亚马逊AWS官方博客
在Amazon EKS上部署OpenClaw AI Agent:基于Kata Containers的企业级沙箱实践
容器环境下AI Agent Sandbox的需求与挑战
Agent Sandbox需要运行Python脚本、操作文件系统、调用shell命令、安装依赖包,这些操作要求一个完整的运行时环境。在企业环境中,这意味着需要为每个Agent提供一个独立的、受控的计算沙箱。容器是承载这类工作负载的自然选择,但在实际落地过程中需要解决以下几个核心问题。
隔离粒度。 传统容器共享宿主机内核。如果Agent发生了逃逸,理论上可以逃逸到宿主机,进而影响同节点上的所有其他Agent。在多租户场景下,发生安全事件,一个用户的Agent可能访问到另一个用户的数据。Linux namespace和cgroup能够覆盖多数隔离需求,但”多数”在安全领域是不够的。
生命周期管理。 Agent沙箱的生命周期与用户会话绑定,随用户上线创建、离线释放。部分场景对启动速度要求极高,例如用户发送一条消息后,沙箱需要在毫秒级完成初始化并开始执行代码,冷启动延迟直接影响用户体验。这要求底层支持warm pool(预热待命的沙箱实例池)和template(标准化沙箱模板,包含预装环境和配置),使沙箱创建尽可能走热路径。同时,沙箱之间必须保持严格的状态隔离,销毁后不能残留任何数据。
模型对接。 Agent需要调用LLM完成推理。生产环境中不应让每个沙箱Pod直接持有模型API的凭据,credential泄露的影响面不可控。需要一个中间层统一处理认证、路由、限流和监控。
持久化存储。 Agent具有状态数据,包括配置文件、会话历史、工作区内容。沙箱重启后状态不能丢失,但沙箱删除时需要彻底清理。持久化、隔离和IO性能三者需要同时满足。
这篇文章介绍如何在Amazon EKS上利用Kata Containers部署和运维OpenClaw Agent Sandbox,完整的Terraform代码和配置见:openclaw-on-eks
整体架构
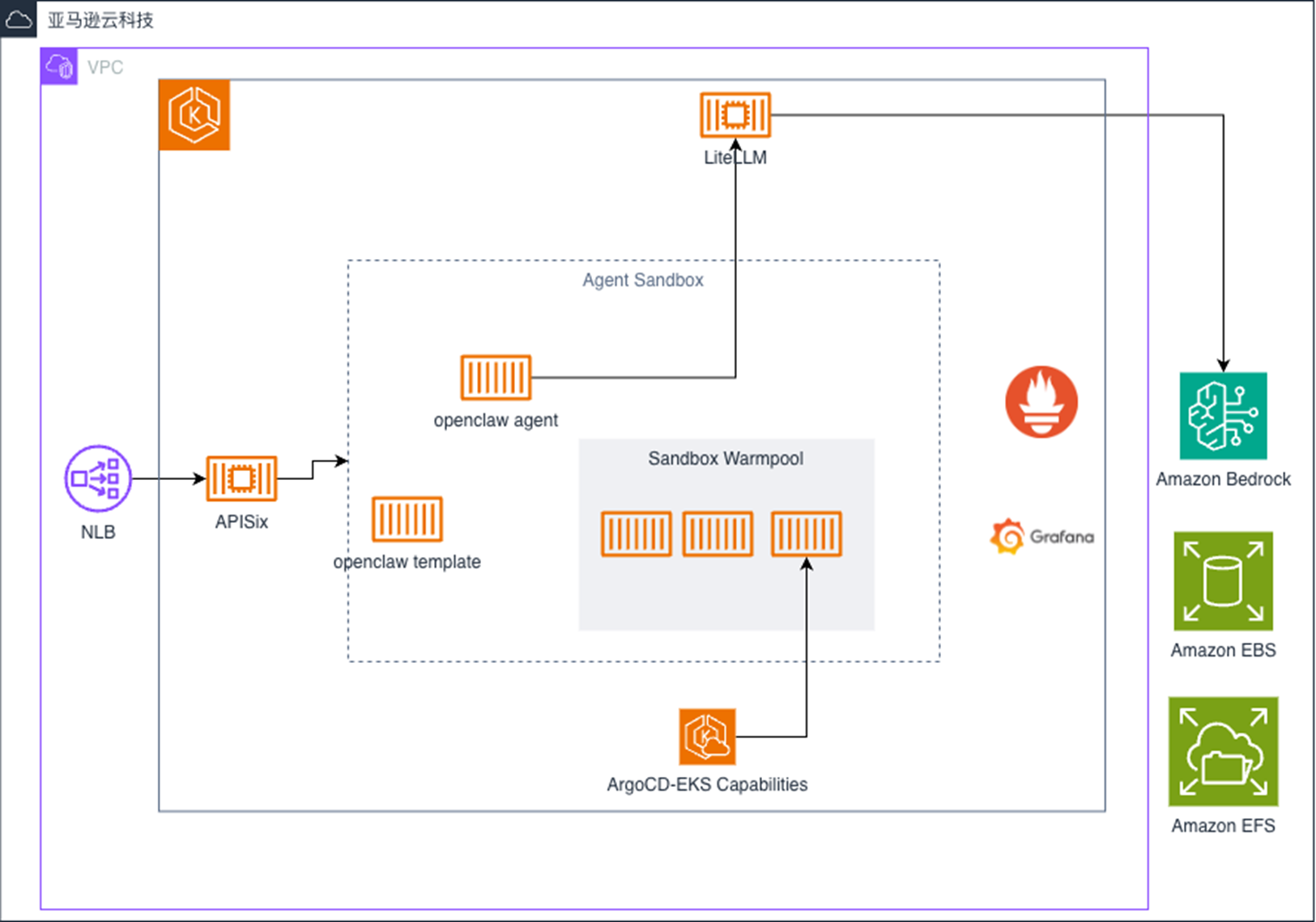 |
- Amazon EKS集群:托管Kubernetes控制平面,core节点组(m5.xlarge)承载系统工作负载
- Karpenter:按需弹性供给裸金属实例,沙箱Pod触发时自动拉起,空闲1分钟内回收
- Kata Containers:为每个沙箱Pod提供VM级别隔离,支持Firecracker和Cloud Hypervisor等
- LiteLLM Proxy:OpenAI兼容的API网关,统一对接Amazon Bedrock、硅基流动等模型提供商
- Agent Sandbox Controller:CRD驱动的沙箱生命周期管理,支持warm pool和模板化创建
- Prometheus + Grafana:可观测性栈,包含预置的LiteLLM监控面板
以下章节将逐一展开各组件的技术细节,包括模型对接方式、Hypervisor选型依据、存储分层设计和安全加固策略。
模型对接
LiteLLM在架构中充当统一的模型网关,对上层暴露OpenAI兼容API,对下层同时对接多个模型提供商。当前方案验证了两种接入方式。
Amazon Bedrock(Claude Opus 4.6)
项目默认对接Bedrock上的Claude Opus 4.6,通过cross-region inference profile路由至us-east-1。认证采用EKS Pod Identity机制,LiteLLM的ServiceAccount绑定IAM Role,运行时自动获取临时凭据,沙箱Pod本身不持有任何credential。
LiteLLM Helm配置示例:
硅基流动(SiliconFlow)
如果将openClaw选择部署在亚马逊云科技中国区,可以考虑使用对接硅基流动,硅基流动提供OpenAI兼容的API接口,LiteLLM原生支持。
在LiteLLM配置中添加对应的model entry即可:
model_list:
OpenClaw端将模型ID指向LiteLLM中定义的model_name:
这一设计使模型切换对沙箱完全透明,只需修改LiteLLM配置,无需变更沙箱Pod。
Kata Hypervisor选型
Kata Containers支持三种Hypervisor,各有适用场景。
特性对比:
- QEMU:生态最为成熟,功能最为完整,支持virtio-fs和hotplug。启动速度和资源开销相对较高,但在兼容性方面没有短板。
- Cloud Hypervisor(CLH):支持virtio-fs和hotplug,启动速度快、内存开销低,功能接近QEMU,定位为QEMU的现代化替代方案。
- Firecracker:启动速度最快(125ms级别),内存开销最低(约5MB/VM)。但不支持virtio-fs(需要配置devmapper),不支持hotplug(CPU/内存必须在启动时静态分配)。
关键差异:
- 文件系统共享:QEMU和CLH支持virtio-fs,容器镜像可通过共享文件系统传递给Guest VM。Firecracker不支持此机制,必须通过block device(devmapper)传递,需要在节点上额外配置thinpool。
- 资源热插拔:QEMU和CLH支持运行时动态调整CPU和内存。Firecracker需在启动时静态分配(static_sandbox_resource_mgmt)。
- Graviton/ARM:三种Hypervisor均兼容Graviton,但QEMU和Firecracker在ARM架构上不支持hotplug,需要开启静态资源管理。
项目默认使用QEMU,同时启用CLH,通过RuntimeClass进行区分:
Hypervisor选型取决于具体场景:对启动延迟敏感的工作负载适合Firecracker或CLH,需要功能完备性的场景适合QEMU或CLH,追求最低资源开销则选择Firecracker。
存储方案
Amazon EBS
每个OpenClaw沙箱Pod挂载一个2Gi的EBS gp3卷至/home/node/.openclaw,用于存储Agent配置、会话历史和workspace文件。EBS通过CSI Driver动态供给,Pod重启后数据持久保留。
需要注意单节点EBS挂载数量存在上限。不同EC2实例类型支持的EBS卷数量不同(参见Amazon EBS specifications),这直接影响单节点的沙箱部署密度。
适用于firecracker。
利用Amazon EFS的Access Point实现隔离
EBS的per-pod持久化模式适用于多数Agent沙箱场景,但EBS卷受限于单AZ挂载,且单节点挂载数量存在上限。当沙箱密度较高或需要跨AZ调度时,Amazon EFS是一个替代方案。EFS的Access Point机制天然适合Agent沙箱的隔离需求:每个沙箱Pod分配一个独立的Access Point,配置独立的root directory、POSIX user identity(UID/GID)和目录权限。当沙箱Pod通过Access Point挂载EFS时,EFS强制将所有文件操作的用户身份替换为Access Point上配置的UID/GID,忽略NFS客户端的实际身份。Access Point的root directory对挂载方而言就是文件系统的根目录,沙箱A无法访问沙箱B的目录。结合IAM Policy可以进一步限制特定Pod只能使用其对应的Access Point,从身份、路径、权限三个维度确保沙箱间的数据隔离。
中小规模部署,Dynamic Provisioning的隔离和自动化已经足够。大规模多租户场景建议Static Provisioning提前预热,同时利用IAM Policy限制每个ServiceAccount只能访问其对应的Access Point。
安全架构
Pod与宿主机隔离
Kata Containers为每个Pod启动独立VM,运行独立的Guest内核。在此基础上,通过以下配置进一步加固:
以非root用户运行,丢弃全部Linux capabilities,禁止权限提升。
网络隔离
Kata在tc网络模式(默认模式),Kubernetes NetworkPolicy在该模式下正常生效。EKS同时支持标准和集群级别的网络策略。
七层流量管理(基于域名的白名单)方面,DNS Policy目前仅在EKS Auto Mode下原生可用,其他集群需要借助Cilium或Istio实现。
凭据管理
整个架构中不存在长期凭据:
- Bedrock:LiteLLM通过Pod Identity获取临时凭据
- LiteLLM API Key:动态生成,设置30天有效期
- Slack/飞书Token:通过Kubernetes Secret管理,定期轮换
- openClaw Token: 建议通过secrets manager进行存储
部署步骤
前置条件
### Step 1:克隆仓库并执行部署脚本
项目基于Terraform管理全部基础设施。`install.sh`封装了Terraform和Helm的执行流程,创建的资源包括:VPC及子网、EKS集群及core节点组、Karpenter(含裸金属EC2NodeClass和NodePool)、Kata Containers(kata-deploy)、LiteLLM Proxy(含Pod Identity配置)、Prometheus和Grafana。
支持自定义Region和集群名称:
完整部署过程约15-20分钟。
### Step 2:获取LiteLLM API Key
集群就绪后,需要通过LiteLLM的master key为每一个Sandbox生成一个专用的API Key。该Key用于OpenClaw沙箱Pod向LiteLLM发起推理请求时的认证,有效期设置为30天:
### Step 3:验证Bedrock连通性
在部署沙箱之前,先确认LiteLLM到Bedrock的完整链路(Pod Identity → STS AssumeRole → Bedrock InvokeModel)工作正常。通过一个临时Pod向LiteLLM发送测试请求:
收到正常的模型回复即表明访问Bedrock的连接已经建立。
### Step 4:部署飞书Agent沙箱
将前面生成的LiteLLM API Key和飞书应用凭据注入沙箱配置文件,然后通过kubectl创建沙箱资源。Agent Sandbox Controller会根据CRD定义创建对应的Pod,该Pod运行在Kata VM中,挂载2Gi EBS卷作为持久化工作区,通过集群内网连接LiteLLM Proxy,对外通过webhook与飞书通信,建议将IM的链接信息也通过secrets manager进行管理:
### Step 5:验证
确认沙箱资源状态为Running,检查Pod日志确认OpenClaw Gateway已启动并成功连接飞书webhook:
在飞书中向Bot发送消息,确认能够收到正常回复。
可观测性
Prometheus和Grafana随Terraform一同部署完成。
Grafana
项目提供了预置的LiteLLM Grafana Dashboard(examples/grafana/grafana_dashboard.json),覆盖以下指标:
- 请求指标:总量、失败率、请求速率
- Token消耗:按模型维度的输入/输出统计
- 延迟指标:请求延迟、LLM API延迟、首token时间(TTFT)
- 费用追踪:按团队、用户、API Key维度的消费统计
资源清理
总结
AI Agent对运行环境的要求与传统容器工作负载有本质区别:不可预测的代码执行、多租户间的强隔离需求、毫秒级的沙箱启停、有状态的持久化管理。Kata Containers通过VM级别的隔离为Agent Sandbox提供了安全基础,每个沙箱Pod运行在独立的Guest内核中,攻击面从整个Linux内核syscall缩小到Hypervisor虚拟设备接口,同时Hypervisor配额与Guest cgroup构成双层资源边界。
在此基础上,Agent Sandbox Controller通过CRD定义沙箱的完整生命周期,结合warm pool和template机制实现快速创建;Karpenter按需供给裸金属节点,将基础设施成本与实际使用量挂钩;LiteLLM统一收口模型认证和路由,使credential不下沉到沙箱层。这些组件共同构成了一个面向AI Agent的沙箱运行框架。
➡️ 下一步行动:
相关产品:
- Amazon Q — 采用生成式人工智能技术的工作助理
- Amazon EKS — 用于运行容器化应用程序的托管式 Kubernetes 服务
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon EBS — 适用于任何规模的高性能数据块存储
- Amazon EFS — 无服务器,完全弹性文件存储
相关文章:
- OpenClaw 安全和功能增强实践
- 还在养龙虾(OpenClaw)吗?教你在 AWS 上让龙虾自己生龙虾
- OpenClaw 在电商平台的应用场景探索
- 推出 OpenClaw on Amazon Lightsail,用于运行您的自主私有人工智能代理
- 基于亚马逊云科技 Mac 实例部署 OpenClaw,深度苹果生态自动化的最佳选择
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
