亚马逊AWS官方博客
OpenClaw 在电商平台的应用场景探索
摘要:当 AI 助手不再只是”聊天机器人”,而是一个可以用 Markdown 文档扩展skill能力、嵌入多种工作渠道、主动推送运营洞察的智能网关——我们用 OpenClaw 在电商卖家场景做了一次从 0 到 1 的实验,讨论电商平台以大规模SaaS部署OpenClaw提供卖家助手的场景下,能够提供的开发便利、使用体验优势、部署模式和成本评估,以及使用体验
目录
1. 当前电商卖家助手的困境
打开任何一个主流电商平台的卖家后台,你几乎都能找到一个”智能助手”入口。它们通常基于多 Agent 架构,配合 Function Calling 机制,提供订单查询、数据看板、操作指引等功能。这类助手在过去两年取得了不错的进展,但随着卖家对 AI 的期望不断提高,一些结构性的问题逐渐显现。
- 功能由平台定义,卖家只能被动接受
传统卖家助手的每一个能力,背后都对应着工程团队开发的一个 Agent 或 Function。想让助手支持”按地域看退货率”?需要提需求、排期、开发、测试、发版。这个过程通常以周为单位,有时甚至更长。
对于平台来说,这意味着需要预判所有卖家可能的查询需求,提前开发好对应功能。而电商运营的实际情况是:不同品类、不同规模的卖家,关注的数据维度差异极大。一个鞋类卖家关心的尺码退货率,和一个食品卖家关心的保质期临期预警,很难用同一套预定义功能覆盖。
- 渠道被锁定在平台内部
目前大多数卖家助手只能在平台自己的 App 或网页后台中使用。但卖家的日常工作并不只在电商后台——他们在飞书群里讨论运营策略,在企业微信里沟通客服问题,在 Slack 里和海外团队协作。
当卖家想查一个销售数据时,需要:切换到电商 App → 找到助手入口 → 输入问题 → 看到回答 → 再切回工作场景。这个上下文切换看似简单,但在高频运营场景下,摩擦成本是显著的。
- 被动响应,缺乏主动触达
现有卖家助手几乎都是”你问我答”模式。库存快断货了?助手不会主动告诉你。昨天退货率异常飙升?你不去问就不知道。
对于每天需要盯几十个数据指标的运营人员来说,一个只会被动等提问的助手,实际使用频率会迅速衰减。
- 本质:一种”编译型”的能力构建方式
如果做一个类比,传统卖家助手的能力扩展方式类似”编译型语言”:
需求 → 工程师编码 → 定义 Function Schema → 测试 → 编译打包 → 部署上线
每一个新功能都需要经过完整的开发流水线,才能到达用户手中。
而电商运营场景的数据查询需求是千变万化的——卖家今天想看”本周复购客户的客单价趋势”,明天可能想看”滞销品的库存周转天数”。这种灵活多变的需求,用”编译型”的方式去响应,注定会有一个很长的供需错配期。
那有没有一种”解释型”的方式——写了就能用,改了就生效,不需要工程团队介入?
2. OpenClaw:一种新的卖家助手构建范式
OpenClaw 是一个开源的 AI Gateway 项目。和常见的 chatbot 框架不同,OpenClaw 的设计理念是 “Gateway as Runtime”——把 HTTP 服务、WebSocket 通信、AI Agent 引擎、Session 管理、Channel 集成、定时任务调度全部打包到一个进程中。
2.1 单实例完整架构
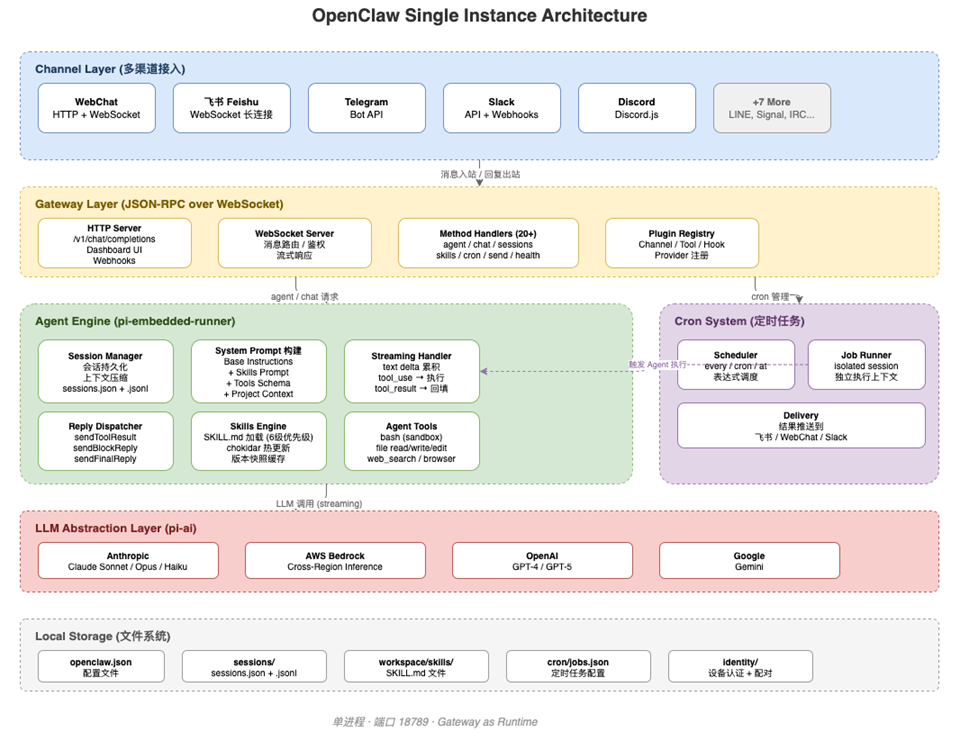 |
一个 OpenClaw 实例是一个单进程(node openclaw.mjs gateway,端口 18789),内含五个层次:
|
层次 |
职责 |
关键特征 |
|
Channel Layer |
多渠道接入 |
12+ 渠道(飞书、Telegram、Slack、Discord、WebChat 等),Plugin 机制,共享同一套 AI 引擎 |
|
Gateway Layer |
请求网关 |
JSON-RPC over WebSocket,20+ method handler,兼容 OpenAI /v1/chat/completions |
|
Agent Engine |
AI 推理引擎 |
流式执行:session lock → System Prompt 构建 → LLM streaming → tool_use 循环 → 保存 |
|
Cron System |
定时任务 |
every / cron / at 三种模式,独立 session 执行,结果推送到任意 Channel |
|
Local Storage |
文件持久化 |
openclaw.json + sessions/ + workspace/skills/ + cron/jobs.json,无外部依赖 |
2.2 一条消息的完整旅程(以飞书渠道为例)
上面的架构表格是静态的”有什么”,下面我们通过一张泳道序列图展示动态的”怎么跑”——以飞书接入为例,完整追踪从应用创建到用户收到 AI 回复的全过程。
图中将整个流程分为三个阶段,涉及五个参与方(管理员、飞书开放平台、飞书服务器、OpenClaw 实例、LLM)。以下是每个阶段的要点:
阶段一:配置(①-⑤)
管理员在飞书开放平台创建企业自建应用,获取 App ID 和 App Secret,配置所需权限(如获取私聊/群聊消息及图片文字资源,获取群聊的@事件,获取群信息/发送方senderOpenId等)并启用 Bot 能力。然后将凭证写入 OpenClaw 的 openclaw.json(channels.feishu.accounts),启动实例。
阶段二:启动连接(⑥-⑬)
OpenClaw 启动后读取配置,发现openclaw.json配置文件中飞书渠道已启用,依次完成:
- 调用飞书 API(/bot/v3/info)根据App ID获取飞书 bot 的 open_id(后续用于后续判断群聊中是否被 @)
- 创建 EventDispatcher,将 im.message.receive_v1 事件绑定到 handleFeishuMessage() 回调,以便收到飞书消息后执行消息处理逻辑
- 主动向飞书服务器发起出站 WebSocket 长连接——这是架构中最关键的设计:OpenClaw 不需要暴露公网端口,不需要配置 Webhook URL,所有通信通过这条出站连接完成。连接建立后,管理员回到飞书开放平台配置事件订阅并发布应用。注意顺序:事件订阅必须在 WebSocket 连接成功之后,否则飞书会报错。
阶段三:消息处理(⑭-㉔)
用户在飞书中发消息(或群聊 @bot)→ 飞书服务器通过已建立的 WebSocket 推送事件到 OpenClaw → OpenClaw 内部经过四步流水线处理:
- EventDispatcher 路由:解析消息内容(text / image / file)
- Policy 检查:根据openclaw.json中配置的dmPolicy(私聊策略)、groupPolicy(群聊策略)、requireMention(是否需要 @)以决定对消息的响应策略。
- Routing 解析:确定目标 agentId 和 sessionKey(配置 per-peer 模式时,不同用户的 senderOpenId 自动隔离到独立 session)。这一特性在电商场景中有实用价值,详情参见2.3章节
- Session + Prompt 构建:获取 session lock,加载历史上下文,编译 System Prompt(Base Instructions + Skills + Tools)
然后调用 LLM 获取流式响应,保存 session,最后通过飞书 REST API 将回复发送给用户。
2.3 Routing与多Agent&多渠道的隔离
上面阶段三中的”Routing 解析”看似简单的一步,实际上是 OpenClaw 支持一个实例运行多个 Agent 的核心机制。
这一机制在电商场景中具有实际应用价值: 一个电商卖家团队的日常沟通通常分散在不同群组和场景中:销售群讨论推广策略、售后群处理退款投诉、运营群关注库存和物流。如果只有一个 Agent,要么它的 Skill 集合膨胀到难以维护(prompt 过长导致精度下降),要么所有群共享同一套能力、无法做差异化。多 Agent 的价值在于:让不同业务角色拥有专属的 AI 助手,各自只加载必要的 Skills、人设和对话历史,互不干扰。例如”销售助手”只挂载销售查询和商品分析 Skill,”售后客服”只挂载退款处理和工单查询 Skill——各司其职,互不打扰。
五个核心概念:
|
概念 |
含义 |
示例 |
|
Peer |
标识消息来源 |
群聊:chatId oc_abc111;私聊:senderOpenId ou_xxx |
|
Binding |
路由规则,标识信息来源与AgentID的路由关系 |
channel=feishu + peer=group:oc_abc111 → agentId: sales |
|
agentId |
Agent 的唯一标识,代表拥有不同人格和技能的智能体 |
“sales” / “support” / “main”(默认) |
|
Workspace |
每个 Agent 独立的工作目录,存放专属 SKILL.md和人格配置 |
workspace-sales/skills/sales-query.SKILL.md |
|
sessionKey |
由 agentId + channel + peer 构造,隔离对话历史 |
agent:sales:feishu:group:oc_abc111 |
Binding 匹配优先级(从高到低):精确 Peer > Parent Peer > Guild+Roles > Guild > Team > Account > Channel > Default。大多数场景只用第一级(精确匹配群或用户)和最后一级(默认兜底)。
Workspace 目录结构(每个 Agent 独立):
Workspace = Agent 的”完整人格”。每个 Agent 不仅有专属的 Skills,还有独立的人格(SOUL.md)、行为规则(AGENTS.md)、身份(IDENTITY.md)和用户记忆(USER.md)。例如”销售助手”的 SOUL.md 可以定义热情积极的语气,而”售后客服”的 SOUL.md 则定义耐心专业的风格。USER.md 尤其值得注意——它是 Agent 在与用户交互过程中逐步积累的个性化记忆,每个 Agent 各自维护独立的 USER.md,不会互相串扰。
不同 Agent 加载各自 workspace 下的全套 bootstrap 文件和 Skills,编译成不同的 System Prompt,因此具备不同的能力和人格。每个Agent后端的Agent Engine 是同一个,使用相同的流式执行引擎,不同的输入(Skills、Bootstrap 文件、Model、Session 历史)。
配置示例(openclaw.json):
3. OpenClaw 作为电商卖家助手的价值
理解了 OpenClaw 的架构之后,让我们看看它如何解决电商卖家的实际痛点。
3.1 统一数据入口
传统模式下,卖家要查不同维度的数据,可能需要在多个页面和工具之间切换。OpenClaw 提供了一个自然语言统一入口——一个对话窗口,覆盖销售、库存、客户、商品所有数据。
对话流程:
卖家:“今天卖了多少?“ → OpenClaw 匹配到 sales-query Skill → 执行: curl $JD_API_ENDPOINT/v1/orders/stats | jq … → API 返回: {“total_orders”: 23, “total_amount”: 528000, …} → AI 格式化回答: “今日共 23 笔订单,销售额 ¥5,280.00,较昨日增长 12.3%”
我们在 PoC 中构建了4 个平台级 Skill 覆盖了卖家日常最高频的数据查询:
|
Skill |
覆盖场景 |
|
sales-query |
销售概况、订单列表、退货分析、趋势图 |
|
product-ranking |
热销榜、滞销品、新品表现、品类分布 |
|
inventory-alert |
低库存预警、断货提醒、补货建议 |
|
customer-insight |
客户概览、新客/回头客分析、地域分布 |
3.2 Skill 构建范式的变革
传统方式(”编译型”):
产品经理提需求 → 工程师写代码 → 定义 Function Schema → CR → 测试 → 发版 周期:1-4 周 参与者:工程师
Skill 方式(”解释型”):
运营人员写 SKILL.md → 放到 skills 目录 → 立即生效 周期:分钟级 参与者:产品经理 / 运营人员(会写 curl + jq 即可)
这个范式变革意味着:传统助手能做的(查订单、看物流、处理退款流程),可以通过 Skill 覆盖;传统助手做不到的(自定义维度的数据分析、跨数据源关联查询),也可以通过 Skill 快速实现。
Skill 的能力边界不是由平台预定义的,而是由 API 的能力决定的——只要有 API,就可以封装成 Skill。
3.3 多渠道嵌入工作流
OpenClaw 的 Channel Plugin 系统让同一套 AI 能力可以嵌入多种工作场景:
- WebChat:嵌入卖家管理后台,浏览器中直接使用
- 飞书:卖家在飞书工作群里直接 @机器人 查数据
- Slack:海外团队在 Slack 中获取运营报告
- Telegram / Discord:跨境电商团队使用
关键是:不同渠道背后共享同一个 Agent 引擎和同一套 Skills。卖家在飞书里问”今天卖了多少”和在 WebChat 里问同样的问题,得到的数据来自同一个 API、经过同一套 Skill 处理。
在飞书集成中,OpenClaw 使用 WebSocket 长连接模式连接飞书平台,不需要公网入站端口。每个用户的 DM 对话自动隔离为独立的 session。
3.4 主动通知:从”你问我答”到”AI 主动找你”
OpenClaw 内置的 Cron 系统让 AI 从被动响应变为主动监控。
实际配置示例——每 30 分钟检查库存预警:
配置后,OpenClaw 每 30 分钟在一个独立 session 中执行 inventory-alert Skill,如果发现异常,自动将结果推送到卖家最近使用的渠道(飞书或 WebChat)。
更多定时场景:
- 每日早报 (cron: “0 8 * * *”):昨日销售概况 + 异常订单 + 补货提醒
- 实时监控 (every: “15m”):大额退款告警
- 周报 (cron: “0 9 * * 1”):本周 TOP 10 热销品 + 滞销品分析
3.5 多 Agent × 多 Channel:让专业的人做专业的事
前面 讲了多渠道和多 Agent 架构。当这两者结合时,才真正释放出电商场景的价值。
一个典型的电商卖家团队,日常沟通天然分散在不同群组中:
|
群 / 渠道 |
绑定 Agent |
加载的 Skills |
人格 (SOUL.md) |
|
飞书 – 销售运营群 |
sales |
销售查询、商品排名、趋势分析 |
数据驱动、简洁直接 |
|
飞书 – 售后客服群 |
support |
退款处理、工单查询、客户投诉 |
耐心专业、安抚为主 |
|
飞书 – 私聊 |
main(默认) |
全部 Skills |
通用助手 |
|
WebChat – 卖家后台 |
main |
全部 Skills |
通用助手 |
|
Slack – 海外运营 |
overseas |
销售查询(英文)、跨境物流 |
英文沟通 |
这意味着:
1. 各群各司其职:销售群只出现销售相关的能力,不会有人在销售群里触发退款流程。每个 Agent 的 System Prompt 只包含自己的 Skills,prompt 更短、精度更高。
2. 人格隔离:售后客服的 SOUL.md 写着”语气温和、优先安抚情绪”,销售助手的 SOUL.md 写着”数据优先、结论先行”——同一个引擎,不同的沟通风格。
3. 会话历史隔离:销售群讨论的促销策略不会泄漏到售后群。配合 dmScope: per-peer,私聊场景下每个用户也有独立的对话记忆。
4. 跨渠道统一体验:通过 identityLinks 配置身份映射,同一个运营人员在飞书和 Slack 上的对话历史可以打通——在飞书问过的数据,切到 Slack 不用再问一遍。
整个多 Agent × 多 Channel 的配置完全通过 openclaw.json 声明式完成,不需要写代码、不需要部署多个实例。一个 实例 内运行一套 Agent Engine,通过 Routing + Binding 机制把不同来源的消息分发到对应的 Agent Workspace。
4. 从单机版个人助手到SaaS规模部署的挑战与应对
从一个单实例的 PoC 到可以服务成百上千商家的生产系统,需要解决一系列工程挑战。
4.1 多租户隔离
OpenClaw 的 “Gateway as Runtime” 架构意味着一个进程就是一个完整的功能栈。这天然适合 per-tenant 独占模式——每个商家一个 Pod,物理隔离。
|
隔离维度 |
实现方式 |
|
数据隔离 |
EFS Access Point per tenant,每个商家数据在独立的文件系统路径下 |
|
计算隔离 |
独立 Pod(独立进程),一个商家的大量请求不影响其他商家 |
|
网络隔离 |
Envoy Gateway 按路径前缀路由,每个商家的流量只到达自己的 Pod |
|
Session 隔离 |
OpenClaw 内部按 senderOpenId 分配独立 session |
挑战:AWS EFS 单个文件系统限制 1000 个 Access Point。超过 1000 个商家需要创建多个 EFS 文件系统并配置多个 StorageClass。这是一个已知的架构上限,需要在规模化阶段提前规划。
4.2 成本控制
每次用户查询都涉及 LLM 调用,成本是最现实的挑战。
PoC 实测数据:
|
指标 |
数值 |
|
简单查询(如”今天卖了多少”) |
~18K input tokens + 1.7K output tokens ≈ $0.08 |
|
复杂分析(如”本周退货趋势 + 原因分析”) |
~22K input + 3K output ≈ $0.12 |
|
基础设施(100 商家) |
EKS + EFS 分摊 ≈ $17.74/商家/月 |
优化手段:
- Prompt Cache:Skills 内容和 system prompt 在会话中高度重复,Bedrock 的 Prompt Caching 可以节省 80-90% 的 input token 费用
- 模型分级:简单的数据查询(”今天卖了多少”)用 Claude Haiku(成本约为 Sonnet 的 1/10),复杂的多步分析才用 Sonnet
- Savings Plans:EC2 和 Bedrock 的预留容量计划,进一步降低 30-40%
优化后目标:约 $45/商家/月(中等使用频率)。
4.3 与现有系统共存
OpenClaw PoC 使用 Mock API 模拟电商数据(12 个 SKU、50 个客户、20+ 个 API 端点)。进入生产环境需要对接真实的平台 API。
关键考量:
- API 认证与权限:每个商家的 Pod 只能通过 API Token 访问自己的数据,Token 通过 Kubernetes Secret 注入
- 渐进式接入:先从只读的数据查询场景切入(销售、库存、客户分析),验证准确性和稳定性后,再逐步覆盖操作类场景(批量改价、库存调拨)
- API 网关适配:不同平台的 API 风格不同,可以通过 Skill 层面适配,不需要修改 OpenClaw 本身
4.4 安全边界
Skill 通过 bash 工具执行 curl 命令,这给了 AI 很大的灵活性,但也带来安全考量。
已有的安全机制:
- Sandbox 模式:OpenClaw 内置 sandbox 限制 bash 工具的可访问路径,只允许操作 workspace 目录
- 环境变量注入:API endpoint 通过环境变量($JD_API_ENDPOINT)传入,凭证不暴露给 AI 模型
- 危险命令防护:OpenClaw 维护了危险环境变量黑名单(LD_PRELOAD、NODE_OPTIONS 等),防止注入攻击
需要额外考虑的:
- 写操作确认:当 Skill 涉及核心交易操作(退款、改价、库存调拨),AI 的”解释型”执行模式需要引入人工确认步骤——AI 生成操作方案,人工审批后执行
- 操作审计:所有 Skill 执行记录保存在 session 文件中(.jsonl 格式),可用于事后审计
- Skill 来源管控:生产环境应限制 Skill 的来源——平台级 Skill 由平台团队审核发布,商家自定义 Skill 只能调用白名单 API
5. 从单机到平台:多租户实践
前面三章描述的都是一个 OpenClaw 实例服务一个卖家的场景。当我们要把它变成一个平台级服务——同时为成百上千个商家提供 AI 助手——需要先回答一系列问题。
5.1 需要解决的问题
1. 多租户隔离:不同商家的数据、对话、Skills 必须完全隔离。具体涉及三个层面:
- 接入隔离:商家 A 的请求不能路由到商家 B 的实例
- 计算隔离:商家 A 的高频查询不能导致商家 B 的响应变慢
- 存储隔离:Sessions、Skills、配置文件、Cron 任务必须物理分离
2. 部署成本:规模化后每个商家的部署成本如何?
3. 真实 API 对接:PoC 使用 Mock API,生产环境需要对接真实的电商平台 API——每个商家的 API Token 不同,权限范围不同
4. 安全边界:Skill 通过 bash 执行 curl 命令,这给了 AI 很大灵活性,但如何防止越权操作?写操作(退款、改价)是否需要人工确认?
5. 运维效率:如何快速开通/下线一个商家?Skills 更新如何批量下发?
5.2 架构方案
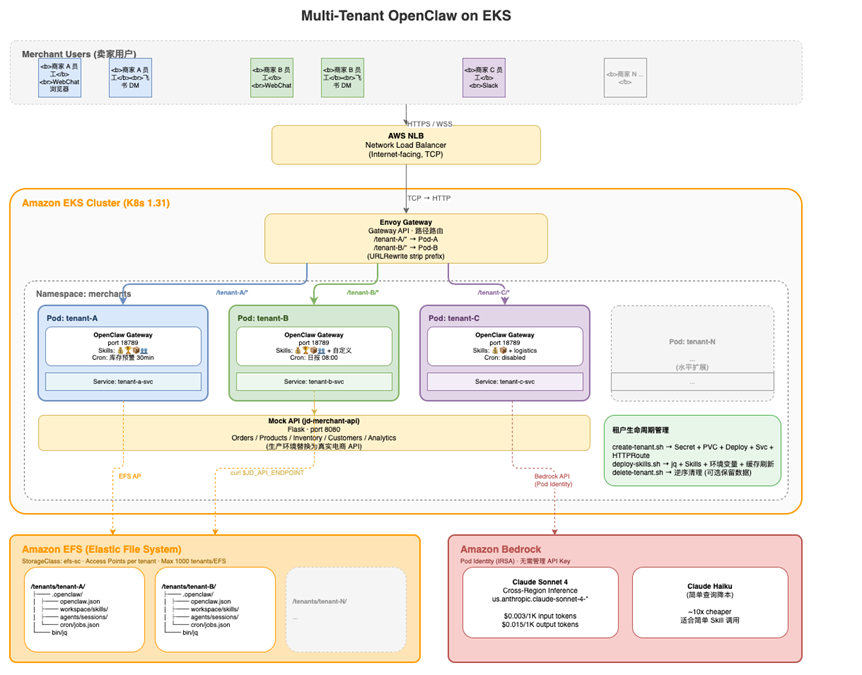 |
我们在 AWS 上构建了一个多租户 OpenClaw 平台,用 per-tenant Pod 的方式回应上述隔离需求:
- EKS:容器编排,支持节点组自动扩缩
- Envoy Gateway:原生 Kubernetes Gateway API,动态路由配置无需 reload
- EFS:Access Point 天然多租户隔离,ReadWriteMany 模式跨 AZ 持久化
- Bedrock:Pod Identity (IRSA) 访问 Claude 模型,无需管理 API Key
为什么 per-Pod 而不是共享进程?
OpenClaw 的 “Gateway as Runtime” 架构把所有功能打包在一个 Node.js 进程中。这意味着:
- 无法在一个进程内运行多个互相隔离的 Agent Engine实例
- 每个商家的 Skills、Session、Cron 都需要独立的文件系统空间
- 一个商家的 LLM 调用阻塞不应影响其他商家
per-Pod 是 OpenClaw 架构下的保持代码改动量最小的自然选择。
为什么 Envoy Gateway 而不是 Nginx Ingress?
Envoy Gateway 实现了 Kubernetes Gateway API 标准,相比传统 Nginx Ingress:
- HTTPRoute 资源原生支持路径前缀匹配 + URL 重写,声明式配置
- 路由变更通过 K8s API 即时生效,不需要全量配置 reload,添加商户时影响面小。
- 配合 EnvoyProxy CRD 可以精确控制 NLB 参数(internet-facing、IP target type)
为什么 EFS 而不是 EBS?
- EBS 是 block storage,一次只能挂载到一个节点。Pod 迁移到其他节点时需要 detach/attach,有停机时间
- EFS 是 NFS,ReadWriteMany 模式,Pod 可以在任意节点启动并立即访问数据
- EFS Access Point 提供了原生的 per-tenant 目录隔离 + UID/GID 映射
已知上限:AWS EFS 单个文件系统限制 1000 个 Access Point。超过 1000 个商家需要创建多个 EFS 文件系统并配置多个 StorageClass。
以下仅统计 Pod 运行所需的基础设施资源,不含大模型调用费用(模型价格差异较大,需根据实际选型单独评估)。
估算基准:机型 r7i,区域 us-east-1,采用 1 年期 Compute Savings Plans(No Upfront)价格。选择 r7i 是考虑到 OpenClaw 是 Node.js 单线程应用,CPU 占用低但内存需求高(启动即 ~800MB),r7i 的 1:8 CPU 内存比更匹配此类负载。实际价格请以 AWS Pricing Calculator 为准。
单租户 Pod 资源配置:CPU requests 100m / limits 500m,内存 requests 1.5Gi / limits 2Gi。
每节点可调度 Pod 数(扣除系统预留 ~0.5 vCPU + 0.5 GiB 后,按内存 requests 为瓶颈计算):
|
节点规格 |
可用内存 |
可调度租户 Pod |
|
r7i.large |
~15.5 GiB |
~10 个 |
|
r7i.xlarge |
~31.5 GiB |
~21 个 |
|
r7i.2xlarge |
~63.5 GiB |
~42 个 |
分规模成本估算:
|
规模 |
节点配置 |
EC2 (SP) |
EKS 集群 |
EFS |
合计/月 |
分摊/商家/月 |
|
10 商家 |
2× r7i.large |
$116 |
$73 |
~$1 |
~$190 |
~$19.0 |
|
100 商家 |
5× r7i.xlarge |
$580 |
$73 |
~$3 |
~$656 |
~$6.6 |
|
1000 商家 |
24× r7i.2xlarge |
$5,568 |
$73 |
~$30 |
~$5,671 |
~$5.7 |
- EKS 集群管理费固定 $0.10/hr = $73/月,与租户数无关
- EFS 按实际存储量计费($0.30/GB/月),每商家 Sessions + Skills + Config 通常在 100MB 以内
- Envoy Gateway Pod 资源占用较小(~0.5 vCPU),已含在节点资源中
- 规模越大分摊越低,主要因为 EKS 固定费用被稀释 + 大节点装箱率更高
- 相比通用型 m7i 方案,r7i 在同等规模下每商家成本降低约 15-20%
在电商场景下,AI 助手通过 bash 执行 curl 命令调用业务 API——灵活性很高,但也意味着安全边界必须考虑清楚。以下按实际威胁场景展开。
场景一:AI 执行了危险的系统命令
Skill 通过 bash 工具执行 curl + jq,如果 AI 被诱导(prompt injection)或出现幻觉,可能尝试删除文件或安装恶意软件。
OpenClaw 原生提供了 Docker Sandbox 机制,可在 openclaw.json 中配置:sandbox.mode 控制启用范围(off / non-main / all),sandbox.docker.* 精细配置容器的只读文件系统、网络隔离、Linux 能力移除、资源上限等,配合 tools.exec.host: “sandbox” 使 bash 命令在受限嵌套容器中执行。
迁移至 EKS 环境下后,虽然Docker Sandbox 无法直接使用,但per-tenant Pod 架构本身已经提供了等价的隔离能力,每个商家独占一个 Pod,AI 的 bash 命令在该 Pod 内执行。即使出现破坏性操作,影响范围被限制在这个 Pod 内部,不会波及其他商家。配合 EFS Access Point 的目录隔离,文件系统层面也无法越界访问。
EKS 部署需要两步调整:OpenClaw 侧关闭 Sandbox,K8s 侧承接安全职责。
第一步:openclaw.json 配置——关闭 Sandbox,命令在 Pod 内直接执行:
- sandbox.mode: “off” — 禁用 Docker Sandbox
- tools.exec.host: “node” — bash 命令在 Pod 内直接执行(此时环境变量黑名单自动生效,见场景二)
- tools.exec.security / ask — 执行审批机制仍然有效(见场景三)
第二步:Pod 层面安全配置——将 Sandbox 的隔离能力上移到 K8s:
|
Docker Sandbox 的能力 |
EKS Pod 层面的等价配置 |
|
只读文件系统 |
securityContext.readOnlyRootFilesystem: true |
|
网络隔离 |
Kubernetes NetworkPolicy 限制 Pod 只能访问指定 API 地址 |
|
Linux 能力全部移除 |
securityContext.capabilities.drop: [“ALL”] |
|
资源上限 |
resources.limits(CPU / memory,已配置) |
|
非 root 运行 |
runAsUser: 1000 / runAsNonRoot: true(已配置) |
每个商家独占一个 Pod,AI 的 bash 命令在该 Pod 内执行。即使出现破坏性操作,影响范围被限制在这个 Pod 内部,不会波及其他商家。配合 EFS Access Point 的目录隔离,文件系统层面也无法越界访问。
场景二:AI 尝试通过环境变量注入攻击
攻击方式:AI 在 bash 命令中设置 LD_PRELOAD 劫持动态链接库,或修改 PATH 替换系统命令。
OpenClaw 的应对——环境变量黑名单(内建安全策略,不可配置):
当 tools.exec.host 为 gateway 或 node 时(非 sandbox 模式),OpenClaw 硬编码拦截以下危险环境变量,任何尝试设置的命令直接抛出 Security Violation 异常:
|
攻击类型 |
拦截的变量 |
|
动态链接器注入 |
LD_PRELOAD、LD_LIBRARY_PATH、LD_AUDIT、DYLD_* 系列 |
|
运行时注入 |
NODE_OPTIONS、NODE_PATH、PYTHONPATH、PYTHONHOME、RUBYLIB、PERL5LIB |
|
Shell 初始化劫持 |
BASH_ENV、ENV、IFS |
|
其他 |
GCONV_PATH、SSLKEYLOGFILE、PATH(完全禁止修改) |
这是一条不可绕过的底线——LD_PRELOAD 注入这类攻击没有合理的业务场景,因此不提供配置开关。Sandbox 模式下不启用此检查,因为容器本身已经提供了更强的隔离。
场景三:AI 自主执行了退款/改价等高危操作
这是电商场景最敏感的问题——AI 不应该在无人确认的情况下执行涉及资金的操作。
OpenClaw 在 AI 层面提供了以下安全控制能力:
- Skill 级别的启用/禁用:在 openclaw.json 中可以按 Skill 配置 enabled: false,禁用的 Skill 不会出现在 AI 的 prompt 中——AI 完全看不到该能力,也不会尝试调用。Gateway 还提供 skills.update API 支持运行时动态切换,skills.status 可查询当前状态
- bash 执行审批:tools.exec.security 支持 deny(全拒,默认)/ allowlist(白名单放行)/ full(全放),配合 tools.exec.ask 的 on-miss(白名单未命中时审批)/ always(每条都审批)/ off(不审批),可控制哪些程序允许自动执行
- 安全白名单 safeBins:默认包含 jq、grep、sort 等纯本地数据处理工具,这些程序只做文本变换不发起网络请求,可以安全地自动放行
以上能力组合使用,可以实现:AI 只能看到查询类 Skill,jq/grep 等工具自动执行,curl 不在白名单中不会自动执行。
但落到”退款”这个具体场景,仍有两个挑战:
挑战一:safeBins 的控制粒度是”可执行程序”,而非”API 操作”。 safeBins 和 exec-approvals.json 匹配的都是程序名或路径(如 curl、/usr/bin/curl),不检查命令参数。一旦 curl 被放入白名单,所有 curl 调用(GET 查询和 POST 退款)都会被自动放行。OpenClaw 无法区分同一个程序的安全用法和危险用法。
挑战二:Skill 开关是”能力边界”,不是”逐笔审批”。 enabled: false 可以彻底关闭退款能力,但如果业务确实需要 AI 辅助退款(如卖家说”帮我退了上个月那笔订单”),就需要启用退款 Skill。而 Skill 开关是全局的——启用期间所有退款请求都能执行,不是只针对某一笔操作的审批。”谁来审批启用””启用期间如何限制范围”这些问题,不在 OpenClaw 的能力范围内。
因此高危业务操作的审批是业务 API 层面的问题,不是 AI 层面的问题。 无论调用者是人工客服还是 AI 助手,”退款”的安全保障都应该由业务系统本身提供,即退款接口本身要求二次确认(如短信验证码、金额阈值审批)等。
OpenClaw 负责”AI 能看到什么 Skill、能执行什么程序”,业务系统负责”这笔退款该不该批准”——两层各司其职。
*场景四:商家 API 凭证的生命周期管理
电商开放平台(京东、淘宝等)普遍采用 OAuth2 授权,每个卖家的 access_token 绑定了卖家身份——拿到 token 就能访问该卖家的订单、库存、财务数据。因此 token 是核心资产,需要从授权、存储、注入、轮换、隔离全链路管理。
OpenClaw 本身不处理 OAuth2 流程,需要平台侧配套建设:
授权:卖家在 Web 管理后台完成 OAuth2 授权(浏览器跳转电商平台授权页 → 登录确认 → 回调拿到 access_token + refresh_token)。这一步无法在飞书群聊中完成,必须通过 Web 交互。
存储与轮换:token 存入 AWS Secrets Manager,利用其原生 Rotation 能力挂载 Lambda 自动用 refresh_token 换取新 access_token,无需自建 token 管理服务。
注入:Pod 通过 EKS Pod Identity(IRSA)自动获得 IAM 临时凭证,Skill 执行时直接从 Secrets Manager 读取当前有效 token:
Pod 通过IRSA 提供的 IAM 身份在 Pod 启动时由 EKS 和 AWS STS 自动注入。
隔离:IAM Policy 限制每个租户的 Pod Role 只能读取自己的 secret(arn:aws:secretsmanager:*:*:secret:/openclaw/seller-a/*),这是 AWS 基础设施级别的隔离,比应用层隔离更可靠。配合 CloudTrail 记录所有 secret 访问,满足审计需求。
场景五:恶意或有缺陷的 Skill 文件
如果允许商家上传自定义 Skill,可能包含挖矿脚本、数据窃取代码等。
OpenClaw 的应对——Skill 安全扫描器(src/security/skill-scanner.ts):在 Skill 加载前扫描内容,检测危险 shell 调用、动态代码执行、挖矿特征(stratum 协议)、环境变量窃取 + 网络发送组合、大段混淆编码等模式。命中 CRITICAL 规则的 Skill 会被阻止加载。
生产环境建议:平台级 Skill 由团队审核后发布,商家自定义 Skill 限定只能调用白名单 API,且必须通过安全扫描。
场景六:操作审计与追溯
AI 执行的所有操作都记录在 Session 的 .jsonl 文件中,每行一个 JSON 对象,包含消息角色(user/assistant/tool)、完整内容、时间戳等。Session 元数据还记录了来源渠道、用户 ID、使用的模型、token 用量、加载的 Skill 快照等信息。
OpenClaw 提供了以下读取方式:
- Gateway API:通过 WebSocket 调用 sessions.list(按时间范围、agentId、关键词筛选会话)、sessions.preview(读取最近消息摘要)、sessions.usage(按日期范围统计 token 用量)
- CLI:openclaw sessions 命令列出会话元数据(类型、时间、模型、token 数等)
- 文件直读:transcript 文件位于 ~/.openclaw/agents/{agentId}/sessions/{sessionId}.jsonl,可直接用 jq 等工具解析
多租户场景下的局限:每个 Pod 的 session 文件是独立的,Gateway API 只能查本 Pod 内的数据。如果要在平台级为商家提供审计能力,需要在 OpenClaw 之外建设日志汇聚层——例如将每个 Pod 的 EFS 目录中的 .jsonl 文件通过 Fluent Bit 采集到 CloudWatch Logs 或 OpenSearch,再为每个卖家提供查询、告警和合规检查。
整个租户管理通过三个脚本完成:
从一无所有到一个完整可用的商家 AI 助手实例,整个过程在分钟级别完成。
6. 使用体验
以下是实际 PoC 中的几个使用场景。(测试中将Bot命名为“京东小欧”仅为POC随意命名)
6.1 卖家与助手的单聊场景
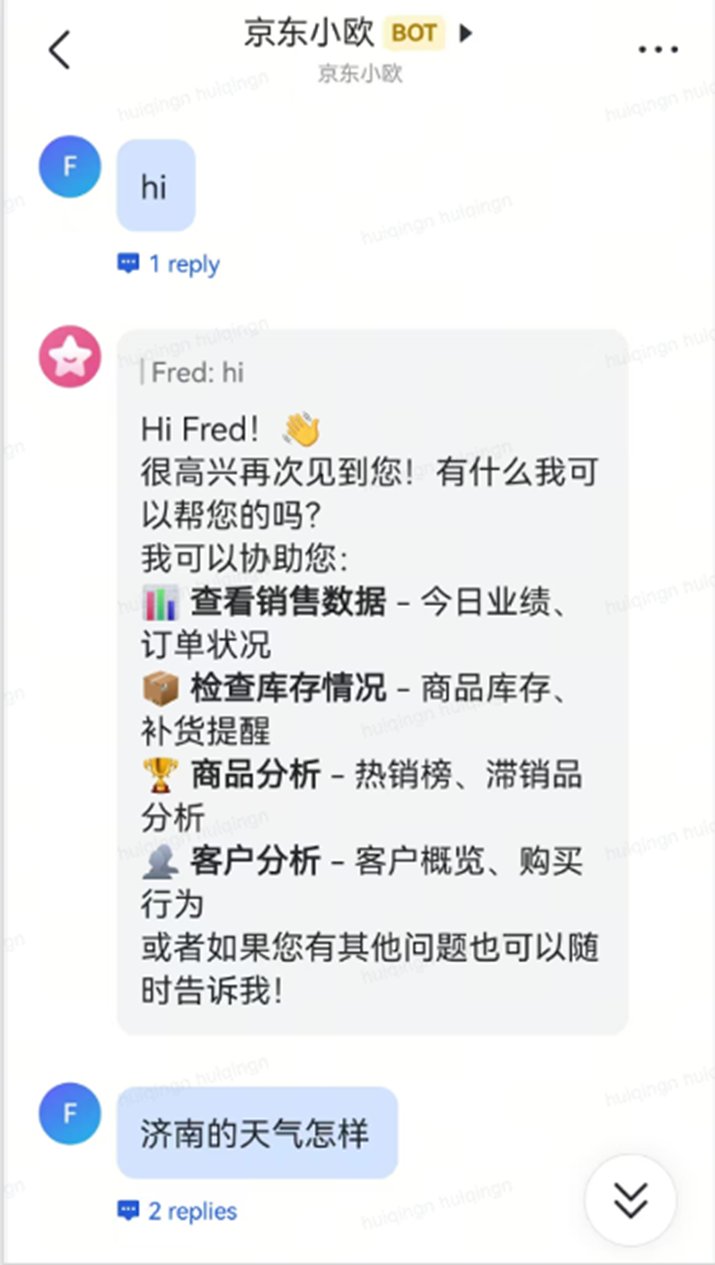 |
6.2 店员群拉入助手的群聊场景
模拟三个店员和bot建群,通过@方式让Bot进行销售情况查询和分析
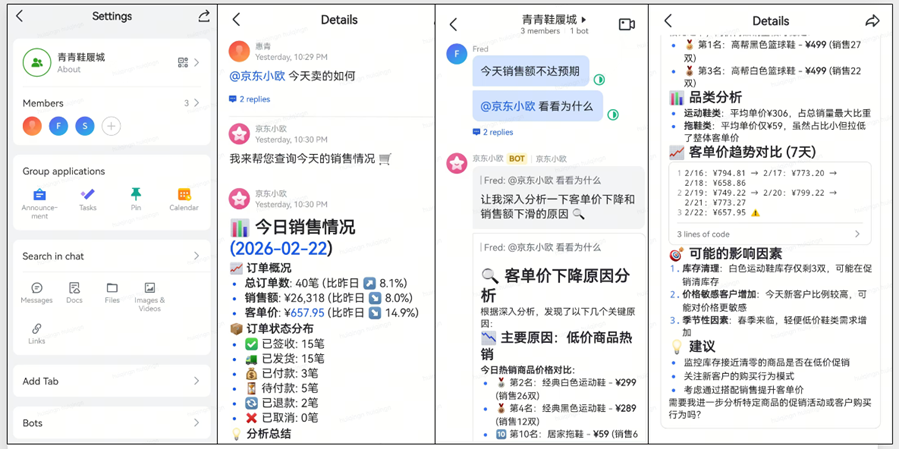 |
6.3 定时任务场景
模拟店员通过自然语言对话方式设定定时任务,Bot根据需求定时检查库存,店员将定时任务关停的场景
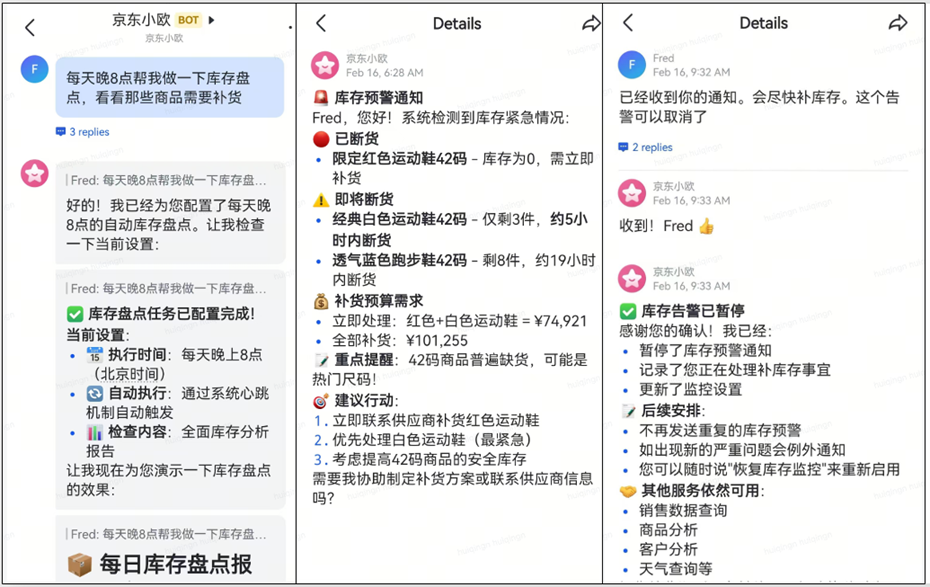 |
7. 总结
这次 PoC 验证了:Markdown Skill + 多渠道嵌入 + 主动通知,是构建电商卖家助手的一条可行路径。Skill 范式将能力构建门槛从”会写代码”降到”会写 curl”,上线周期可以压缩到分钟级。
OpenClaw 作为单租户 AI Gateway 引擎,Skill 机制、多 Agent 路由、Cron 主动通知等能力成熟度高。但从单机到平台,需要清醒认识它的边界:
- 安全控制止步于工具级别:能管”AI 看到哪些 Skill、能执行哪些程序”,但无法区分 curl GET 查询和 curl POST 退款。高危操作审批是业务 API 的职责,不是 AI 层的职责
- 租户运维自动化、OAuth2 凭证、平台审计等配套设施需要在 OpenClaw 之外建设——这些才是平台化真正的工程量
一句话:OpenClaw 解决了”AI 引擎”的问题,围绕它构建”业务平台”是下一步的工作。
项目代码结构:https://github.com/SharonNi/jdopenclaw
➡️ 下一步行动:
相关产品:
- Amazon EFS — 无服务器,完全弹性文件存储
- Amazon EKS — 用于运行容器化应用程序的托管式 Kubernetes 服务
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- Amazon IAM — 身份管理以及对 AWS 服务和资源的访问权限
- Amazon Secrets Manager — 轮换、管理和检索数据库凭证、API 密钥和其他密钥
相关文章:
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
