第一章 前言
Amazon Aurora是亚马逊云科技自研的一项关系数据库服务,它在提供和开源数据库MySQL、PostgreSQL的完好兼容性同时,也能够提供和商业数据库媲美的性能和可用性。性能方面,Aurora MySQL能够支持到与开源标准MySQL同等配置下五倍的吞吐量,Aurora PostgreSQL能够支持与开源标准PostgreSQL同等配置下三倍的吞吐量的提升。在扩展性的角度,Aurora在存储与计算、横向与纵向方面都进行了功能的增强和创新。
Aurora的最大数据存储量现在支持多达128TB,而且可以支持存储的动态收缩。计算方面,Aurora提供多个读副本的可扩展性配置支持一个区域内多达15个读副本的扩展,提供多主的架构来支持同一个区域内4个写节点的扩展,提供Serverless无服务器化的架构实例级别的秒级纵向扩展,提供全球数据库来实现数据库的低延迟跨区域扩展。
随着用户数据量的增长,Aurora已经提供了很好的扩展性,那是否可以进一步增强更多的数据量、更多的并发访问能力呢?您可以考虑利用分库分表的方式,来支持底层多个Aurora集群的配置。基于此,包含这篇博客在内的系列博客会进行相应的介绍,旨在为您进行分库分表时代理或者JDBC的选择提供参考。
1.1 为什么要分库分表
| 架构 |
各种架构的优缺点 |
适应场景 |
| 单机 |
请求量大查询慢
单机故障导致业务不可用
|
数据量不太大,读写性能要求不高的场景 |
| 主从 |
数据库主从同步,从库可以水平扩展,满足更大读需求
但单服务器TPS,内存,IO都是有限的
|
数据量不太大,读写符合二八原则,在写性能满足要求情况下通过扩展从实例应对高性能读请求 |
| 双主 |
用户量级上来后,写请求越来越多
一个Master是不能解决问题的,添加多了个主节点进行写入,
多个主节点数据要保存一致性,写操作需要2个master之间同步更加复杂
|
在单机能满足数据容量的情况下,写性能成为主要的性能瓶颈,通过多主架构满足业务对写性能的要求 |
| 分库分表 |
数据量和读写性能同时超过了单机性能能力
通过将数据分摊到多个数据库实例上以同时提升读写和数据容量
数据读写的路由处理,数据一致性,分布式事务的问题更为负责
|
单机无法满足数据容量的要求,读写性能超过单机性能瓶颈的情况下,在不改变数据库类型的情况下选择分库分表的方案 |
AWS Aurora提供了关系型数据库单机,主从,多主,全球数据库等托管架构形式可以满足以上各种架构场景,但分库分表的场景下Aurora没有提供直接的支持,并且分库分表还衍生出来如垂直与水平多种形态,再进一步提升数据容量的情况下,也带来一些需要解决的问题,如跨节点数据库Join关联查询、分布式事务、执行的SQL排序、翻页、函数计算、数据库全局主键、容量规划、分库分表后二次扩容等问题。
1.2 分库分表的方式
查询一次所花的时间业界公认MySQL单表容量在 1千万 以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。通过对数据的切分可以在降低单表的数据量的同时,将读写的压力分摊到不同的数据节点上,数据切分可以分为:垂直切分和水平切分。
| 切分方式 |
分类 |
说明 |
|
业务维度
垂直拆分
|
垂直分库 |
按业务相关性将业务耦合关系比较大的表分拆到单独的数据库中 |
| 垂直分表 |
将单表字段数量比较多的表拆分为两个或以上的表 |
|
数据维度
水平拆分
|
水平分库 |
数据条数比较多的表,按照一定的规则在表结构不变的情况下,将数据分到不同的库中 |
| 水平分表 |
数据条数比较多的表,按照一定的规则在表结构不变的情况下,将数据分到不同的库中 |
1. 垂直切分的优点
解决业务系统层面的耦合,业务清晰
与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
2. 垂直切分的缺点
– 分库后无法Join,只能通过接口聚合方式解决,提升了开发的复杂度
– 分库后分布式事务处理复杂
– 依然存在单表数据量过大的问题(需要水平切分)
3. 水平切分的优点
– 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
– 应用端改造较小,不需要拆分业务模块
4. 水平切分的缺点
– 跨分片的事务一致性难以保证
– 跨库的Join关联查询性能较差
– 数据多次扩展难度和维护量极大
结合以上分析,在调研了常见的分库分表的中间件基础上,我们选取ShardingSphere开源产品结合Amazon Aurora,介绍这两种产品的结合是如何满足各种形式的分库分表方式和如何解决由分库分表带来的一些问题。
第二章 Sharding-JDBC介绍
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar这3款相互独立的产品组成。
| 对比项 |
ShardingSphere-JDBC |
ShardingSphere-Proxy |
ShardingSphere-Sidecar |
| 数据库 |
任意 |
MySQL/PostgreSQL |
MySQL/PostgreSQL |
| 连接消耗数 |
高 |
低 |
高 |
| 异构语言 |
仅 Java |
任意 |
任意 |
| 性能 |
损耗低 |
损耗略高 |
损耗低 |
| 无中心化 |
是 |
否 |
是 |
| 静态入口 |
无 |
有 |
无 |
其中Sharding-JDBC的特点如下:
- 它使用客户端直连数据库,以 jar 包形式提供服务。
- 无需额外部署和依赖,可理解为增强版的JDBC 驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP等;
- 支持任意实现JDBC 规范的数据库,目前支持MySQL,PostgreSQL,Oracle,SQLServer以及任何可使用 JDBC 访问的数据库。
- 采用无中心化架构,与应用程序共享资源,适用于 Java 开发的高性能的轻量级 OLTP 应用
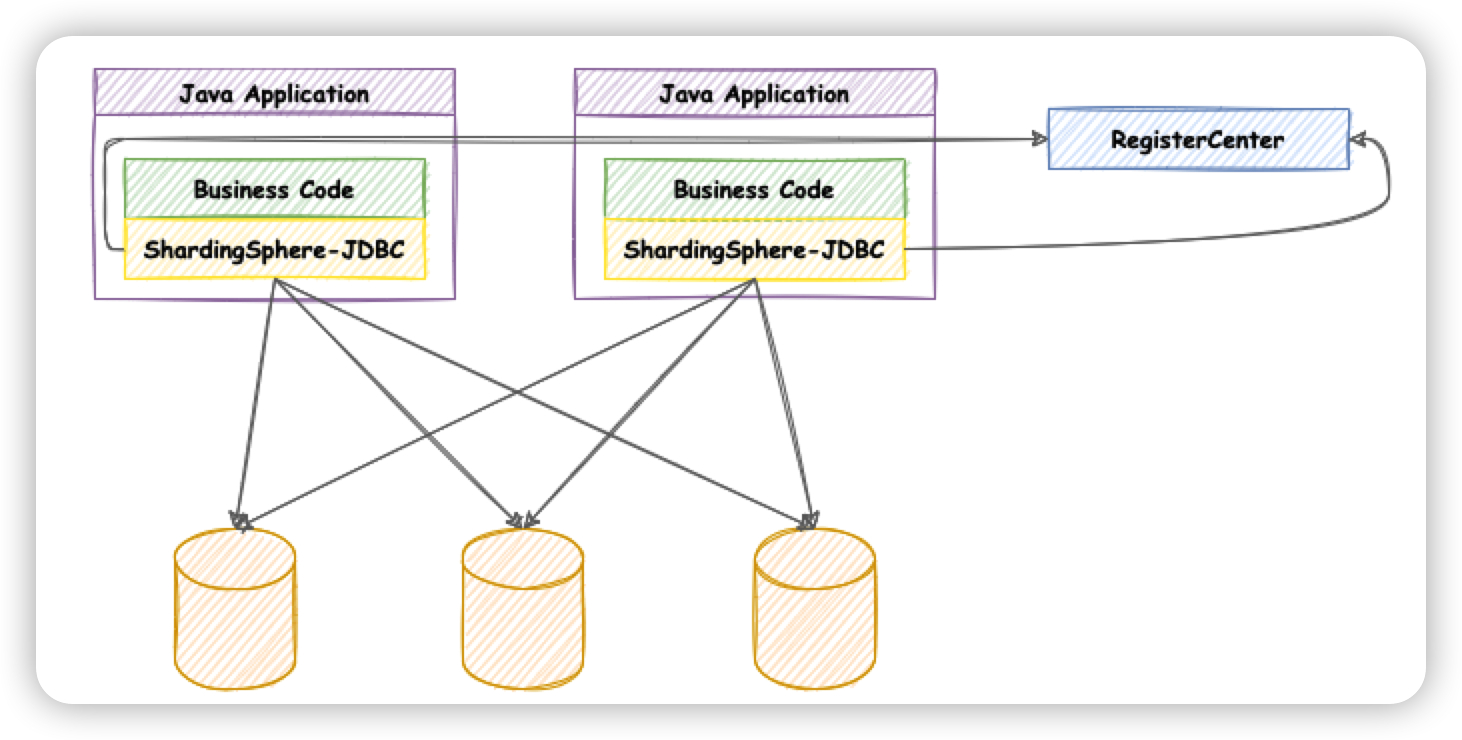
Sharding-JDBC与应用集成的架构

Sharding-JDBC基本术语
数据节点Node:数据分片的最小单元,由数据源名称和数据表组成,比如:ds_0.product_order_0。
真实表:在分片的数据库中真实存在的物理表,比如商品订单表 product_order_0、product_order_1、product_order_2。
逻辑表:水平拆分的数据库(表)的相同逻辑和数据结构表的总称,比如商品订单表 product_order_0、product_order_1、product_order_2,逻辑表就是product_order。
绑定表:指分片规则一致的主表和子表,比如product_order表和product_order_item表,均按照order_id分片,则此两张表互为绑定表关系,绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
广播表:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致,适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表、配置表。
第三章 Sharding-JDBC功能测试
3.1 样例工程说明
下载样例工程代码到本地,为保证测试代码的稳定性我们这里选择使shardingsphere-example-4.0.0这个tag版本
git clone https://github.com/apache/shardingsphere-example.git
工程项目说明
shardingsphere-example
├── example-core
│ ├── config-utility
│ ├── example-api
│ ├── example-raw-jdbc
│ ├── example-spring-jpa #spring+jpa集成基础的entity,repository
│ └── example-spring-mybatis
├── sharding-jdbc-example
│ ├── sharding-example
│ │ ├── sharding-raw-jdbc-example
│ │ ├── sharding-spring-boot-jpa-example #集成基础的sharding-jdbc的功能
│ │ ├── sharding-spring-boot-mybatis-example
│ │ ├── sharding-spring-namespace-jpa-example
│ │ └── sharding-spring-namespace-mybatis-example
│ ├── orchestration-example
│ │ ├── orchestration-raw-jdbc-example
│ │ ├── orchestration-spring-boot-example #集成基础的sharding-jdbc的治理的功能
│ │ └── orchestration-spring-namespace-example
│ ├── transaction-example
│ │ ├── transaction-2pc-xa-example #sharding-jdbc分布式事务两阶段提交的样例
│ │ └──transaction-base-seata-example #sharding-jdbc分布式事务seata的样例
│ ├── other-feature-example
│ │ ├── hint-example
│ │ └── encrypt-example
├── sharding-proxy-example
│ └── sharding-proxy-boot-mybatis-example
└── src/resources
└── manual_schema.sql
配置文件说明
application-master-slave.properties #读写分离配置文件
application-sharding-databases-tables.properties #分库分表配置文件
application-sharding-databases.properties #仅分库配置文件
application-sharding-master-slave.properties #分库分表加读写分离的配置文件
application-sharding-tables.properties #分表配置文件
application.properties #spring boot 配置文件
代码逻辑说明
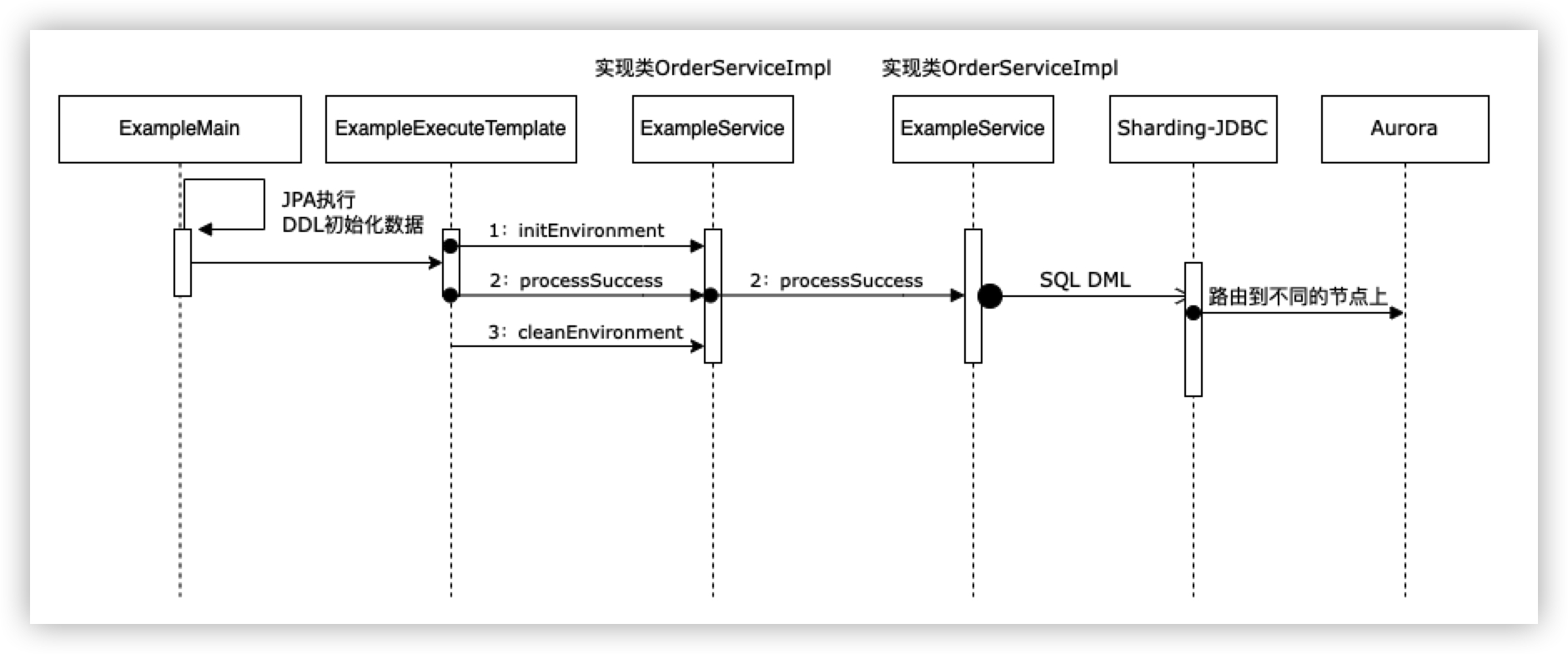
Spring Boot应用的入口类,执行该类就可以运行工程

其中demo的执行逻辑如下

3.2 读写分离验证
随着业务增长,写和读请求分离到不同的数据库节点上能够有效提高整个数据库集群的处理能力。Aurora通过读/写的endpoint可以满足用户写和强一致性读的需求,单独只读的endpoint可以满足用户非强一致性读的需求。Aurora的读写延迟通常在毫秒级别,比MySQL基于binlog的逻辑复制要低得多,所以有很多负载是直接打到只读endpoint。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题。 Aurora以完全托管的形式提供了主从架构,但上层应用在与Aurora交互时,仍然需要管理多个数据源,根据SQL语句的读写类型和一定的路由策略将SQL请求路由到不同的节点上。
Sharding-Jdbc提供的读写分离的特性,应用程序与Sharding-JDBC集成,将应用程序与数据库集群之间复杂配置关系从应用程序中剥离出来,开发者通过配置文件管理Shard,再结合一些ORM框架如Spring JPA、Mybatis就可以完全将这些复制的逻辑从代码中分离。极大的提高代码的可维护性,降低代码与数据库的耦合。
3.2.1 数据库环境准备
首先创建一套Aurora MySQL 读写分离集群,机型为db.r5.2xlarge,每套集群有一个写节点2个读节点。如下图所示


3.2.2 Sharding-Jdbc配置
application.properties spring boot主配置文件说明
如下图所属:绿色标注的部分你需要替换成自己环境上的配置
# jpa自动根据实体创建和drop数据表
spring.jpa.properties.hibernate.hbm2ddl.auto=create-drop
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5Dialect
spring.jpa.properties.hibernate.show_sql=true
#spring.profiles.active=sharding-databases
#spring.profiles.active=sharding-tables
#spring.profiles.active=sharding-databases-tables
#激活master-slave 配置项,这样sharding-jdbc将使用master-slave配置文件
spring.profiles.active=master-slave
#spring.profiles.active=sharding-master-slave
application-master-slave.properties sharding-jdbc配置文件说明
spring.shardingsphere.datasource.names=ds_master,ds_slave_0,ds_slave_1
# 数据源 主库-master
spring.shardingsphere.datasource.ds_master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_master.password= 您自己的主db密码
spring.shardingsphere.datasource.ds_master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_master.jdbc-url=您自己的主db数据源url spring.shardingsphere.datasource.ds_master.username=您自己的主db用户名
# 数据源 从库
spring.shardingsphere.datasource.ds_slave_0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_slave_0.password= 您自己的从db密码
spring.shardingsphere.datasource.ds_slave_0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_slave_0.jdbc-url=您自己的从db数据源url
spring.shardingsphere.datasource.ds_slave_0.username= 您自己的从db用户名
# 数据源 从库
spring.shardingsphere.datasource.ds_slave_1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_slave_1.password=您自己的从db密码
spring.shardingsphere.datasource.ds_slave_1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_slave_1.jdbc-url= 您自己的从db数据源url
spring.shardingsphere.datasource.ds_slave_1.username= 您自己的从db用户名
# 路由策略配置
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
spring.shardingsphere.masterslave.name=ds_ms
spring.shardingsphere.masterslave.master-data-source-name=ds_master
spring.shardingsphere.masterslave.slave-data-source-names=ds_slave_0,ds_slave_1
# sharding-jdbc 配置信息存储方式
spring.shardingsphere.mode.type=Memory
# 开启shardingsphere 日志,开启的情况下从打印中可以看到逻辑SQL到实际SQL的转换
spring.shardingsphere.props.sql.show=true
3.2.3 测试验证过程说明
- 测试环境数据初始化:Spring JPA初始化自动创建用于测试的表

如下图ShardingSphere-SQL log所示,写SQL在ds_master数据源上执行。

如下图ShardingSphere-SQL log所示,读SQL按照轮询的方式在ds_slave数据源上执行。
[INFO ] 2022-04-02 19:43:39,376 --main-- [ShardingSphere-SQL] Rule Type: master-slave
[INFO ] 2022-04-02 19:43:39,376 --main-- [ShardingSphere-SQL] SQL: select orderentit0_.order_id as order_id1_1_, orderentit0_.address_id as address_2_1_,
orderentit0_.status as status3_1_, orderentit0_.user_id as user_id4_1_ from t_order orderentit0_ ::: DataSources: ds_slave_0
---------------------------- Print OrderItem Data -------------------
Hibernate: select orderiteme1_.order_item_id as order_it1_2_, orderiteme1_.order_id as order_id2_2_, orderiteme1_.status as status3_2_, orderiteme1_.user_id
as user_id4_2_ from t_order orderentit0_ cross join t_order_item orderiteme1_ where orderentit0_.order_id=orderiteme1_.order_id
[INFO ] 2022-04-02 19:43:40,898 --main-- [ShardingSphere-SQL] Rule Type: master-slave
[INFO ] 2022-04-02 19:43:40,898 --main-- [ShardingSphere-SQL] SQL: select orderiteme1_.order_item_id as order_it1_2_, orderiteme1_.order_id as order_id2_2_, orderiteme1_.status as status3_2_,
orderiteme1_.user_id as user_id4_2_ from t_order orderentit0_ cross join t_order_item orderiteme1_ where orderentit0_.order_id=orderiteme1_.order_id ::: DataSources: ds_slave_1
注意:如下图所示,如果在一个事务中既有读也有写,sharding-jdbc将读写操作都路由到主库;如果读写请求不在一个事务中,那么对应读请求将按照路由策略分发到不同的读节点上。
@Override
@Transactional // 开启事务时在该事务中读写都走主库;关闭事务时,读走从库,写走主库
public void processSuccess() throws SQLException {
System.out.println("-------------- Process Success Begin ---------------");
List<Long> orderIds = insertData();
printData();
deleteData(orderIds);
printData();
System.out.println("-------------- Process Success Finish --------------");
}
3.2.4 Aurora failover场景验证
Aurora数据库环境采用3.2.1中的配置
3.2.4.1.1 验证过程中说明
1.启动Spring-Boot工程
2.在Aurora的console上执行故障转移操作

3.执行Rest API请求
4.多次执行POST http://localhost:8088/save-user直到该API的调用写入Aurora失败到最终恢复成功。
5.观测执行代码failover过程如下图所示,从log可以分析最近一次SQL执行写入操作成功到下次执行再次写入成功大概需要37s,也就是应用从Aurora failover中可以自动恢复,恢复的时长大概是37s。

3.3 仅分表功能验证
3.3.1 Sharding-Jdbc配置
application.properties spring boot主配置文件说明
# jpa 自动根据实体创建和drop数据表
spring.jpa.properties.hibernate.hbm2ddl.auto=create-drop
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5Dialect
spring.jpa.properties.hibernate.show_sql=true
#spring.profiles.active=sharding-databases
#激活sharding-tables配置项
#spring.profiles.active=sharding-tables
#spring.profiles.active=sharding-databases-tables
# spring.profiles.active=master-slave
#spring.profiles.active=sharding-master-slave
application-sharding-tables.properties sharding-jdbc配置文件说明
spring.shardingsphere.datasource.names=ds
spring.shardingsphere.datasource.ds.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds.jdbc-url= 您自己的db数据源url
spring.shardingsphere.datasource.ds.username= 您自己的db用户名
spring.shardingsphere.datasource.ds.password=您自己的db密码
spring.shardingsphere.datasource.ds.max-active=16
# 分表配置
## 逻辑表对应的物理表
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds.t_order_$->{0..1}
## 分表使用的字段
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
## 分表的路由策略
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2}
## 主键策略配置
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=123
spring.shardingsphere.sharding.tables.t_order_item.actual-data-nodes=ds.t_order_item_$->{0..1}
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item_$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order_item.key-generator.column=order_item_id
spring.shardingsphere.sharding.tables.t_order_item.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order_item.key-generator.props.worker.id=123
# 配置t_order与 t_order_item的绑定关系
spring.shardingsphere.sharding.binding-tables[0]=t_order,t_order_item
# 配置广播表
spring.shardingsphere.sharding.broadcast-tables=t_address
# sharding-jdbc的模式
spring.shardingsphere.mode.type=Memory
# 开启shardingsphere日志
spring.shardingsphere.props.sql.show=true
3.3.2 测试验证过程说明
- DDL操作
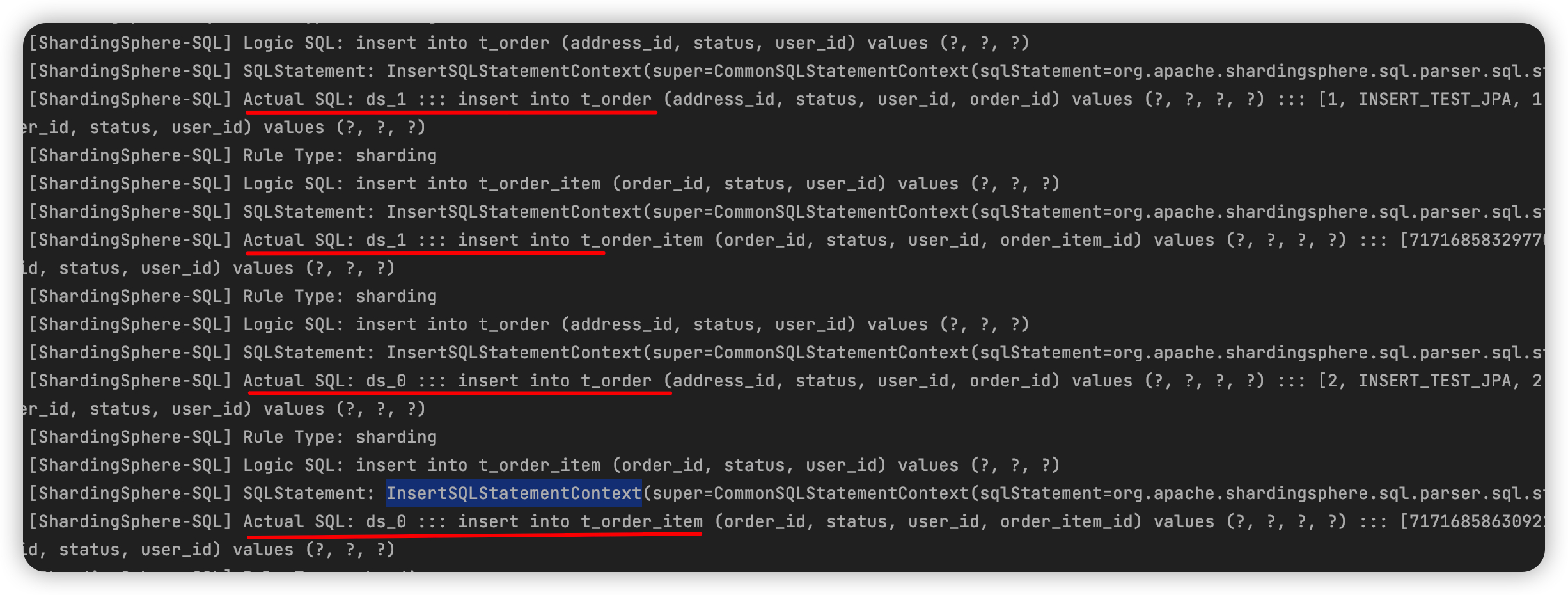
如下图所属,JPA自动创建用于测试的表,在配置了sharding-jdbc的路由规则的情况下,client端执行DDL,sharding-jdbc会自动根据分表规则创建对应的表;如t_address是广播表,由于只有一个主实例,所以创建一个t_address; t_order按照取模分表,创建t_order时会创建t_order_0, t_order_1两张表物理表。

- 写操作
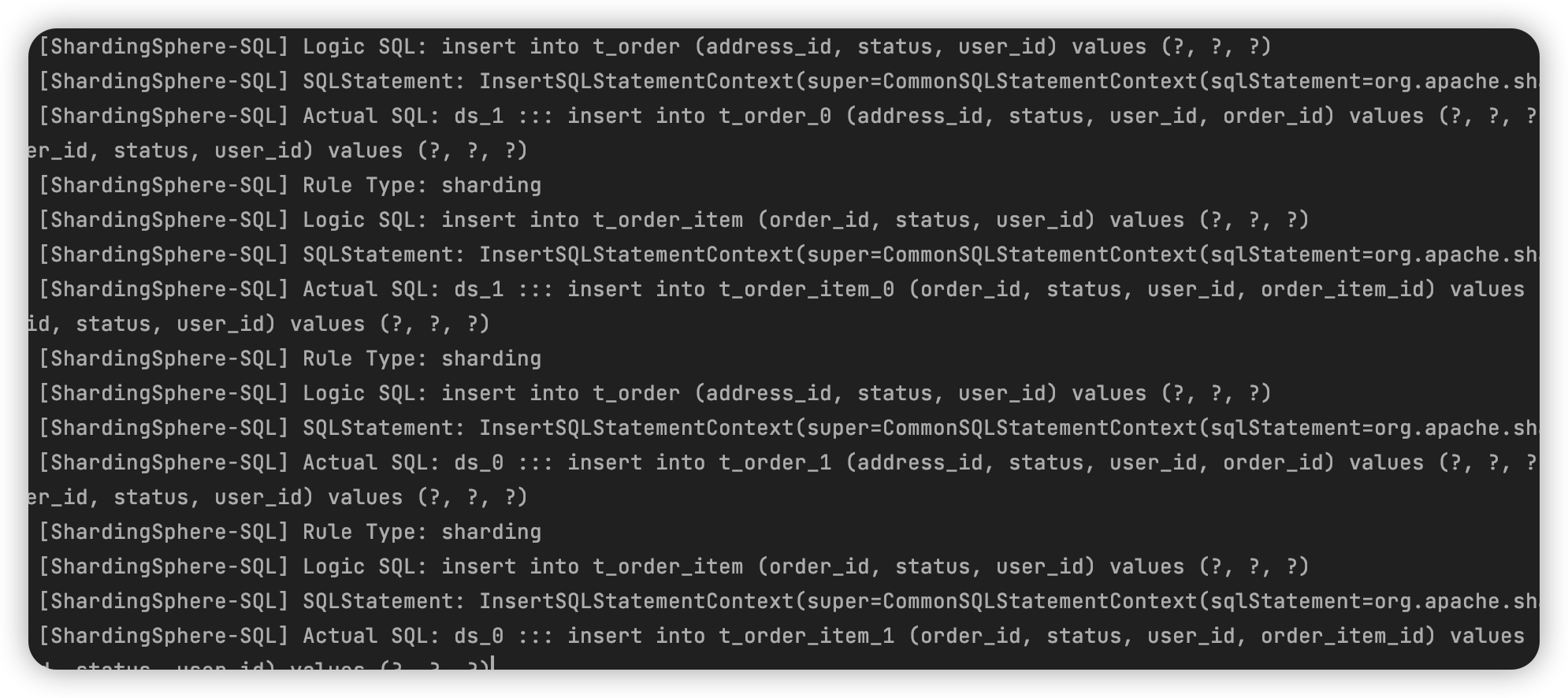
如下图所示 Logic SQL向t_order插入一条记录,sharding-jdbc执行的时候会根据分表规则将数据分布放到t_order_0, t_order_1中。
当t_order和t_order_item配置了绑定关系时,order_item与order有关联关系的记录会放到同一个物理分表中。

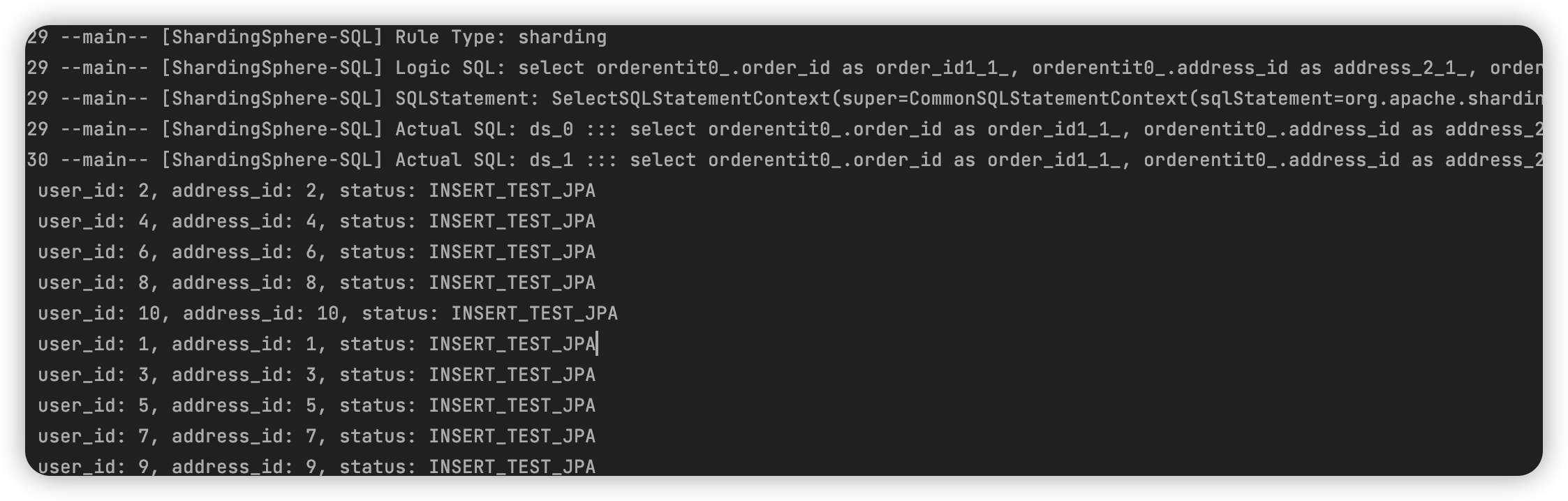
- 读操作
绑定表下的join查询操作order和order_item,如下图所示,会根据绑定关系精确定位对应的物理shard上。

非绑定表下的join查询操作order和order_item,如下图所属,会遍历所有的shard。

3.4 仅分库功能验证
3.4.1 数据库环境准备
如下图所属,在Aurora上创建两个实例:ds_0和ds_1

启动Sharding-spring-boot-jpa-example工程时会在两个Aurora实例上创建表t_order, t_order_item,t_address
3.4.2 Sharding-Jdbc配置
application.properties springboot主配置文件说明
# jpa 自动根据实体创建和drop数据表
spring.jpa.properties.hibernate.hbm2ddl.auto=create
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5Dialect
spring.jpa.properties.hibernate.show_sql=true
# 激活sharding-databases配置项
spring.profiles.active=sharding-databases
#spring.profiles.active=sharding-tables
#spring.profiles.active=sharding-databases-tables
#spring.profiles.active=master-slave
#spring.profiles.active=sharding-master-slave
application-sharding-databases.properties sharding-jdbc配置文件说明
spring.shardingsphere.datasource.names=ds_0,ds_1
# ds_0
spring.shardingsphere.datasource.ds_0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_0.jdbc-url= spring.shardingsphere.datasource.ds_0.username=
spring.shardingsphere.datasource.ds_0.password=
# ds_1
spring.shardingsphere.datasource.ds_1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_1.jdbc-url=
spring.shardingsphere.datasource.ds_1.username=
spring.shardingsphere.datasource.ds_1.password=
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds_$->{user_id % 2}
spring.shardingsphere.sharding.binding-tables=t_order,t_order_item
spring.shardingsphere.sharding.broadcast-tables=t_address
spring.shardingsphere.sharding.default-data-source-name=ds_0
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds_$->{0..1}.t_order
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=123
spring.shardingsphere.sharding.tables.t_order_item.actual-data-nodes=ds_$->{0..1}.t_order_item
spring.shardingsphere.sharding.tables.t_order_item.key-generator.column=order_item_id
spring.shardingsphere.sharding.tables.t_order_item.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order_item.key-generator.props.worker.id=123
# sharding-jdbc的模式
spring.shardingsphere.mode.type=Memory
# 开启shardingsphere日志
spring.shardingsphere.props.sql.show=true
3.4.3 测试验证过程说明
- DDL操作
JPA自动创建用于测试的表,如下图所属,在配置了sharding-jdbc的分库路由规则的情况下,client端执行DDL,sharding-jdbc会自动根据分表规则创建对应的表;如t_address是广播表在ds_0和ds_1上都会创建物理表t_address,t_order,t_order_item按照取模分库,这三个表会分别在ds_0和ds_1上创建。

- 写操作
对于广播表t_address,每写入一条记录会在ds_0和ds_1的t_address表上都写入

对于分库的表t_order,t_order_item,会按照分库字段和路由策略写入到对应实例上的表中。

- 读操作
如下图所示,查询order,根据分库路由规则路由到对应的Aurora实例上。

如下图所示,查询Address,由于address是广播表,会在所用的节点中随机选择一个address所在的实例查询。

如下图所示,绑定表下的join查询操作order和order_item时,会根据绑定关系精确定位对应的物理shard上。

3.5 分库分表功能验证
3.5.1 数据库环境准备
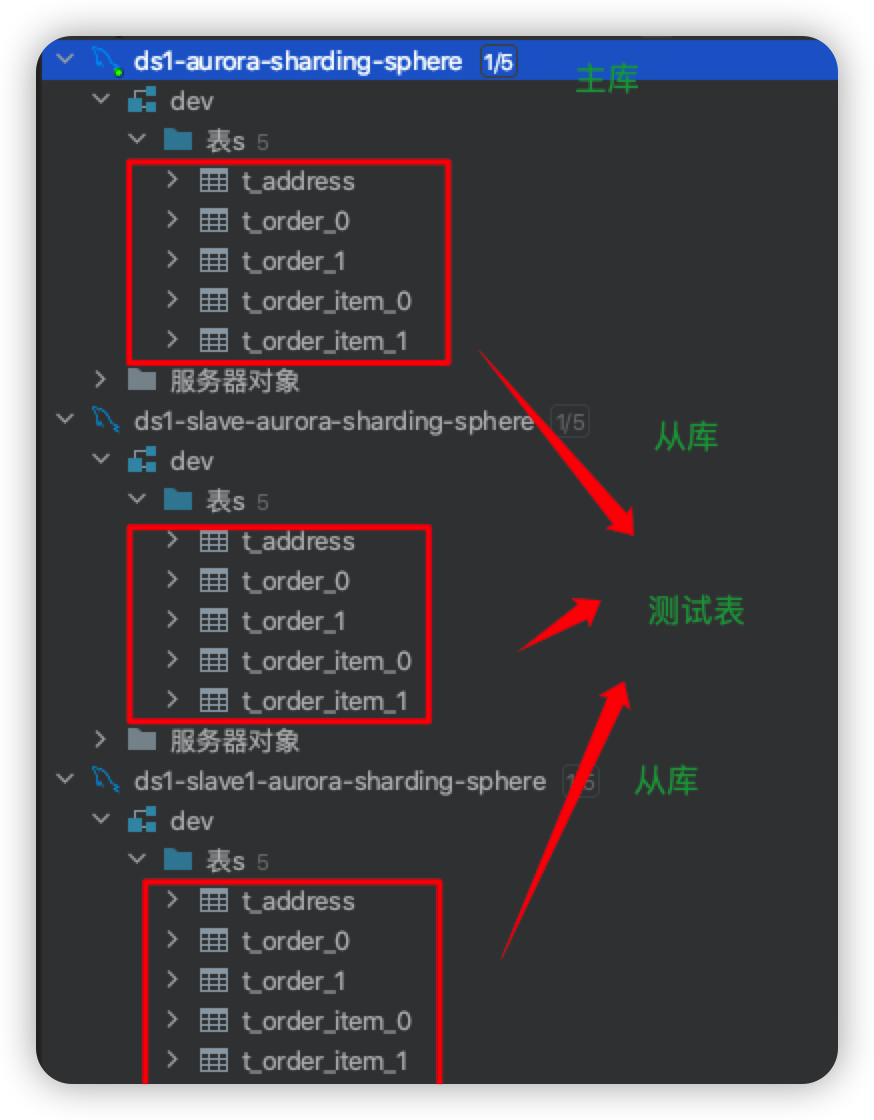
如下图所示,在Aurora上创建两个实例:ds_0和ds_1
启动sharding-spring-boot-jpa-example工程时会在两个Aurora实例上创建物理表t_order_01, t_order_02, t_order_item_01,t_order_item_02和t_address全局表。

3.5.2 Sharding-Jdbc配置
application.properties springboot主配置文件说明
# jpa 自动根据实体创建和drop数据表
spring.jpa.properties.hibernate.hbm2ddl.auto=create
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5Dialect
spring.jpa.properties.hibernate.show_sql=true
# 激活sharding-databases-tables配置项
#spring.profiles.active=sharding-databases
#spring.profiles.active=sharding-tables
spring.profiles.active=sharding-databases-tables
#spring.profiles.active=master-slave
#spring.profiles.active=sharding-master-slave
application-sharding-databases.properties sharding-jdbc配置文件说明
spring.shardingsphere.datasource.names=ds_0,ds_1
# ds_0
spring.shardingsphere.datasource.ds_0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_0.jdbc-url= 306/dev?useSSL=false&characterEncoding=utf-8
spring.shardingsphere.datasource.ds_0.username=
spring.shardingsphere.datasource.ds_0.password=
spring.shardingsphere.datasource.ds_0.max-active=16
# ds_1
spring.shardingsphere.datasource.ds_1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_1.jdbc-url=
spring.shardingsphere.datasource.ds_1.username=
spring.shardingsphere.datasource.ds_1.password=
spring.shardingsphere.datasource.ds_1.max-active=16
# 默认的分库策略
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds_$->{user_id % 2}
spring.shardingsphere.sharding.binding-tables=t_order,t_order_item
spring.shardingsphere.sharding.broadcast-tables=t_address
# 不满足分库策略的表放在ds_0上
spring.shardingsphere.sharding.default-data-source-name=ds_0
# t_order分表策略
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds_$->{0..1}.t_order_$->{0..1}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=123
# t_order_item分表策略
spring.shardingsphere.sharding.tables.t_order_item.actual-data-nodes=ds_$->{0..1}.t_order_item_$->{0..1}
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item_$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order_item.key-generator.column=order_item_id
spring.shardingsphere.sharding.tables.t_order_item.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order_item.key-generator.props.worker.id=123
# sharding-jdbc的模式
spring.shardingsphere.mode.type=Memory
# 开启shardingsphere日志
spring.shardingsphere.props.sql.show=true
3.5.3 测试验证过程说明
- DDL操作
JPA自动创建用于测试的表,如下图所示,在配置了sharding-jdbc的分库分表路由规则的情况下,client端执行DDL,sharding-jdbc会自动根据分表规则创建对应的表;如t_address是广播表在ds_0和ds_1上都会创建t_address。t_order,t_order_item按照取模分库分表,这三个表会分别在ds_0和ds_1上创建。

- 写操作
对于广播表t_address,每写入一条记录会在ds_0和ds_1的t_address表上都写入。

对于分库的表t_order,t_order_item,会按照分库字段和路由策略写入到对应实例上的表中。

- 读操作
读操作与仅分库功能验证类似,这里不再赘述
3.6 分库分表加读写分离功能验证
3.6.1 数据库环境准备
创建的数据库实例于对应的物理表如下图所示。


3.6.2 Sharding-Jdbc配置
application.properties spring boot主配置文件说明
# jpa 自动根据实体创建和drop数据表
spring.jpa.properties.hibernate.hbm2ddl.auto=create
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5Dialect
spring.jpa.properties.hibernate.show_sql=true
# 激活sharding-databases-tables配置项
#spring.profiles.active=sharding-databases
#spring.profiles.active=sharding-tables
#spring.profiles.active=sharding-databases-tables
#spring.profiles.active=master-slave
spring.profiles.active=sharding-master-slave
application-sharding-master-slave.properties sharding-jdbc配置文件说明
其中数据库的url、name、password需要修改成你自己的数据库的参数。
spring.shardingsphere.datasource.names=ds_master_0,ds_master_1,ds_master_0_slave_0,ds_master_0_slave_1,ds_master_1_slave_0,ds_master_1_slave_1
spring.shardingsphere.datasource.ds_master_0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_master_0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_master_0.jdbc-url= spring.shardingsphere.datasource.ds_master_0.username=
spring.shardingsphere.datasource.ds_master_0.password=
spring.shardingsphere.datasource.ds_master_0.max-active=16
spring.shardingsphere.datasource.ds_master_0_slave_0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_master_0_slave_0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_master_0_slave_0.jdbc-url= spring.shardingsphere.datasource.ds_master_0_slave_0.username=
spring.shardingsphere.datasource.ds_master_0_slave_0.password=
spring.shardingsphere.datasource.ds_master_0_slave_0.max-active=16
spring.shardingsphere.datasource.ds_master_0_slave_1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_master_0_slave_1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_master_0_slave_1.jdbc-url= spring.shardingsphere.datasource.ds_master_0_slave_1.username=
spring.shardingsphere.datasource.ds_master_0_slave_1.password=
spring.shardingsphere.datasource.ds_master_0_slave_1.max-active=16
spring.shardingsphere.datasource.ds_master_1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_master_1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_master_1.jdbc-url=
spring.shardingsphere.datasource.ds_master_1.username=
spring.shardingsphere.datasource.ds_master_1.password=
spring.shardingsphere.datasource.ds_master_1.max-active=16
spring.shardingsphere.datasource.ds_master_1_slave_0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_master_1_slave_0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_master_1_slave_0.jdbc-url=
spring.shardingsphere.datasource.ds_master_1_slave_0.username=
spring.shardingsphere.datasource.ds_master_1_slave_0.password=
spring.shardingsphere.datasource.ds_master_1_slave_0.max-active=16
spring.shardingsphere.datasource.ds_master_1_slave_1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds_master_1_slave_1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds_master_1_slave_1.jdbc-url= spring.shardingsphere.datasource.ds_master_1_slave_1.username=admin
spring.shardingsphere.datasource.ds_master_1_slave_1.password=
spring.shardingsphere.datasource.ds_master_1_slave_1.max-active=16
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds_$->{user_id % 2}
spring.shardingsphere.sharding.binding-tables=t_order,t_order_item
spring.shardingsphere.sharding.broadcast-tables=t_address
spring.shardingsphere.sharding.default-data-source-name=ds_master_0
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds_$->{0..1}.t_order_$->{0..1}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=123
spring.shardingsphere.sharding.tables.t_order_item.actual-data-nodes=ds_$->{0..1}.t_order_item_$->{0..1}
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item_$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order_item.key-generator.column=order_item_id
spring.shardingsphere.sharding.tables.t_order_item.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order_item.key-generator.props.worker.id=123
# 主从数据源,分库数据源配置
spring.shardingsphere.sharding.master-slave-rules.ds_0.master-data-source-name=ds_master_0
spring.shardingsphere.sharding.master-slave-rules.ds_0.slave-data-source-names=ds_master_0_slave_0, ds_master_0_slave_1
spring.shardingsphere.sharding.master-slave-rules.ds_1.master-data-source-name=ds_master_1
spring.shardingsphere.sharding.master-slave-rules.ds_1.slave-data-source-names=ds_master_1_slave_0, ds_master_1_slave_1
# sharding-jdbc的模式
spring.shardingsphere.mode.type=Memory
# 开启shardingsphere日志
spring.shardingsphere.props.sql.show=true
3.6.3 测试验证过程说明
- DDL操作所属
JPA自动创建用于测试的表,如下图,在配置了sharding-jdbc的分库路由规则的情况下,client端执行DDL,sharding-jdbc会自动根据分表规则创建对应的表;如t_address是广播表在ds_0和ds_1上都会创建, t_address,t_order,t_order_item按照取模分库,这三个表会分别在ds_0和ds_1上创建。

- 写操作
对于广播表t_address,每写入一条记录会在ds_0和ds_1的t_address表上都写入

对于分库的表t_order,t_order_item,会按照分库字段和路由策略写入到对应实例上的表中。

- 读操作
绑定表下的join查询操作order和order_item,如下图所示。

第四章 结语
ShardingSphere作为一款专注于数据库增强的开源产品,从社区活跃度、产品成熟度、文档丰富程度上来看都是比较好的。其中的sharding-jdbc是基于客户端的分库分表方案,它支持了所有的分库分表的场景,并且无需引入proxy这样的中间层,所以降低了运维的复杂性,相比proxy这种方式由于少了中间层所以时延理论上会比proxy低,其次sharding-jdbc可以支持各种基于SQl标准的关系型数据库如MySQL/PostgreSQL/Oracle/SQlserver等。但由于sharding-jdbc与应用程序集成,目前支持的语言仅限于Java,对应用程序有一定的耦合性,但sharding-jdbc将所以分库分表的配置从应用程序中分离,这样面临切换其他的中间件时由此带来的变更相对较小。综上所述如果您不希望引入中间层,且使用基于Java语言开发的系统,且需要对接不同的关系型数据库,sharding-jdbc将会是一个不错的选择。
相关博客
百尺竿头更进一步 – 拓展 Aurora的读写能力之Gaea篇
百尺竿头更进一步 – Amazon Aurora的读写能力扩展之ShardingSphere-Proxy篇
本篇作者