda@Edge 将 request body 写入自定义 header
X-Original-Body - 请求转发至源站,源站返回 4xx/5xx 响应
- origin-response Lambda@Edge 检测到错误状态码,从自定义 header 读取 body,记录完整请求信息到 Amazon CloudWatch Logs
- 日志通过相同的 Subscription Filter 和 Amazon Kinesis Data Firehose 管道写入 Amazon S3
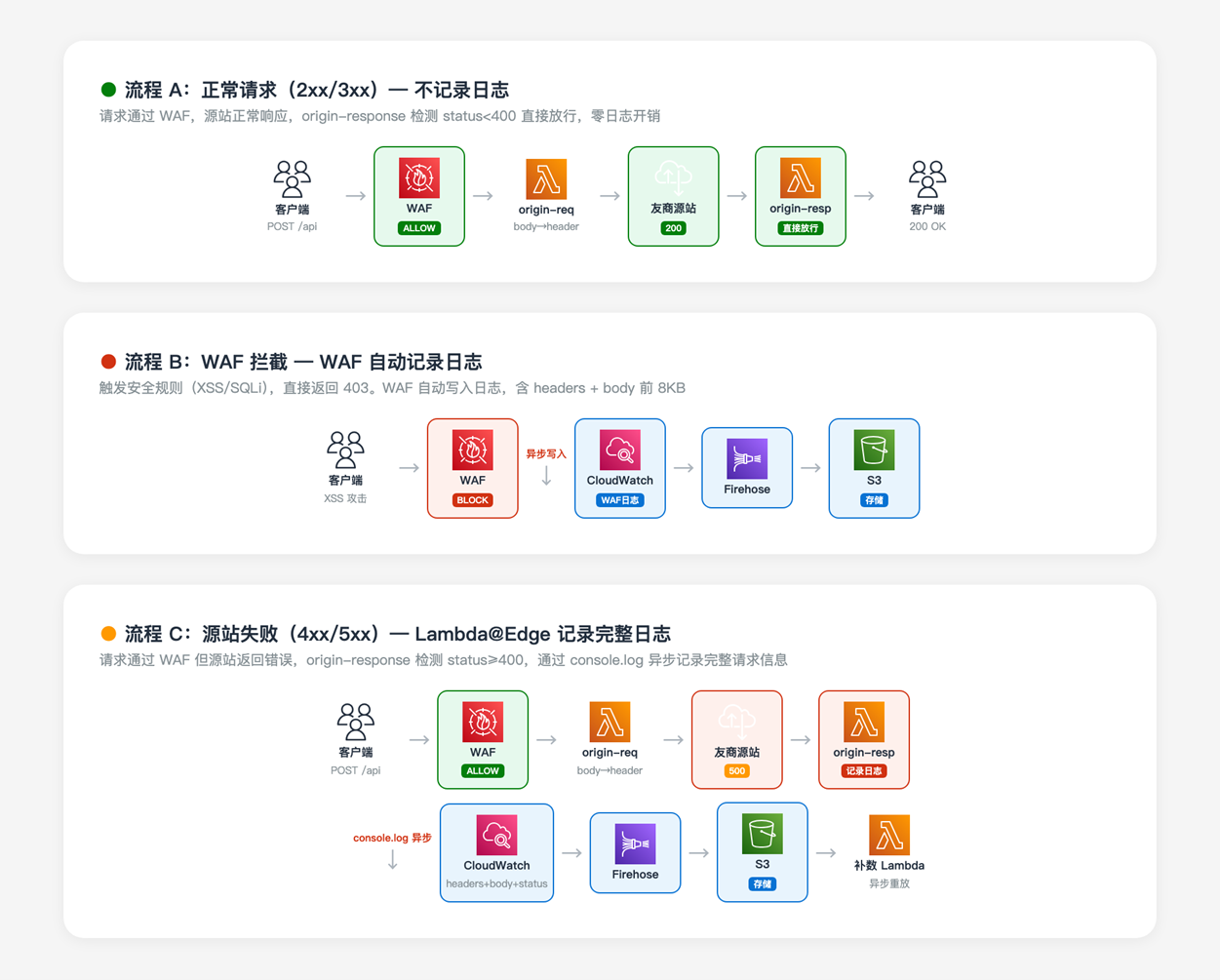
[图2:日志采集流向示意图] |
四、方案评估与选型
在确定最终方案之前,需要对多种技术方案进行系统评估。以下是针对”源站部署在非 AWS 环境、无法修改源站代码、需要记录完整 headers 和 body”这一场景的六种候选方案分析。
4.1 候选方案概述
4.1.1 方案 A:应用层记录
在源站应用中添加中间件,当响应 4xx/5xx 时记录完整请求信息。
- 优势:零额外 AWS 成本,对正常请求零开销
- 局限:需要修改源站代码;如果源站部署在第三方云平台,代码改动和日志同步均不便
- 适用场景:源站在 AWS 上,且有权限修改应用代码
4.1.2 方案 B:Amazon CloudFront 实时日志 + Amazon Kinesis
利用 Amazon CloudFront Real-time Logs 将请求详情异步记录到 Amazon Kinesis Data Streams。
- 优势:无需 Lambda@Edge,异步处理不影响请求延迟
- 局限:不包含 request body,仅记录 headers、status code、URI 等元数据
- 适用场景:不需要 body,仅需请求元数据的场景
4.1.3 方案 C:ALB Access Logs
如果源站前端有 Application Load Balancer,可以启用 Access Logs。
- 优势:零额外成本
- 局限:不记录 request body 和完整 headers;源站不在 AWS 时不适用
- 适用场景:源站在 AWS 上,仅需基本访问日志
4.1.4 方案 D:Custom Error Pages + Lambda@Edge
利用 Amazon CloudFront 的 Custom Error Pages 功能,仅在源站返回错误时触发 Lambda@Edge。该方案参考了 AWS 官方博客 Enhanced Origin Failover using Amazon CloudFront and AWS Lambda@Edge 中介绍的架构模式。
- 优势:成本极低,仅在错误时执行 Lambda
- 局限:CloudFront 在错误重定向后发起的是全新内部请求,原始 request body 和 request headers 均丢失
- 适用场景:错误时执行 failover 或展示友好错误页面
4.1.5 方案 E:origin-request Lambda + 实时日志关联
在 origin-request 阶段记录 body 和 requestId 到 Amazon CloudWatch,同时通过 Amazon CloudFront 实时日志记录 status code,后续通过 requestId 进行关联分析。
- 优势:仅需一个 Lambda@Edge 函数,Lambda 执行成本减半
- 局限:需要额外的 Amazon Kinesis 资源,关联逻辑复杂,总成本并无显著降低
- 适用场景:对架构复杂度不敏感,希望减少 Lambda 调用次数
4.1.6 方案 F:双 Lambda@Edge(推荐方案)
在 origin-request 阶段将 body 写入自定义 header,在 origin-response 阶段检测错误并从 header 读取 body,记录完整日志。
- 优势:单条日志包含完整信息(status code + headers + body),无需跨数据源关联;不依赖源站做任何改动;架构简洁,易于维护
- 局限:每个请求触发两次 Lambda@Edge;body 通过 header 传递,受 20KB 总请求大小限制
- 适用场景:需要完整请求信息记录且无法修改源站代码
4.2 方案对比
| 方案 | 完整 Headers | 完整 Body | 无需改源站 | 成本 | 架构复杂度 |
|---|---|---|---|---|---|
| A. 应用层记录 | 是 | 是 | 否 | 低 | 低 |
| B. CloudFront 实时日志 | 是 | 否 | 是 | 中 | 低 |
| C. ALB Access Logs | 否 | 否 | 否 | 低 | 低 |
| D. Custom Error Pages | 否 | 否 | 是 | 低 | 中 |
| E. origin-request + 日志关联 | 是 | 是 | 是 | 中 | 高 |
| F. 双 Lambda@Edge | 是 | 是 | 是 | 中 | 低 |
在”源站部署在第三方云平台、无法修改源站代码、需要完整 headers 和 body”这三个硬性约束下,方案 F(双 Lambda@Edge)是唯一同时满足所有需求的方案。
4.3 选型过程中的关键技术细节
在方案评估过程中,有三个关键的技术细节需要特别说明,这些细节直接影响了最终的方案选型。
4.4 细节一:origin-response 阶段无法访问 request body
根据 AWS 官方文档 Work with requests and responses 的说明:
You can opt to have Lambda@Edge expose the body in a request… choose Include Body when you create a CloudFront trigger for your function that’s for a viewer request or origin request event.
Include Body 选项仅适用于 viewer-request 和 origin-request 两个阶段。在 origin-response 阶段,Amazon CloudFront 传递给 Lambda 的 request 对象中包含 method、URI、headers,但 body 已被丢弃。
同一文档中另有说明:
When you’re working with the HTTP response, Lambda@Edge does not expose the body that is returned by the origin server to the origin-response trigger.
这意味着单个 Lambda@Edge 函数无法在 origin-response 阶段同时获取响应状态码和请求体,因此需要采用双函数架构。

[图3:CloudFront Lambda@Edge 四阶段数据访问能力] |
4.5 细节二:Amazon CloudFront 存在两套不同的 Header 大小限制
在评估通过自定义 header 传递 request body 的可行性时,Amazon CloudFront Quotas 文档中存在两套不同的 header 限制,适用于不同场景:
| 限制类型 | 最大值 | 适用场景 |
|---|---|---|
| Custom Headers(静态) | 单个 header 值 1,783 字符 | Amazon CloudFront 控制台配置的 Origin Custom Headers |
| 请求总大小(动态) | 20,480 字节(含 headers + query string) | Lambda@Edge 在代码中动态设置的 header |
对于 10KB 的 request body,经过 base64 编码后约 13.3KB,加上其他原始 headers(通常 2-4KB),总计约 15-17KB,在 20KB 限制范围内。
ℹ️ 注意:
在查阅 Amazon CloudFront Quotas 文档时,需要区分不同章节的限制所适用的场景,避免将静态 Origin Custom Headers 的限制误用于 Lambda@Edge 动态 header 的评估。
4.6 细节三:Lambda@Edge 日志写入执行节点所在区域
Lambda@Edge 的日志不是写入函数部署区域(通常为 us-east-1)的 Amazon CloudWatch,而是写入实际执行节点所在区域的 Amazon CloudWatch。例如,函数部署在 us-east-1,但用户从中国访问时请求被路由到 us-west-2 的边缘节点,日志则写入 us-west-2 的 Amazon CloudWatch Logs。
这意味着:
- 调试时需要在多个区域查看 Amazon CloudWatch Logs
- 如果需要通过 Subscription Filter 将日志汇聚到 Amazon Kinesis Data Firehose,需要在每个有用户访问的区域配置相应的 Subscription Filter
五、实施详解
5.1 前置条件
在开始实施之前,请确保满足以下条件:
5.1.1 AWS 环境要求:
- 具有适当 IAM 权限的 AWS 账户
- Amazon CloudFront Distribution 已创建并配置源站
- AWS WAF Web ACL 已关联到 Amazon CloudFront Distribution
- Lambda@Edge 函数需要部署在 us-east-1 区域
5.1.2 网络要求:
- Amazon CloudFront 到源站的网络连通性
- Amazon CloudWatch Logs 到 Amazon Kinesis Data Firehose 的 Subscription Filter 权限
5.2 步骤一:创建 origin-request Lambda@Edge 函数
该函数部署在 origin-request 阶段,负责将 request body 写入自定义 header,以便 origin-response 阶段读取。
创建 Lambda 函数时,需要在 Amazon CloudFront 触发器配置中勾选 Include Body 选项,确保函数可以访问请求体。
关键说明:
- 自定义 header
X-Original-Body仅用于在 Amazon CloudFront 内部的两个 Lambda@Edge 函数之间传递数据 - 该 header 会随请求一起发送到源站,但不会对源站行为产生影响
- body 数据默认以 base64 编码存储,通过
X-Original-Body-Encodingheader 标记编码方式
5.3 步骤二:创建 origin-response Lambda@Edge 函数
该函数部署在 origin-response 阶段,负责检测源站响应状态码。当状态码为 4xx 或 5xx 时,从自定义 header 中读取 body,并将完整请求信息写入 Amazon CloudWatch Logs。
关键说明:
- 日志记录通过
console.log实现,写入 Amazon CloudWatch Logs 为异步操作,不会阻塞响应返回 - 内部传递用的
x-original-body和x-original-body-encodingheader 在日志中被过滤,仅保留原始请求 headers - 日志格式为结构化 JSON,便于后续通过 Amazon Athena 或脚本进行解析
5.4 步骤三:配置 Amazon CloudFront Distribution
在 Amazon CloudFront Distribution 中关联两个 Lambda@Edge 函数:
- 在 Distribution 的 Behavior 配置中,添加 origin-request 触发器,关联步骤一创建的函数,并勾选 Include Body
- 添加 origin-response 触发器,关联步骤二创建的函数
5.5 步骤四:配置日志汇聚管道
为实现日志的统一存储,需要配置从 Amazon CloudWatch Logs 到 Amazon S3 的传输管道:
- 在 Amazon Kinesis Data Firehose 中创建 Delivery Stream,目标设置为 Amazon S3 存储桶
- 在 Lambda@Edge 执行节点可能涉及的每个区域,为对应的 Amazon CloudWatch Logs 日志组创建 Subscription Filter,将日志投递至 Amazon Kinesis Data Firehose
- 对于 AWS WAF 日志,同样配置 Subscription Filter 将其投递至同一个 Amazon S3 存储桶
[图4:完整日志汇聚架构] |
5.6 已知限制
| 限制项 | 说明 |
|---|---|
| 请求总大小 | Lambda@Edge 动态 header 受 20KB 总请求大小限制(含所有 headers + query string) |
| Body 截断 | Amazon CloudFront 对 request body 的截断上限为 40KB |
| Base64 编码膨胀 | base64 编码会将原始数据膨胀约 33%,实际可传递的 body 上限约为 15KB |
| 日志分散 | Lambda@Edge 日志分散在多个区域的 Amazon CloudWatch Logs 中,需要逐一配置汇聚 |
六、成本分析
Lambda@Edge 的计费模式与标准 AWS Lambda 有所不同:请求单价约为标准 Lambda 的 3 倍,且没有免费额度。以下以日均 100 万请求为例,估算该方案的月度成本。
6.1 Lambda@Edge 成本
每个请求触发 2 个 Lambda@Edge 函数(origin-request + origin-response),月均约 6,000 万次执行:
| 计费项 | 单价 | 用量 | 月费用 |
|---|---|---|---|
| 请求费 | $0.60 / 百万次 | 6,000 万次 | $36.00 |
| 执行时长 | $0.00000625125 / 128MB-秒 | 平均 10ms/次 | ~$3.60 |
| Lambda@Edge 小计 | ~$39.60 |
6.2 AWS WAF 成本
| 计费项 | 单价 | 月费用 |
|---|---|---|
| Web ACL | $5.00/月 | $5.00 |
| 规则 | $1.00/规则/月(假设 5 条) | $5.00 |
| 请求检查 | $0.60/百万次 | ~$6.00 |
| WAF 小计 | ~$16.00 |
6.3 日志采集成本
| 计费项 | 月费用 |
|---|---|
| Amazon CloudWatch Logs 写入 | ~$3.00 |
| Amazon Kinesis Data Firehose | ~$2.00 |
| 日志采集小计 | ~$5.00 |
6.4 总成本估算
| 组件 | 月费用 |
|---|---|
| Lambda@Edge | ~$39.60 |
| AWS WAF | ~$16.00 |
| 日志采集 | ~$5.00 |
| 合计 | ~$60.60 |
以上价格基于 AWS 官方定价页面(2026 年 3 月),实际费用可能因区域和使用模式有所不同。建议使用 AWS Pricing Calculator 进行精确估算。
尽管 Lambda@Edge 的单次请求成本高于标准 Lambda,但对于大多数业务场景,月度绝对金额处于可接受范围内。建议在做方案决策时,以实际业务量进行成本估算,而非仅关注单价差异。
七、常见问题
Q:该方案是否会增加请求延迟?
A:origin-request 阶段的 Lambda@Edge 仅执行 header 写入操作,执行时间通常在 1-2ms。origin-response 阶段的日志记录通过 console.log 异步写入 Amazon CloudWatch Logs,不会阻塞响应返回。整体对请求延迟的影响可忽略不计。
Q:自定义 header X-Original-Body 是否会被源站接收?
A:是的,该 header 会随请求一起转发到源站。如果源站对未知 header 不做处理(大多数情况如此),则不会产生影响。如果源站对 header 有严格校验,可以在源站侧配置忽略该 header。
Q:如何处理超过 20KB 限制的大型请求体?
A:对于超过限制的请求体,建议采用截断策略:在 origin-request Lambda@Edge 中仅存储 body 的前 N 个字节,并在日志中标记截断状态。对于大多数 API 请求场景,15KB 的 body 容量已能覆盖绝大部分业务需求。
Q:Lambda@Edge 日志分散在多个区域,如何统一查看?
A:建议在每个可能有用户访问的区域配置 Amazon CloudWatch Logs Subscription Filter,将日志统一投递到一个中心化的 Amazon S3 存储桶。也可以使用 Amazon CloudWatch Logs 的跨账户、跨区域日志聚合功能。
Q:该方案能否记录被 AWS WAF 拦截的请求?
A:被 AWS WAF 拦截的请求不会到达 Lambda@Edge 阶段。AWS WAF 有独立的日志记录机制,可以将拦截日志写入 Amazon CloudWatch Logs(包含 headers 和 body 前 8KB)。本方案通过配置两条独立的日志采集路径,分别处理 WAF 拦截请求和源站错误请求,最终统一汇聚到 Amazon S3。

[图5:Lambda@Edge 关键限制速查表] |
八、总结
本文介绍了一种基于 Amazon CloudFront 和 Lambda@Edge 的失败请求完整记录方案。通过双 Lambda@Edge 函数架构,在不修改源站代码的前提下,实现了对失败请求的完整 headers 和 body 记录,支持后续的异步数据补偿和请求重放。
该方案的核心价值:
| 维度 | 效果 |
|---|---|
| 零侵入 | 无需修改源站代码,完全在 Amazon CloudFront 边缘层实现 |
| 信息完整 | 单条日志包含完整的 status code、headers 和 body |
| 成本可控 | 日均百万请求场景下,月度成本约 $60 |
| 架构简洁 | 两个 Lambda@Edge 函数 + 标准日志管道,易于维护 |
适用场景:源站部署在非 AWS 环境且无法修改代码、需要记录完整请求信息用于数据补偿、需要同时覆盖 AWS WAF 拦截和源站错误两类失败场景。
➡️ 下一步行动:
相关产品:
- AWS Lambda — 无需服务器即可运行代码
- Amazon CloudFront — 全球内容分发网络
- Amazon CloudWatch — 可观测性工具
- Amazon WAF — Web 应用程序防火墙
- Amazon Kinesis — 实时流数据处理
相关文章:
- CloudFront 部署小指南(二十三)- 全新网站分发与安全防护固定月费套餐(Flat-rate)介绍与配置指导
- Amazon CloudWatch 推出面向运营、安全和合规的统一数据管理与分析功能
- Aurora 慢查询与无索引慢查询监控方案
- 从智能工厂到车联网:S3 Tables 双模式写入实战指南
- 在亚马逊云科技中国区域利用 S3 Object Lambda 轻松实现自定义图片缩放
九、参考资源
- AWS Lambda Pricing — Lambda@Edge 定价在页面底部 “Lambda@Edge Pricing” 部分
- AWS WAF Pricing — Web ACL、规则、请求检查定价
- Work with requests and responses (Lambda@Edge) — Include Body 选项说明及 origin-response 的限制
- CloudFront Quotas — Lambda@Edge 限制、Custom Header 限制、请求总大小限制
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
