亚马逊AWS官方博客
使用 Simple Replay 实用程序简化 Amazon Redshift RA3 迁移评估
Amazon Redshift 是快速、广受欢迎的完全托管式云数据仓库,允许您使用标准 SQL 处理数据仓库、运营数据库和数据湖中的 EB 级数据。它提供不同的节点类型以适应各种工作负载;您可以根据需求从 RA3、DC2 和 DS2 中选择。RA3 是最新的实例类型,它允许您独立扩展计算和存储并支付其费用,还支持跨集群数据共享和跨可用区集群重新定位等高级功能。有关升级时节点计数和类型建议的更多信息,请参阅升级到 RA3 节点类型。
博文借助带托管存储的新型 Amazon Redshift RA3 节点扩展云数据仓库和降低成本与Amazon Redshift 基准测试:比较 RA3 与DS2 实例类型详细介绍了从 DS2 迁移到 RA3 的优势。在了解了 RA3 的优势之后,我们的许多现有 DC2 客户在成功评估其性能后已迁移到 RA3。但是,此评估主要通过手动完成,这需要您复制工作负载以评估在新节点上的性能。
您可以使用 Simple Replay 工具进行假设分析并评估工作负载在不同场景中的性能。例如,您可以使用该工具在 RA3 等新实例类型上对实际工作负载进行基准测试、评估新功能或评估不同的集群配置。它还包括增强了对使用 COPY 和 UNLOAD 语句 重放数据摄入和导出管道的支持。要开始和 重放您的工作负载,请从 Amazon Redshift GitHub 存储库下载该工具。
在本文中,我们将介绍有关通过 Amazon Redshift Simple Replay 实用程序自动评估 Amazon Redshift RA3 实例的步骤。如果您使用旧一代 DS2 和 DC2 节点类型在 Amazon Redshift 中运行生产工作负载,则可以使用此解决方案自动从源生产集群中提取工作负载日志并在隔离的环境中 重放这些日志,以便您直接无缝地对比这两个 Amazon Redshift 集群。
先决条件
此解决方案使用 AWS CloudFormation 自动预置您 AWS 账户中的所有必需资源。有关详情,请参阅 AWS CloudFormation 使用入门。
作为此解决方案的先决条件,您需要完成以下步骤。您可能需要拥有 AWS 账户的管理员访问权限,才能执行这些步骤以及随后部署此解决方案。
- 在 Amazon Redshift 控制台的源 Amazon Redshift 集群中启用审计日志记录,然后指定 Amazon Simple Storage Service (Amazon S3) 存储桶位置以保存日志文件。有关详情,请参阅数据库审计日志记录。
- 将参数组 enable_user_activity_logging 更改为 true。有关详情,请参阅使用控制台管理参数组。
- 重新启动集群。
- 在计划部署 CloudFormation 模板的 AWS 账户中创建 Amazon Elastic Compute Cloud (Amazon EC2) 密钥对。有关详情,请参阅使用 Amazon EC2 创建密钥对。
解决方案概览
该解决方案包括两个 CloudFormation 模板,用于执行工作负载的提取和 重放。您可以在托管 Amazon Redshift 集群的同一账户中部署这两个模板,这是我们推荐的方法。或者,您也可以在生产账户运行提取模板,在独立的开发账户运行重放模板来执行此评估,如下图所示。
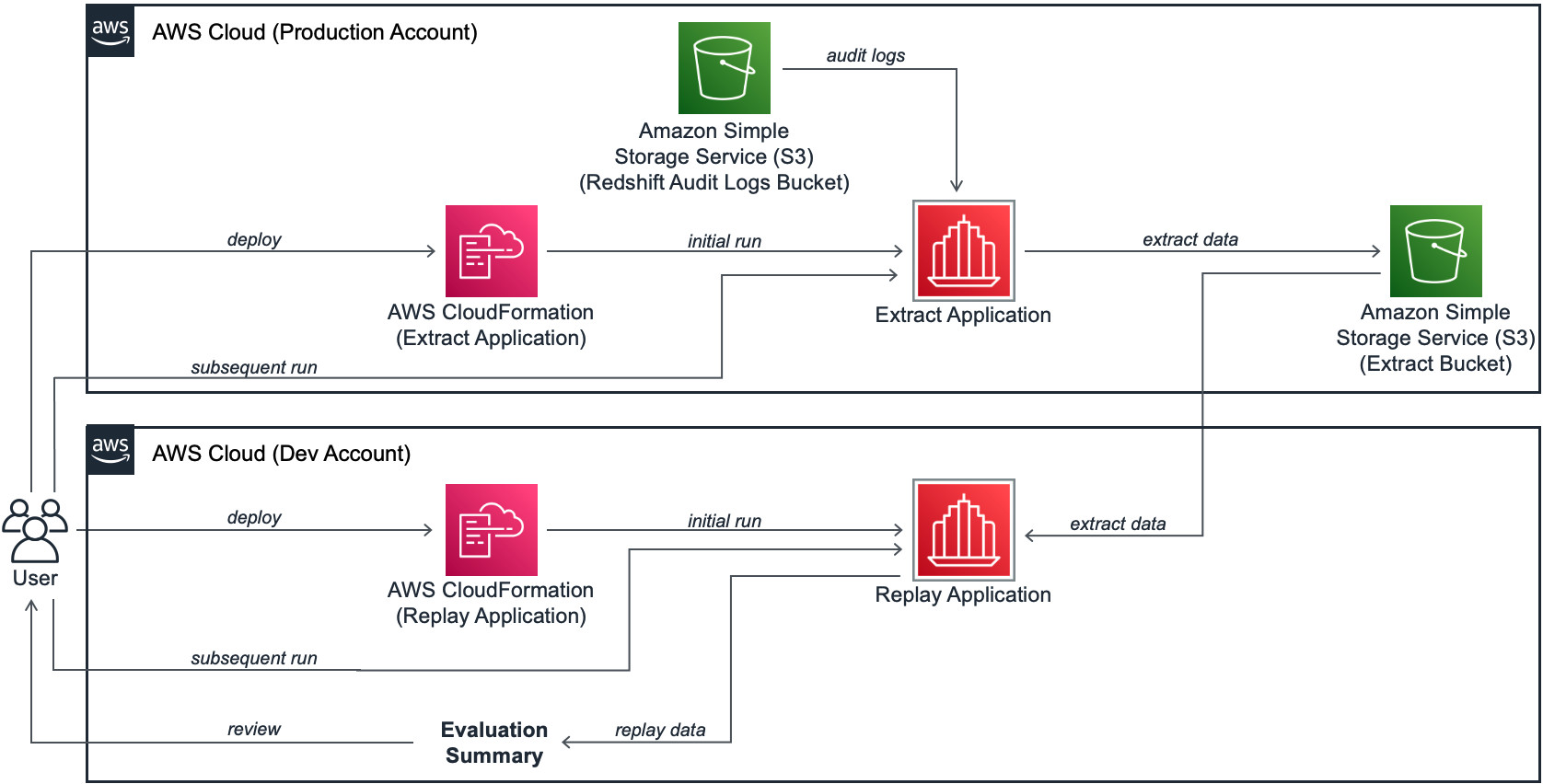
该流程使用 AWS Step Functions 和 AWS Lambda 来编排端到端工作流以进行提取和 重放。第一个模板在源账户中部署提取应用程序。这将从 S3 存储桶中提取审计日志以进行 Amazon Redshift 审计日志记录。它将其存储在为 重放-提取流程创建的新 S3 存储桶中。它还会创建您集群的手动快照,并授权 重放账户恢复快照。
第二个模板将 重放应用程序部署在开发账户中(如果您选择不在源账户中运行 重放)。它使用来自提取应用程序的 Amazon S3 文件,并生成 重放的自动评估摘要。
端到端工作流:提取流程
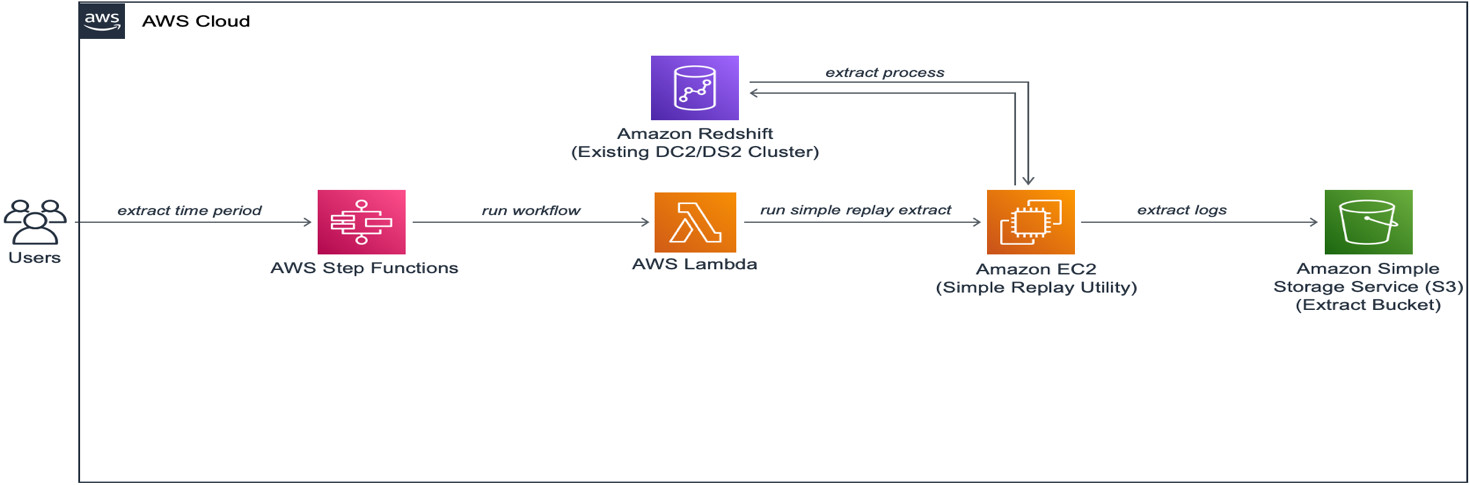
提取流程在您输入要运行此流程的时间间隔时开始。它自动从源集群中提取审计日志,并将这些日志存储在该账户的新 S3 存储桶中。它还会部署大小为 m5.large 的 Amazon EC2 实例(安装有 Simple Replay 实用程序)。下图展示了该解决方案架构。
下图显示了用于提取流程的 AWS Step Functions 状态机。

状态机执行以下步骤,将源集群元数据提取到提取 S3 存储桶中:
- 等待源集群处于可用状态。
- 使用与集群标识符字符串连接的标识符 ra3-migration-evaluation-snapshot-,创建源集群的手动快照。
- 将快照授权给您计划运行 重放流程的目标账户。
- 将源集群配置参数上传到提取 S3 存储桶。
- 运行提取流程以从源集群获取日志并将其放入提取 S3 存储桶中。
提取 CloudFormation 模板自动启动提取流程的第一次迭代,但您可以提交带有 start_time 和 end_time 输入参数的状态机来随时重新运行该流程,如以下代码所示:
{“input”: {“start_time”: “<<Extract_Start_Time>>”, “end_time”: “<<Extract_End_Time>>”}}
将 start_date 和 end_date 的值替换为 ISO-8601 格式的实际日期(例如,2021-03-05T12:30:00+00:00)。以下屏幕截图显示了状态机运行输入。

您需要在托管源集群的同一账户中为提取流程部署 CloudFormation 模板。此模板要求您提供以下参数:
- SourceRedshiftClusterEndpoint — 非 RA3 源集群端点,包括端口号和数据库名称。
- AccountIdForReplay — 如果您计划在其他账户中运行 重放流程,请在此参数中输入 12 位 AWS 账户 ID。如果您在同一账户中运行提取和 重放流程,请输入 N/A。
- SimpleReplayStartTime — 您想从源集群运行提取流程的第一次迭代的开始日期,采用 ISO-8601 格式(例如,2021-01-20T21:41:16+00:00)。您可以稍后在提取状态机的输入 JSON 中更改它。
- SimpleReplayEndTime — 您希望从源集群中提取并在目标 RA3 集群中 重放的结束日期和时间,采用 ISO-8601 格式。您可以稍后在提取状态机的输入 JSON 中更改它。请确保开始时间和结束时间之间相差不超过 24 小时。
- ExtractSystemTables — 这是可选步骤(前提是您要提取源集群系统表以供参考)。我们建议将此参数设置为 No,因为它会将 AWS Identity and Access Management (IAM) 角色添加到源集群中,以便从源集群卸载系统表。
- EndUserIamRoleName — 可能在运行提取- 重放评估的最终用户的现有 IAM 角色名称。您可以使用此参数,允许非管理员用户在没有对 AWS 资源的任何其他权限情况下运行提取- 重放状态机。如果您不想提供任何最终用户权限,请输入 N/A。
- EC2InstanceAMI — 基于 Amazon Linux 2 的 EC2 实例的 AMI。我们建议保留此参数的默认 AMI,除非合规性要求需要它。
部署模板后,导航到模板的输出选项卡,其中列出了 重放流程部署所需的一些相关参数。
端到端工作流: 重放流程
此解决方案的第二部分是,使用 CloudFormation 模板在运行提取流程的同一账户或同一区域的其他账户中部署 重放流程。
此流程预置两个 Amazon Redshift 集群:一个为副本集群(配置与源集群完全相同),另一个为具有 RA3 配置的目标集群。它将部署安装了 Simple Replay 实用程序的 M5 系列的两个 EC2 实例,并在这些集群中同时 重放提取的工作负载。由于 重放流程会保留查询和事务之间的时间间隔,以模拟来自源集群的确切工作负载,因此,此流程所花费的时间与您在运行提取流程时提供的 start_time 与 end_time 之间的持续时间大致相同。下图展示了该解决方案的架构。

下图显示了用于 重放流程的 Step Functions 状态机。

状态机执行以下步骤, 重放从提取 S3 存储桶中提取的工作负载:
- 将 Amazon Redshift 参数组更新为与源集群参数组相同的配置,该参数组作为提取流程的一部分保存在提取 S3 存储桶中。
- 如果副本和目标集群不存在,则并行启动其创建集群流程。副本集群将通过与源集群完全相同的配置创建,而目标集群将通过 RA3 配置创建(如果源集群与您在部署 CloudFormation 模板时指定的 RA3 配置的弹性调整兼容)。如果目标 RA3 配置与弹性调整不兼容,则它会通过与副本集群相同的配置创建目标集群。
- 如果上一步由于与弹性调整不兼容而使用非 RA3 配置创建了目标集群,则当该集群可用时,它将针对该集群执行经典的调整。
- 如果目标集群或副本集群处于暂停状态,它将恢复该集群。
- 如果目标集群或副本集群处于可用状态,且针对该集群的任何恢复操作(如果适用)已完成,则它会运行 SQL 脚本,在集群的公共架构中设置一些 Amazon Redshift 对象,以便在集群之间执行自动性能比较。
- 目标集群和副本集群的设置流程完成后,它会同时在两个集群中运行 重放流程,从而运行从源集群中提取的所有 SQL,同时保持与源集群相同的事务顺序和时间间隔。
- 重放流程完成后,它将从副本集群中卸载查询统计数据并将其加载到目标 RA3 集群,从而实现 RA3 集群内各环境之间的直接性能比较。
重放流程的 CloudFormation 模板自动启动 重放流程的第一次迭代,但您可以通过提交不带任何参数的状态机,随时重新运行该流程。此模板要求您提供以下参数:
- SourceAccountNumber — 运行提取流程的源账号。您可以在提取堆栈的输出选项卡上找到它。
- SourceAccountSimpleReplayS3Bucket — 提取 S3 存储桶,由提取模板创建(可在堆栈输出选项卡上找到)。
- SourceRedshiftClusterEndpoint — 非 RA3 源集群端点,包括端口号和数据库名称(可在堆栈输出选项卡上找到)。
- SourceRedshiftClusterKMSKeyARN — AWS Key Management Service (KMS) 密钥 ARN (Amazon Resource Name)(如果您的源 Redshift 集群经过加密)(可在堆栈输出选项卡上找到)。如果源集群经过加密,则您需要在同一账户中运行提取和 重放。
- SourceRedshiftClusterMasterUsername — 与源集群的主用户账户关联的用户名(可在堆栈输出选项卡上找到)。
- SourceRedshiftClusterPrimaryDatabase — 源集群中您要 重放工作负载的主数据库名称。Amazon Redshift 会自动创建名为 dev 的默认数据库,该数据库可能不是您的主数据库。根据您的部署输入正确的值。如果您有多个数据库,则需要一次对一个数据库运行提取和 重放。
- TargetRedshiftClusterNodeType — 要预置的 RA3 节点类型。我们建议按照升级到 RA3 节点类型中的建议使用节点类型和节点计数。
- TargetRedshiftClusterNumberOfNodes — 集群中计算节点的数量。
- EndUserIamRoleName — 可能在运行提取- 重放评估的最终用户的现有 IAM 角色名称。您可以使用此参数,允许非管理员用户在没有对 AWS 资源的任何其他权限情况下运行提取- 重放状态机。如果您不想提供任何最终用户权限,请输入 N/A
- GrantS3ReadOnlyAccessToRedshift — 如果您在同一账户中部署提取和 重放流程,则可以为此参数输入 Yes,该参数将 AmazonS3ReadOnlyAccess 授予给 Amazon Redshift 目标和副本集群,以在账户中 重放 Amazon Redshift 的副本语句。否则,您需要手动复制文件,并调整提取 S3 存储桶最新提取文件夹中的 copy_replacement.csv 文件,还需在 重放 S3 存储桶的 config/replay.yaml 文件中将副本语句的参数设置为 true。
- VPC — 您希望部署集群和 EC2 实例的现有 Amazon Virtual Private Cloud (Amazon VPC)。
- SubnetId — VPC 内您部署集群和 EC2 实例的现有子网。
- KeyPairName — 允许 SSH 连接到 重放 EC2 实例的现有密钥对。
- OnPremisesCIDR — 用于从 SQL 客户端访问目标集群和副本集群的现有基础设施的 IP 范围(CIDR 表示法)。如果不确定,请输入公司桌面的 CIDR 地址。例如,如果桌面的 IP 地址是 10.156.87.45,请输入 10.156.87.45/32。
- EC2InstanceType — 托管 Simple Replay 实用程序代码库的 EC2 实例类型。如果集群中的数据大小小于 1 TB,则您可以使用大型实例类型。我们建议针对较大工作负载使用较大的实例类型,以防止 EC2 实例在从集群获取查询结果时成为瓶颈。
- EC2InstanceVolumeGiB — 以 GiB 为单位的 EC2 实例卷大小。我们建议将其保持 30 GiB 或更多。
- EC2InstanceAMI — 基于 Amazon Linux 2 的 EC2 实例的 AMI。除非您需要符合合规性要求,否则不要更改此参数。
访问权限和安全性
要使用 AWS CloudFormation 部署此解决方案,您需要对计划部署提取和 重放流程的 AWS 账户拥有管理员访问权限。两个模板都提供有输入参数 EndUserIamRoleName,您可以使用该参数,允许非管理员用户在没有对系统资源的任何广泛权限情况下运行流程。
CloudFormation 模板基于最低权限原则使用安全最佳实践来预置所有必需的资源,并在账户 VPC 中托管所有资源。EC2 实例和 Amazon Redshift 集群共享相同的安全组,不允许对 EC2 实例进行 SSH 访问。对 Amazon Redshift 目标集群和副本集群的访问权限由 CloudFormation 模板参数 OnPremisesCIDR 进行控制,您需要提供该参数才能允许本地用户在 Amazon Redshift 端口上使用 SQL 客户端连接到新集群。
所有资源的访问权限均使用 IAM 角色控制,此类角色向 Amazon Redshift、Lambda、Step Functions 和 Amazon EC2 授予适当权限。将提取流程创建的 S3 存储桶的读写访问权限授予给用于 重放流程的 AWS 账户,以便它从该存储桶中读取和更新配置。
评估 RA3 性能
完成 重放状态机的首次运行后,您应该能够在部署了 重放模板的 AWS 账户的 Amazon Redshift 控制台上查看 RA3 目标和非 RA3 副本集群。 重放的每次迭代都会自动填充目标 RA3 集群公共架构中的以下表和视图,便于您直接比较集群之间的性能:
- source_target_comparison — 提供两个集群 重放工作负载所用时间的比较摘要。它提供按 Amazon Redshift 队列和用户名分组的 total_query_time_saved_seconds 列,这在您的最终评估中可能非常有用。
- source_target_comparison_raw — 提供两个集群对每个查询所用时间的详细比较。
- replica_cluster_query_stats — 存储在副本集群上运行的 重放的查询级别指标。
- target_cluster_query_stats — 存储在 RA3 集群上运行的 重放的查询级别指标。
- source_cluster_query_stats — 存储源集群中的查询级别指标。此表可能为空,因为它依赖于源集群中的 STL 日志视图,这些视图仅保留 2-5 天。有关详情,请参阅用于日志记录的 STL 视图。
- detailed_query_stats — 填充 query_stats 表并提供我们用于从 STL 日志视图填充这些统计数据的逻辑。
成本和时间表考虑因素
在您的 AWS 账户中运行此模板会带来一些成本影响,因为它会预置新的 Amazon Redshift 集群和三个 EC2 实例,如果您没有预留实例,这些实例可能会作为按需实例收费。完成评估后,我们建议删除 CloudFormation 堆栈。这将删除除用于提取和 重放的两个 S3 存储桶之外的所有关联资源。我们还建议在不使用集群时将其暂停。有关详情,请参阅 Amazon Redshift 定价 和 Amazon EC2 定价。
限制
Simple Replay 和此自动化流程存在一些已知限制:
- 如果将审计日志传送到 Amazon S3 存在滞后,则提取流程可能会失败。在这种情况下,您需要选择与过去不同的时间间隔来重新运行提取状态机。
- 不能保证跨连接的相关 SQL 查询以原始顺序运行。
- 如果目标集群无权访问外部表,则不会 重放 Redshift Spectrum 查询。
- 不会 重放具有 BIND 变量的查询。
- 不支持使用 JDBC 进行 重放。
- 并发的大量获取可能会给 Amazon EC2 客户端造成压力。对于这些情况,可能需要更大的 EC2 实例。
- 审计日志可能包含未提交到生产集群的 SQL。将 重放这些 SQL。
您可以使用副本和目标集群进行比较(而不是与生产 Amazon Redshift 集群进行直接比较),最大限度地减少这些限制的影响。
结论
与之前的实例相比,Amazon Redshift RA3 实例提供许多额外的优势。如果您尝试迁移到 RA3 实例类型,但担心评估工作,则借助 Amazon Redshift Simple Replay 实用程序,您可以轻松无缝地执行此评估并成功迁移到 RA3 节点。
如果您对 RA3 实例类型的性能感到满意,可以针对生产集群执行调整操作,将其移到 RA3 平台。调整生产集群所花的时间与创建测试 RA3 集群所花的时间相近,具体取决于使用的是弹性调整还是传统调整。我们建议在对生产集群执行调整操作之前创建手动快照。