亚马逊AWS官方博客
利用 AWS Serverless 构建现代化的自动驾驶数据注入管理平台
前言
Serverless (无服务器) 是一种用于描述服务、实践和策略的方式, 开发人员可以使用 Serverless 构建更敏捷的应用程序,从而能够更快地创新和响应变化。通过 Serverless, 开发人员可以将容量预置和补丁等基础设施管理任务交由 AWS 来处理,从而专注于编写为客户服务的代码。现代应用程序在“Serverless First (即无服务器优先)”的基础上进行构建,而 AWS 在计算、应用程序集成和数据存储等方面均提供了丰富的服务帮助开发人员快速构建现代化的应用。
本博客以自动驾驶初创公司文远知行WeRide为例,介绍文远知行是如何利用Lambda, API Gateway, S3 和 Fargate 等Serverless相关服务,实现对自动驾驶数据注入管理平台的应用现代化改造。
自动驾驶数据注入管理平台介绍
文远知行,像所有的自动驾驶公司一样,需要不断地从现场道路测试中收集数据用于模型训练、算法测试和模拟仿真。随着更多的车辆投入运营和测试,数据采集量不断增加。在2020年,文远知行的自动驾驶车队每天产生TB级别的数据。同时,文远知行在多地开展自动驾驶技术的研发和车队运营,数据需要跨区域进行采集,并进行管理。
自动驾驶的研发是以数据为中心的。文远知行在2019年开始便在AWS中国区域内利用 Amazon S3 构建了自动驾驶数据湖,测试车辆通过各类传感器采集了测试数据后经过多种方式注入云端的数据湖,并进行数据处理、标注、模型训练和仿真等等一系列的步骤,将训练好的模型重新部署到车端,再到路面进行测试,由此完成一个闭环。在这个博客里,我们主要关注“数据采集与注入”这个环节。
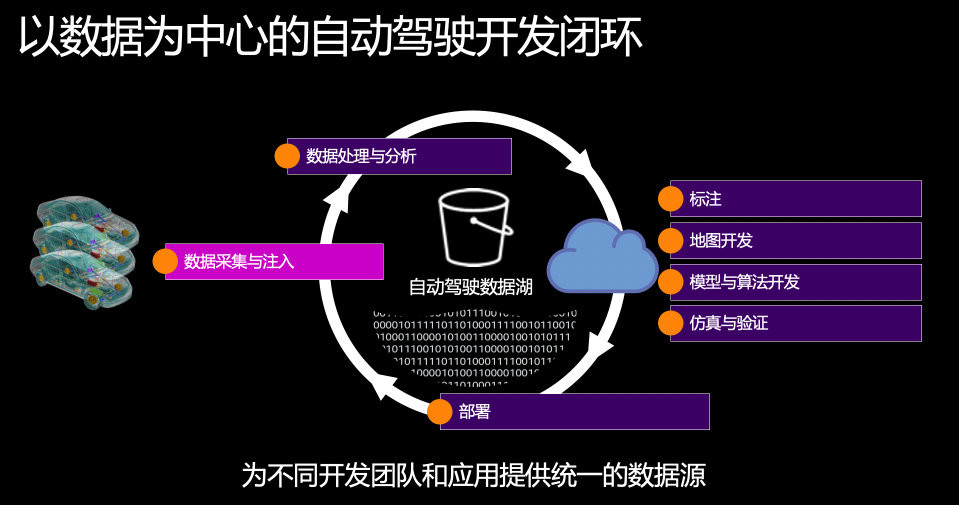
随着文远知行与车企的合作不断深入,自动驾驶车队规模迅速扩大,测试数据上传与任务管理变得更为复杂,旧有的数据注入平台已经无法满足需求。2020年下半年,我们开始尝试利用AWS Serverless 技术进行应用现代化发行,以构建一个低成本、免运维和高安全性的数据注入管理服务。
数据注入服务工作流程
在这里我们先简要描述一下数据注入服务的基本工作流程:

数据上传服务
如上图示,各地的自动驾驶车辆在每天的运行过程中,会自动采集数据,记录到随车部署的服务器上。收车后,车载服务器上的移动硬盘插到车库的一台服务器上(我们称之为 Uploader )。Uploader 会自动对移动硬盘内的数据进行分析,将研发人员关注的Labeling,Incidents和Logs等数据自动上传至AWS云端存储S3。另外部分数据也会同时上传到本地机房的存储集群供后续处理。
车库里的显示屏会实时显示Uploader的数据上传状态,如下图示:

同时管理员也能实时查看Uploader的健康状态、下发上传或计算任务以及任务运行状态。
基于 Serverless 的整体架构设计
我们利用了 AWS Serverless 服务,包括 API Gateway 、 Lambda 和等服务,在不到一周的时间内就重构了数据注入服务(Uploader)的相关后台API。开发工程师只需要关注业务逻辑和相关的代码实现即可,并不需要关注底层的服务器维护等基础架构的运维细节,大大减轻了开发和运维的压力,如下是整体架构图:

整体架构
接下来我们可以对上述架构图中涉及到的关键流程和组件分别进行介绍:
数据上传、解密与索引创建
该部分流程及组件如下图高亮所示:
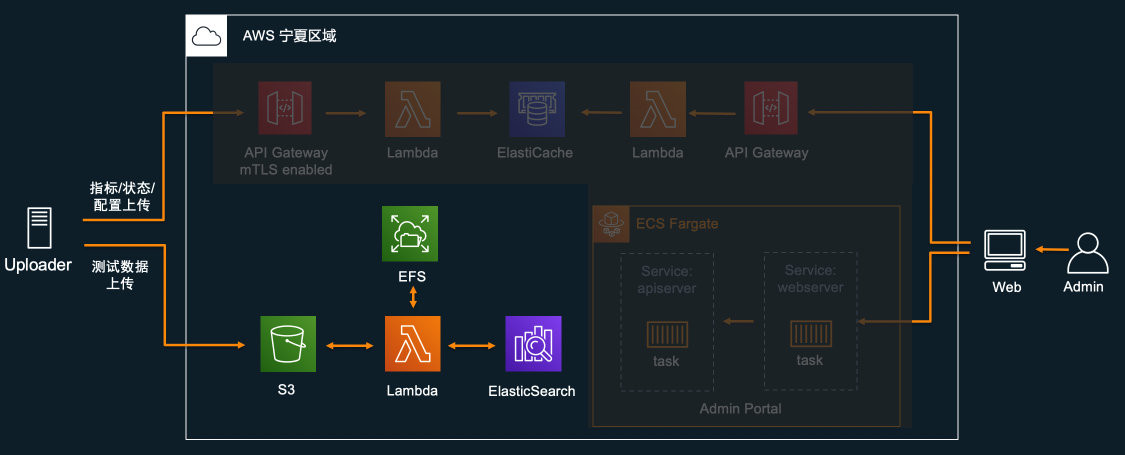
在Uploader上,通过 Boto3 提供的 S3 api,将数据上传到 S3 存储桶。因为数据上传前进行了加密,因此在云端进行处理时,需要先进行解密。加密数据在写入S3存储桶后,会通过S3的事件通知机制(S3 Event Notification)自动触发Lambda进行数据解密操作,解密后的数据会重新写入S3中进行保存。
尽管Lambda提供了512MB的存储空间,但对于测试数据解密这个场景来说,这个容量还是太小了。因此我们为Lambda挂载了Amazon Elastic File System (EFS) ,作为数据解密操作所需要的存储空间。Lambda配置EFS 很简单,可以使用 AWS Console 、CLI、AWS SDK 或是 AWS无服务器应用程序模型(AWS SAM)来进行部署和配置。因为EFS是在部署在VPC内,因此Lambda也需要运行在VPC中。关于 Lambda 挂载 EFS 的更详细介绍,可以参考这个博客
数据进行解密并存入S3后,我们会对这些数据编制索引,比如这些测试数据具体是在什么样的场景下获取的,以便后续工程师可以根据索引在数据湖中快速找到模型训练所需要的特定场景的数据。这个索引我们会使用 ElasticSearch 来进行维护。 这里我们使用了 AWS 托管的 ElasticSearch 服务。在Lambda中我们直接使用 Elasticsearch 的 Python SDK 提供的API 将数据的相关标签写入索引中。
Uploader 云端 API 网关
该部分流程及组件如下图高亮所示:

除了数据上传,Uploader 机器还需要定期上报机器状态、数据状态、收取配置信息,任务信息等信息。因此需要在云端为分布在全国多个地方的 Uploader 提供一系列的 API 进行调用。在这里我们使用了 Amazon API Gateway 来做为 API 网关,对外提供 API 。相比最早发布的 REST API, 2019年发布的 HTTP API 提供了更好的响应时间和更低的成本,因此我们在这里使用了 HTTP API 来构建云端的 API 。关于HTTP API的基本设计逻辑在这里就不再展开赘述,但我们可以着重介绍下认证的设计。
通过双向认证(mTLS)保护云端 API
由于 Uploader 是通过互联网来访问云端的 API, 那我们要如何保护这个云端的API,确保只能由 Uploader 来进行访问?传统的Web API 通过移动端或是浏览器端进行访问,我们可以要求用户先进行登录,认证通过后再访问后台的API。但在 Uploader 这个场景,我们没有办法让 Uploader 来进行登录。考虑到 Uploader 实际上是一台设备,因此我们可以借鉴IoT的认证机制,即使用证书的方式来对设备进行认证。正好 API Gateway 在2020年下半年的时候发布了 mutual TLS 认证的功能,这个功能可以让我们很方便地进行客户端和服务器端的双向认证,而之前我们只能做单向认证,也就是让API的客户端通过校验公钥来确认API服务端的身份。
通过在API Gateway启用自定义域名,并给Uploader颁发证书,我们可以快速实现双向的TLS认证,即mTLS,只有拥有合法证书的Uploader才能向云端API发起请求并被认证通过。这样我们就能有效地保护 API 即使暴露在公网,也不会被非法请求。关于mTLS更详细的介绍和配置方法,可以参考这个博客。
后台管理服务
该部分流程及组件如下图高亮所示:
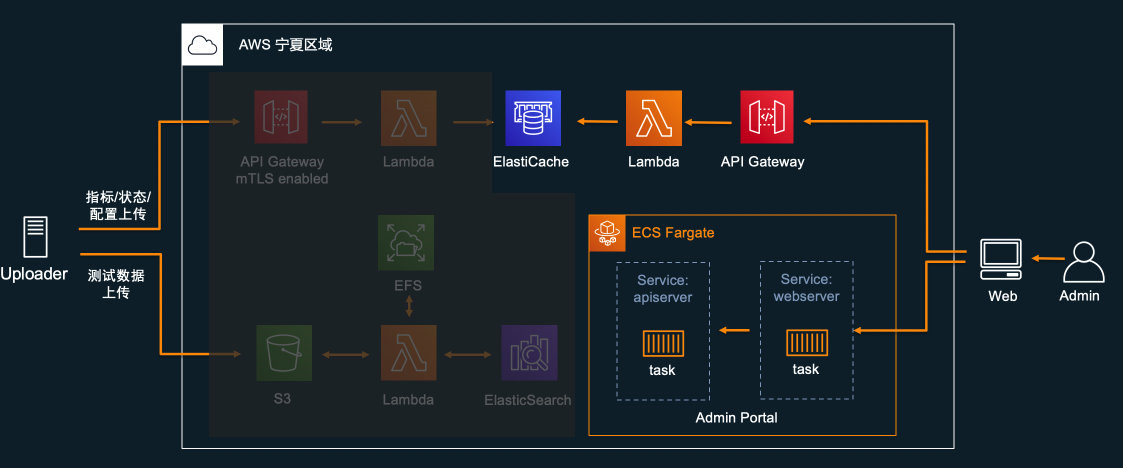
Uploader的后台管理服务是一个前后端分离的 Web 平台,使用Django编写,有前端 webserver 和后端 apiserver,最开始设计时都是以 container 的形式运行在自己搭建的 Kubernetes 集群里面。用户通过 ELB 访问 webserver 前端服务,而 webserver 则通过 K8S service 访问 apiserver。
对于后台管理服务,我们暂时不想花时间去进行Serverless改造以适配 API Gateway+Lambda ,因此我们研究了AWS在容器方面的解决方案,并最终选择了ECS + Fargate 来部署我们的后台管理服务。主要的考虑是可以通过ECS直接运行原有的容器而无须做应用改造,同时使用Fargate可以省去我们对底层EC2的管理,进而节省运维工作量。
Amazon Elastic Container Service (Amazon ECS) 是一项高度可扩展的快速容器管理服务,可以轻松地运行、停止和管理容器。通过在 AWS Fargate 上启动服务或任务,将容器托管在由 Amazon ECS 管理的无服务器基础设施上,开发人员可以专注于设计和构建应用程序,而不必管理运行它们的基础设施。
同时,在这个平台部署中,我们也探索一种更经济高效的容器运行方式,Fargate Spot 是一个新的购买选项,允许很大的折扣以可用容量启动容器任务,竞价任务的价格(每 CPU 小时和 GB 小时)是可变的,比按需任务的价格低50%至70%。Fargate Spot 的运行原理与 Amazon EC2 竞价型实例相同,当 Fargate Spot 的容量可用时,部署的容器任务将运行。由于这些任务以剩余容量运行,因此当 AWS 需要回收容量时,任务会在两分钟内收到中断通知,就像 EC2 Spot 实例一样。
具体迁移改造过程如下:
- 创建ECS集群,该集群会同时运行 webserver 和 apiserver 的服务,同时对该集群指定 capacity provider 为 Fargate 和 Fargate Spot 在以下示例中,指定了两个容量提供程序 FARGATE 和 FARGATE_SPOT。
- 创建 ECS apiserver 服务并运行,这里我们指定运行4个任务数,其中有2个是按需容量计费,2个是按照Spot容量计费,使用者可以根据工作负载灵活地分配容量的运行基本数量和提供策略权重。
那具体是如何来确定多少任务跑在Fargate, 多少任务跑在Fargate Spot呢?可以通过capacity provider策略来确定。这个策略包含一个或多个capacity provider,可以指定可选的基准和权重值,以便更好地控制容量提供程序。基准值指明在指定的capacity provider上至少运行多少个任务。权重值指明应使用指定capacity provider的已启动任务总数的相对百分比。例如,如果策略包含两个capacity provider,并且两个capacity provider的权重均为 `1`,那么当满足基准时,这些任务将在两个capacity provider之间均匀分配。按照相同的逻辑,如果为 *capacityProviderA* 指定权重 `1`,并为 *capacityProviderB* 指定权重 `4`,那么运行的每一个任务均使用 *capacityProviderA*,四个任务将使用 *capacityProviderB*。
- 创建内网 ALB 关联到 ECS apiserver 服务的目标组,需要注意的是注册到目标组的服务需要设置运行状况检查,如果检查失败的话则认为服务是不健康的状态导致不断关闭并创建新的 FARGATE 任务。apiserver 可以提供一个可以检测的 URL path,例如 /api/helath,健康的情况返回 HTTP 200。控制台终端可以观察服务健康状态,可以用在同一个 VPC 内的 EC2 机器测试 apiserver 服务。
- 创建 ECS
- 创建公网 ALB 关联到 ECS webserver 服务的目标组,同样需要注意的是注册到目标组的服务需要设置运行状况检查。这里选择内网还是公网具体看业务场景的需求,如果设置为公网访问,那么需要考虑一下如何设置安全组策略。此时我们通过 ALB 的 CNAME 地址进行完整的平台功能测试。
- 所有功能和性能测试都验证没有问题的话,可以把正式的域名切换成上面公网 ALB 的 CNAME 地址,至此完成整个迁移改造流程。
Fargate 和 Fargate Spot 结合起来用,非常适合可并行处理的工作负载和要求高可用性的网站和 API 。在 Fargate Spot 上运行的应用程序应具有容错能力,同时通过捕获 SIGTERM 信号来优雅地处理中断。
运行效果
我们使用了不到一周的时间就完成了整个服务的重构。随后经过一段时间测试,我们投入生产进行使用。目前我们有数十个Uploader部署在全国各地,通过互联网或专线将测试数据源源不断地上传至S3,同时我们通过统一的后台服务可以查看到全国各个 Uploader 的运行状态。
这里以Lambda为例,上线后我们从 AWS 控制台查看了 Lambda 的运行情况:

可以看看每天的 Invocations 并不均衡。正因为使用了 Serverless 技术,我们不再需要去担心高峰时间段服务器压力问题,也不需要去费时费力地进行弹性伸缩的设计,这些 Lambda 都帮我们做好了。
小结
Serverless 的出现和完善,让软件开发变得更加友好,极大的解放了工程师的生产力,提高开发效率,减少维护工作量。通过减少闲置资源的浪费,帮助用户降低了成本。对于初创公司来说,无需投入资源和精力在底层服务器、网络等基础架运维,能更加聚焦在业务实现上,同时又能缩短业务上线时间,帮助企业更快实现业务创新。 Serverless 对开发运维虽然带来了特别多的优势,但对工程师开发流程会带了一些转变,由于平台屏蔽了很多技术细节,这让工程师 debug 或测试带来一些不便,所幸 AWS 的文档都特别详细,support 也特别及时,期望 AWS 服务越来越好用,debug 和 测试工具越来越完善,用户体验越来越好。在这里也顺带提一下,文远知行目前正在大规模招人中,欢迎加入我们,一起以无人驾驶改变人类出行!