亚马逊AWS官方博客
基于AWS和西门子工业边缘的云边协同方案
解决方案概述
什么是边缘计算?
边缘计算,是指在靠近物或数据源头的一侧,采用网络、计算、存储、应用核心能力为一体的开放平台,就近提供最近端服务。其应用程序在边缘侧发起,产生更快的网络服务响应,满足行业在实时业务、应用智能、安全与隐私保护等方面的基本需求。
边缘计算技术在工业场景的应用,成为了工厂数字化转型的必经之路。
在工业场景中,边缘是最靠近现场数据源的层级,将数据进行采集和处理,并在本地进行运算和反馈。边缘计算可以将诸如预测性维护、质量检测等任务下沉到工业现场层,从而使工业控制领域得到进一步延伸和拓展。
为什么客户需要考虑工业边缘与云端的结合?
近年来,随着工厂数字化、智能化程度的提高,工业界越来越关注生产数据的价值,同时智能化生产也成为许多工业客户的切身诉求。而IT技术的迅猛发展也为实现上述目标提供了无限可能。将IT技术与OT技术相融合,促进工厂数字化、智能化程度的进一步提升,已然成为业界发展的趋势。
在数字化转型过程中,工业现场往往面临以下挑战:
- 将AI/ML等先进技术与传统工控设备结合有一定难度。
- 工业现场数据来源广,数据量大,且实时性、安全性要求高。
- 用户希望在应用IOT、数据分析及ML的中新技术时,使用管理复杂度低但灵活度高的解决方案。
为解决上述问题,工业客户不约而同地期待能够在生产设备端部署一套具备数据采集与处理能力,拥有足够计算能力,能够即插即用的解决方案。而近年来蓬勃发展的边缘计算技术,恰好满足了这一需求。
西门子工业边缘是什么?
西门子工业边缘是一种边缘解决方案,该方案可以帮助您充分挖掘机器和工厂数据的潜力,结合云端的能力生成新的业务模式从而提高您的竞争优势。
AWS与西门子工业边缘的云边协同方案优势是什么?
充分利用AWS的数据分析和ML服务
虽然边缘计算具有低延迟和数据本地化的优势,但本地计算和存储资源有限,无法支持数据分析和 AI/ML(有/无 GPU)等复杂计算场景,AWS可以解决这个问题。 AWS可以提供各种云原生的分析/ML 服务,如 Amazon SageMaker、Amazon Glue、Amazon EMR等,充分发挥云端资源扩展的力量。

在AWS云端构建功能强大的数据湖
本地设备或传感器每秒都会产生大量数据,但是边缘的存储容量有限,并且没有专业的工具来管理数据。 利用 AWS云存储服务(如 Amazon S3),客户可以高效构建集中且安全的数据湖。
分布式、敏捷以及低管理复杂度
使用 Industrial Edge 进行本地数据处理,同时可以通过Amazon IOT Core、Amazon IOT SiteWise等服务将数据快速上云并提供看板展示。针对ML场景,您可以轻松实现云端训练和边缘推理的最佳实践。边缘设备和应用程序通过西门子工业边缘集中管理减少了部署和维护支出,云上托管服务即开即用,降低运维工作量。
降低存储和传输的成本
Industrial Edge 支持就近实时分析数据,无需将全部数据保存到云端,满足数据的实时性及本地合规的需求。 来自物联网设备的数据可以在本地进行预处理或脱敏后再发送到云端进行长期存储以及复杂的数据分析/建模等。
西门子工业边缘Cloud Connector
利用云端的优势,对工业现场产生的海量数据进行分析与训练,或者实现云上的数据展示和存储,是许多工业用户的诉求。西门子工业边缘也为数据上云提供了解决方案。例如,使用西门子官方提供的Cloud Connector,可以便捷地将设备产生的数据上传至云服务器。通过Cloud Connector,您可以非常方便的连接到AWS云(上传证书,输入MQTT topic名称以及消息队列的URL地址)。

除了通过西门子官方提供的Cloud Connector连接云服务器以外,西门子工业边缘设备也支持通过AWS云提供的SDK,自行开发云连接APP,实现云——边——端的协同。
解决方案技术架构

特别说明:此技术架构作为解决方案指导供客户使用,在实际的项目中会根据具体的需求进行选择,并非全部服务都必须使用。针对IOT数据接入,您可以只选择IOT SiteWise、IOT Event以及IOT Core服务。针对数据湖以及数据分析,您可以只选择Amazon Kinesis、S3、Glue以及Athena。针对数据仓库,您在数据湖和分析的基础上增加Redshift。针对ML场景,可以增加使用SageMaker。最后,针对应用的CI/CD,可以选择使用CodeCommit以及CodeBuild等。
1.在西门子工业边缘设备中运行的南向连接器支持不同协议连接到工厂中的设备或者网关。西门子工业边缘管理平台负责将南向连接器部署到工业边缘设备中并做集中的管理
2.云连接器与AWS云之间建立连接,通过MQTT协议以TLS加密的方式将数据传输到云端
3.时序数据以流的方式注入到AWS云的IOT Core服务,IOT Core服务再通过不同的IOT Rule将数据转发到Amazon IoT SiteWise、 Amazon Kinesis Data Streams以及Amazon IoT Events等其它的云服务
4.Amazon IoT Events处理数据并基于业务逻辑触发事件通知
5.Amazon Kinesis Data Firehose 将数据直接转储到Amazon S3桶中, Amazon Glue 对数据进行ETL处理后,提供给后续的Amazon SageMaker以及 Amazon Redshift做数据消费
6.基于CodePipeline、CodeCommit以及CodeBuild在云端构建CI/CD流水线,流水线中处理的工业边缘 API 和 Amazon IoT 作业将 Docker 映像和配置文件发布到 西门子工业边缘管理平台。
Demo演示
验证 AWS与 Industry Edge 之间的集成。 Industry Edge 已经提供了一个云连接器,可以通过证书导入连接到 IOT Core。 IED 设备将在 IOT Core 中注册为事物。 通过该配置,Industry Edge 可以通过 MQTT 主题将数据传输到AWS。 数据在云端保存后,我们可以进一步存储、分析、显示甚至使用数据进行ML。 西门子有一个模拟的智能农场环境,其中包含多个传感器来收集温度、湿度、设备状态等。 我们会将这些数据收集到云端并进一步处理数据。

POC架构

- 传感器数据从 Industry Edge(IED) 注入到 IOT Core,并通过 IOT Rule 转发到 IOT Sitewise。 原始数据(属性)和聚合数据(指标)都可以显示在自定义的 Sitewise 仪表板中。 原始数据也将每 5 分钟通过 Kinesis Firehose 传输到 S3,S3 作为数据湖长期存储原始/聚合/处理数据。
- S3中的原始数据(步骤1)由Amazon Glue进一步处理,表的结构由Glue Crawler自动生成。 通过 Glue 作业将数据格式从 CSV 转换为 Parquet,客户可以定义更复杂的 ETL 流程。 Parquet 格式的数据将再次被 Glue Crawler 解析。 所有步骤均由 Glue Workflows 完成编排,并自动每天执行一次。 客户可以在 Amazon Athena 中使用 SQL 语句查询无论数据格式是 CSV 还是 Parquet 的结果,对数据进行进一步处理。
- Sagemaker 用作 ML 模型开发和训练,训练数据在前面的步骤中已被保存到S3。模型的文件在训练工作完成后存储回 S3。 Industry Edge (IEM) 中管理的应用程序下载模型并将其部署在应用程序中。 最终用户可以使用此应用程序进行预测。
配置步骤
先决条件
- AWS云测试账号
- 农作物培育箱和传感器(仅完整Demo需要)
由于Demo的后续配置过程已通过CloudFormation实现自动化,我们推荐在培育箱中使用和如下内容相同的传感器或者模拟生成相同的配置。关于传感器和开关的具体配置,您可以联系jiamin.wang@siemens.com
已使用的传感器和开关:
{“name”: “SoilTemp”, “id”: “101”, “dataType”: “Real”},
{“name”: “Illumination”, “id”: “102”, “dataType”: “DInt”},
{“name”: “AirTemp”, “id”: “103”, “dataType”: “Real”},
{“name”: “SoilHumi”, “id”: “104”, “dataType”: “Real”},
{“name”: “CO2”, “id”: “105”, “dataType”: “DInt”},
{“name”: “AirHumidity”, “id”: “106”, “dataType”: “Real”},
{“name”: “Auto_Manu”, “id”: “107”, “dataType”: “Bool”},
{“name”: “Heating”, “id”: “108”, “dataType”: “Bool”},
{“name”: “Pump”, “id”: “109”, “dataType”: “Bool”},
{“name”: “Fan”, “id”: “110”, “dataType”: “Bool”},
{“name”: “RedLight”, “id”: “111”, “dataType”: “Bool”},
{“name”: “BlueLight”, “id”: “112”, “dataType”: “Bool”},
{“name”: “WhiteLight”, “id”: “113”, “dataType”: “Bool”},
{“name”: “FanManu”, “id”: “114”, “dataType”: “Bool”},
{“name”: “WhiteLightManu”, “id”: “115”, “dataType”: “Bool”},
{“name”: “RedLightManu”, “id”: “116”, “dataType”: “Bool”},
{“name”: “PumpManu”, “id”: “117”, “dataType”: “Bool”},
{“name”: “HeatingManu”, “id”: “118”, “dataType”: “Bool”},
{“name”: “DAY”, “id”: “119”, “dataType”: “Byte”},
{“name”: “BlueLightManu”, “id”: “120”, “dataType”: “Bool”},
{“name”: “Month”, “id”: “121”, “dataType”: “Byte”},
{“name”: “Year”, “id”: “122”, “dataType”: “Int”},
{“name”: “AutoLightTime”, “id”: “123”, “dataType”: “Real”},
{“name”: “LongDay”, “id”: “124”, “dataType”: “Bool”},
{“name”: “ShortDay”, “id”: “125”, “dataType”: “Bool”},
{“name”: “LightManualStop”, “id”: “126”, “dataType”: “Bool”},
{“name”: “LightTime”, “id”: “127”, “dataType”: “Real”},
{“name”: “LightHalfAuto”, “id”: “128”, “dataType”: “Bool”},
{“name”: “AgeDays”, “id”: “129”, “dataType”: “Int”},
{“name”: “SetAgeStart”, “id”: “130”, “dataType”: “Bool”}
- 西门子PLC硬件及工业边缘软件 (仅完整Demo需要)
如需在您的AWS云测试账号中完整实现Demo的环境,请联系西门子工业边缘团队咨询如何获取西门子硬件(如HMI,PLC以及IPC)以及工业边缘软件,并获得相应的部署支持。请联系jiamin.wang@siemens.com
云资源准备
选择一: 如果您已经获取了西门子硬件以及工业边缘软件,请使用此CloudFormation脚本在您的账号中自动创建并配置部分云资源。当CloudFormation执行成功后,您需要下载证书文件(.crt)和私钥文件(.key)到您的本地,然后将它们导入到工业边缘连接器(connector)。您也需要在工业边缘连接器中使用和CloudFormation中相同的消息topic名称。请联系jiamin.wang@siemens.com咨询如何导入文件到连接器。请注意您必须使用和前面章节介绍的相同的传感器/开关,否则您还需要在CloudFormation执行完毕后调整Sitewise 和 IOT Core两个部分的配置,使Sitewise中的模型配置以及IOT Core中的转发规则与您实际的传感器/开关 保持一致。
如何下载证书和私钥文件?
- 登录到您的AWS云管理控制台切换到CloudFormation服务,从Systems Manager – Parameter Store中获取证书和私钥的内容

- 点击‘IoTCertificateKeyURL’ 和 ‘IoTCertificatePrivateKeyURL’的输出URL,页面会被重定向到Parameter Store


- 复制‘/smartfarm/certificatePem’对应的值并保存成文件csr,复制‘/smartfarm/keyPair/PrivateKey’对应的值并保存成文件privatekey.key
选择二: 如果您只希望测试AWS云端的部分,请在您的账号中使用此CloudFormation脚本。这个CloudFormation脚本会额外创建一个EC2虚拟机,此虚拟机会被用于模拟传感器生成和真实环境相同配置的数据格式并实时注入数据到Amazon IOT服务
测试AWS云服务
第一部分:IOT Core/Sitewise/Kinesis/S3
CloudFormation执行成功后,会自动完成IOT Core/Sitewise/Kinesis Firehose/S3的配置。 您可以从 AWS云 服务控制台检查配置。 我们只展示部分关键配置。
IOT Sitewise
模型架构:两层架构:Smart Farm作为父层,各种类型的传感器/设备作为子层。 {Byte, DInt, Int} 匹配 Int,Real 匹配 Double,Bool 匹配 Bool。 最终会生成4个模型。 Smart Farm模型包括其他三个。

Asset 架构:使用之前创建的模型为每一个传感器/开关创建一个资产,一共有30个资产会被创建,这些资产归属于Smart_Farm资产。

接下来我们需要配置后续在Sitewise Dashboard中使用的的告警
- 选择您希望添加告警的模型并切换到Alarm definitions

- 点击 Add Alarm 为土壤湿度和温度增加两个告警,输入告警的名称

- 选择需要监控的 property,我们选择Max Val作为 property,告警触发值为 SoilHumiNormal的值,这个值在Attribute中已经定义好了。You can also define the severity of this alarm.您也可以定义告警的Severity。当土壤湿度大于15%时,告警会在您后续配置的Dashboard中触发并显示。
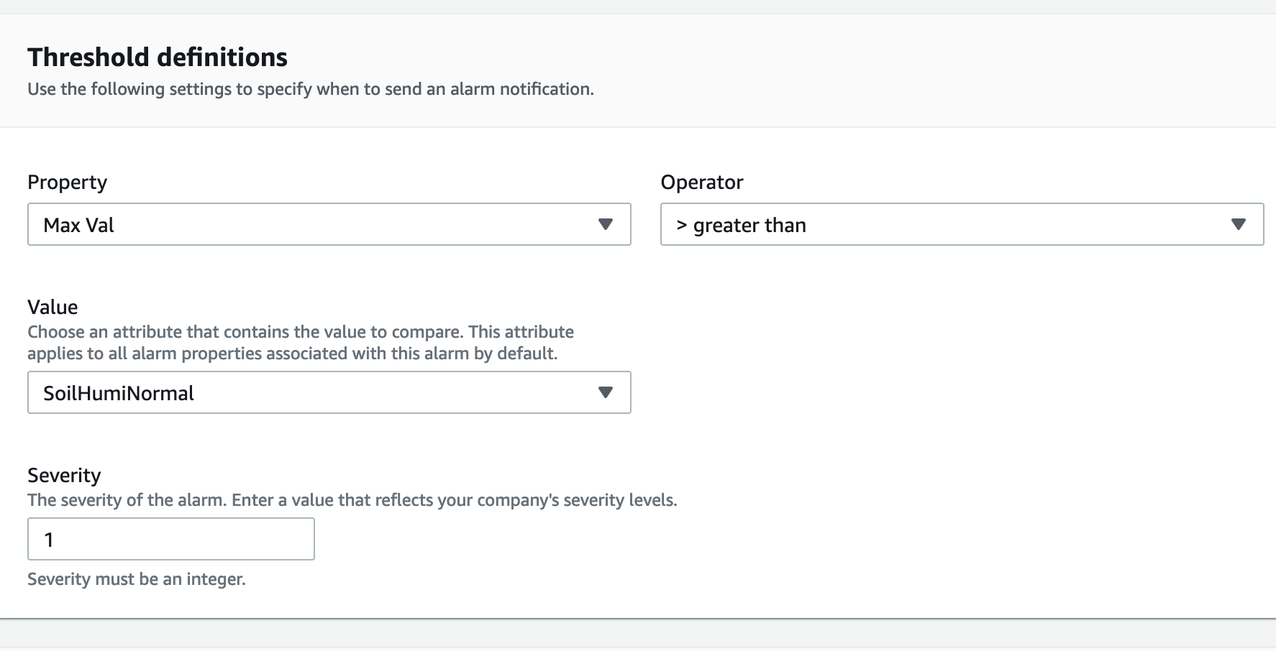
- 重复第2步和第3步创建另外一个告警。我们仍然使用Max Val作为property,但使用SoilTempNormal作为threshold

到目前为止,我们已经通过工业边缘设备 (IED) 中的云连接器成功地将数据从传感器加载到 Sitewise。 接下来,我们将制作一个仪表板来显示资产属性和指标。 最终的示例仪表板将是这样的。

- 切换到Sitewise服务并点击Portals

- 点击Assign users 添加Portal administrator

- 选择您自己的IAM用户并点击Assign administrators, 添加后就可以通过URL登录到URL

- 在使用管理员用户权限登录到Portal后,您可以看到所有之前在Sitewise控制台中配置完成的模型和资产

- 接下来我们配置一个Dashboard,切换到Project之后打开已经创建好的Project并点击Create dashboard
2
- 您现在可以拖拽之前定义好的properties和alarms。您可以定制您的Visualization甚至是可以为特定的property增加Trend lines

- 关于如何配置Sitewise Monitor的更多细节,请访问link
Kinesis/S3
- 切换到Kinesis Firehose 控制台并找到已经创建好的delivery stream

- 检查monitoring确认是否有数据写入到Kinesis, 您会看到类似如下的图形

- 最终,您会在S3桶中看到对象文件的生成。由于我们在Buffer interval中定义了默认5分钟,大约每5分钟会生成一个文件到S3

第二部分: Glue/Athena
在本节中,我们将使用 Glue 和 Athena 处理数据湖(S3)中每日生成的数据。 我们将使用 Glue Crawler 生成数据模式并将数据自动导入 Glue 数据库。 然后我们可以使用 Athena 来查询和检查数据。 将在 Glue 中创建数据 ETL 作业,以将数据格式从 CSV 转换为 Parquet。 然后将创建另一个 Crawler 作业以基于 Parquet 文件生成新表。 之后,我们可以使用 Athena 查询 Parquet 格式的数据,并与 CSV 格式的性能进行比较。 最后,我们将使用 Glue Workflow 将两个爬虫作业和一个 ETL作业 编排在一起,并每日自动触发工作流。 我们已经通过 CloudFormation 创建了两个 Crawler 作业,您只需要配置其它的部分。
使用Glue管理Metadata
- 切换到Glue console并选择Crawler, 点击Run crawler 运行名字前缀为SmartFarmDataCrawler的crawler

- 作业运行完毕后,您可以查看运行的结果。正常情况下,您可以看到有Tables added或者Tables updated的记录

使用Athena查询数据
- 找到刚刚创建成功的table并点击View data

- 您会被重定向到Athena控制台,Athenam会自动生成一个SQL查询语句。请注意右上角Workgroupd中的配置不能为空。

- 接下来我们可以调整SQL语句,删除 ‘limit 10’。查询运行成功后,记录Run time和Data scanned

使用Glue将数据格式从CSV转换成Parquet
- 切换回Glue控制台并选择Jobs

- 点击Add job,输入名称并选择有足够访问S3权限的IAM角色。我们已经创建好了一个IAM角色,名字的前缀为prefix SiemensSmartFarm.。我们选择使用Spark 2.4.为engine type。
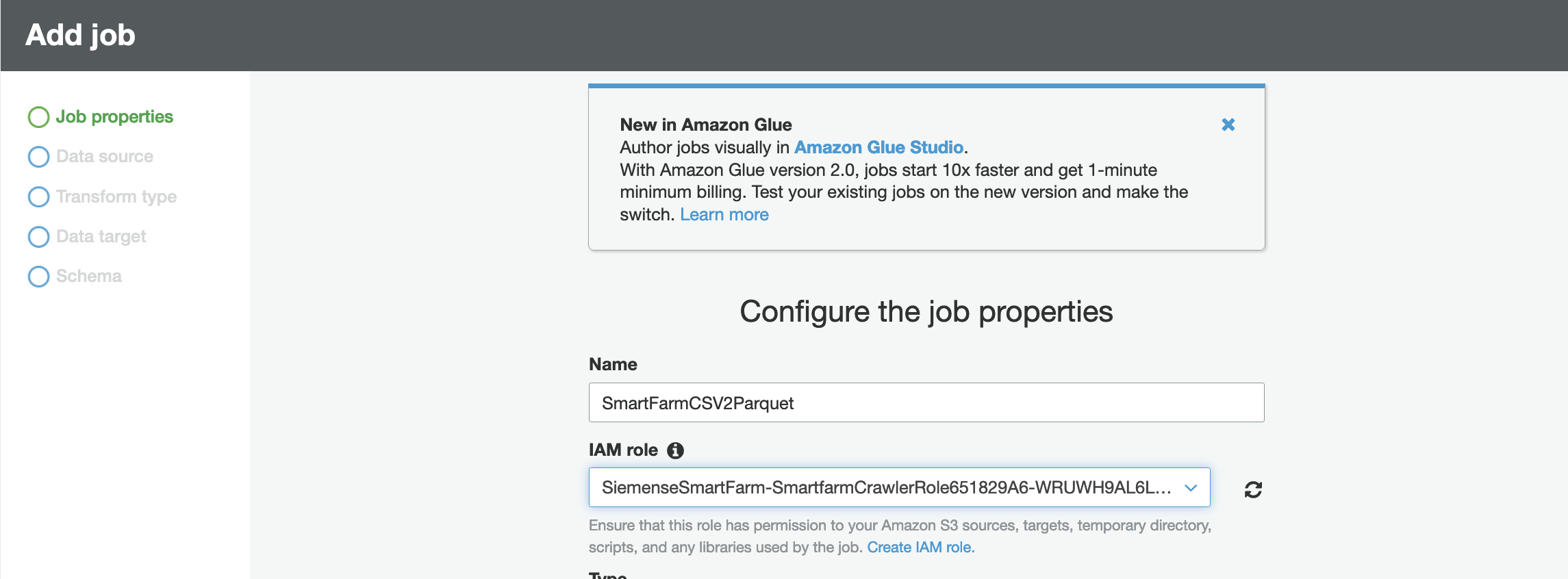
- Glue 将帮助生成脚本,设置如下。 请注意,您必须启用Job bookmark,,然后每次 ETL 作业将只处理 Glue 表中的每日增量数据,而不是所有数据。

- 选择您刚刚创建好的table作为Data source

- 我们需要创建一个新的dataset,因此选择Change schema

- 选择S3作为Data store,Format是Parquet,选择名称前缀为“siemensesmartfarm-siemensindustryedgedemo”的S3 bucket作为Target path。请记住在选择 S3 存储桶后添加“/rawdataparquet”。

- 确认schema但无需更改任何内容

- 点击Save job并选择edit script,您将被重定向到生成的代码,您可以修改代码以支持更复杂的逻辑。但是对于这个演示,无需更改任何内容,只需关闭页面即可。

- 至此一个ELT作业配置完成,您可以点击Run job执行该作业

- 作业运行成功后,您可以看到相应的记录并在S3中找到对应的文件


配置第二个Crawler用于爬取Parquet文件
- 找到另一个名称前缀为“smartFarmDataCrawlerParquet”的crawler并运行该爬虫
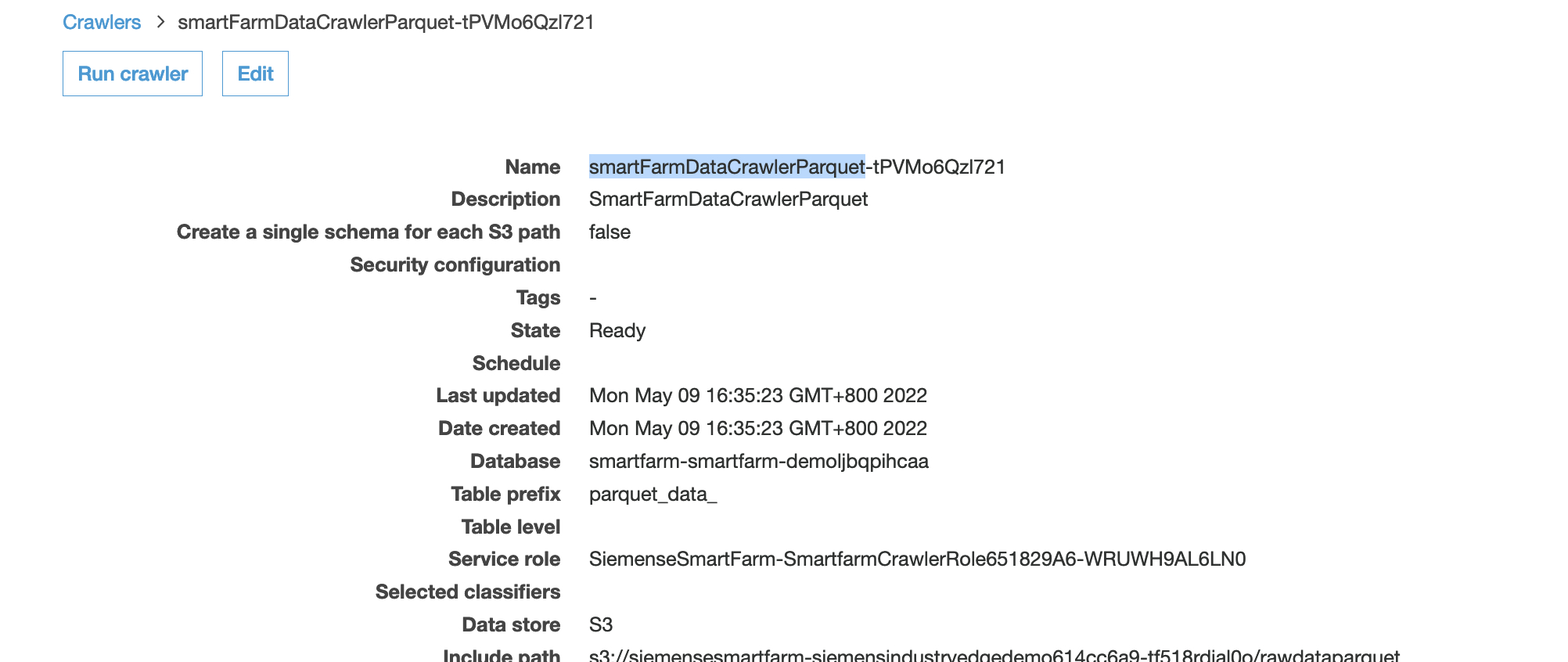
- job执行后,会在同一个数据库下生成一张新表

使用Athena查询新的Table中的数据
- 找到table并点击View data

- 运行 SQL 查询。如果比较 CSV 格式的结果(运行时间=3.553s, 扫描数据:3MB),性能从时间和数据大小都得到了优化。

使用Glue Workflows编排多个步骤
- 切换到Workflows并点击Add workflow

- 给它一个名字并将 Max concurrency 设置为 1,因为该workflow每天只执行一次

- 选择Add trigger开始定义流程

- 新增一个trigger, 输入名称并选择Schedule 作为Trigger type

- 将频率设置为Daily,开始时间我们配置为 00:02,以便处理昨天生成的所有数据,然后单击Add

- 点击Add node, 然后选择第一个用于处理原始数据(CSV)的爬虫
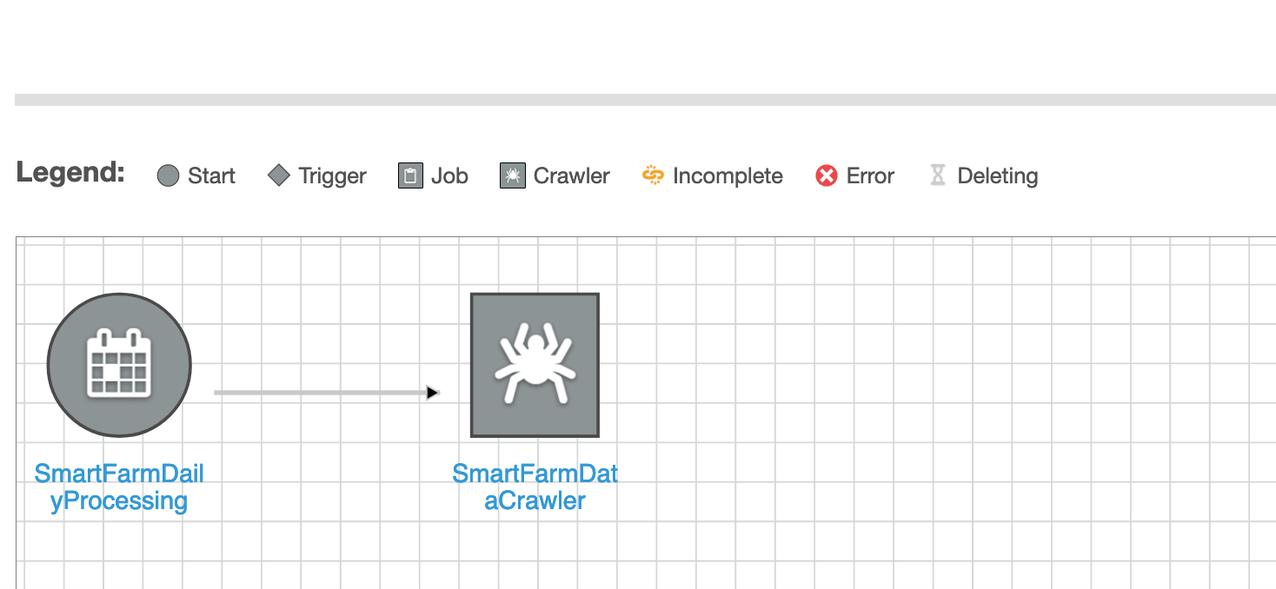
- 点击crawler图标并增加下一个trigger

- Trigger 的type选择Event, 点击Add
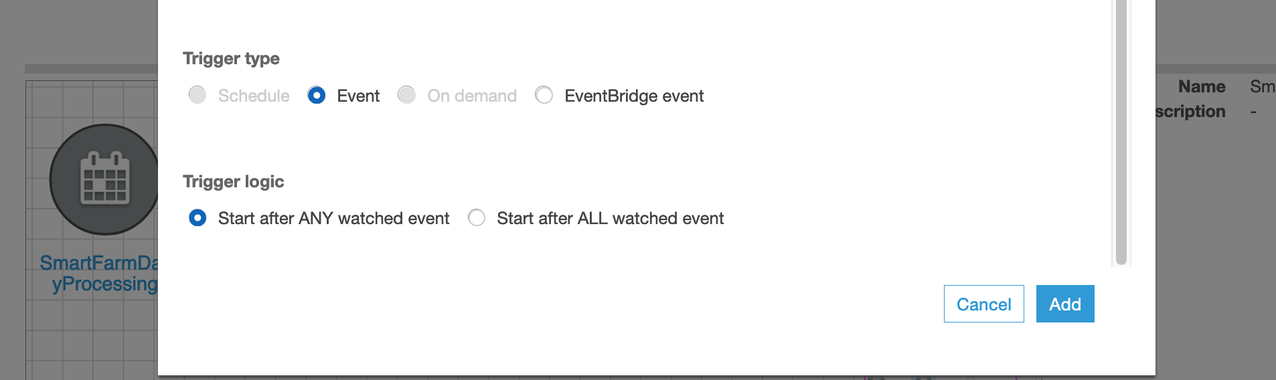
- 点击Add node添加一个ETL作业,该作业将数据格式从CSV转换成Parquet

- 点击这个ETL作业的图标增加下一个trigger
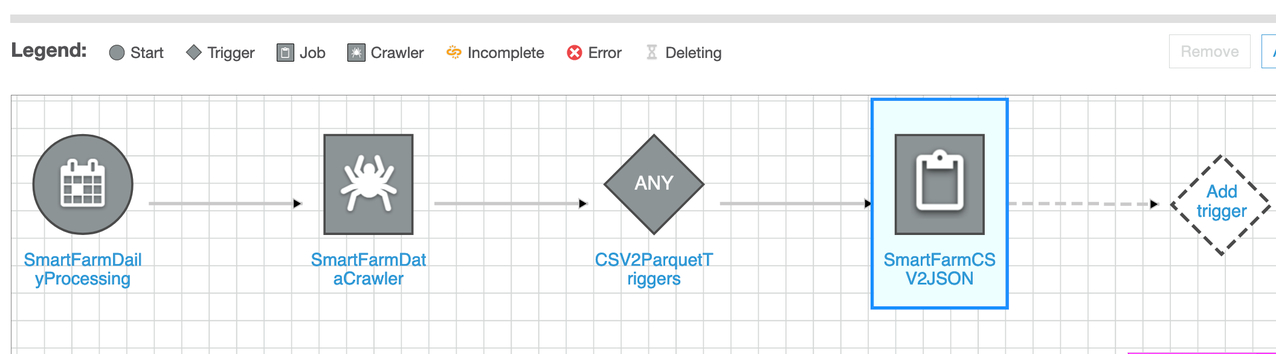
- 点击Add trigger增加下一个trigger,属于一个名称并选择Event类型

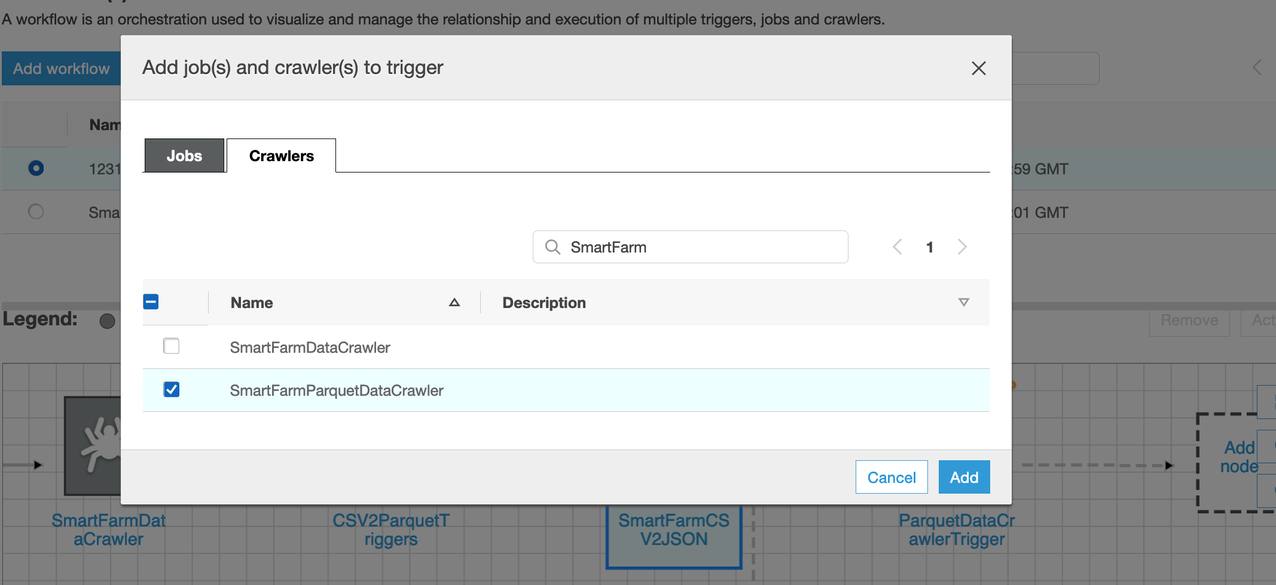
- 点击Add node添加我们之前创建的第二个爬虫作业。
- 最后,我们在Workflow中配置了完整的流程,工作流将每天自动触发。

第三部分: Sagemaker
在温室作物的种植中,大多数人关注温室内气温湿度和土壤温湿度的变化,却往往忽略了温室内CO2浓度对作物生长的影响。能量转换过程-光合作用,因此科学测量温室内CO2浓度,通过温室通风、CO2基肥的使用等方式合理调节CO2浓度,有利于农业增产增效。
在本节中,我们将使用 Sagemaker 训练一个模型,该模型可以根据传感器的历史数据预测未来 10 分钟内的 CO2 浓度变化。模型文件将存储在 S3 存储桶中,您可以下载该文件并将其加载到托管在您的 Industry Edge 中的应用程序中以进行本地预测和监控。一旦CO2浓度变化趋势异常,用户可提前报警并执行相应动作。
我们已经通过 CloudFormation 在 Sagemaker 中生成了两个 Jupyter Notebook 文件。您只需要打开它们并逐步执行代码。然后你可以检查预测。通过以下步骤开始使用 Sagemaker。
- 打开Sagemaker控制台并选择Notebook instances

- 单击Open Jupyter,您将找到两个以“.ipynb”结尾的笔记本。您将使用ipynb 分析和准备数据,然后使用 2_time_series_forecast-gluonts.ipynb 构建模型并检查预测。

- 打开0_data_prepare.ipynb notebook,按照步骤执行代码。 请注意,您需要等到 2-3 天才能收集足够的数据用于训练和测试。

修改 S3 桶名称:
训练任务定义:
- 您可以根据数据的时间范围对训练/测试/预测数据集进行分段。
- 您可以定义预测频率,默认为 1 分钟
- 您可以定义预测长度,默认为 10 分钟
- 您可以选择预测目标,我们在这个演示中使用 CO2(id=105)为例训练预测模型

- 打开 2_time_series_forecast-gluonts.ipynb
模型文件输出定义:

选择DeepAR或NPTS作为预测器:

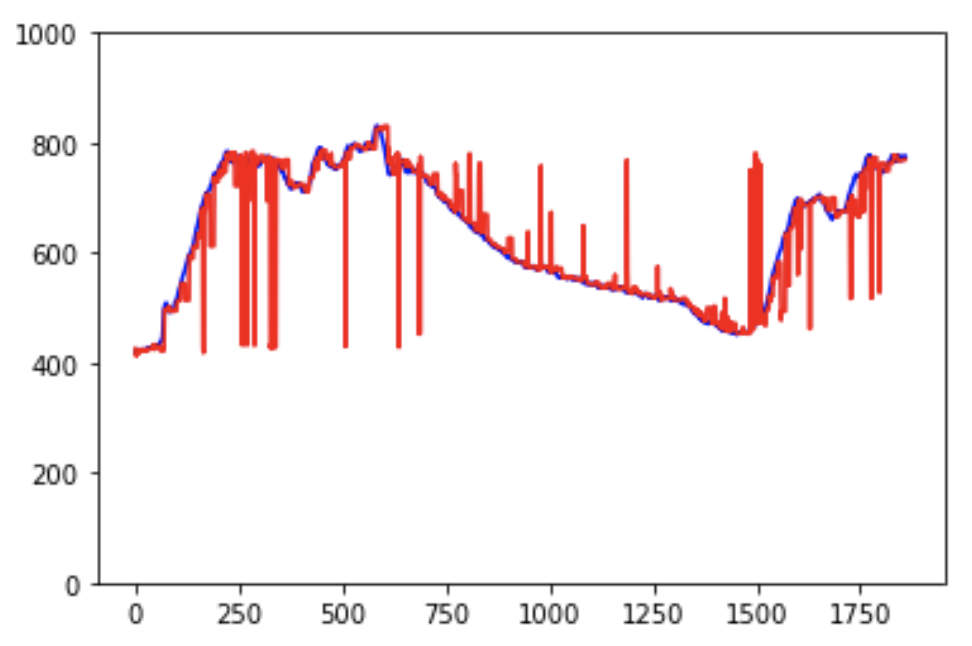
在演示中,我们同时使用了 Sagemaker 内置算法 DeepAR 和 GluonTS的 NPTS,并比较了预测结果。 用于模型训练的源数据位于 S3 存储桶中,但是您需要等待 2-3 天才能收集到足够的数据用于模型训练。 我们使用前 1 天的数据来预测当前代码中未来 10 分钟的趋势,您可以修改时间窗口。 从下图中您可以发现两种算法都可以正确预测趋势(蓝线是真实数据/红线是预测)。
 |
 |
总结
基于AWS云和西门子工业边缘的云边协同方案是一个云和边缘协同的集成解决方案,客户可以从 Siemens Industry Edge 和 AWS 云服务中获益。 客户可以在本地继续处理需要更低延迟和强制性数据本地化合规要求的数据或业务逻辑,同时利用丰富的云服务,包括 Amazon IOT、Data Lake、Data Analytics、AI/ML 和 CICD等,通过托管服务提供扩展的计算和存储资源。 围绕这个方案,西门子和 AWS 也会持续扩大云边生态,同时我们希望邀请越来越多的合作伙伴加入并共同完善这个生态。