在现代应用程序开发和数据处理领域,使用 Apache Kafka 作为数据管道和扇出方法的标准传输机制已成为一种常见趋势。 Amazon Managed Streaming for Apache Kafka(Amazon MSK)是一项完全托管的、高度可用且安全的服务,可让开发人员和 DevOps 经理轻松地在 AWS 中的 Apache Kafka 上运行应用程序,而无需具备 Apache Kafka 基础设施管理专业知识。随着开发人员和应用程序拥有者在其现代应用程序中使用基于 JSON 的数据集,诸如 Amazon DocumentDB(与 MongoDB 兼容)之类的文档数据库的使用量正在增加。Amazon DocumentDB 是一项可扩展、耐用且完全托管的数据库服务,可用于操作任务关键型 MongoDB 工作负载。越来越多的客户在各种使用案例中将 Amazon MSK 与 Amazon DocumentDB 结合使用。在本博文中,我们将讨论如何运行和配置 MongoDB Kafka 连接器,以便在 Amazon DocumentDB 和 Amazon MSK 之间移动数据以用于接收器和来源使用案例。
解决方案概览
Amazon DocumentDB 可以用作 Amazon MSK 的数据来源和数据接收器。在任一使用案例中,MongoDB Kafka 连接器都可用于在 Amazon DocumentDB 和 Amazon MSK 之间传输数据。
Kafka Connect 是 Apache Kafka 的开源组件,它解决了将 Apache Kafka 连接到数据存储这一难题。它提供了一个框架,用于部署连接器(例如 MongoDB Kafka 连接器)以便连接到数据库、键值存储、搜索索引和文件系统等外部系统。
Kafka Connect 目前支持两种模式:
- 独立 – 在单一流程中完成工作
- 分布式 – 多个工作线程、自动平衡和任务的动态扩缩
分布式模式的平衡和扩缩提供了有效任务、配置和偏移量提交数据的容错能力,而独立模式无法提供此能力。在本博文中,我们在分布式模式中配置和运行连接器。在分布式模式中,Kafka Connect 还公开了 REST API 接口来管理我们在本博文中使用的连接器。
以下是示例使用案例,在这些使用案例中,您可以使用 Amazon DocumentDB 作为 Amazon MSK 背后的数据存储:
- 在大型视频直播或限时抢购活动中,可以将生成的与观众、反应或买家点击流相关的数据作为原始数据提供给 Amazon MSK。您可以进一步将这些数据流式传输到 Amazon DocumentDB 来进行下游处理和聚合。
- 对于流式传输来自 IoT 设备的遥测数据、网站点击数据或气象数据,可以使用连接器将这些数据流式传输到 Amazon DocumentDB 中,然后再进行处理(例如,聚合或最小值/最大值计算)。
- 对于 Amazon DocumentDB 集群中的任何记录重播或应用程序恢复,应用程序可以重播从 Amazon MSK 到 Amazon DocumentDB 集合的特定项目级别更改,而不是恢复整个备份。
以下是示例使用案例,其中您可以向 Amazon MSK 发送 Amazon DocumentDB 更改流:
- 如果选择性地将集合从一个 Amazon DocumentDB 集群复制到另一个集群或其他数据存储,则可将 Amazon MSK 用作中间层。
- Amazon DocumentDB 提供了丰富的聚合框架,但对于高级分析和机器学习,您可以创建从 Amazon DocumentDB 到各种其他的数据存储的数据管道。您可以先使用 Amazon MSK 作为中间层来修改和筛选更改事件,然后再将这些事件加载到目标数据存储。
在这两个使用案例中,您可以使用 Kafka 连接器将更改流从 Amazon DocumentDB 移至 Amazon MSK。
我们将本博文分为两个主要部分:
- Amazon DocumentDB 用作接收器 – 在本博文的前半部分,我们将讨论使用连接器通过 Amazon MSK 向 Amazon DocumentDB 传输数据。
- Amazon DocumentDB 作为来源 – 在本博文的后半部分,我们将介绍使用同一连接器从 Amazon DocumentDB 提取数据,并将数据发布到 Kafka 主题以供下游 Kafka 使用器使用。
我们还将讨论分布式模式提供的针对有效连接器任务的自动平衡和容错。
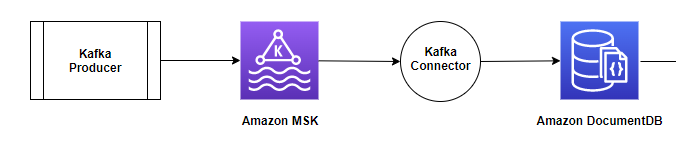
下图展示了架构和数据流。

先决条件
要为学习本博文做准备,您需要以下资源:
- Amazon DocumentDB 集群 – 您可以使用现有集群或创建新集群。如果创建新集群,请通过子网组设置验证您的实例是否已部署到多个可用区。

- Amazon MSK 集群 – 您可以使用现有集群或使用自定义创建方法来创建新集群。应预置 Amazon MSK 集群类型。该集群应部署到与 Amazon DocumentDB 集群相同的 VPC 中,并通过用于 Amazon DocumentDB 的同一安全组进行配置。您的集群还应具有以下配置:
- 使用
auto.create.topics.enable=true 创建自定义配置。以下屏幕截图显示名为 production-config 的自定义配置示例。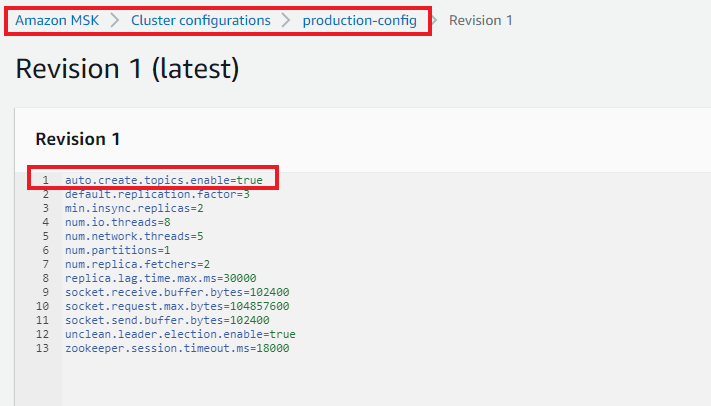
-
- 在配置 Amazon MSK 集群时创建三个代理(最少),如以下屏幕截图中所示。
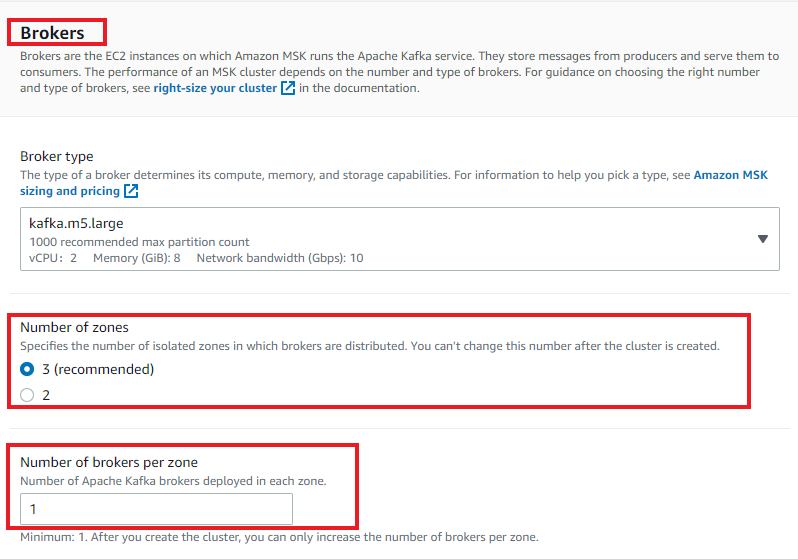
-
- 在 Amazon MSK 集群配置期间使用自定义配置。
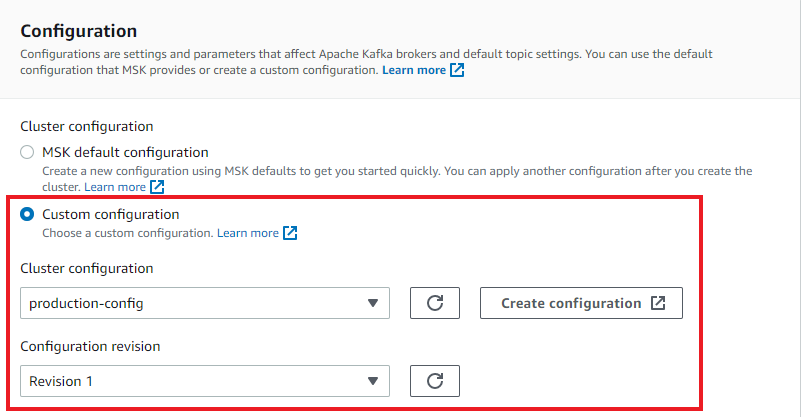
-
- Amazon EC2 实例 – 您可以选择一个 Amazon Elastic Compute Cloud(Amazon EC2)实例或配置一个新实例。我们将此 EC2 实例用于运行容器和测试目的。作为生产最佳实践,您可以在 Amazon Elastic Container Service(Amazon ECS)、Amazon Elastic Kubernetes Service(Amazon EKS)或 AWS Fargate 上部署容器,以便有效管理容器。您的实例应具有以下配置:
- 至少 t3.large 的实例类。
- 至少 10 GB 的实例存储空间。
- 已部署在 Amazon DocumentDB 集群和 Amazon MSK 集群所在的同一 VPC 中,并具有同一安全组。
- 实例安全组应配置为连接到 Amazon MSK 集群(端口 9098)和 Amazon DocumentDB 集群(端口 27017)和从这两个集群连接。
- 客户管理型策略 – 使用以下文档为 Amazon MSK 集群创建客户管理型策略。您需要在策略中更新您的区域和账户 ID。区域应为您在其中预置 Amazon DocumentDB 集群、Amazon MSK 集群和 EC2 实例的区域。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "kafka-cluster:*",
"Resource": "arn:aws:kafka:<region>:<account id>:*/*/*" } ] }
- IAM 角色 – 使用上面的策略创建一个 IAM 角色并将该角色分配给 EC2 实例。
- 用于连接到 Amazon DocumentDB 集群的 mongo Shell – 您可以在 EC2 实例上安装 mongo Shell。有关说明,请参阅安装 mongo Shell。
- 用于运行 Docker 容器的包 – 登录 EC2 实例,运行以下命令以安装运行 Docker 容器所需的 Java、Docker 和 docker-compose 包:
sudo yum install docker -y
sudo usermod -a -G docker ec2-user
newgrp docker
sudo systemctl enable docker.service
sudo systemctl start docker.service
sudo curl -L https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo yum install -y java-11-amazon-corretto-headless
sudo yum install -y jq
- JVM 的信任存储 – Amazon DocumentDB 默认启用 SSL/TLS,并且 Kafka 连接器与 Java 虚拟机(JVM,Java Virtual Machine)一起运行,因此,您需要使用密码创建信任存储。有关说明,请参阅以编程方式连接到 Amazon DocumentDB。创建一个本地目录并复制您的信任存储文件(名为
rds-truststore.jks)。如果您已按照步骤操作,正确创建信任存储,则该文件位于 /tmp/certs 中。
mkdir -p ~/local_kafka/; cd ~/local_kafka/;cp /tmp/certs/rds-truststore.jks .
您的账户中将产生与 Amazon DocumentDB、Amazon MSK 和 Amazon EC2 资源相关的费用。您可以使用 AWS 定价计算器来估计此费用。
Amazon DocumentDB 用作接收器
在本博文的这一部分中,我们将重点介绍接收器使用案例,如下图所示。我们将讨论如何创建和运行连接器(使用 Docker 容器),以及如何将 Amazon DocumentDB 用作接收器数据库来移动由 Kafka 生成器生成的 Amazon MSK Kafka 主题中的数据。
构建并运行连接器 Docker 容器
要构建和运行我们的连接器 Docker 容器,请完成以下步骤:
- 在 Amazon MSK 控制台的导航窗格中,选择 Clusters(集群)。
- 打开您的集群。
- 选择 View client information(查看客户端信息)。
- 复制 Amazon MSK 引导服务器的私有端点。


- 在您的 EC2 实例中,使用 vi 编辑器创建一个包含以下内容的新
Dockerfile。更新 Amazon MSK 引导服务器和信任存储密码。
FROM amazonlinux:latest
ENV KAFKA_HOME /usr/local/kafka
ENV DOCDBJKSPASS <truststore_password>
ENV KAFKA_OPTS " -Djavax.net.ssl.trustStore=/usr/local/kafka/rds-truststore.jks \
-Djavax.net.ssl.trustStorePassword=${DOCDBJKSPASS}"
ENV BOOTSTRAP_SERVER <kafka_bootstarp_servers_with_ports>
ENV CONNECT_CLUSTER_GROUP_NAME docdb-kafka-connect-cluster1
EXPOSE 8083
USER root
RUN echo "Installing Java..." \
&& yum update -y \
&& yum install -y java-11-amazon-corretto-headless \
&& yum install wget tar -y -q \
&& echo "Installing Kafka Connect..." \
&& wget https://dlcdn.apache.org/kafka/3.2.3/kafka_2.13-3.2.3.tgz -q \
&& tar -xzf kafka_2.13-3.2.3.tgz \
&& mv kafka_2.13-3.2.3 ${KAFKA_HOME} \
&& cd ${KAFKA_HOME} \
&& echo "Installing MongoDb Kafka Connector jar for DocumentDB..." \
&& wget https://repo1.maven.org/maven2/org/mongodb/kafka/mongo-kafka-connect/1.7.0/mongo-kafka-connect-1.7.0-all.jar -q \
&& cp mongo-kafka-connect-1.7.0-all.jar /usr/local/kafka/libs/ \
&& echo "Installing MSK IAM Authehtication jar..." \
&& wget https://github.com/aws/aws-msk-iam-auth/releases/download/v1.1.3/aws-msk-iam-auth-1.1.3-all.jar -q \
&& cp aws-msk-iam-auth-1.1.3-all.jar /usr/local/kafka/libs/
RUN echo "Configuring Kafka Connect.." \
&& useradd -ms /bin/bash conuser \
&& chown -R conuser:conuser $KAFKA_HOME \
&& sed -i s/localhost:9092/${BOOTSTRAP_SERVER}/g ${KAFKA_HOME}/config/connect-distributed.properties \
&& sed -i s/offset.storage.replication.factor=1/offset.storage.replication.factor=3/g ${KAFKA_HOME}/config/connect-distributed.properties \
&& sed -i s/status.storage.replication.factor=1/status.storage.replication.factor=3/g ${KAFKA_HOME}/config/connect-distributed.properties \
&& sed -i s/config.storage.replication.factor=1/config.storage.replication.factor=3/g ${KAFKA_HOME}/config/connect-distributed.properties \
&& sed -i s/group.id=connect-cluster/group.id=${CONNECT_CLUSTER_GROUP_NAME}/g ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "topic.creation.enable=true" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& cp /usr/lib/jvm/java-11-amazon-corretto.x86_64/lib/security/cacerts ${KAFKA_HOME}/kafka_iam_truststore.jks
RUN echo "Configuring SSL for DocumentDB..."
COPY rds-truststore.jks ${KAFKA_HOME}/rds-truststore.jks
RUN echo "Configuring SSL and IAM for MSK..." \
&& echo "ssl.truststore.location=${KAFKA_HOME}/kafka_iam_truststore.jks" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "security.protocol=SASL_SSL" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "sasl.mechanism=AWS_MSK_IAM" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "producer.ssl.truststore.location=${KAFKA_HOME}/kafka_iam_truststore.jks" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "producer.security.protocol=SASL_SSL" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "producer.sasl.mechanism=AWS_MSK_IAM" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "consumer.ssl.truststore.location=${KAFKA_HOME}/kafka_iam_truststore.jks" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "consumer.security.protocol=SASL_SSL" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "consumer.sasl.mechanism=AWS_MSK_IAM" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;" >> ${KAFKA_HOME}/config/connect-distributed.properties \
&& echo "consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler" >> ${KAFKA_HOME}/config/connect-distributed.properties
USER conuser
CMD ${KAFKA_HOME}/bin/connect-distributed.sh ${KAFKA_HOME}/config/connect-distributed.properties
在 Dockerfile 中,您可以从头开始构建连接器(安装 Java、使用连接器 JAR 安装 Kafka Connect、配置 IAM 身份验证等)。
我们在分布式模式中运行连接器以提供容错能力。在分布式模式中,您可以使用相同的 group.id config 启动多个工作进程,它们会自动协调来安排在可用工作线程上运行连接器和任务。在前面的 Dockerfile 中,group.id 定义为 docdb-kafka-connect-cluster1。
- 创建 Docker 映像:
docker build . -t docdbkafkaconnet:latest
在本博文中,我们将使用 Docker Compose 运行容器,Docker Compose 是一个容器编排框架,可让您定义和运行多个容器。它在单个主机上运行容器。
- 使用以下内容创建 Docker Compose 文件
docker-compose.yaml:
version: "3.7"
services:
docdb_kafka_connect_worker:
image: docdbkafkaconnet
- 使用 Docker Compose 运行
docdbkafkaconnect 映像的两个容器:
docker-compose up -d --scale docdb_kafka_connect_worker=2
您将获得以下输出:
[+] Running 2/2
⠿ Container local_kafka-docdb_kafka_connect_worker-1 Started 0.6s
⠿ Container local_kafka-docdb_kafka_connect_worker-2 Started 0.6s
这两个容器在分布式模式中运行连接器工作线程。您可以使用以下命令验证容器的运行状态:
您将获得以下输出:
NAME COMMAND SERVICE STATUS PORTS
local_kafka-docdb_kafka_connect_worker-1 "/bin/sh -c '${KAFKA…" docdb_kafka_connect_worker running 8083/tcp
local_kafka-docdb_kafka_connect_worker-2 "/bin/sh -c '${KAFKA…" docdb_kafka_connect_worker running 8083/tcp
- 使用 docker inspect 命令获取这两个正在运行的容器的 IP 地址。您可以从上一步的输出中获取容器名称。
docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' &<container name>
您将获得以下输出:
docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' local_kafka-docdb_kafka_connect_worker-1
172.XX.XX.3
docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' local_kafka-docdb_kafka_connect_worker-2
172.XX.XX.2
- 定义
CONTAINER_IP1 和 CONTAINER_IP2 这两个环境变量以存储这些正在运行的容器的 IP 地址:
export CONTAINER_IP1=<ip_address_of_first_container>
export CONTAINER_IP2=<ip_address_of_second_container>
- 使用 REST API 检查连接器的运行状况。Kafka Connect 支持用于管理连接器的 REST API 接口。默认情况下,此服务在端口 8083 上运行。您可以使用任意容器 IP 地址,如下所示:
curl -X GET http://${CONTAINER_IP1}:8083/
此 GET API 调用提供有关 Kafka Connect 集群的基本信息,例如提供 REST 请求的 Kafka Connect 工作线程的版本(包括源代码的 git 提交 ID)以及它连接到的 Kafka 集群 ID。如果您收到错误 404,则表示连接器仍在启动。您应等待,直到它返回所需的信息。
由于没有连接器配置,因此,以下对连接器的 REST API 调用将返回空值:
curl -X GET http://${CONTAINER_IP1}:8083/connectors
配置 Amazon DocumentDB 接收器连接器
现在,您需要配置连接器以读取来自 Amazon MSK 主题的数据,并将该数据同步到目标 Amazon DocumentDB 数据库。
连接器配置是键值映射。在分布式模式中,它们包含在创建和配置连接器的请求的 JSON 有效负载中。您需要更新 Amazon DocumentDB 登录名、密码、集群端点和集群端口。您可以在 Amazon DocumentDB 控制台的 Connectivity & security(连接性和安全性)选项卡上获取这些值。
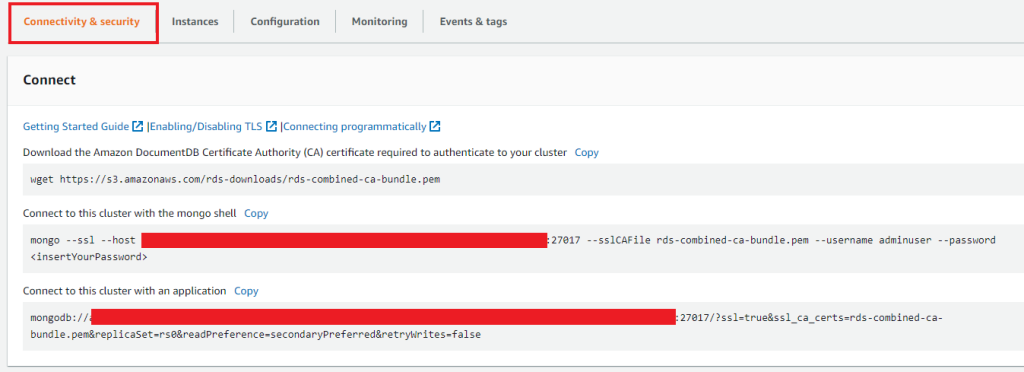
您可以使用任意连接器 IP 地址进行 REST API 调用。请参阅以下代码:
curl -X POST \
-H "Content-Type: application/json" \
--data '
{"name": "documentdb-sink",
"config": {
"connector.class":"com.mongodb.kafka.connect.MongoSinkConnector",
"tasks.max":1,
"topics":"documentdb_topic",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"connection.uri":"mongodb://<docdbloginname>:<docdbpassword>@<docdbclusterendpoint>:<docdbportnumber>/?ssl=true&replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false",
"database":"sinkdatabase",
"collection":"sinkcollection"
}
}
' \
http://${CONTAINER_IP1}:8083/connectors -w "\n"
上面的数据有效负载包含以下 JSON 格式的连接器配置详细信息:
- name – 连接器的唯一名称。对于此配置,连接器名称为
documentdb-sink。
- connector.class – 连接器的 Java 类。这是负责从 Kafka 移动数据的类。
- tasks.max – 应为此连接器创建的最大任务数。
- topics – 此接收器连接器监控的 Kafka 主题列表。主题名称为
documentdb_topic。
- key.converter – 指示连接器如何从 Kafka 序列化格式转换密钥的转换器类。我们使用字符串类转换器。
- value.converter – 指示连接器如何从 Kafka 序列化格式转换值的转换器类。我们的 Kafka 主题中有 JSON 数据,因此,我们将 Kafka Connect 配置为使用 JSON 转换器。
- value.converter.schemas.enable – 默认情况下,JSON 转换器需要一个 JSON 架构,但由于没有架构,因此我们将它设置为 false。
- connection-uri – 定义要连接到 Amazon DocumentDB 集群的端点。我们使用带 SSL 选项的端点。
- database – 目标 Amazon DocumentDB 数据库。我们使用数据库名称
sinkdatabase。
- collection – 数据库中用于推送更改的集合名称。集合名称为
sinkcollection。
有关配置的完整详细信息,请参阅所有接收器连接器配置属性。
现在,您可以使用 REST API 调用查看已配置的连接器详细信息,该调用返回连接器名称 documentdb-sink:
curl -X GET http://${CONTAINER_IP1}:8083/connectors
您还可以使用 REST API 调用查看 documentdb-sink 连接器状态,如下所示(jq 命令有助于更清楚地显示输出)。
curl -X GET http://${CONTAINER_IP1}:8083/connectors/documentdb-sink/status |jq
您将获得以下输出;状态显示为 Running:
{
"name": "documentdb-sink",
"connector": {
"state": "RUNNING",
"worker_id": "172.XX.XX.2:8083"
},
"tasks": [
{
"Id": 0,
"state": "RUNNING",
"worker_id": "172.XX.XX.2:8083"
}
],
"type": "sink"
}
在此输出中,接收器连接器在 IP 地址为 172.XX.XX.2 的容器上运行。
要查看正在运行的 documentdb-sink 连接器的配置,请使用以下代码:
curl -X GET http://${CONTAINER_IP1}:8083/connectors/documentdb-sink/config|jq
您将获得以下输出:
{
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"database": "sinkdatabase",
"tasks.max": "1",
"topics": "documentdb_topic",
"value.converter.schemas.enable": "false",
"connection.uri": "mongodb://XXX:XXX@XXX:XXX/?ssl=true&replicaSet=rs0&readPreference=secondaryPreferred&retryWrites=false",
"name": "documentdb-sink",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"collection": "sinkcollection",
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
}
使用 Amazon DocumentDB 作为接收器来测试 MongoDB Kafka 连接器
要测试连接器,请启动 Kafka 生成器以将更改推送到 Kafka 主题 documentdb_topic。Kafka 连接器将读取本主题中的详细信息,并根据配置将详细信息放入 Amazon DocumentDB 中。
- 要运行本地 Kafka 生成器,您需要下载 Apache Kafka 的二进制发行版,并在 EC2 实例的
local_kafka 目录中提存档:
cd ~/local_kafka/
cp /usr/lib/jvm/java-11-amazon-corretto.x86_64/lib/security/cacerts kafka_iam_truststore.jks
wget https://dlcdn.apache.org/kafka/3.2.3/kafka_2.13-3.2.3.tgz
tar -xzf kafka_2.13-3.2.3.tgz
ln -sfn kafka_2.13-3.2.3 kafka
- 要使用 IAM 对 MSK 集群进行身份验证,请下载适用于 IAM 的 Amazon MSK 库并复制到本地 Kafka 库目录,如以下代码中所示。有关完整说明,请参阅为 IAM 访问控制配置客户端。
wget https://github.com/aws/aws-msk-iam-auth/releases/download/v1.1.3/aws-msk-iam-auth-1.1.3-all.jar
cp aws-msk-iam-auth-1.1.3-all.jar kafka/libs
截至本博文发布之日,我们使用的是最新版本的 Kafka,即 3.2.3 版。
- 在
~/local_kafka/kafka/config/ 目录中,创建一个 client-config.properties 文件以将 Kafka 客户端配置为对 Kafka 控制台生成器和使用器使用 IAM 身份验证:
ssl.truststore.location=/home/ec2-user/local_kafka/kafka_iam_truststore.jks
security.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
- 定义
BOOTSTRAP_SERVERS 环境变量以存储 Amazon MSK 集群的引导服务器,并在路径环境变量中本地安装 Kafka:
export BOOTSTRAP_SERVERS=<kafka_bootstarp_serverswithports>
export PATH=$PATH:/home/ec2-user/local_kafka/kafka_2.13-3.2.3/bin
- 运行 Kafka 控制台生成器以写入 Amazon MSK 主题
documentdb_topic 并提交有效的 JSON 文档 {"name":"DocumentDB NoSQL"} 和 {"test":"DocumentDB Sink Connector"}:
cd ~/local_kafka/kafka/config
kafka-console-producer.sh --bootstrap-server $BOOTSTRAP_SERVERS --producer.config client-config.properties --topic documentdb_topic
{"name":"DocumentDB NoSQL"}
{"test":"DocumentDB Sink Connector"}
- 打开第二个终端,并使用 mongo Shell 连接到 Amazon DocumentDB 集群。上面两个 JSON 文档应属于
sinkdatabase 中的 sinkcollection 集合:
use sinkdatabase
db.sinkcollection.find()
您将获得以下输出:
{ "_id" : ObjectId("62c3cf2ec3d9010274c7a37e"), "name" : "DocumentDB NoSQL" }
{ "_id" : ObjectId("62c3d048c3d9010274c7a37f"), "test" : "DocumentDB Sink Connector" }
您应看到我们已使用控制台生成器推送的 JSON 文档。
Amazon DocumentDB 用作来源
在此部分中,我们将讨论如何使用 Kafka Connect 框架创建和运行连接器(使用 Docker 容器),以及如何将 Amazon DocumentDB 用作源数据库以将集合更改移至 Amazon MSK Kafka 主题。
下图展示了此数据流。
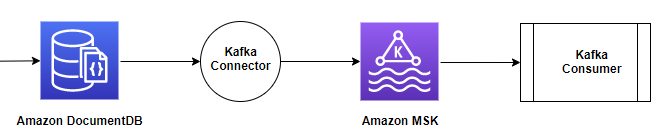
我们使用之前设置的连接器容器。
为更改流配置 Amazon DocumentDB
连接器通过更改流光标读取源集合中的更改。Amazon DocumentDB 中的更改流功能可按时间顺序对集合中发生的一系列更改事件进行排序。
在本博文中,我们使用 Amazon DocumentDB 集群中的 sourcedatabase 数据库中的 sourcecollection 集合。
连接到 Amazon DocumentDB 集群并启用集合 sourcecollection 的更改流:
use sourcedatabase
db.createCollection("sourcecollection")
db.adminCommand({modifyChangeStreams: 1,database: "sourcedatabase",collection: "sourcecollection", enable:true});
将连接器配置为 Amazon DocumentDB 源连接器
现在,我们需要配置源连接器以读取 Amazon DocumentDB 集合中的更改,并将这些更改存储在 Amazon MSK 主题中。连接器将从我们配置的 Amazon DocumentDB 更改流中读取这些更改。
连接器配置是键值映射。在分布式模式中,它们包含在创建和配置连接器的请求的 JSON 有效负载中。您需要更新 Amazon DocumentDB 登录名、密码、集群端点和集群端口。您可以使用任意容器 IP 地址进行以下 REST API 调用。
请注意,connection.uri 与上一个接收器使用案例不同。不要在 connection.uri 中将读取首选项设置作为辅助设置,因为 Amazon DocumentDB 仅支持主实例上的更改流。
您可以打开一个新的终端,也可以停止之前创建的某个终端来运行以下命令:
curl -X POST \
-H "Content-Type: application/json" \
--data '
{"name": "documentdb-source",
"config": {
"connector.class":"com.mongodb.kafka.connect.MongoSourceConnector",
"connection.uri":"mongodb://<docdbloginname>:<docdbpassword>@<docdbclusterendpoint>:<docdbportnumber>/?ssl=true&replicaSet=rs0",
"database":"sourcedatabase",
"collection":"sourcecollection",
"pipeline":"[{\"$match\": {\"operationType\": \"insert\"}}, {$addFields : {\"fullDocument.newfield\":\"Testing DocumentDB Kafka Source Connecter\"}}]"
}
}
' \
http://${CONTAINER_IP1}:8083/connectors -w "\n"
上面的数据有效负载包含连接器类型及其属性:
- name – 连接器的唯一名称。对于此配置,连接器名称为
documentdb-source。
- connector.class – 连接器的 Java 类。它是负责将数据从 Amazon DocumentDB 集合移至 Amazon MSK 主题的类。
- tasks.max – 应为此连接器创建的最大任务数。
- connection-uri – 用于连接到 Amazon DocumentDB 集群的 Amazon DocumentDB 端点。我们使用带 SSL 选项的端点。
- database – 源数据库。在此示例中,数据库名称为
sourcedatabase。
- collection – 数据库中用于监控更改的集合。集合名称为
sourcecollection。
- pipeline – 用于在文档中添加新字段的聚合管道。利用此配置,我们在文档中添加了一个字段,但它不是必填字段。
有关配置的完整详细信息,请参阅所有来源连接器配置属性。
使用 REST API 调用检查已配置的连接器详细信息;它将返回所有已配置的连接器,包括此新连接器。您可以使用任意容器 IP 地址进行 REST API 调用:
curl -X GET http://${CONTAINER_IP1}:8083/connectors
您将看到名为 documentdb-source 的连接器和名为 documentdb-sink 的连接器。
您还可以使用 REST API 调用查看 documentdb-sink 连接器状态,如下所示:
curl -X GET http://${CONTAINER_IP1}:8083/connectors/documentdb-source/status|jq
您将获得以下输出;状态显示为 Running:
{
"name": "documentdb-source",
"connector": {
"state": "RUNNING",
"worker_id": "172.XX.XX.3:8083"
},
"tasks": [
{
"Id": 0,
"state": "RUNNING",
"worker_id": "172.XX.XX.3:8083"
}
],
"type": "source"
}
如前所述,接收器连接器在 IP 地址为 172.XX.XX.2 的容器上运行。现在,来源连接器位于另一个 IP 地址为 172.XX.XX.3 的容器上。在分布式模式中,Kafka Connect 会自动在不同的可用容器(连接器工作线程)之间对任务实施负载平衡。如果容器出现故障,它会自动将正在运行的任务移至另一个可用容器。
要检查正在运行的 documentdb-source 连接器的配置,请使用以下代码:
curl -X GET http://${CONTAINER_IP1}:8083/connectors/documentdb-source/config|jq
您将获得以下输出:
{
"connector.class": "com.mongodb.kafka.connect.MongoSourceConnector",
"pipeline": "[{\"$match\": {\"operationType\": \"insert\"}}, {$addFields : {\"fullDocument.newfield\":\"Testing DocumentDB Kafka Source Connecter\"}}]",
"database": "sourcedatabase",
"connection.uri": "mongodb://XXX:XXX@XXX:XXX/?ssl=true&replicaSet=rs0",
"name": "documentdb-source",
"collection": "sourcecollection"
}
使用 Amazon DocumentDB 作为来源测试连接器
为了测试连接器,我们在 Amazon DocumentDB 集合中插入数据。Kafka 连接器使用集合更改流读取插入的数据,并将其写入 Kafka 主题。
- 打开一个新的终端或使用现有终端,然后运行 Kafka 控制台使用器,从
sourcecollection.sourcedatabase Kafka 主题中读取详细信息。如果您在新的终端上运行它,请务必创建 BOOTSTRAP_SERVERS 环境变量。
cd ~/local_kafka/kafka/config
kafka-console-consumer.sh --bootstrap-server $BOOTSTRAP_SERVERS --consumer.config client-config.properties --topic sourcedatabase.sourcecollection --from-beginning
您将收到以下警告,因为控制台试用期命令创建了一个新的名为 sourcedatabase.sourcecollection 的主题:
WARN [Consumer clientId=console-consumer, groupId=console-consumer-32474] Error while fetching metadata with correlation id 2 :
{sourcedatabase.sourcecollection=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
- 在第二个终端中,在您的 Amazon DocumentDB 集群的
sourcedatabase.sourceCollection 中添加记录:
use sourcedatabase
db.sourcecollection.insert({"name":"Amazon DocumentDB"})
- 返回第一个终端,控制台使用器正在其中读取 Amazon MSK 主题:
kafka-console-consumer.sh --bootstrap-server $BOOTSTRAP_SERVERS --consumer.config client-config.properties --topic sourcedatabase.sourcecollection --from-beginning
{"schema":{"type":"string","optional":false},"payload":"{\"_id\": {\"_data\": \"0162c3ff0400000001010000000100006039\"}, \"operationType\": \"insert\", \"clusterTime\": {\"$timestamp\": {\"t\": 1657011972, \"i\": 1}}, \"ns\": {\"db\": \"sourcedatabase\", \"coll\": \"sourcecollection\"}, \"documentKey\": {\"_id\": {\"$oid\": \"62c3ff045986fd12df47f0e6\"}}, \"fullDocument\": {\"_id\": {\"$oid\": \"62c3ff045986fd12df47f0e6\"}, \"name\": \"Amazon DocumentDB\", \"newfield\": \"Testing DocumentDB Kafka Source Connecter\"}}"}
我们可以观察到,对 Amazon DocumentDB 集合执行的插入操作适用于控制台使用器。此外,还添加了一个新字段,其中 newfield 作为键,Testing DocumentDB Kafka Source Connecter 作为值。
现在,我们可以通过运行带 Docker 容器的连接器,使用 MongoDB Kafka 连接器捕获作为源数据库的 Amazon DocumentDB 中的更改。
清理
要清理您在账户中使用的资源,请按以下顺序将它们删除:
- EC2 实例
- IAM 角色和客户管理型策略
- Amazon MSK Kafka 集群
- Amazon DocumentDB 集群
结论
在本博文中,我们讨论了如何运行和配置 MongoDB Kafka 连接器,以便在 Amazon DocumentDB 和 Amazon MSK 之间移动数据以用于不同的接收器和来源使用案例。您可以将此解决方案用于各种使用案例,例如为大型视频直播或限时抢购活动创建管道,从 IoT 设备流式传输遥测数据,收集网站点击数据,将集合从 Amazon DocumentDB 复制到其他数据存储,以及移动数据进行高级分析和机器学习。
我们首先向您展示了如何使用连接器将数据从 Amazon MSK 流式传输到 Amazon DocumentDB,其中 Amazon DocumentDB 充当接收器。我们还说明了如何构建和配置连接器 Docker 映像,以及在分布式模式中运行连接器容器。在本博文的后半部分中,我们向您展示了如何将数据从 Amazon DocumentDB 流式传输到 Amazon MSK,其中 Amazon DocumentDB 充当来源。通过查询连接器状态,我们说明了连接器如何在分布式模式中提供自动平衡和容错能力。我们还讨论了两种使用案例中可用的各种配置,您可以根据自己的特定使用案例或工作负载要求进行调整。
关于作者
 Anshu Vajpayee 是 Amazon Web Services(AWS)的高级 DocumentDB 专家级解决方案架构师。他一直在帮助客户采用 NoSQL 数据库,并利用 Amazon DocumentDB 实现应用程序的现代化。在加入 AWS 之前,他已大量使用关系数据库和 NoSQL 数据库。
Anshu Vajpayee 是 Amazon Web Services(AWS)的高级 DocumentDB 专家级解决方案架构师。他一直在帮助客户采用 NoSQL 数据库,并利用 Amazon DocumentDB 实现应用程序的现代化。在加入 AWS 之前,他已大量使用关系数据库和 NoSQL 数据库。




