亚马逊AWS官方博客
基于 EMR on EKS 的 Spark 集群通过 Karpenter、Spot、Graviton 实现成本优化系列 Blog(一):方案架构、设计原理和基础配置
1.背景
成本优化近年来已经成为云上客户越发重点关注的问题。容器场景的成本优化的需求量尤其突出。现实中客户在做容器场景下的成本优化时经常会遇到的痛点,比如:
- 如何引入 Graviton,Spot 这两种 AWS 成本优化利器?
- 在启动 Spot 时是否可以指定 Spot 实例的启动优先级?
- 部署在 Spot 上的 pod 在 Spot 中断时如何优雅退出?
- 是否有方法模拟 Spot 中断验证当前应用程序的可用性?
根据实践我们总结了容器场景下成本优化的三板斧:Amazon 成本优化利器 Spot, Graviton 和 Kubernetes 节点弹性伸缩开源组件 Karpenter。
在整个系列博客中我们会以大数据分析业务场景为示例,利用 Karpenter + Spot + Graviton,通过控制实例启动的优先级达到成本优化的目的。
第一部分:构建基于 EMR on EKS 的 Spark 集群的成本优化解决方案。
第二部分:有效性测试 — 验证该方案下实例启动的优先级和成本优化的有效性,并整理出成本优化最佳实践。
第三部分:可靠性测试 — 利用 AWS Fault Injection Simulator(FIS)全托管服务模拟 Spot 中断故障,测试方案的可靠性,并且总结出使用 Spot 的最佳实践。
2.架构描述
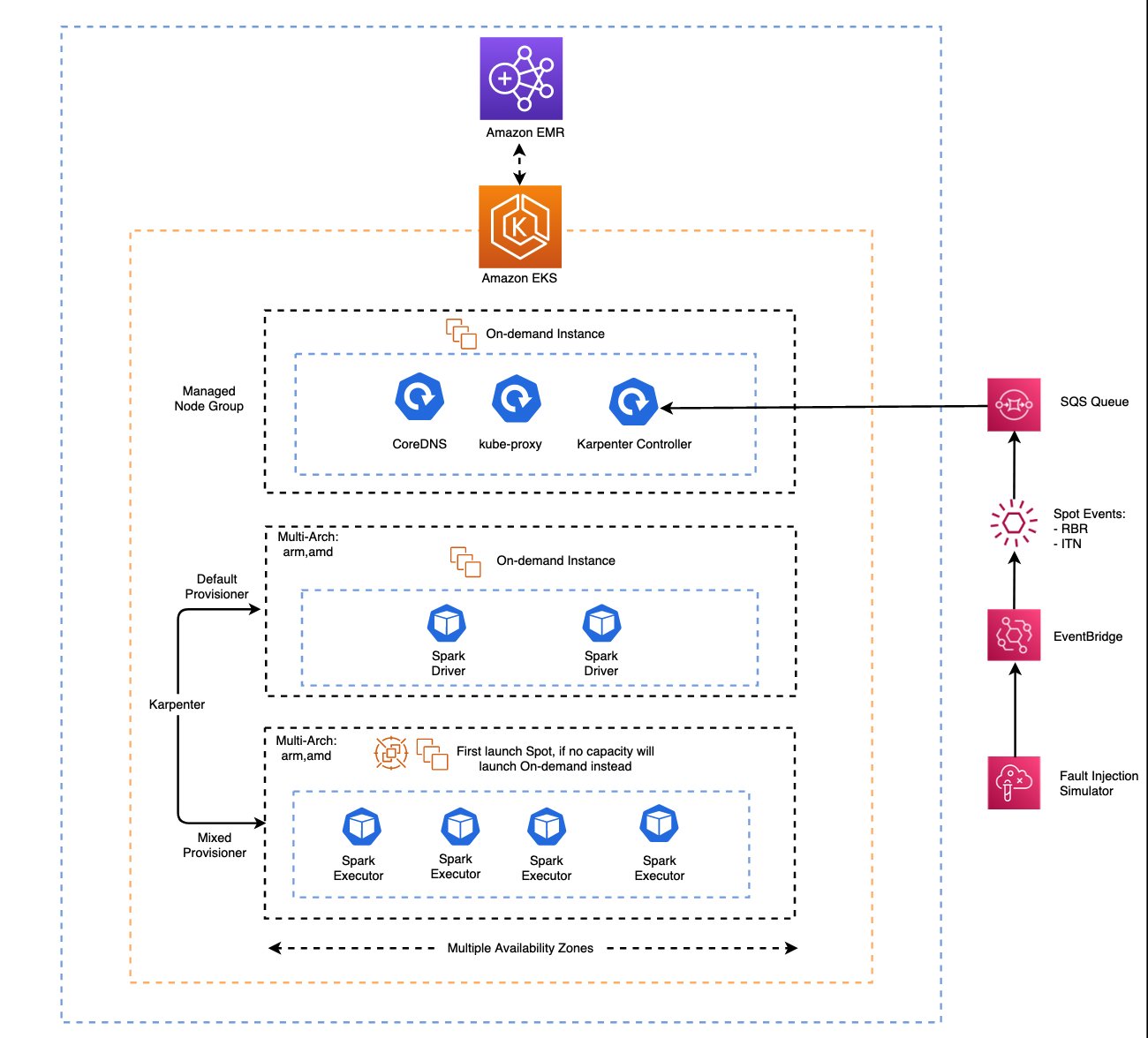
首先我们会创建一个 EKS 集群和一个托管节点组,用来部署系统管理组件(比如 CoreDNS,Karpenter Controller)。
其次我们会使用 Karpenter 配置两个 Provisioner,分别管理 Spark Driver pods 和 Spark Executor pods 所需的实例;不可中断的 Spark Driver pods 放置在按需实例上,可中断的 Spark Executor pods 放置在 Spot 或者按需实例上。考虑到同等机型大小(vCPU,memory)的前提下基于 ARM 架构的实例价格低于基于 AMD 架构的实例,我们在 Provisioner 中配置多架构(arm, amd),并且在 pod template 中定义的亲和性 nodeAffinity 设置优先启动基于 ARM 架构的实例,达到成本的进一步优化。
由此通过控制实例启动的优先级,可以达到成本优化的目的:
- 对 Spark Driver Pods 启动优先级为:arm 架构按需实例 → amd 架构按需实例
- 对 Spark Executor Pods 启动优先级为:arm 架构 Spot 实例→ amd 架构 Spot 实例→ arm 架构按需实例 → amd 架构按需实例
接下来我们将在 EKS 集群上部署 EMR on EKS 的虚拟集群,创建 Spark Driver 和 Spark Executor pod template 并将任务日志发送到 Cloudwatch,S3 中。
最后我们在整体架构设计中加入 AWS Fault Injection Simulator(FIS)全托管服务。FIS 模拟 Spot 中断故障,帮助我们验证该方案下应用的可靠性。
3.部署
整体的部署过程如下:

实验环境版本:
- Region: us-east-1
- EKS: 1.24
- Karpenter: 0.23.0
- EMR on EKS: 6.8.0
- Spark: 3.3.0-amzn-0
3.1 配置 Cloud9
第一步:创建 Cloud9 环境
(1)登录到 AWS Cloud9 控制台,选择 Create environment(创建环境) 按钮。命名为比如 EMRonEKSGravitonSpot,选择 Next step(下一步)。
(2)在 Configure setting(配置设置)页面,对于 Environment type(环境类型),选择为环境创建新的 EC2 实例(直接访问)。保留 Instance type(实例类型) 的默认选项。
(3)为 Cost-saving setting(节省成本设置)选择 After four hours,可以避免 Cloud9 示例在空闲一小段时间的情况就被关闭。
(4)设置 Tags,Key 为 env,Value 为 cloud9,便于识别 Cloud9 环境的资源。
第二步:等 Cloud9 环境建好之后,完成以下步骤更新环境为实验做准备
(1)跳转到 IAM 控制台,选择 Roles, 然后选择 Create role。
(2)对于 Select trusted entity(选择可信实体),选择 AWS service(AWS 服务),再选择 EC2。选择 Next: Permissions。
(3)确保 AdministratorAccess 策略选上,然后选择下一步 Next: Tags,继续下一步 Next: Review。
(4)命名角色名 Cloud9-Admin-Role,然后创建 Role。
(5)回到 EC2 控制台,找到 Cloud9 示例,选择该实例,按照 Actions -> Security -> Modify IAM role 步骤,选择新创建的 Cloud9-Admin-Role,然后点击 Save 保存修改。
(6)回到 Cloud9 控制台,点击右上角 Open in Cloud9 打开 IDE 环境。在 IDE 环境选择右上角齿轮,在新页面上往下划拉到 AWS Settings 然后到 AWS Resources,取消临时凭证的使用,如下图。

3.2 创建 EKS 集群
第一步:将集群名称、区域、ID 等信息配置到环境变量,以便后续命令行操作时使用:
第二步:准备集群的配置文件以供 eksctl 工具使用:
第三步:通过以上配置文件创建 EKS 集群:
eksctl 会按依次创建集群和托管节点组,在 managedNodeGroups 部分设置了使用 m5 机型配置并建立托管节点组。
第四步:配置 Endpoint 环境变量以供后续安装 Karpenter 使用
第五步:查看节点是否都已经处于 ready 状态

将 Cluster Endpoint 配置到环境变量
3.3 安装 Karpenter
创建该测试环境时 Karpenter 版本已经更新到 v0.23.0。请参考 Karpenter 官网 v0.23.0 安装指南,完成从 Create the Karpenter Infrastructure and IAM Roles 开始到 Install Karpenter Helm Chart 的步骤。
检查 Karpenter Controller 是否已经正常运行
注意:自 Karpenter v0.16.0 版本开始 Controller 有两个 replica,一个为 Leader,另一个为 standby。

3.4 配置多个 Provisioners
第一步:配置 Provisioner 管理 Spark Driver
Spark Driver 负责调度管理 Spark Executor,如果 Driver 出现中断整个任务都会失败,因此我们需要将 Spark Driver 部署在按需实例上。因此创建第一个 Provisioner default 只启动按需实例,用于部署 Spark Executor Pod。为了提高可用性,设置了多个不同实例类型和多个不同可用区。
同时,为了降低成本:
- 设置多架构(arm64,amd64)之后,结合 pod 模版设置优先启动低价格的 arm64 架构实例。
- Karpenter 对于按需实例使用的分配策略是 lowest-price,启动按需实例时会优先选择最便宜的机型启动。
首先创建第一个 Provisioner default。只启动按需实例,用于部署 SparkExecutor Pod。
第二步:配置 Provisioner 管理 Spark Executor
Spot Executor 由 Spark Driver 启动,真正负责运行任务。Spot Executor 即使被中断退出,还可以由 Driver 启动新的 Executor 继续任务处理,因此成本优化时可以将 Spot Exector 放在 Spot 实例上。
为了降低成本:
- 设置多架构(arm64,amd64)之后,结合 pod template 设置优先启动低价格的 arm64 架构实例。
- 自 19.0 版本开始,Karpenter 对于 Spot 实例使用的分配策略更新为 price-capacity-optimized,可以帮助我们在优化容量的前提下进一步降低成本。
创建第二个 Provisioner mixed 用于部署 Spot Executor Pod:
在 karpenter.sh/capacity-type 中配置了 Spot 和 On-demand 两种类型。 在karpenter 选择资源时,会优先选择 Spot 实例类型,当 Spot 实例容量不足的时候,会尝试启动 On-demand 实例类型。
3.5 创建 EMR on EKS 虚拟集群
在 EKS 上运行 Amazon EMR 提供的优化的 Spark 运行时有几个优点,例如性能提高 3 倍、这些作业的完全托管生命周期、内置监控和日志记录功能、与 Kubernetes 安全集成等。由于 Kubernetes 可以天然运行 Spark 作业,因此,如果您使用多租户 EKS 环境(与其他微服务共享),则与基于 EC2 需要几分钟完成部署相比,您的 Spark 作业将在几秒钟内完成部署。
第一步:创建命名空间 spark 和 RBAC permission
第二步:将 IAM 和集群 OIDC 关联
第三步:为 EMR job 创建 job execution role
第四步:为 EMR job execution role 添加 IAM 策略使其有权限将日志写入 S3 和 Cloudwatch 中
第五步:更新 EMR job execution role 的信任策略
在 EMR job execution role 和 EMR 托管式服务账户身份之间创建信任关系:
第六步:创建 EMR 虚拟集群并注册到 EKS 集群中
将 EMR 命名为 emr-on-eks-graviton-spot:

注意:记录下 EMR cluster ID,后面会用到。
第七步:验证 EKS cluster with EMR 创建成功
3.6 创建 EMR on EKS 多架构容器镜像
因为 Amazon EMR on EKS 本身支持适用于 Amazon Elastic Container Registry(Amazon ECR)的多架构容器镜像,既支持基于 Graviton(arm64 架构)的 EC2 实例,也支持非基于 Graviton(amd64架构)的 EC2 实例。两种架构的镜像都存储在 Amazon ECR 中的相同镜像存储库中。
为简化实验步骤,本次测试我将使用默认的 Amazon EMR on EKS 多架构镜像。您可以参考官方文档创建自定义多架构容器镜像。
3.7 创建 Spark Driver,Spark Executor 的 Pod 模版实现更精细的控制
从 Amazon EMR 版本 5.33.0 或 6.3.0 开始,Amazon EMR on EKS 支持 Spark 的 Pod 模板功能。通过将 Pod 模板与 Amazon EMR on EKS 结合使用,来定义如何在共享 EKS 集群上运行 Spark 任务,从而节省成本并提高资源利用率和性能。
第一步:创建一个 S3 桶用来存放 Pod template,sample script 还有日志。
第二步:创建 spark_driver_pod_template.yaml
- 通过在 Pod 内配置 nodeSelector 部署 Spark Driver pod 在 provisioner ‘default’创建的节点上。
- 通过在 Pod 内配置 nodeAffinity,优先部署 Spark Driver pod 到 arm64 架构的节点上。
第三步:创建 spark_executor_pod_template.yaml
- 通过在 Pod 内配置 nodeSelector 部署 Spark Executor pod 在 provisioner mixed 创建的节点上。
- 通过在 Pod 内配置 tolerations 进一步约束 provisioner mixed 创建的节点(带有 taints spot)只能运行 spark executor pod。
- 通过在 Pod 内配置 nodeAffinity,优先部署 Spark Executor 到 arm64 架构的节点上。
第四步:上传两个 pod template 到提前创建好的 S3 桶中 pod_templates 下
3.8 准备 EMR Spark Job 的测试应用脚本和数据集
这里使用 Amazon EMR 官方示例中的 wordcount.py 程序。
第一步 通过以下命令下载
打开 wordcount.py 程序,找到 text_file 行。此处是 wordcount.py 的数据集。
第二步:使用以下 shell script 扩大数据集,并上传新数据集到之前创建的 S3 桶里
输出结果类似下图:

第三步:编辑 workcount.py 并替换 wordcount.py 程序中的 text_file 行中数据集的地址为刚上传的 S3 桶位置
第四步:上传更新后的 wordcount.py 到 S3 桶中
4. 总结
至此,以 EMR on EKS 大数据分析业务场景为例的 Spark Cluster 的成本优化方案架构和测试环境已经搭建完毕。
该方案架构中我们巧用 Karpenter、Spot 和 Graviton 三板斧最大程度的优化基础架构的成本:
- 通过在 Karpenter Provsioner 中使用多种购买选项引入 Spot,将可中断的 Spark Executor pods 优先放置在 Spot;
- 通过在 Karpenter Provsioner 中使用多架构引入 Graviton 实例,且在 pod template 中定义的亲和性 nodeAffinity 设置优先启动基于 ARM 架构的实例。
接下来我们可以开始第二部分:有效性测试和第三部分:可靠性测试,对方案进行验证。