成本优化近年来已经成为云上客户越发重点关注的问题。容器场景的成本优化的需求量尤其突出。在整个系列博客中我们以大数据分析业务场景为示例,利用 Karpenter + Spot + Graviton,通过控制实例启动的优先级达到成本优化的目的,由此构建基于 EMR on EKS 的 Spark 集群的成本优化解决方案。
在系列 blog(一)中的方案基本配置完成后,测试环境已经准备好,我们可以开始进行有效性测试观察节点机型启动优先级,并且为此方案整理出成本优化最佳实践。
有效性测试
第一步:将实验环境的参数存入~/.bash_profile 中,这样在不同的 terminal 都可以保持同样的变量值
echo "export CLUSTER_NAME=spot-graviton-karpenter-demo" >> ~/.bash_profile
echo "export AWS_REGION=us-east-1" >> ~/.bash_profile
echo "export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)" >> ~/.bash_profile
echo "export CLUSTER_ENDPOINT=$(aws eks describe-cluster --name ${CLUSTER_NAME} --query "cluster.endpoint" --output text)" >> ~/.bash_profile
echo "export KARPENTER_VERSION=${KARPENTER_VERSION}" >> ~/.bash_profile
echo "export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"" >> ~/.bash_profile
echo "export EMR_Job_Execution_Role=EMRContainers-JobExecutionRole" >> ~/.bash_profile
echo "export s3DemoBucket=s3://emr-on-eks-graviton-spot-${AWS_ACCOUNT_ID}-${AWS_REGION}" >> ~/.bash_profile
source ~/.bash_profile
第二步:创建 EMR Job Json 文件并指定 Spark Job 任务运行所需的参数
首先创建 Cloudwatch 日志组用来存储 EMR job 日志。
aws logs create-log-group --log-group-name=/emr-on-eks/spot-graviton-karpenter-demo
然后创建测试 1 的 EMR Job Json 文件并指定 Spark Job 任务运行所需的参数。
- 通过
entryPoint 指定 S3 桶的测试应用代码
- 通过
spark.kubernetes.driver.podTemplateFile 和 spark.kubernetes.executor.podTemplateFile 指定 S3 桶中 pod template
- 通过
monitoringConfiguration 将 EMR job 日志传到 Cloudwatch group ‘/emr-on-eks/spot-graviton-karpenter-demo/wordcount-demo1’ 和 S3 中
- 启用 Spark Dynamic Resource Allocation(DRA)扩缩 executor 的数量。该功能有助于根据工作负载上下扩展向应用程序注册的执行程序的数量。使用 DRA,Spark 驱动程序会生成初始数量的执行程序,然后按比例扩展,直到达到指定的最大执行程序数来处理挂起的任务。当没有挂起的任务时,空闲执行程序将终止。启用该功能的参数详情可参考 Spark 官网。
替换下方的<EMR_on_EKS_ClusterID>还有<EMR_execution_role_ARN>。
cat << EOF > start-job-run-request_wordcount_demo1.json
{
"name": "spark-demo",
"virtualClusterId": "<EMR_on_EKS_ClusterID>",
"executionRoleArn": "<EMR_execution_role_ARN>",
"releaseLabel": "emr-6.8.0-latest",
"jobDriver": {
"sparkSubmitJobDriver": {
"entryPoint": "$s3DemoBucket/wordcount.py",
"entryPointArguments": ["$s3DemoBucket/output/wordcount_output_demo1"],
"sparkSubmitParameters": "--class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.executor.memory=2G --conf spark.executor.cores=1 --conf spark.driver.cores=1 --conf spark.driver.memory=2G"
}
},
"configurationOverrides": {
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.dynamicAllocation.enabled":"true",
"spark.dynamicAllocation.shuffleTracking.enabled":"true",
"spark.dynamicAllocation.shuffleTracking.timeout":"120s",
"spark.dynamicAllocation.minExecutors":"3",
"spark.dynamicAllocation.maxExecutors":"10",
"spark.dynamicAllocation.initialExecutors":"3",
"spark.kubernetes.allocation.batch.size":"1",
"spark.dynamicAllocation.executorAllocationRatio":"1",
"spark.dynamicAllocation.schedulerBacklogTimeout": "1s",
"spark.dynamicAllocation.executorIdleTimeout": "120s",
"spark.kubernetes.executor.deleteOnTermination": "true",
"spark.decommission.enabled": "true",
"spark.storage.decommission.enabled": "true",
"spark.storage.decommission.rddBlocks.enabled": "true",
"spark.storage.decommission.shuffleBlocks.enabled": "true",
"spark.kubernetes.driver.podTemplateFile":"$s3DemoBucket/pod_templates/spark_driver_pod_template.yaml",
"spark.kubernetes.executor.podTemplateFile":"$s3DemoBucket/pod_templates/spark_executor_pod_template.yaml"
}
}
],
"monitoringConfiguration": {
"cloudWatchMonitoringConfiguration": {
"logGroupName": "/emr-on-eks/spot-graviton-karpenter-demo",
"logStreamNamePrefix": "wordcount-demo1"
},
"s3MonitoringConfiguration": {
"logUri": "$s3DemoBucket/job_monitoring_logging/"
}
}
}
}
EOF
第三步:提交任务
使用 start-job-run 命令和存储在本地的 start-job-run-request.json 文件路径。
aws emr-containers start-job-run --cli-input-json file://./start-job-run-request_wordcount_demo1.json
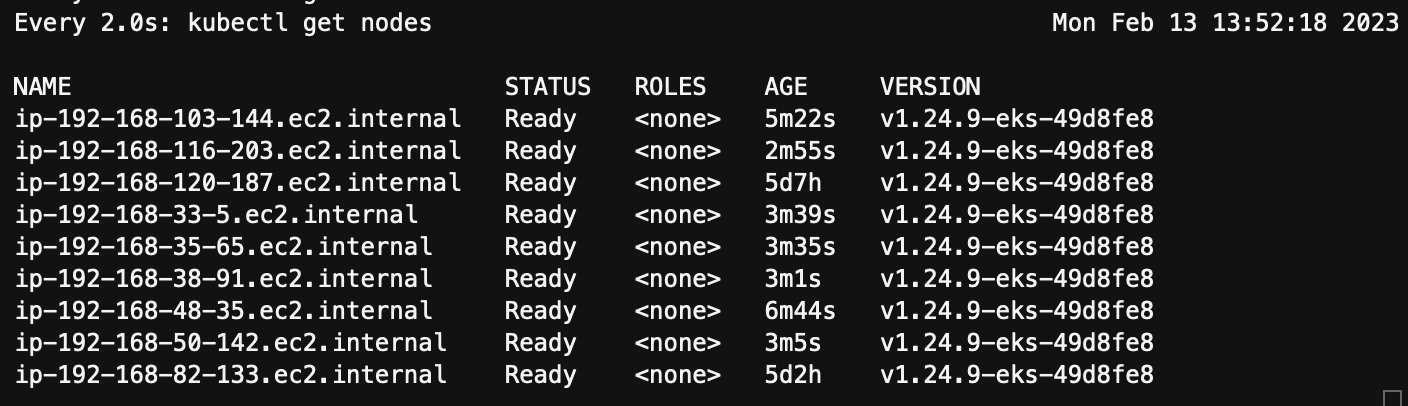
第四步:通过以下命令看到观察命名空间 spark 下 pod 的状态和集群节点的变化
watch kubectl get pods -n spark


第五步:当 Spark 命名空间下的 pod 都在 Running 状态下,运行以下命令观察哪些 pods 部署在按需或者 Spot 实例上
首先查看目前 EKS 集群中节点的 CPU 架构(arm64/amd64)和 Capacity 类别(按需/Spot)。
kubectl get nodes -o custom-columns=Node:.metadata.name,Capacity-Type:".metadata.labels.karpenter\.sh/capacity-type",Arch:".metadata.labels.kubernetes\.io/arch",Instance-Type:".metadata.labels.beta\.kubernetes\.io/instance-type",Status:status.conditions[-1].type -w

集群中当前共 9 个节点,其中 Capacity-Type 为<none>的是之前由 EKS 托管节点组创建的两个按需节点。其余 7 个节点中 2 个是 arm64 架构的按需节点,另外 5 个是 arm64 架构 spot 节点。
然后查看在按需实例上的 pod:
for n in $(kubectl get nodes -l karpenter.sh/capacity-type=on-demand --no-headers | cut -d " " -f1); do echo "Pods on instance ${n}:";kubectl get pods -n spark --no-headers --field-selector spec.nodeName=${n} ; echo ; done

可以看到 Spark Driver pod 运行在新增的节点 – 按需实例 192.168.103.44 上,结合之前的命令结果该实例为 on-demand 按需实例。由此我们可以验证管理 Driver pod 的 Karpenter default Provisioner 的配置会优先启动 arm 64 架构按需节点,帮助我们降低成本。
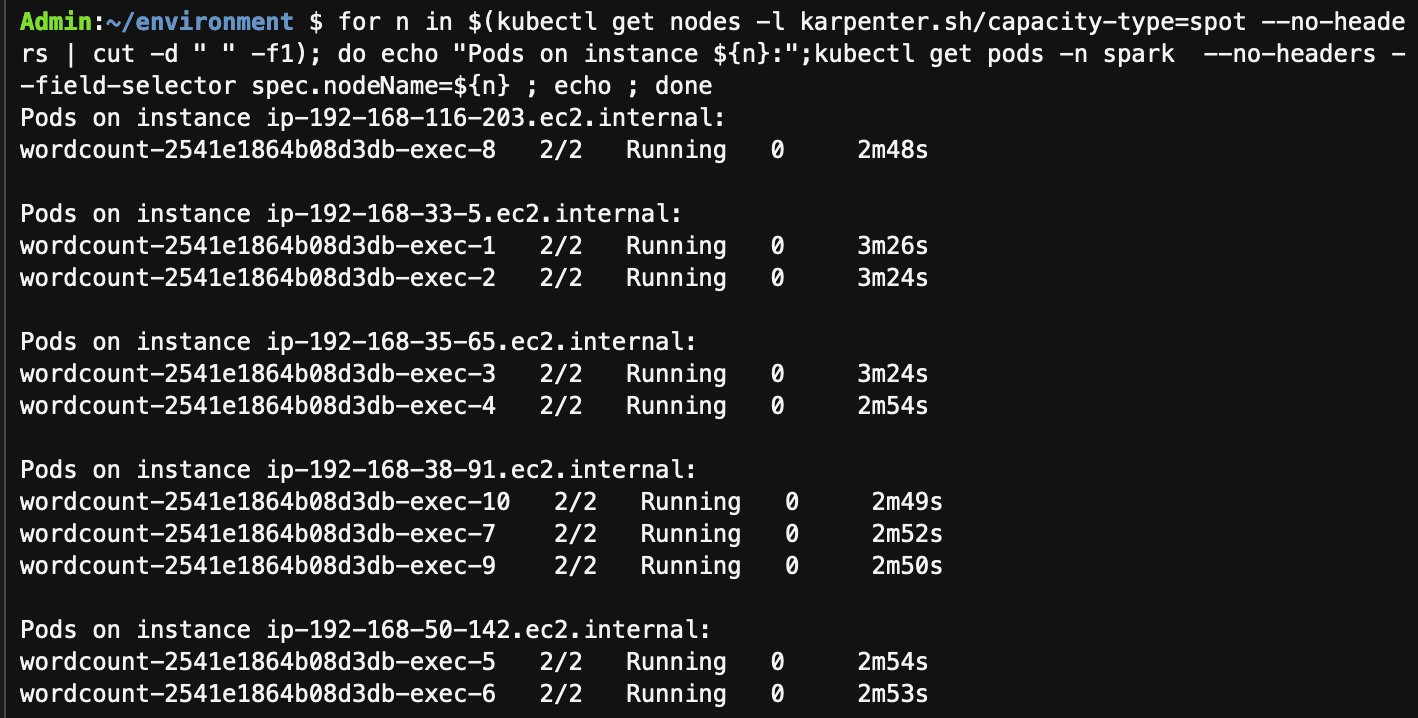
其次查看在 Spot 上的 pod:
for n in $(kubectl get nodes -l karpenter.sh/capacity-type=spot --no-headers | cut -d " " -f1); do echo "Pods on instance ${n}:";kubectl get pods -n spark --no-headers --field-selector spec.nodeName=${n} ; echo ; done

可以看到运行在 10 个 Spark Executor pod 均运行在 Spot 节点中,结合之前的命令结果已知这些 Spot 节点均为 arm64 架构。由此我们可以验证管理 Executor pod 的 Karpenter mixed Provisioner 的配置可以帮我们在多架构,多购买选项的情况下实现优先启动 arm 架构 Spot 实例,将 graviton 和 Spot 两个成本优化利器结合对成本进一步优化。
第六步:通过 karpenter controller log 查看 provisioner 如何启动节点用于部署 Spark Driver、Spark Executor pods
kubectl logs -f --tail=100 <karpenter-pod-name> -c controller -n karpenter
日志显示先是 Karpenter default Provisioner 启动了按需实例用来运行 Spark Driver pod。
2023-02-13T13:45:32.072Z INFO controller.provisioner found provisionable pod(s) {"commit": "5a7faa0-dirty", "pods": 1}
2023-02-13T13:45:32.072Z INFO controller.provisioner computed new node(s) to fit pod(s) {"commit": "5a7faa0-dirty", "newNodes": 1, "pods": 1}
2023-02-13T13:45:32.072Z INFO controller.provisioner launching node with 1 pods requesting {"cpu":"1155m","memory":"932Mi","pods":"5"} from types r6g.large, m6i.xlarge, r6g.xlarge, c7g.xlarge, r6i.large and 9 other(s) {"commit": "5a7faa0-dirty", "provisioner": "default"}
2023-02-13T13:45:32.318Z DEBUG controller.provisioner.cloudprovider discovered security groups {"commit": "5a7faa0-dirty", "provisioner": "default", "security-groups": ["sg-03c7be3011cfeaef7", "sg-06a14cfe67b1f8a7f"]}
2023-02-13T13:45:32.322Z DEBUG controller.provisioner.cloudprovider discovered kubernetes version {"commit": "5a7faa0-dirty", "provisioner": "default", "kubernetes-version": "1.24"}
2023-02-13T13:45:32.357Z DEBUG controller.provisioner.cloudprovider discovered new ami {"commit": "5a7faa0-dirty", "provisioner": "default", "ami": "ami-0c37c8c45fd4bedfb", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2-arm64/recommended/image_id"}
2023-02-13T13:45:32.381Z DEBUG controller.provisioner.cloudprovider discovered new ami {"commit": "5a7faa0-dirty", "provisioner": "default", "ami": "ami-06bf8e441ff8de6c6", "query": "/aws/service/eks/optimized-ami/1.24/amazon-linux-2/recommended/image_id"}
2023-02-13T13:45:32.514Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "5a7faa0-dirty", "provisioner": "default", "launch-template-name": "Karpenter-spot-graviton-karpenter-demo-13684190768216811295", "launch-template-id": "lt-05ffdefd14edb2a38"}
2023-02-13T13:45:32.698Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "5a7faa0-dirty", "provisioner": "default", "launch-template-name": "Karpenter-spot-graviton-karpenter-demo-8243106936454155178", "launch-template-id": "lt-0d228aa905c48784f"}
2023-02-13T13:45:35.277Z INFO controller.provisioner.cloudprovider launched new instance {"commit": "5a7faa0-dirty", "provisioner": "default", "id": "i-02bae816baa229214", "hostname": "ip-192-168-48-35.ec2.internal", "instance-type": "c6g.large", "zone": "us-east-1a", "capacity-type": "on-demand"}
2023-02-13T13:46:55.448Z INFO controller.provisioner found provisionable pod(s) {"commit": "5a7faa0-dirty", "pods": 1}
2023-02-13T13:46:55.448Z INFO controller.provisioner computed new node(s) to fit pod(s) {"commit": "5a7faa0-dirty", "newNodes": 1, "pods": 1}
2023-02-13T13:46:55.448Z INFO controller.provisioner launching node with 1 pods requesting {"cpu":"1155m","memory":"3187Mi","pods":"5"} from types m6g.xlarge, m6g.large, r6g.large, r6g.xlarge, c7g.xlarge and 1 other(s) {"commit": "5a7faa0-dirty", "provisioner": "default"}
2023-02-13T13:46:55.829Z DEBUG controller.provisioner.cloudprovider discovered launch template {"commit": "5a7faa0-dirty", "provisioner": "default", "launch-template-name": "Karpenter-spot-graviton-karpenter-demo-8243106936454155178"}
2023-02-13T13:46:57.885Z INFO controller.provisioner.cloudprovider launched new instance {"commit": "5a7faa0-dirty", "provisioner": "default", "id": "i-04c34e8421b9d623d", "hostname": "ip-192-168-103-144.ec2.internal", "instance-type": "m6g.large", "zone": "us-east-1a", "capacity-type": "on-demand"}
日志时间戳往下可以看到 Karpenter mixed Provisioner 连续起了 5 台 arm 架构 Spot实例(4 台 c6g.xlarge,1 台 m6g.xlarge),用来运行 10 个 Spark executor pods。
2023-02-13T13:48:38.132Z INFO controller.provisioner found provisionable pod(s) {"commit": "5a7faa0-dirty", "pods": 1}
2023-02-13T13:48:38.132Z INFO controller.provisioner computed new node(s) to fit pod(s) {"commit": "5a7faa0-dirty", "newNodes": 1, "pods": 1}
2023-02-13T13:48:38.132Z INFO controller.provisioner launching node with 1 pods requesting {"cpu":"1155m","memory":"3187Mi","pods":"5"} from types r6g.xlarge, m6g.xlarge, c6g.xlarge, c7g.xlarge, m6g.large and 1 other(s) {"commit": "5a7faa0-dirty", "provisioner": "mixed"}
2023-02-13T13:48:38.506Z DEBUG controller.provisioner.cloudprovider created launch template {"commit": "5a7faa0-dirty", "provisioner": "mixed", "launch-template-name": "Karpenter-spot-graviton-karpenter-demo-17922350669851481555", "launch-template-id": "lt-0409ef4bed1d0e0b2"}
2023-02-13T13:48:40.794Z INFO controller.provisioner.cloudprovider launched new instance {"commit": "5a7faa0-dirty", "provisioner": "mixed", "id": "i-052e57c1883a2d44f", "hostname": "ip-192-168-33-5.ec2.internal", "instance-type": "c6g.xlarge", "zone": "us-east-1a", "capacity-type": "spot"}
2023-02-13T13:48:42.277Z INFO controller.provisioner found provisionable pod(s) {"commit": "5a7faa0-dirty", "pods": 3}
2023-02-13T13:48:42.277Z INFO controller.provisioner computed new node(s) to fit pod(s) {"commit": "5a7faa0-dirty", "newNodes": 1, "pods": 1}
2023-02-13T13:48:42.278Z INFO controller.provisioner computed 1 unready node(s) will fit 2 pod(s) {"commit": "5a7faa0-dirty"}
2023-02-13T13:48:42.296Z INFO controller.provisioner launching node with 1 pods requesting {"cpu":"1155m","memory":"3187Mi","pods":"5"} from types r6g.xlarge, m6g.xlarge, c6g.xlarge, c7g.xlarge, m6g.large and 1 other(s) {"commit": "5a7faa0-dirty", "provisioner": "mixed"}
2023-02-13T13:48:44.664Z INFO controller.provisioner.cloudprovider launched new instance {"commit": "5a7faa0-dirty", "provisioner": "mixed", "id": "i-04ca2e8ffc001f591", "hostname": "ip-192-168-35-65.ec2.internal", "instance-type": "c6g.xlarge", "zone": "us-east-1a", "capacity-type": "spot"}
2023-02-13T13:49:11.718Z INFO controller.provisioner found provisionable pod(s) {"commit": "5a7faa0-dirty", "pods": 3}
2023-02-13T13:49:11.718Z INFO controller.provisioner computed new node(s) to fit pod(s) {"commit": "5a7faa0-dirty", "newNodes": 1, "pods": 1}
2023-02-13T13:49:11.718Z INFO controller.provisioner computed 1 unready node(s) will fit 2 pod(s) {"commit": "5a7faa0-dirty"}
2023-02-13T13:49:11.718Z INFO controller.provisioner launching node with 1 pods requesting {"cpu":"1155m","memory":"3187Mi","pods":"5"} from types m6g.xlarge, c6g.xlarge, c7g.xlarge, m6g.large, r6g.large and 1 other(s) {"commit": "5a7faa0-dirty", "provisioner": "mixed"}
2023-02-13T13:49:14.110Z INFO controller.provisioner.cloudprovider launched new instance {"commit": "5a7faa0-dirty", "provisioner": "mixed", "id": "i-0deafaa323a9f567b", "hostname": "ip-192-168-50-142.ec2.internal", "instance-type": "c6g.xlarge", "zone": "us-east-1a", "capacity-type": "spot"}
2023-02-13T13:49:15.997Z INFO controller.provisioner found provisionable pod(s) {"commit": "5a7faa0-dirty", "pods": 7}
2023-02-13T13:49:15.997Z INFO controller.provisioner computed new node(s) to fit pod(s) {"commit": "5a7faa0-dirty", "newNodes": 1, "pods": 3}
2023-02-13T13:49:15.997Z INFO controller.provisioner computed 2 unready node(s) will fit 4 pod(s) {"commit": "5a7faa0-dirty"}
2023-02-13T13:49:15.998Z INFO controller.provisioner launching node with 3 pods requesting {"cpu":"3155m","memory":"9321Mi","pods":"7"} from types m6g.xlarge, r6g.xlarge {"commit": "5a7faa0-dirty", "provisioner": "mixed"}
2023-02-13T13:49:18.256Z INFO controller.provisioner.cloudprovider launched new instance {"commit": "5a7faa0-dirty", "provisioner": "mixed", "id": "i-005131ed28bd0b622", "hostname": "ip-192-168-38-91.ec2.internal", "instance-type": "m6g.xlarge", "zone": "us-east-1a", "capacity-type": "spot"}
2023-02-13T13:49:21.689Z INFO controller.provisioner found provisionable pod(s) {"commit": "5a7faa0-dirty", "pods": 6}
2023-02-13T13:49:21.689Z INFO controller.provisioner computed new node(s) to fit pod(s) {"commit": "5a7faa0-dirty", "newNodes": 1, "pods": 1}
2023-02-13T13:49:21.689Z INFO controller.provisioner computed 2 unready node(s) will fit 5 pod(s) {"commit": "5a7faa0-dirty"}
2023-02-13T13:49:21.689Z INFO controller.provisioner launching node with 1 pods requesting {"cpu":"1155m","memory":"3187Mi","pods":"5"} from types m6g.large, r6g.large, r6g.xlarge, m6g.xlarge, c6g.xlarge and 1 other(s) {"commit": "5a7faa0-dirty", "provisioner": "mixed"}
2023-02-13T13:49:24.413Z INFO controller.provisioner.cloudprovider launched new instance {"commit": "5a7faa0-dirty", "provisioner": "mixed", "id": "i-086eec91ab88dffff", "hostname": "ip-192-168-116-203.ec2.internal", "instance-type": "c6g.xlarge", "zone": "us-east-1a", "capacity-type": "spot"}

从 EMR console 选中任务点击 view logs,可以看到 executor pods 启动过程,EMR job 成功完成。
小结:
在 karpenter 日志中可以看到提交 EMR 任务运行后,先是出现了 pending pod(spark driver pod),然后 karpenter default provisioner 根据配置优先启动了arm 架构按需实例;在由 Spark Driver 管理启动的 Spark Executor pod 出现后,karpenter mixed provisioner 根据配置优先启动了 arm 架构 Spot 实例。
由此我们验证该方案在 EMR 任务提交场景下可以控制 spark driver,spark executor 所在节点的启动优先级从而优化成本。
2. 总结
在系列 blog(二) 里,我们完成了“基于 EMR on EKS 的 Spark 集群通过 Karpenter、Spot、Graviton 实现成本优化”方案的有效性测试,通过 Karpenter Provsioner 的设计引入 Spot 和 Graviton,结合 node affinity 实现了对实例启动优先级的控制,从而有效降低成本。
- 对 Spark Driver Pods 启动优先级为:arm 架构按需实例 → amd 架构按需实例
- 对 Spark Executor Pods 启动优先级为:arm 架构 Spot 实例→ amd 架构 Spot 实例→ arm 架构按需实例 → amd 架构按需实例
针对这一具体场景,我们也总结了一些成本优化的最佳实践:
(1)Spot 用于 Spark executors,按需实例用于 Spark driver
(2)使用多架构或迁移任务到 Graviton 实例
(3)利用 Karpenter 同时管理 Spot 和 On-demand,实现 Spot 容量不足时自动启动 On-demand,降低运维成本
(4)启用 Spark DRA 功能扩缩 executor 的数量
最后建议您先采用真实业务数据测试,在各项参数调优后性能指标比如任务处理时长等达到您的预期后,再在生产环节中实际应用参考本方案。
本篇作者