亚马逊AWS官方博客
全新 — 介绍 Amazon SageMaker Data Wrangler 中实时和批量推理的支持
要构建机器学习模型,机器学习工程师需要开发数据转换管道来准备数据。设计管道的过程非常耗时,需要机器学习工程师、数据工程师和数据科学家之间的跨团队协作,才能在生产环境中实现数据准备管道。
Amazon SageMaker Data Wrangler 的主要目标是简化数据准备和数据处理工作负载。使用 SageMaker Data Wrangler,客户可以在单个可视界面上简化数据准备过程和数据准备工作流程的所有必要步骤。SageMaker Data Wrangler 缩短了快速原型设计和将数据处理工作负载部署到生产环境的时间,因此客户可以轻松地与 MLOP 生产环境集成。
但是,在实时推理期间,在模型训练中应用于客户数据的转换需要应用于新数据。如果在实时推理端点中不支持 SageMaker Data Wrangler,客户需要编写代码以在预处理脚本中复制流程中的转换。
介绍 Amazon SageMaker Data Wrangler 中实时和批量推理的支持
我很高兴与大家分享,您现在可以部署 SageMaker Data Wrangler 的数据准备流程,用于实时和批量推理。作为 Amazon SageMaker 推理管道中的一个步骤,您可以重复使用在 SageMaker Data Wrangler 中创建的数据转换流程。
SageMaker Data Wrangler 对实时和批量推理的支持可加快生产部署,因为无需重复实施数据转换流程。您现在可以将 SageMaker Data Wrangler 与 SageMaker 推理集成。使用易于使用的 SageMaker Data Wrangler 的点击式界面创建的数据转换流程,包含主要组件分析和独热编码等操作,将在推理期间处理您的数据。这意味着您无需为实时和批量推理应用程序重建数据管道,可以更快地投入生产。
实时和批量推理入门
让我们来看看如何使用 SageMaker Data Wrangler 的部署支持。在这种情况下,我在 SageMaker Data Wrangler 内部有一个流程。我需要做的是使用 SageMaker 推理管道将此流程集成到实时和批量推理中。
首先,我要对数据集进行一些转换,为训练做好准备。
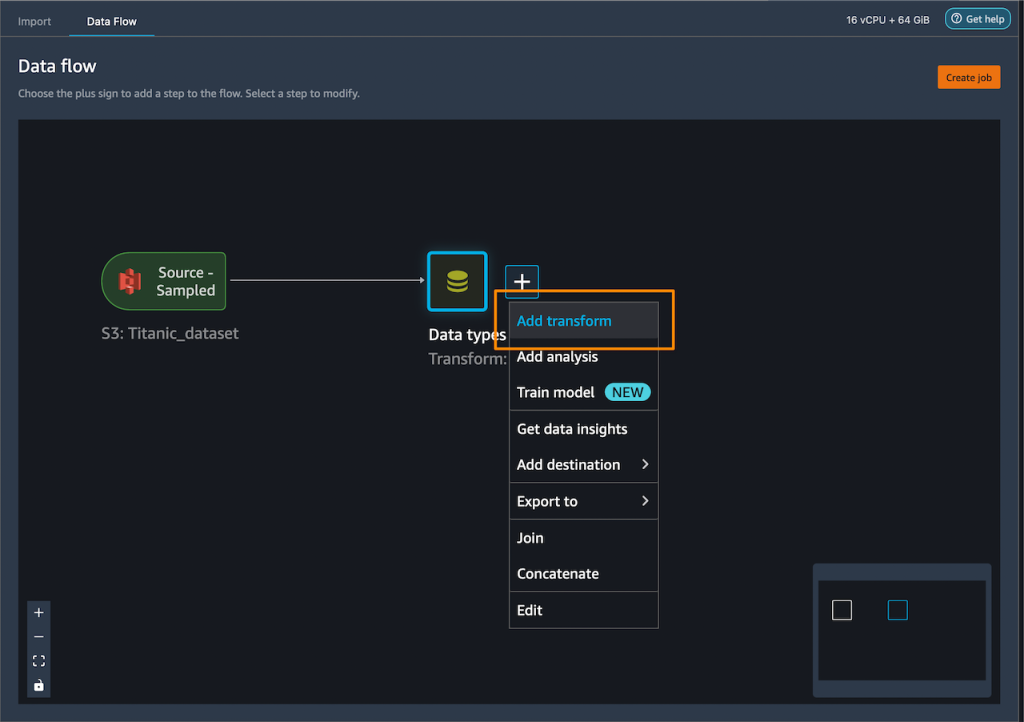
我在分类列上添加了独热编码来创建新功能。
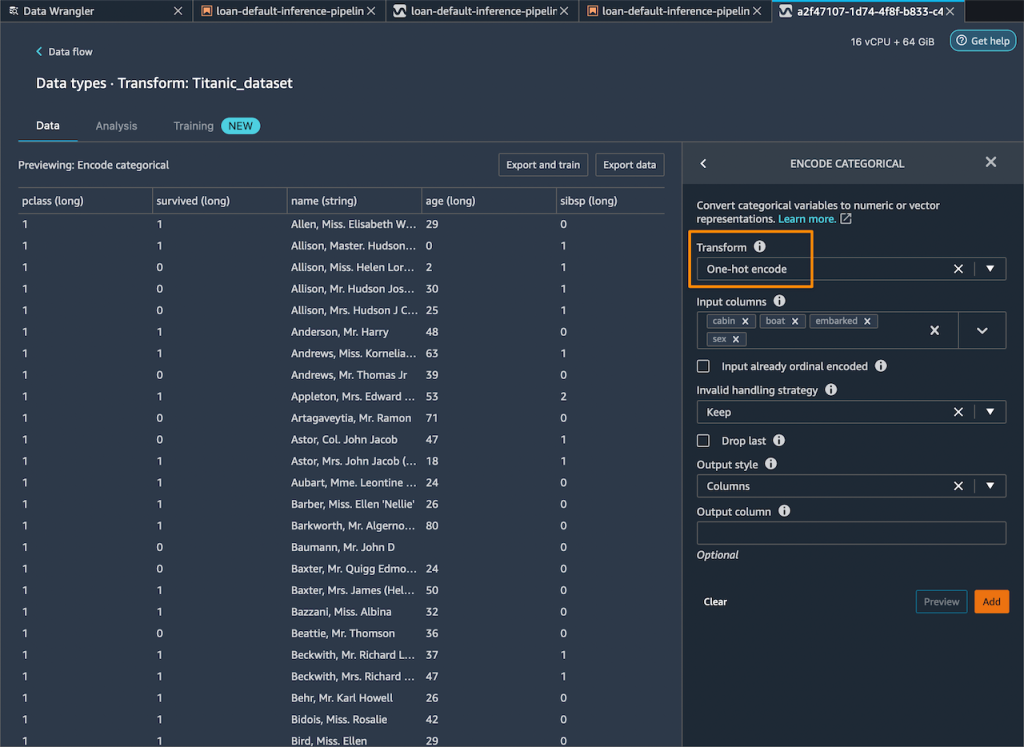
然后,我删除训练期间无法使用的剩余字符串列。

我的生成的流程现在包含两个转换步骤。
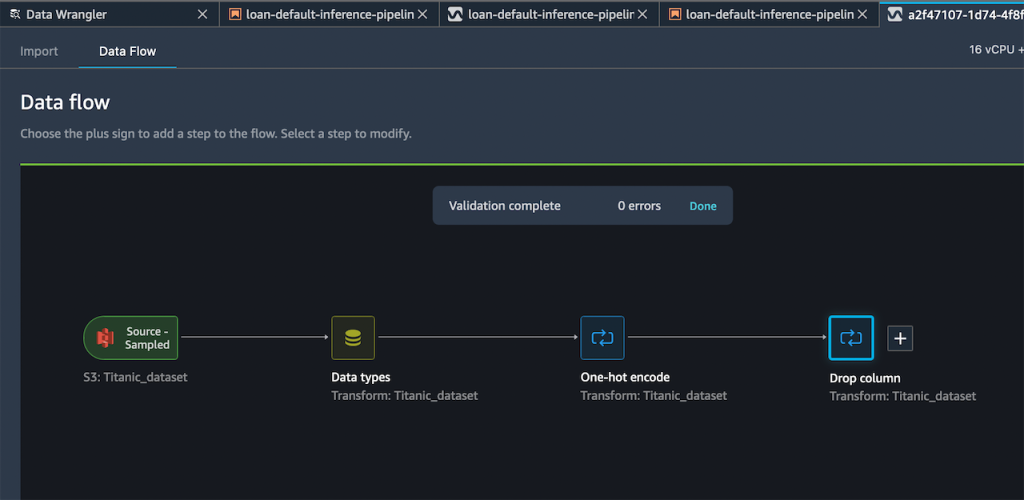
在我对添加的步骤感到满意之后,可以展开导出至菜单,然后可以选择导出到 SageMaker Inference Pipeline(通过 Jupyter Notebook)。

我选择导出到 SageMaker Inference Pipeline,SageMaker Data Wrangler 将准备完全定制的 Jupyter notebook,将 SageMaker Data Wrangler 流程与推理集成。生成的 Jupyter notebook 执行了一些重要操作。首先,在 SageMaker 管道中定义数据处理和模型训练步骤。下一步是运行管道,使用 Data Wrangler 处理我的数据,然后使用处理过的数据来训练用于生成实时预测的模型。然后,将我的 Data Wrangler 流程和经过训练的模型作为推理管道部署到实时端点。最后,调用我的端点进行预测。

此功能使用 Amazon SageMaker Autopilot,我能够轻松构建 ML 模型。我只需要提供 SageMaker Data Wrangler 步骤的输出转换后的数据集,然后选择要预测的目标列。其余部分将由 Amazon SageMaker Autopilot 处理,探索各种解决方案以找到最佳型号。

默认情况下,将 use_automl_step 变量笔记本中 AutoML 用作 SageMaker Autopilot 的训练步骤处于启用状态。使用 AutoML 步骤时,我需要定义 target_attribute_name 的值,这是我想要在推理期间预测的数据列。如果我想改用 XGBoost 算法来训练模型,还可以将 use_automl_step 设置为 False。
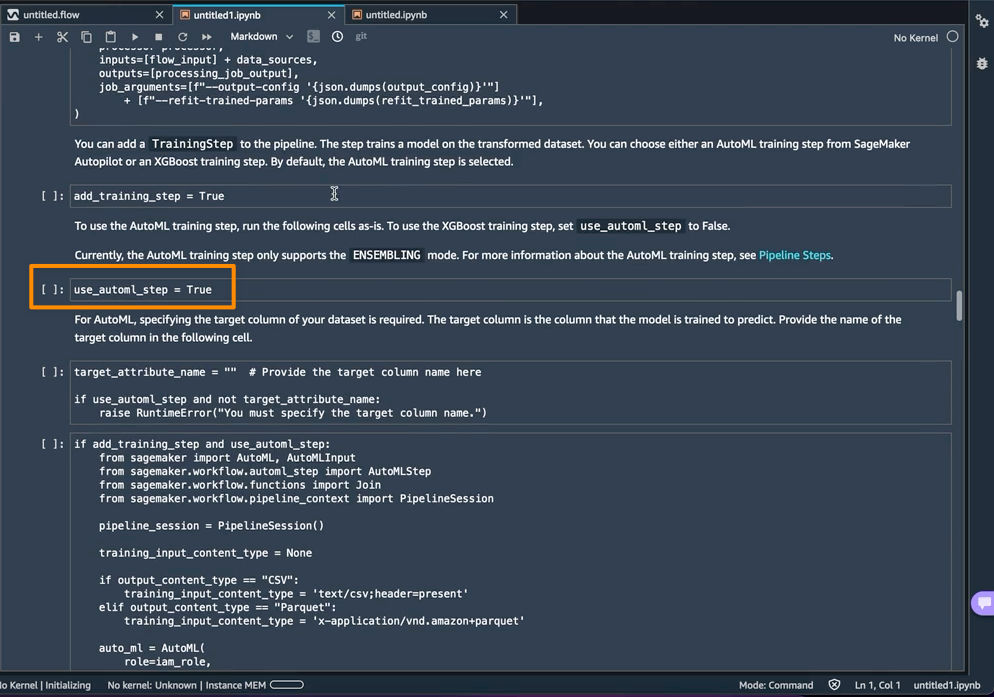
另一方面,如果我想改用在本笔记本之外训练过的模型,那么可以直接跳到笔记本的 Create SageMaker Inference Pipeline(创建 SageMaker 推理管道)部分。在这里,我需要将 byo_model 变量的值设置为 True。我还需要提供 algo_model_uri 的值,这是我的模型所在的 Amazon Simple Storage Service (Amazon S3) URI。使用笔记本训练模型时,这些值将自动填充。
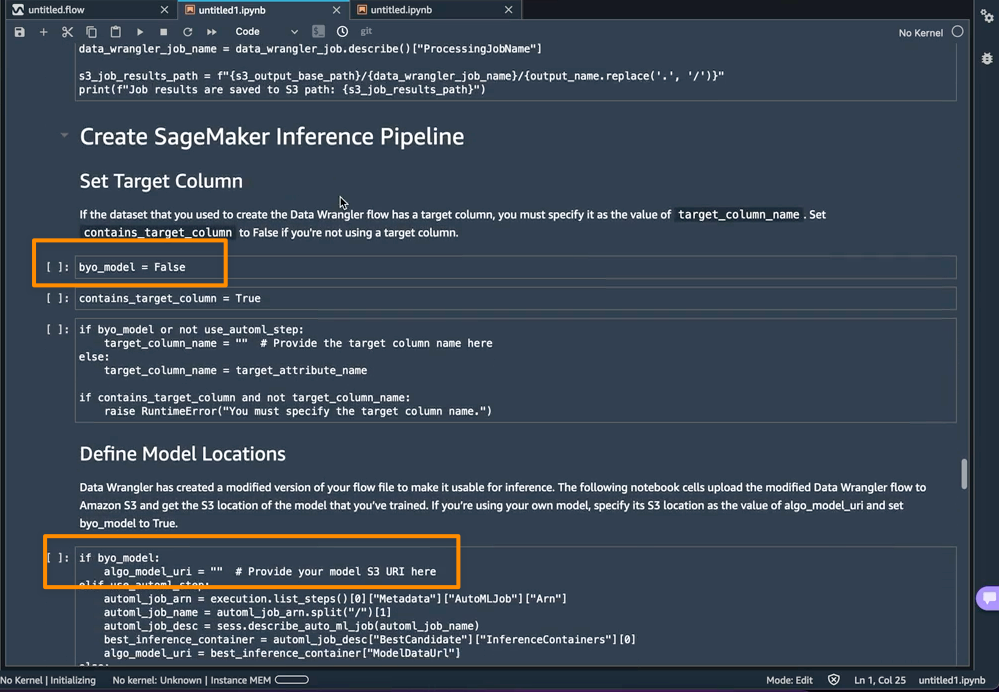
此外,此功能还将压缩包保存在我的 SageMaker Studio 实例上的 data_wrangler_inference_flows 文件夹中。此文件是 SageMaker Data Wrangler 流程的修改版本,包含推理时要应用的数据转换步骤。将从笔记本上传到 S3,可用于在推理管道中创建 SageMaker Data Wrangler 预处理步骤。
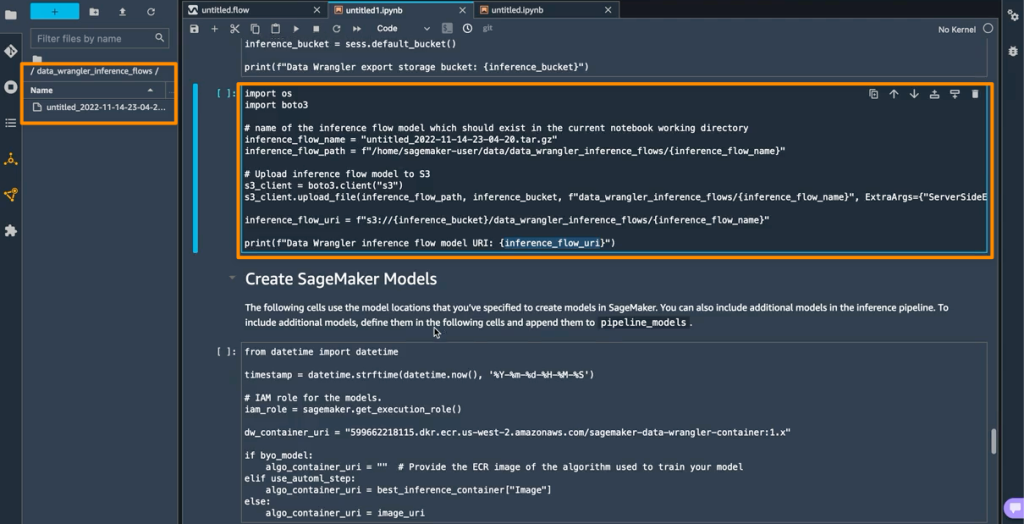
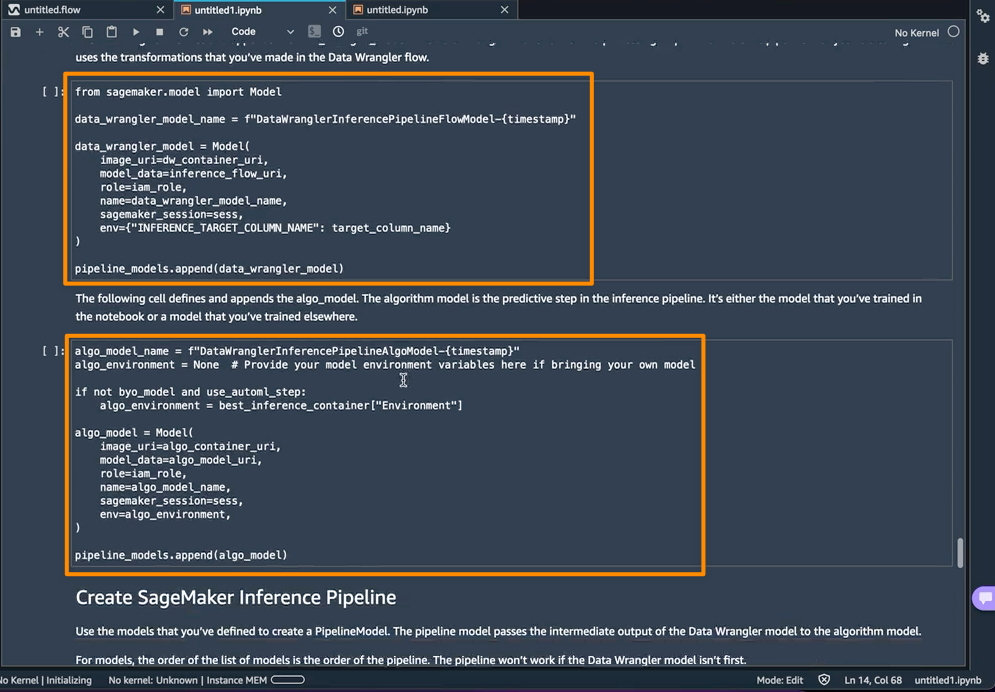
下一步是笔记本创建两个 SageMaker 模型对象。第一个对象模型是带有变量的 data_wrangler_model 的 SageMaker Data Wrangler 模型对象,第二个对象模型是变量为 algo_model 的算法模型对象。对象 data_wrangler_model 将用数据形式提供输入,这些输入已处理为 algo_model 进行预测。
笔记本的最后一步是创建 SageMaker 推理流水线模型,并将其部署到端点。
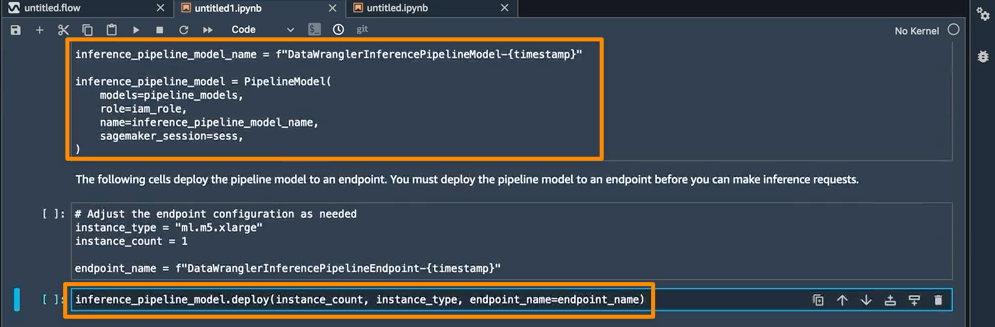
完成部署后,我将获得一个可用于预测的推理端点。借此功能,推理管道使用 SageMaker Data Wrangler 流程将推理请求中的数据转换为经过训练的模型可以使用的格式。
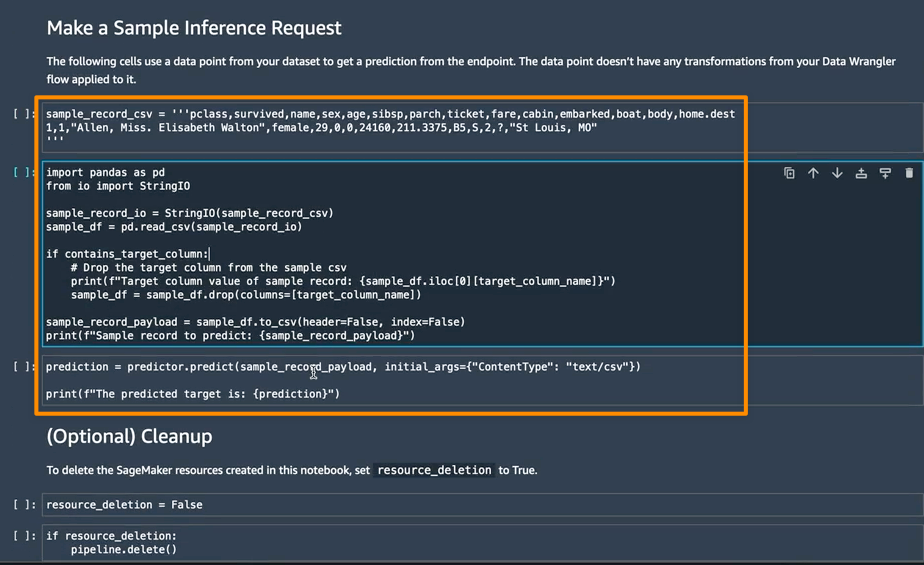
在下一节中,我可以在 Make a Sample Inference Request(提出样本推理请求)中运行单个笔记本单元。如果需要通过使用未处理的数据中的单个数据点调用端点快速检查端点是否正常工作,这很有用。Data Wrangler 会自动将这个数据点放到笔记本中,所以不必手动提供。
注意事项
增强的 Apache Spark 配置 — 在 SageMaker Data Wrangler 中,在数据保存到 Amazon S3 时,现在可以轻松配置 Apache Spark 如何对 SageMaker Data Wrangler 任务的输出进行分区。添加目标节点时,您可以设置分区数,与写入 Amazon S3 的文件数相对应,也可以指定分区依据的列名,将这些列具有不同值的记录写入 Amazon S3 中的不同子目录。此外,您还可以在提供的笔记本中定义配置。

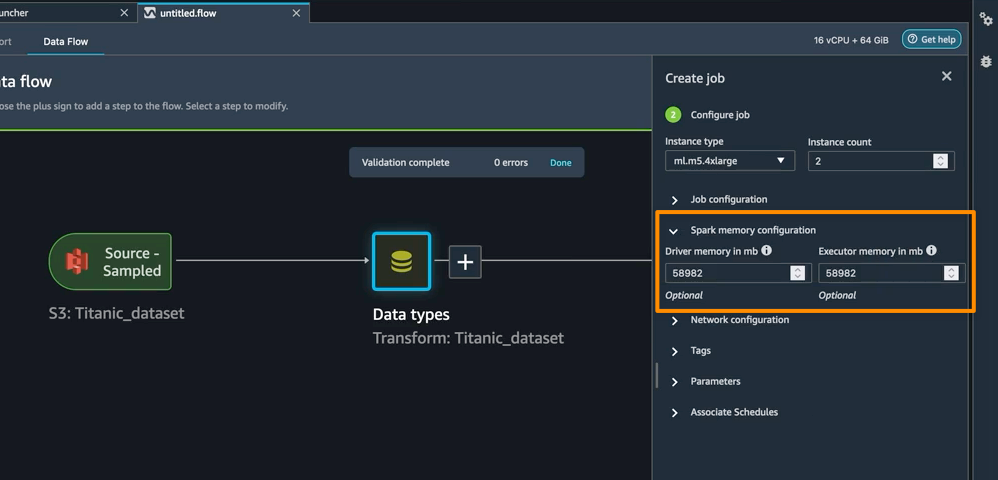
作为 Create job(创建作业)工作流程的一部分,您还可以为 SageMaker Data Wrangler 处理作业定义内存配置。您会在笔记本电脑中找到类似的配置。
可用性 — SageMaker Data Wrangler 支持实时和批量推理,以及针对数据处理工作负载的增强型 Apache Spark 配置,通常在 Data Wrangler 目前支持的所有 AWS 区域都可用。
要开始使用 Amazon SageMaker Data Wrangler 支持实时和批量推理部署,请访问 AWS 文档。
祝大家构建顺利
– Donnie