亚马逊AWS官方博客
基于 NodeLocal DNSCache 优化 EKS DNS 查询时延和深层降低跨 AZ 流量费
简介
微服务是一种软件开发的组织和架构方法,它可以加快软件交付周期、增强创新和自主性,提高软件的可维护性和可伸缩、可扩展性,同时也提高了企业开发和发布软件服务的能力。使用微服务架构,软件产品将由多个独立的、可通过API进行交互的服务组成。这些服务将由各个小团队独自负责。
EKS 为客户提供在 AWS 云和本地启动、运行和扩展 Kubernetes 应用程序所需的灵活性。Amazon EKS 可帮助您提供高度可用且安全的集群,并自动化补丁、节点预置和更新等关键任务。
随着越来越多的客户通过容器化上云,EKS的优化成为了一个我们必须经历的过程。例如对资源调度,网络,存储以及成本等的优化。本文我们将描述在EKS使用过程中对于DNS网络优化的实践以及通过以上实践深度降低跨可用区(AZ)流量成本的整体。此方案在AWS大型企业客户得到实践,并证明有显著的效果。
问题现状
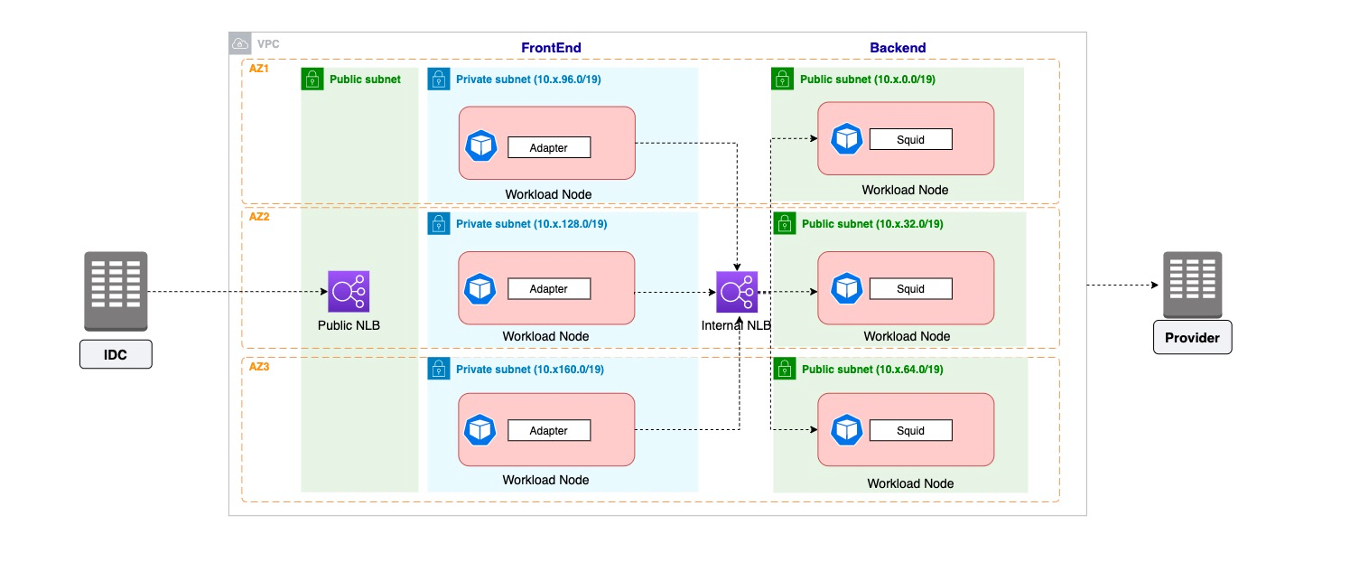
客户的 EKS 集群部署在美西俄勒冈区域,客户从中国区的 IDC调度美西的 EKS 集群,再从美西EKS集群去供应商查询生产信息。EKS的集群的架构如下,在俄勒冈有3个AZ,6个子网,Frontend有三个基于APP(无状态服务)的NodeGroup(一个Node Group 有多个nodes分别在3个私有子网),Backend有三个基于Squid(网络代理)服务的NodeGroup(一个Node Group 有多个nodes分别在3个公有子网),Frontend APPS通过跨AZ方式把流量发送到NLB,NLB在通过跨AZ方式把流量发送到Backend Squid,NLB是Squid部署的service,最终 Squid服务把流量打到Internet去访问后端的供应商,每天会有30TB东西向流量透过NLB,详情请参考如下架构图。
优化前的架构图
问题1(性能问题):
在业务高峰期,DNS查询有超时的情况发生,延时平均为1.5秒,最高达到2.5秒。
问题2(成本问题):
由于东西向流量都是默认以跨AZ访问,每天会有4.81TB的跨AZ流量,产生48.71美金的跨AZ费用。而这些跨AZ的流量从客户的业务场景切入,是不必要的。
优化方案:
- 在每个Node部署基于DaemonSet的NodeLocal DNSCache,通过Node LocalDNS缓解CoreDNS服务的DNS查询压力,以及CoreDNS所在Node的单网卡最大1024 Package限制。(https://docs.aws.amazon.com/vpc/latest/userguide/vpc-dns.html#vpc-dns-limits)
- 通过Node LocalDNS 服务监听服务DNS 请求,对特定域名(基于NLB的暴露的服务)的访问直接返回特定的同子网IP,减少跨AZ流量。
- 配置NLB所在的Service YAML文件 将流量只路由到POD所在的node,减少IPTables 转发带来的跨可用区流量问题。
前置条件:
- 此方案基于1.6.6的CoreDNS组件,建议使用1.15到1.17的EKS版本,1.18或以上的EKS版本也能使用。
- 需要通过CLI/Console得到NLB在3个AZ的Private IP地址。
- 得到Frontend和Backend所在6个子网的CIDR信息。
收集相应信息如下
| AZ 分布 | Frontend Subnet | BackendSubnet | NLB IP(xxxx.elb.<region>.amazonaws.com): |
| AZ1 | 10.X.96.0/19 | 10.X.0.0/19 | 10.X.122.101 |
| AZ2 | 10.X.128.0/19 | 10.X.32.0/19 | 10.X.158.126 |
| AZ3 | 10.X.160.0/19 | 10.X.64.0/19 | 10.X.164.176 |
优化后方案架构图:
部署步骤
- 部署NodeLocalDns
LocalNodeDNS 或监听所在Node 的POD的DNS请求,并返回相应解析地址.架构图如下:
本次利用LocalNodeDns 的Cache功能缓解对CoreDNS所在Node的单网卡最大1024 Package 查询限制,提升访问性能
其次利用LocalNodeDNS 监听访问特定服务暴露NLB的域名,返回相应同AZ对应的NLB IP ,减少跨流量访问的成本
在部署LocalNodeDNS ,需要获得部署所在的node的IP ,来判断所在子网,来绑定NLB 相应子网IP,参考如下LocalNodeDNS YAML模板
LocalNodeDNS模板本身需要修改根据集群信息,需要进行如下设置:
可参考官方文档:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/nodelocaldns
2.本次需要使用LocalNodeDNS ‘Hosts‘ 组件对相应的域名解析通过本地/etc/hosts 文件中获取,官方的LocalNodeDNS 镜像并没有安装此插件,需要使用CoreDNS 重新构建所需镜像.也可使用本次已经构建好的镜像进行部署,public.ecr.aws/u1q9i0s7/localdns
利用含有‘Host’组件的新镜像部署,并启用相应的解析功能
3. 为保证NLB不垮可用区分发流量,需要关闭相应的跨可用区功能(如下aws-load-balancer-cross-zone-load-balancing-enabled:false),并将流量策略改成local(如下externalTrafficPolicy: local)
externalTrafficPolicy
通过将externalTrafficPolicy设置为Local,我们可以通过使用类型为LoadBalancer的服务(使用NodePort功能并通过该节点端口将后端添加到负载平衡器)来允许此外部流量策略。 使用负载平衡器,我们会将每个Kubernetes节点添加为后端,但是我们可以依靠负载平衡器的运行状况检查功能,仅将流量发送到相应NodePort响应的后端(即,只有NodePort代理规则指向健康的pod的节点).
这将减少负载均衡器上流量需要经过的kube-proxy 转发次数和跨AZ转发的可能。
另外这种模式下LoadBalancer 通常不会考虑Pod 在节点的分布情况,可能会造成Pod流量的分发的不平衡。在EKS 1.18版本中,我们已经支持基于NLB-IP模式部署,也可以参考这种部署方式,达到同样的效果。
4. 为避免该情况,我们可以通过使用Pod Anti-affinity 尽量的将Pod平衡的 水平扩展到足够多的节点上.
完整部署参考yaml模板:https://github.com/hades1712/localdns/blob/main/proxy.yaml
优化结果:
1. 优化前和优化后的性能对比:
优化前:
峰值在平均1.5秒的延时,峰值在2.5秒的延时
优化后:
保持在平均300毫秒的延时
延时优化了将近80%
2. 优化前和优化后的跨可用区(AZ)流量对比:
优化前:
跨AZ流量为每天4.817TB
费用为每天$48.17
费用为每月$1445.1
优化后:
跨AZ流量为每天261.75GB(流量优化了94.6%)
费用为每天$2.62(费用优化了94.6%)
费用为每月$78.6
可以发现,无论是跨可用区(AZ)流量还是费用都节省了94.6%!
结束语:
通过以上优化,我们分别降低了DNS的延迟达80%以及优化了跨AZ的流量和成本94.6%。对于东西向流量比较大的业务场景,这是一次显著而有效的网络优化。随着EKS的版本迭代,我们期能结合最新的EKS特性和功能,持续的对于EKS的网络做优化,并帮助客户更简易,有效并且低成本的上云。
文献参考:
Using NodeLocal DNSCache in Kubernetes clusters https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/
External Traffic Policy: https://kubernetes.io/docs/concepts/services-networking/service/
CoreDNS Hosts Plugin: https://coredns.io/plugins/hosts/
CoreDNS Mannual: https://coredns.io/manual/toc/