亚马逊AWS官方博客
基于 Lambda + DynamoDB 托管服务构建灵巧型 HPC 集群
1.应用场景
在客户运用云端计算集群来处理诸如分子匹配分析或中小规模基因分析的任务时,首先需要及时响应样本输入,由于有任务完成时限的要求,所以在较短的一段时间内对于 HPC 的算力需求仍会达到几千到几万个 vCPU 的较大规模,这些 vCPU 根据数据并行的方式进行分片计算,在 AWS Batch 批量处理任务管理服务或 AWS ParallelCluster 开源集群管理工具来配置集群的方式之外,需要能有一个更轻量级的、可自定义并行规则的集群调度方式。同时客户非常关注成本控制,需要将单个输入样本的计算成本尽可能压低。
概括地看,客户希望设计一种灵巧型的 HPC 来同时满足以下场景特点:
- 弱耦合型:计算过程中间很少数据交互;
- 随来随算: HPC 的算力构建基于事件触发,能即时响应;
- 数据切分:计算任务可基于数据维度来分解并行的;
- 运维零压:部署完成后,平时基本是零维护和零管理;
- 足够节省:平时运维低费用,且算完及时回收资源以降成本。
2.架构设计
从降低配置运维的角度出发,我们考虑尽可能多地采用托管型服务来构建,计算集群的调度由 Lambda 函数来串接,分析任务的切片对应关系和各数据片的状态基于 DynamoDB 数据库来存储,计算节点调用 Spot 实例来降低成本,计算任务的参数配置通过 API Gateway 提供给前后端来调用。整个架构设计图如下所示。

本场景里的计算是将样本文件与海量已知样本数据做匹配分析计算,我们将一个计算任务(Mission)按照不同的样本比对区间切分成多个分片计算事务(Transactions)。数据处理的流程:
- 分析任务的输入是由样本文件上传至 S3 源端Src桶来触发,处理 Lambda 函数(lightScheduler)负责划分计算事务并将Mission和Transactions的信息记入DynamoDB的任务信息表(tblMission)和事务信息表(tblTrans)中,并发起启动对应数量的 Spot 实例。
- Spot 实例根据计算节点的AMI镜像启动,根据源文件名和事务表记录信息执行计算脚本,计算完成后结果文件输出至 S3 存储的 Result 桶,并自行终止实例。
- 结果文件以消息驱动结果处理函数(RsltProc)来进行结果汇集和计算任务完成通知。
- 计算任务的配置通过 Lambda 配置函数(MissionCfg)来写入tblMission表。
3.部署与配置
以下示例部分的完整Python代码可参见:https://github.com/Iwillsky/lightHPC
- Lambda中的处理函数
在Lambda服务的控制台中新一个名为“lightScheduler”的处理函数,Runtime 类型选择“Python3.7”,权限配置上分配一个包含 EC2、DynamoDB、SNS 服务足够操作权限的角色。

处理函数中的事务表写入部分的代码如下。
处理函数启动 Spot 实例的代码如下,启动时将对应样本文件名通过实例 Tag 值传递至实例。
代码拷贝完成后,在右上角 Actions 菜单内选择“Publish new version”。
- S3中的触发设置
在S3控制台 Bucket 属性页面的 Events 选项中配置事件驱动发送给“Lambda Function”,并指定 Lambda 处理函数名为 LightScheduler 。

- 计算节点的执行过程
先启动一个 Amazon Linux2 的实例并拷贝好 jobrun.py 脚本文件,手动创建好计算节点的AMI镜像。再进行启动模板的配置,EC2 的控制台界面中 Launch Template 的配置参数如下图,设置好启动对应的 AMI 镜像、实例类型和安全组。

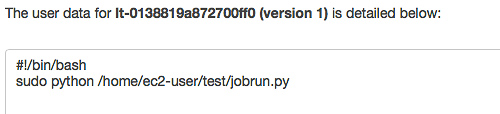
在启动模板 Advanced details 的 User Data 中填入加载的启动脚本,如下图。
Demo 测试脚本用随机延迟来模拟处理耗时并更新计算进度,如希望准确模拟工作负载的情况,可将模拟延迟改为对应脚本的调用。代码示例如下所示。
整个任务处理完成后发送 SNS 通知到对应的 SNS topic 目标,代码如下。
- 配置接口的开放
任务参数配置的接口在 API Gateway 中的 Method Execution 页面的配置如下图。

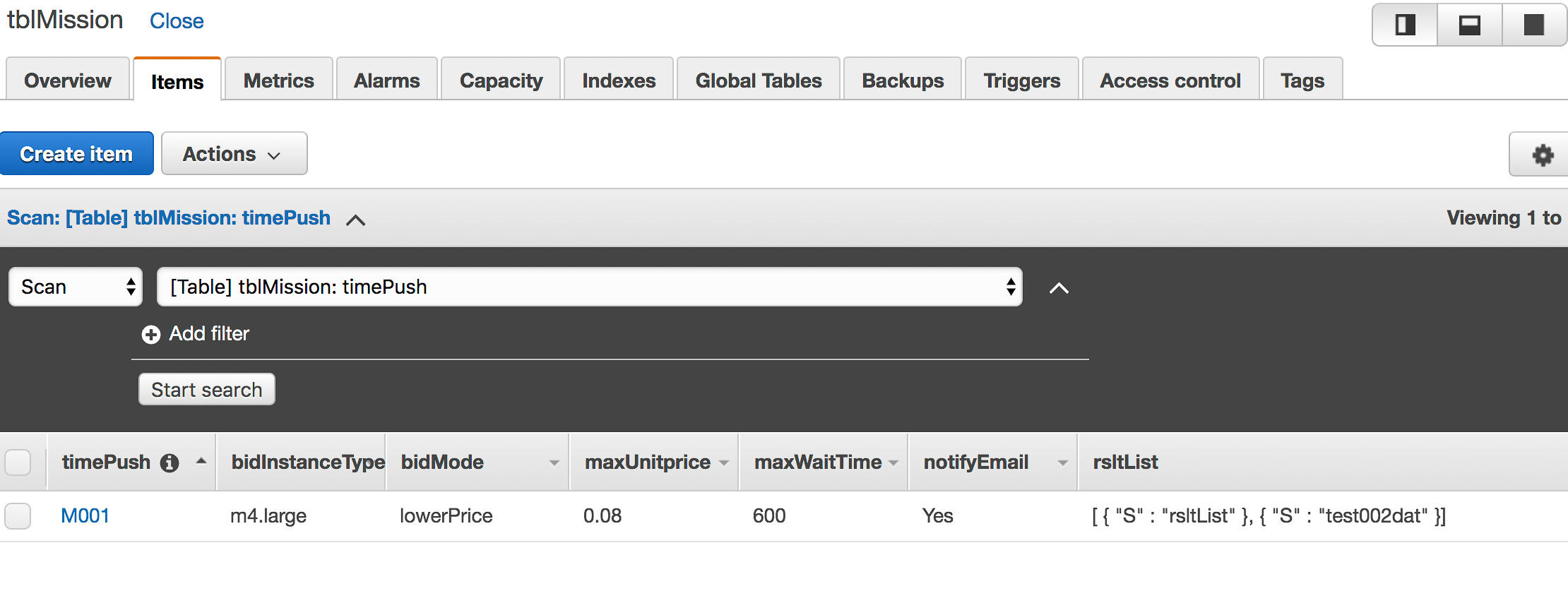
- 运行截图
系统搭建完成后,测试任务运行时 tblMission 和 tblTrans 表的数据记录如下图所示。

如果计算资源要求比较高,记得 AWS 账号中实例运行数的 Limit 限制提前申请做提升。
4.扩展讨论
- 对 Spot 实例中断的处理
该架构中并未采取轮询式中断通知检测,这是基于发生中断概率非常低的实际,如果一个计算事务在过程中被中断,可通过 tblTrans 表中记录检查的方式再重新触发。如果事务切分颗粒度不够小的情况下实际项目中还可设置检查点的方式来减少重算的工作量。
- 自定义成本策略
原型实现时仅采用价格符合的策略,实际项目中如果 Spot 资源数不足以满足计算需求时,而计算时限又有要求的情况下,可采取按 Spot 和按需实例混搭配置 EC2 Fleet 的方式来满足,可在Lambda处理函数中增加这部分处理逻辑。
- 扩展日志保存功能
原型中的 DynamoDB 库表主要是当前计算状态的记录与更新,实际项目如果需要日志记录的功能,可在 Lambda 处理函数、计算节点脚本和 Lambda 结果处理函数三处分别增加 Cloud Watch Log 记录的推送。
5.参考链接
- Lambda 配置与部署:https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/getting-started-create-function.html
- API Gateway 配置:https://docs.aws.amazon.com/zh_cn/apigateway/latest/developerguide/set-up-lambda-integrations.html
- S3 事件触发配置:https://docs.aws.amazon.com/zh_cn/AmazonS3/latest/user-guide/enable-event-notifications.html
- SNS 通知配置:https://docs.aws.amazon.com/zh_cn/sns/latest/dg/sns-tutorial-create-topic.html
- AMI 镜像制作:https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/creating-an-ami-ebs.html
- 启动模板配置:https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/ec2-launch-templates.html#create-launch-template
(本文参考难度为301级别)