亚马逊AWS官方博客
利用机器学习和 BI 服务构建社交媒体控制面板
在这篇博文中,我们将展示如何利用 Amazon Translate、Amazon Comprehend、Amazon Kinesis、Amazon Athena 和 Amazon QuickSight 构建受自然语言处理 (NLP) 支持的社交媒体控制面板,以便处理推文。
组织与客户之间的社交媒体交互可以深化品牌认知度。这些交流是发掘销售线索、增加网站流量、发展客户关系并改进客户服务的低成本方法。
在这篇博文中,我们将构建无服务器数据处理和机器学习 (ML) 管道,在 Amazon QuickSight 中提供处理推文的多语言社交媒体控制面板。我们将利用 API 驱动的 ML 服务,来让开发人员只需调用高度可用、可扩展、安全的终端节点,便可轻松向任何应用程序添加智能功能,例如计算机视觉、语音、语言分析和聊天自动程序功能。借助 AWS 内的无服务器产品,这些构建块只需极少的代码便可整合在一起。在这篇博文中,我们将对流经系统的推文执行语言翻译和自然语言处理。
除了构建社交媒体控制面板之外,我们还希望捕获原始数据集和充实后的数据集,并将其长期存储在数据湖中。这将允许数据分析师快速轻松地对此数据执行新型分析和机器学习。

在这篇博文中,我们将展示如何实现以下操作:
- 利用 Amazon Kinesis Data Firehose 轻松捕获和准备实时数据流,并将其加载到数据存储、数据仓库和数据湖中。在本例中,我们使用的是 Amazon S3。
- 触发 AWS Lambda 以使用 Amazon Translate 和 Amazon Comprehend (来自 AWS 的两种完全托管式服务) 分析推文。仅需几行代码,我们就能利用这些服务将推文翻译为不同语言,并对推文执行自然语言处理 (NLP)。
- 在 Amazon Kinesis Data Firehose 内利用独立的 Kinesis 数据传送流,将经过分析的数据写回数据湖。
- 利用 Amazon Athena,查询 Amazon S3 中存储的数据。
- 使用 Amazon QuickSight 构建一组控制面板。
下图展示了提取 (蓝色) 和查询 (橙色) 流。

注意:在本博文发文之际,Amazon Translate 仍为预览版。在生产工作负载中,在 Amazon Translate 公开发布 (GA) 之前,应使用 Amazon Comprehend 的多语言功能。
自行构建此架构
我们为您提供了 AWS CloudFormation 模板,可用于创建前文示意图中除 AWS Lambda 的 Amazon S3 通知之外 (以蓝色虚线表示) 的所有提取组件。
在 AWS 管理控制台中,启动 CloudFormation 模板。
![]()
这会自动将 CloudFormation 堆栈启动至具有如下设置的 us-east-1 区域:
| 输入 | 值 |
| 区域 | us-east-1 |
| CFN 模板: | https://s3.amazonaws.com/serverless-analytics/SocialMediaAnalytics-blog/deploy.yaml |
| 堆栈名称: | SocialMediaAnalyticsBlogPost |
指定以下必需参数:
| 参数 | 描述 |
| InstanceKeyName | 用于连接到 Twitter 流实例的密钥对 |
| TwitterAuthAccessToken | Twitter 账户访问令牌 |
| TwitterAuthAccessTokenSecret | Twitter 账户访问令牌密码 |
| TwitterConsumerKey | Twitter 账户使用方密钥 (API 密钥) |
| TwitterConsumerKeySecret | Twitter 账户使用方密码 (API 密码) |
您需要在 Twitter 上创建一个应用:创建一个使用方密钥 (API 密钥)、使用方密码密钥 (API 密码)、访问令牌以及访问令牌密码,并将其用作 CloudFormation 堆栈中的参数。您可以通过此链接进行创建。
此外,您还可以修改要从 Twitter 流 API 提取哪些条件和语言。此 Lambda 实施会为每条推文调用 Comprehend。如果您要将条件修改为每秒检索上千篇推文,可考虑执行批量调用,或者利用 AWS Glue 及触发器来执行批处理,而非流式处理。
注意:在本博文发文之际,Amazon Translate 为预览版。如果您无法访问 Amazon Translate,只需添加 en (英语) 值即可。

注意:本博客中的代码假设 Twitter 所用语言代码与 Amazon Translate 和 Comprehend 所用语言代码相同。此代码可轻松扩展,但如果您要添加新标签,请确认此假设是正确的。(除非您同时更新 AWS Lambda 代码。)
在 CloudFormation 控制台中,您可以选中允许 AWS CloudFormation 使用自定义名称创建 IAM 资源对应的复选框,加以确认。CloudFormation 模板使用无服务器转换。选择“创建更改集”,检查这些转换添加的资源,然后选择“执行”。
启动 CloudFormation 堆栈并等待其启动完成。

启动完成后,您将看到一组输出,我们将在本博文中使用这组输出:

设置 S3 通知 – 从新推文调用 Amazon Translate/Comprehend:
在 CloudFormation 堆栈启动完成后,转到“输出”选项卡,查看直接链接和信息。然后单击 LambdaFunctionConsoleURL 链接,直接进入 Lambda 函数页面。
Lambda 函数会调用 Amazon Translate 和 Amazon Comprehend,对推文执行语言翻译和自然语言处理 (NLP)。该函数使用 Amazon Kinesis 将经过分析的数据写入 Amazon S3。

CloudFormation 堆栈已经完成了大多数设置,但您需要添加 S3 通知,以便在新推文写入 S3 时调用 Lambda 函数:
- 在“Add Triggers”(添加触发器) 下,选择 S3 触发器。
- 然后通过 CloudFormation 使用“raw/”前缀创建的新 S3 存储桶配置触发器。事件类型应为“对象已创建 (全部)”。
根据最小特权模式,Lambda 函数已分配的 IAM 角色仅可访问 CloudFormation 模板创建的 S3 存储桶。
下图显示了一个示例:

抽出片刻时间,查看代码的其余部分。仅需几行代码,我们就能调用 Amazon Translate,在阿拉伯语、葡萄牙语、西班牙语、法语、德语、英语和其他多种语言之间进行转换。
使用 Amazon Comprehend 在应用程序中添加自然语言处理也是同样简单。请注意,在 Lambda 函数内,我们可以非常轻松地对推文执行情绪分析和实体提取。
启动 Twitter 流生成器
本示例中使用的唯一服务器在 Kinesis Data Firehose 中的实际提取流外。它用于从 Twitter 收集推文,并将这些推文推送到 Kinesis Data Firehose 中。在以后的博文中,我们将展示如何调整此组件,使之也成为无服务器组件。
利用 SSH 连接到 CloudFormation 堆栈创建的 Amazon Linux EC2 实例。
CloudFormation 堆栈的部分输出包含 SSH 式命令,可在多个系统上用于连接到实例。
注意:如需详细了解如何从 Windows 或 Mac/Linux 机器建立连接,请参阅 Amazon EC2 文档。
运行以下命令:
会启动推文流:如果您希望流继续运行,只需以后台任务的形式运行它即可。为了执行简单的测试,您还可以使 SSH 隧道保持打开状态。
几分钟后,您应能够在 CloudFormation 模板创建的 S3 存储桶内看到各种数据集:

注意 (如果您未看到全部三个前缀):如您未看到任何数据,请检查以确保 Twitter 读取器能正确读取,并且未产生错误。如果您只看到 raw 前缀,而未看到其他内容,请检查以确保已经在 Lambda 函数上设置了 S3 触发器。
创建 Athena 表
我们将手动创建 Amazon Athena 表。这是在您的数据湖架构内利用 AWS Glue 爬网功能的大好机会。爬网程序会自动发现 Amazon S3 上驻留的不同数据集 (以及关系型数据库和数据仓库) 的数据格式和数据类型。更多详细信息,请参阅爬网程序与 AWS Glue 文档。
在 Athena 中,运行以下命令,创建 Athena 数据库和表:
这将在 Athena 中创建一个新的数据库。
运行下一条语句。
重要说明:将 <TwitterRawLocation> 替换成显示为 CloudFormation 脚本输出的内容:
这将创建推文表。接下来,我们执行同样的操作,来创建实体和情绪表。务必使用 CloudFormation 输出中所列的实际路径更新这两项内容。
首先,运行以下命令,替换下例中突出显示的路径,以创建实体表:
现在,运行以下命令来创建情绪表:
运行这四条语句,并替换表创建语句的位置后,您应能够在下拉列表中选择 socialanalyticsblog 数据库,并能看到三个表:

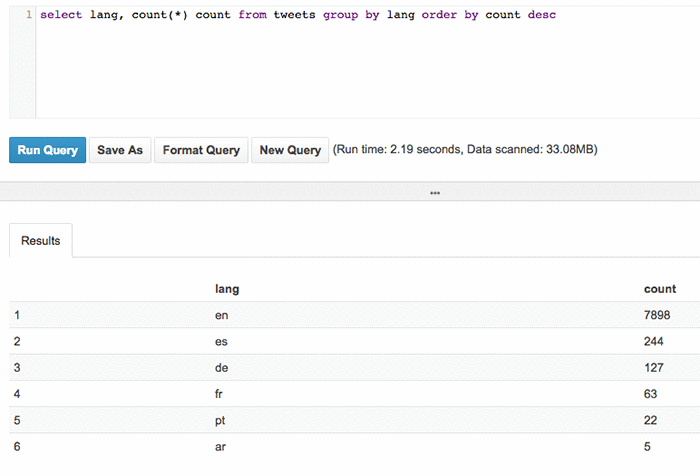
可以运行查询来调查您所收集的数据。我们首先来看看表本身。
可以查看包含 20 条推文示例:
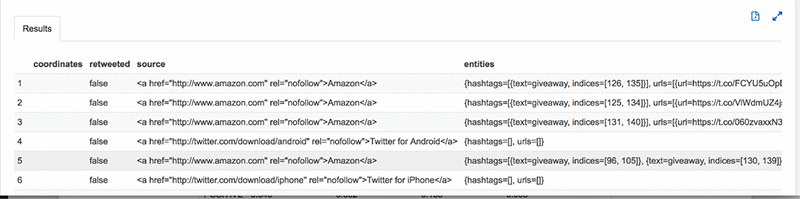
提取主要实体类型:

现在,我们可以提取排名前 20 的商业内容:

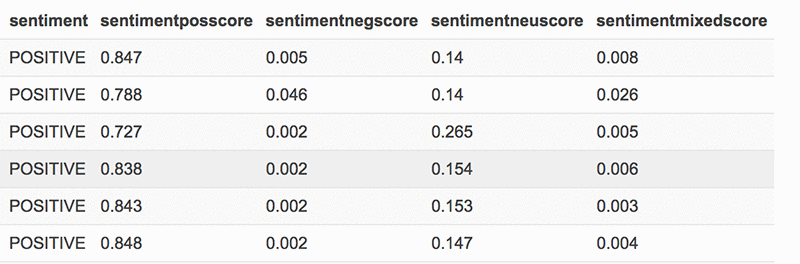
现在,我们来提取 20 条积极向上的推文,查看其情绪分析分数:
您还可以开始查询翻译详细信息。即便不知道“鞋子”这个词的德语翻译,我也能轻而易举地执行以下查询:
结果将以翻译后的文本为依据,显示一条谈论鞋子的推文:

我们还可以查看通过 NLP 提取 Kindle 的非英语推文:
注意:从技术角度来说,如果在 Athena 中选择了数据库,则您不必使用完全限定的表名称,但我还是使用了完全限定表名称,以避免有人未首先选择 socialanalyticsblog 数据库而导致出现问题。
构建 QuickSight 控制面板
- 启动 QuickSight – https://us-east-1.quicksight.aws.amazon.com/sn/start。
- 从右上角选择“Manage data”(管理数据)。
- 选择“New Data Set”(新建数据集)。
- 创建一个新的 Athena 数据源。
- 选择 socialanalyticsblog 数据库和 tweet_sentiments 表。
- 然后选择“Edit/Preview Data”(编辑/预览数据)。

- 在“表”下方,选择“Switch to custom SQL tool”(切换到自定义 SQL 工具):

- 为查询命名 (例如“SocialAnalyticsBlogQuery”)
- 输入此查询:
- 然后选择“完成”。
- 这会保存查询,并为您显示示例数据。
- 切换数据类型,将 timestamp_in_seconds 改为日期:

- 随后选择“Save and Visualize”(保存并查看)。
现在,您就可以轻松开始构建某些控制面板了。
注意:使用我创建自定义查询的方法时,您不妨将不同的 tweetid 视为值。
我们将逐步指导您创建控制面板。
- 首先在显示区的左上象限中设置第一项可视化效果。

- 选择类型,从字段列表中选择 tweetid。
- 选择“Field Well”(字段井) 旁边的双下拉箭头。

- 将 tweetid 移到“值”处。
- 然后选择它并执行“非重复值计数”:

- 现在,在可视化类型下切换到饼图。

接下来,我们添加另一项可视化效果。
- 选择“添加”(页面左上角附近):“Add Visual”(添加可视化效果)。
- 调整其大小,将其移动到您的第一个饼图旁边。

- 现在选择情绪、timestamp_in_seconds。
- 在字段井或图表本身下方,可以放大/缩小时间。我们来放大到小时:

- 假设在时间线上,我们仅想查看正面/负面/混合情绪。中立线会导致其他情绪不易查看 – 至少对于我的 Twitter 来说是如此。

- 只需单击中立线,在随即显示的框中,选择“Exclude Neutral”(排除中立) 即可。


下面我们来逐步为此分析再添加一项可视化效果,以显示翻译后的推文:
- 在“添加”下,选择“Add Visual”(添加可视化效果)。
- 重新调整其大小,使之占据显示空间的下半部分。
- 选择“Table View”(表视图)。

- 选择:
- language
- text
- originalText
- 然后在左侧选择“筛选条件“。

- 创建一个:language。
- 随后选择“Custom filter”(自定义筛选条件),再选择“Does not equal”(不等于),输入值“en”。

注意:您可能需要在表视图中,根据屏幕分辨率调整列宽,以保证看到最后一列。
现在,您可以为实体、不同时间的情绪和翻译后的推文调整大小并查看这些内容。

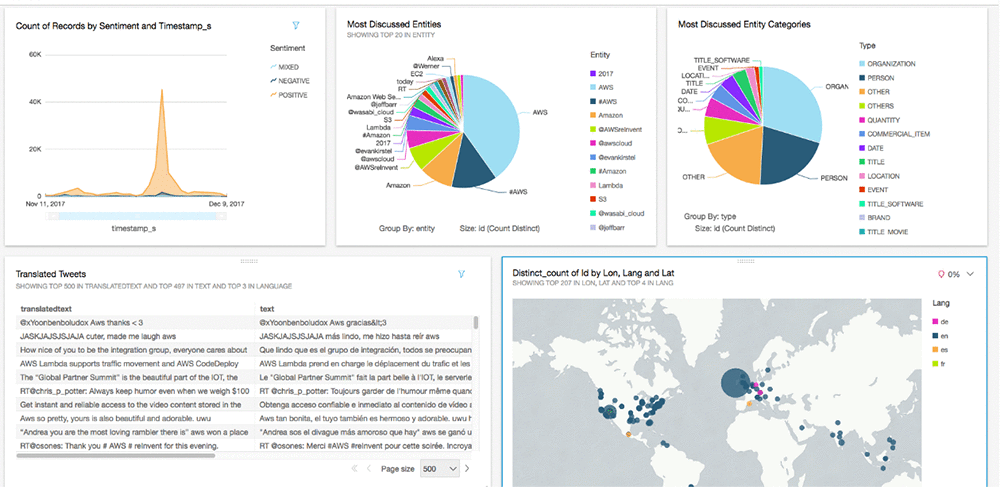
您可以构建多个控制面板、对其进行缩放,并以不同的方式查看数据。例如,下面是情绪的地理空间图表:
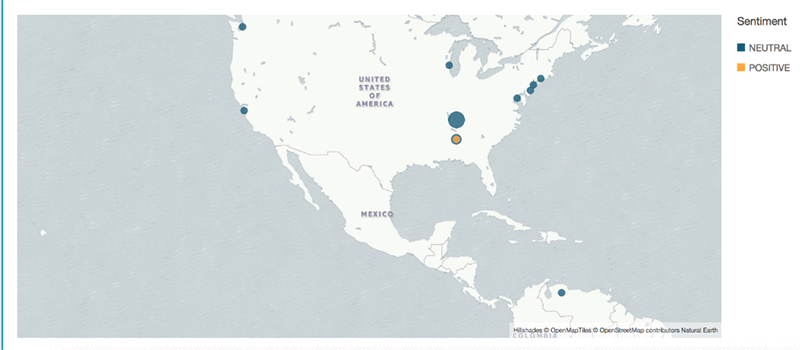
您可以进一步扩展此控制面板,构建如下方所示的分析:

关闭
创建这些资源之后,可以通过以下步骤删除它们。
- 停止 Twitter 流读取器 (如果仍在运行)。
- 按 CTRL-C 或者将其强制终止 (如果它在后台运行)。
- 删除 CloudFormation 模板创建的 S3 存储桶。
- 删除 Athena 表数据库 (socialanalyticsblog)。
- 丢弃表 socialanalyticsblog.tweets。
- 丢弃表 socialanalyticsblog.tweet_entities。
- 丢弃表 socialanayticsblog.tweet_sentiments。
- 丢弃数据库 socialanalyticsblog。
- 删除 CloudFormation 堆栈 (在删除堆栈之前,确保 S3 存储桶为空)。
结论
实体处理、分析和机器学习管道始于 Amazon Kinesis,利用 Amazon Translate 分析数据以便将推文翻译为不同语言,使用 Amazon Comprehend 执行情绪分析,并通过 QuickSight 在无需涉及任何服务器的情况下创建控制面板。
我们通过 AWS Lambda 内的一些简单调用为流添加了高级机器学习 (ML) 服务,还通过 Amazon QuickSight 构建了多语言分析控制面板。我们还将所有数据保存到了 Amazon S3 中,如果愿意,我们还可以利用 Amazon EMR、Amazon SageMaker、Amazon Elasticsearch Service 或其他 AWS 服务对这些数据执行其他分析。
您不必运行 Amazon EC2 实例去读取 Twitter Firehose,而可以利用 AWS Fargate 将该代码部署为容器。AWS Fargate 是适用于 Amazon Elastic Container Service (ECS) 和 Amazon Elastic Container Service for Kubernetes (EKS) 的一项技术,允许您在无需管理服务器或集群的情况下运行容器。使用 AWS Fargate,您不必再预置、配置和扩展虚拟机集群即可运行容器。这样一来,您就无需再选择服务器类型、确定扩展集群的时间和优化集群打包。AWS Fargate 让您省去了考虑服务器和集群以及与之交互的麻烦。使用 AWS Fargate,您可以专注于设计和构建应用程序,而不是管理运行应用程序的基础设施。
作者简介
 Ben Snively 是一位公共部门专业解决方案架构师。他与政府机构、非营利组织和教育业客户合作开展大数据与分析项目,帮助客户利用 AWS 构建解决方案。在闲暇时间,他喜欢为家中的各种物品加装 IoT 传感器并运行分析。
Ben Snively 是一位公共部门专业解决方案架构师。他与政府机构、非营利组织和教育业客户合作开展大数据与分析项目,帮助客户利用 AWS 构建解决方案。在闲暇时间,他喜欢为家中的各种物品加装 IoT 传感器并运行分析。
 Viral Desai 是一位 AWS 解决方案架构师。他提供架构指导,帮助客户在云领域取得成功。在闲暇时间,Viral 喜欢打网球以及与家人共度美好时光。
Viral Desai 是一位 AWS 解决方案架构师。他提供架构指导,帮助客户在云领域取得成功。在闲暇时间,Viral 喜欢打网球以及与家人共度美好时光。