本文为手把手教你玩转 kubeflow on EKS 系列文章的第二篇
1. 前言
Kubeflow 是一个为 Kubernetes 构建的可组合,可以移植,可扩展的机器学习平台,可以很好支持在 Amazon EKS 上实现完整的 ML 工作流程。Kubeflow 一个基于云原生构建的机器学习任务工具大集合,Kubeflow把诸多对机器学习的支持,比如模型训练,超参数训练,模型部署等进行组合并以容器化的方式进行部署,并提供系统的高可用及扩展性,企业就可以利用Kubeflow进行不同的机器学习任务。为了让机器学习模型正常工作,我们往往还需要将其整合至应用程序当中具体包括Web应用程序、移动应用程序。利用Kubeflow,数据科学家无需学习最新概念与平台知识、也不必处理入口与网络证书等复杂因素,即可轻松将模型部署至应用程序之内。
机器学习,绝不仅仅是“建模”而已。在真实的生产环境中,整个机器学习的Pipeline,还包括了环境配置、数据管道搭建、数据整合、分析、视觉化,模型训练,模型验证发布,监控日志等多个环节,涉及到不同的技术、服务和工具。
 从上图可以看出 Kubeflow从工业上机器学习的整体流程,数据采集,验证,到模型训练和服务发布,几乎所有的步骤Kubeflow都提供解决方案的组件,Kubeflow将机器学习各个阶段涉及的组件以微服务的方式进行组合并以容器化的方式进行部署,提供整个流程各个系统的高可用及方便的进行扩展。本文将通过Kubeflow中如下系列组件提供一个端到端的机器学习过程。
从上图可以看出 Kubeflow从工业上机器学习的整体流程,数据采集,验证,到模型训练和服务发布,几乎所有的步骤Kubeflow都提供解决方案的组件,Kubeflow将机器学习各个阶段涉及的组件以微服务的方式进行组合并以容器化的方式进行部署,提供整个流程各个系统的高可用及方便的进行扩展。本文将通过Kubeflow中如下系列组件提供一个端到端的机器学习过程。
- Kubeflow fairing:Kubeflow Fairing是一个Python软件包,可轻松在kubeflow上训练和部署ML模型
- TFJob:TFJob基于 k8s 构建的一种CRD方便运行tensorflow 的分布式架构,通过TFJob可以在Amazon EKS上调用Tensorflow的训练任务
- TensorFlow Serving:TensorFlow Serving是一个用于机器学习模型Serving的高性能开源库服务生成模型
通过上述组件可以实现从创建托管的Jupyter笔记本,用Kubeflow Fairing远程构建模型训练镜像,用TFJob 实现分布式训练用于图像分类的MNIST机器学习模型,用TensorFlow Serving一键式模型部署以及应用界面集成进行在线预测的一个端到端机器学习的完整过程。
2.Kubeflow快速构建、训练和部署机器学习模型
在本文将在手把手教你玩转Kubeflow on EKS(一)基础上,在安装在Amazon EKS 上的Kubeflow基于在MNIST数据集上训练一个TensorFlow模型,实现一个对MNIST数据集的手写字符的识别程序的端到端的过程,MNIST 数据集的训练集 (training set)和测试集(testing set)由来自 250 个不同人手写的数字构成,数据集包含大量从0到9的手写数字图像,以及标识每个图像中数字的标签,经过训练手写识别程序可以根据手写图像进行推理预测手写数字是0 – 9的概率。
 列步骤在Kubeflow上实现一个端到端的MNIST模型训练、部署与应用过程:
列步骤在Kubeflow上实现一个端到端的MNIST模型训练、部署与应用过程:
- 创建托管jupter笔记本:在kubeflow中用自定义镜像(该镜像默认提供了tensorflow和aws cli的环境)的方式创建一个notebook 笔记本,在notebook笔记本创建aws相关资源(S3,ECR)并设置eks对aws相关资源的权限和安装相关依赖包,基于kubeflow官方的例子(https://github.com/kubeflow/examples.git)开始端到端的机器学习模型训练与部署。
- 构建模型训练容器镜像:在EKS中利用kubeflow Fairing直接在EKS上构建模型训练镜像,并上传到Amazon ECR中。
- 模型分布式训练:在EKS上使用TFJob训练模型,并基于数据并行策略的方式实现在EKS上运行TensorFlow分布式训练任务
- 模型部署与监控:使用TensorFlow Serving基于训练好的mnist模型实现在EKS上的弹性部署以及部署tensorflow可视化工具TensorBoard对训练流程进行调试与监控
- 应用集成:部署通过Flask以及bootstrap开发的Web应用程序和使用该模型的web应用程序在线推理,该Web应用会集成TensorFlow Serving部署的模型,并对于每个手写数字图像调用模型进行推理预测手写数字是0 – 9的概率
1)创建Kubeflow Jupyter笔记本
- 启动Kubeflow中央仪表盘
- 在左窗格的“快捷方式”下,单击“ 创建新的笔记本服务器”。
- 输入或选择您的笔记本服务器的以下详细信息:
- 在顶部的下拉菜单中选择一个名称空间。
- 在名称下,输入您笔记本的名称。
- 在image,选中custom image。
- 在custom image下,输入自定义镜像 (seedjeffwan/tensorflow-1.13.1-notebook-cpu:awscli-v2) 创建笔记本。

- 点击 Launch.
2) 启动Jupyter Notebook
在“笔记本服务器”页面中,单击“ CONNECT”以连接到上一步中创建的服务器.

在Jupyter主页上:
- 选择Files。
- 单击右侧的“ New”>“Terminal ”以打开终端。

在Jupyter终端中,输入:
git clone https://github.com/kubeflow/examples.git git_kubeflow-examples
选择顶部的Jupyter主选项卡, 然后选择mnist_aws.ipynb打开笔记本.

在kubernetes中创建 AWS secret, 授予notebook访问aws资源权限
在notebook中安装完aws boto3包以后,点击 Kernal -> Restart
!pip install boto3
在当前namespace创建secret.
注意: secret需要 base64编码, 运行 echo -n $AWS_ACCESS_KEY_ID | base64. 得到AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY的base64编码
%%bash
# Replace placeholder with your own AWS credentials
AWS_ACCESS_KEY_ID='xxxxxxxx'
AWS_SECRET_ACCESS_KEY='xxxxxxx'
kubectl create secret generic aws-secret --from-literal=AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} --from-literal=AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
secret "aws-secret" deleted
secret/aws-secret created
设置 S3 and ECR 访问许可
在本文中,我们将同时使用S3和ECR服务。我们将使用S3来存储和访问管道数据。我们将使用ECR作为训练镜像的容器注册表。我们需要将IAM策略添加到工作节点,以便能够访问S3和ECR,在终端中运行以下命令并分配所需的权限:
aws iam attach-role-policy --role-name $NODE_INSTANCE_ROLE --policy-arn arn:aws-cn:iam::aws:policy/AmazonEC2ContainerRegistryFullAccess
aws iam attach-role-policy --role-name $NODE_INSTANCE_ROLE --policy-arn arn:aws-cn:iam::aws:policy/AmazonS3FullAccess
注意中国区ARN前缀为”arn:aws-cn”
验证访问权限
- 下面的单元格检查该笔记本是否生成了凭证以访问AWS S3和ECR
注意: 替换region_name=’cn-northwest-1′

3)构建模型训练的容器镜像:
首先执行mnist_aws.ipynb笔记本中的安装依赖库代码单元格将安装训练模型所需要的库,训练模型会需要tf-operator,tf-operator是Kubeflow的一个CRD实现,解决了TensorFlow模型训练的问题,它提供了广泛的灵活性和可配置,可以与aws无缝集成

为Kubeflow Fairing配置Image Registry
Kubeflow Fairing是一个Python软件包,可轻松在kubeflow上训练和部署ML模型。Kubeflow Fairing还可以扩展为在其他平台上进行培训或部署。目前,Kubeflow Fairing已扩展为可在aws云平台上进行培训。Kubeflow Fairing可以把Jupyter笔记本,Python函数或Python文件打包为Docker映像,然后在KubeflowI平台上部署并运行培训作业。在构建过程中,您将会使用kaniko来构建包含训练模型所需环境的容器镜像,Kaniko是一个无守护程序的容器映像生成器的工具。它可以在Kubernetes集群内部作为Docker映像运行以构建Docker映像,Kaniko本身作为容器运行,需要以下信息来构建docker映像:
- Dockerfile的路径。
- 构建上下文(工作区)目录的路径。
- 要将容器镜像推送到的镜像存储库的目标地址。
为了通过kubeflow fairing从笔记本构建Docker镜像,我们需要一个镜像仓库来存储镜像
注意: 替换AWS_ACCOUNT_ID=’xxxxxxx’为您aws账户的account id
DOCKER_REGISTRY = ‘{}.dkr.ecr.{}.amazonaws.com.cn’.format(AWS_ACCOUNT_ID, AWS_REGION)

通过Kubeflow Fairing 构建Docker镜像
注意:由于网络原因,需要指定kaniko的镜像为 “048912060910.dkr.ecr.cn-northwest-1.amazonaws.com.cn/gcr/kaniko-project/executor:v0.14.0″,增加下列代码:
from kubeflow.fairing import constants
constants.constants.KANIKO_IMAGE = "048912060910.dkr.ecr.cn-northwest-1.amazonaws.com.cn/gcr/kaniko-project/executor:v0.14.0"

继续运行notebook的代码单元格得到如下运行结果:

打开aws console的ecr服务,检查已经构建并上传成功的mnist镜像:

继续运行notebook的代码单元格,创建存放训练模型的S3存储桶

打开aws console的s3服务,检查已经创建好的存储桶:

4)开始分布式训练
深度学习模型最常用的分布式训练策略是数据并行,因为训练时的一个重要原因是训练的数据量很大。数据并行就是在很多设备上放置相同的模型,并且各个设备采用不同的训练样本来对模型进行训练。训练深度学习模型常采用的是batch SGD方法,采用数据并行,可以每个节点都训练不同的batch,然后收集这些梯度用于模型参数的更新。比如采用数据并行策略,使用256个GPUs,每个GPU读取32个图片进行训练,这样相当于采用非常大的batch size来训练模型。
而TFJob 是将 tensorflow 的分布式架构基于 k8s 构建的一种CRD,通过TFJob这个资源类型,使用TensorFlow的数据科学家无需编写复杂的配置,只需要关注数据的输入,代码的运行和日志的输入输出,方便在kubernetes上运行Tensorflow的训练任务,高效实现在kubernetes上运行的TensorFlow训练任务,TFJob主要由下列资源类型构成:
- Chief 负责协调训练任务
- Ps 参数服务器,为模型的参数提供分布式的数据存储
- Worker 负责实际训练模型的任务. 在某些情况下 worker 0 可以充当Chief的责任。
- Evaluator 负责在训练过程中进行性能评估
运行分布式训练代码单元格将创建TFJob资源,生成TFJob资源描述如下,在TFJob中指定了镜像名称,ps(参数服务器)的数量,worker的数量,模型的输出路径,以及超参数设置
train_name = f"mnist-train-{uuid.uuid4().hex[:4]}"
num_ps = 1
num_workers = 2
model_dir = f"s3://{bucket}/mnist"
export_path = f"s3://{bucket}/mnist/export"
train_steps = 200
batch_size = 100
learning_rate = .01
image = cluster_builder.image_tag
train_spec = f"""apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
name: {train_name}
spec:
tfReplicaSpecs:
Ps:
replicas: {num_ps}
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
serviceAccount: default-editor
containers:
- name: tensorflow
command:
- python
- /opt/model.py
- --tf-model-dir={model_dir}
- --tf-export-dir={export_path}
- --tf-train-steps={train_steps}
- --tf-batch-size={batch_size}
- --tf-learning-rate={learning_rate}
image: {image}
workingDir: /opt
env:
- name: AWS_REGION
value: {AWS_REGION}
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_SECRET_ACCESS_KEY
restartPolicy: OnFailure
Chief:
replicas: 1
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
serviceAccount: default-editor
containers:
- name: tensorflow
command:
- python
- /opt/model.py
- --tf-model-dir={model_dir}
- --tf-export-dir={export_path}
- --tf-train-steps={train_steps}
- --tf-batch-size={batch_size}
- --tf-learning-rate={learning_rate}
image: {image}
workingDir: /opt
env:
- name: AWS_REGION
value: {AWS_REGION}
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_SECRET_ACCESS_KEY
restartPolicy: OnFailure
Worker:
replicas: 2
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
serviceAccount: default-editor
containers:
- name: tensorflow
command:
- python
- /opt/model.py
- --tf-model-dir={model_dir}
- --tf-export-dir={export_path}
- --tf-train-steps={train_steps}
- --tf-batch-size={batch_size}
- --tf-learning-rate={learning_rate}
image: {image}
workingDir: /opt
env:
- name: AWS_REGION
value: {AWS_REGION}
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_SECRET_ACCESS_KEY
restartPolicy: OnFailure
"""
创建训练任务
通过上面定义的yaml文件,我们就能通过运行TFJob client在EKS中创建分布式训练任务,执行下面的命令:
注意:namespace和运行的notebook的namespace一致
tf_job_client = tf_job_client_module.TFJobClient()
tf_job_body = yaml.safe_load(train_spec)
tf_job = tf_job_client.create(tf_job_body, namespace=namespace)
logging.info(f"Created job {namespace}.{train_name}")
Created job anonymous.mnist-train-a599
检查训练任务
运行kubectl get tfjobs -o yaml {train_name},得到下列输出结果:

获取训练日志
- 使用 kubectl 获取训练pod日志
kubectl logs mnist-train-a599-chief-0 -n anonymous
打开AWS Console的S3服务,在S3存储桶中查看训练好的模型文件

5)部署TensorBoard
TensorBoard 是一款可视化的工具,可以使用 TensorBoard 来展现 TensorFlow tensor,绘制tensor生成的定量指标图以及附加数据。TensorBoard 通过读取 TensorFlow 的事件文件来运行。比如,假设你正在训练一个卷积神经网络,用于识别 MNIST 标签。你可能希望记录学习速度(learning rate)的如何变化,以及目标函数如何变化。通过向节点附加scalar_summary操作来分别输出学习速度和期望误差。然后你可以给每个 scalary_summary 分配一个有意义的标签,比如 ‘learning rate‘ 和 'loss function'。
运行部署TensorBoard代码单元格,该单元格将创建一个 Kubernetes Deployment 运行TensorBoard,并通过Kubeflow endpoint访问TensorBoard UI
tb_name = "mnist-tensorboard"
tb_deploy = f"""apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: mnist-tensorboard
name: {tb_name}
namespace: {namespace}
spec:
selector:
matchLabels:
app: mnist-tensorboard
template:
metadata:
labels:
app: mnist-tensorboard
version: v1
spec:
serviceAccount: default-editor
containers:
- command:
- /usr/local/bin/tensorboard
- --logdir={model_dir}
- --port=80
image: tensorflow/tensorflow:1.15.2-py3
name: tensorboard
env:
- name: AWS_REGION
value: {AWS_REGION}
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_SECRET_ACCESS_KEY
ports:
- containerPort: 80
"""
tb_service = f"""apiVersion: v1
kind: Service
metadata:
labels:
app: mnist-tensorboard
name: {tb_name}
namespace: {namespace}
spec:
ports:
- name: http-tb
port: 80
targetPort: 80
selector:
app: mnist-tensorboard
type: ClusterIP
"""
tb_virtual_service = f"""apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: {tb_name}
namespace: {namespace}
spec:
gateways:
- kubeflow/kubeflow-gateway
hosts:
- '*'
http:
- match:
- uri:
prefix: /mnist/{namespace}/tensorboard/
rewrite:
uri: /
route:
- destination:
host: {tb_name}.{namespace}.svc.cluster.local
port:
number: 80
timeout: 300s
"""
tb_specs = [tb_deploy, tb_service, tb_virtual_service]
运行结果如下:

访问TensorBoard UI
通过kubectl port-forward端口转发映射本地8080端口到指定的kubeflow dashboard 80端口
kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80
从本地网络浏览器输入 ,http://127.0.0.1:8080/mnist/namespace/tensorboard/您就可以进入到Kubeflow UI界面,TensorBoard UI的 GRAPHS 页面可以看到我们构建mnist模型的数据流图
注意:namespace为kubeflow中创建的namespace

6)部署模型
TensorFlow Serving是一个用于机器学习模型Serving的高性能开源库,tenserflow serving 提供一个稳定的接口,供用户调用,来部署模型,serving 通过模型文件直接创建模型即服务(Model as a service),它可以将训练好的机器学习模型部署到kubernetes上作为接口接收外部调用并同时支持模型热更新与自动模型版本管理,具有非常灵活的特点。
继续运行模型部署代码单元格,该代码单元格使用 tensorflow serving部署训练好的模型,会创建一个Kubernetes Deployment和service资源,
import os
deploy_name = "mnist-model"
model_base_path = export_path
# The web ui defaults to mnist-service so if you change it you will
# need to change it in the UI as well to send predictions to the mode
model_service = "mnist-service"
deploy_spec = f"""apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: mnist
name: {deploy_name}
namespace: {namespace}
spec:
selector:
matchLabels:
app: mnist-model
template:
metadata:
# TODO(jlewi): Right now we disable the istio side car because otherwise ISTIO rbac will prevent the
# UI from sending RPCs to the server. We should create an appropriate ISTIO rbac authorization
# policy to allow traffic from the UI to the model servier.
# https://istio.io/docs/concepts/security/#target-selectors
annotations:
sidecar.istio.io/inject: "false"
labels:
app: mnist-model
version: v1
spec:
serviceAccount: default-editor
containers:
- args:
- --port=9000
- --rest_api_port=8500
- --model_name=mnist
- --model_base_path={model_base_path}
- --monitoring_config_file=/var/config/monitoring_config.txt
command:
- /usr/bin/tensorflow_model_server
env:
- name: modelBasePath
value: {model_base_path}
- name: AWS_REGION
value: {AWS_REGION}
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aws-secret
key: AWS_SECRET_ACCESS_KEY
image: tensorflow/serving:1.15.0
imagePullPolicy: IfNotPresent
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 30
tcpSocket:
port: 9000
name: mnist
ports:
- containerPort: 9000
- containerPort: 8500
resources:
limits:
cpu: "1"
memory: 1Gi
requests:
cpu: "1"
memory: 1Gi
volumeMounts:
- mountPath: /var/config/
name: model-config
volumes:
- configMap:
name: {deploy_name}
name: model-config
"""
service_spec = f"""apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/path: /monitoring/prometheus/metrics
prometheus.io/port: "8500"
prometheus.io/scrape: "true"
labels:
app: mnist-model
name: {model_service}
namespace: {namespace}
spec:
ports:
- name: grpc-tf-serving
port: 9000
targetPort: 9000
- name: http-tf-serving
port: 8500
targetPort: 8500
selector:
app: mnist-model
type: ClusterIP
"""
monitoring_config = f"""kind: ConfigMap
apiVersion: v1
metadata:
name: {deploy_name}
namespace: {namespace}
data:
monitoring_config.txt: |-
prometheus_config: {{
enable: true,
path: "/monitoring/prometheus/metrics"
}}
"""
model_specs = [deploy_spec, service_spec, monitoring_config]
运行结果如下:
Deleted Deployment anonymous.mnist-model
Created Deployment anonymous.mnist-model
Deleted Service anonymous.mnist-service
Created Service anonymous.mnist-service
Deleted ConfigMap anonymous.mnist-model
Created ConfigMap anonymous.mnist-model
7).部署应用
整个部署过程与TensorBoard使用方法类似,唯一的不同只是需要使用Docker镜像与标记。
最后我们将部署mnist UI应用可视化mnist训练结果
ui_name = "mnist-ui"
ui_deploy = f"""apiVersion: apps/v1
kind: Deployment
metadata:
name: {ui_name}
namespace: {namespace}
spec:
replicas: 1
selector:
matchLabels:
app: mnist-web-ui
template:
metadata:
labels:
app: mnist-web-ui
spec:
containers:
- image: 048912060910.dkr.ecr.cn-northwest-1.amazonaws.com.cn/gcr/kubeflow-examples/mnist/web-ui:v20190112-v0.2-142-g3b38225
name: web-ui
ports:
- containerPort: 5000
serviceAccount: default-editor
"""
ui_service = f"""apiVersion: v1
kind: Service
metadata:
annotations:
name: {ui_name}
namespace: {namespace}
spec:
ports:
- name: http-mnist-ui
port: 80
targetPort: 5000
selector:
app: mnist-web-ui
type: ClusterIP
"""
ui_virtual_service = f"""apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: {ui_name}
namespace: {namespace}
spec:
gateways:
- kubeflow/kubeflow-gateway
hosts:
- '*'
http:
- match:
- uri:
prefix: /mnist/{namespace}/ui/
rewrite:
uri: /
route:
- destination:
host: {ui_name}.{namespace}.svc.cluster.local
port:
number: 80
timeout: 300s
"""
ui_specs = [ui_deploy, ui_service, ui_virtual_service]
运行结果如下:
Deleted Deployment anonymous.mnist-ui
Created Deployment anonymous.mnist-ui
Deleted Service anonymous.mnist-ui
Created Service anonymous.mnist-ui
Deleted VirtualService anonymous.mnist-ui
Created VirtualService mnist-ui.mnist-ui
访问Web UI来测试您的模型
从本地网络浏览器输入 http://127.0.0.1:8080/mnist/namespace/ui/,您就可以进入到Web UI测试界面
注意:namespace为kubeflow中创建的namespace

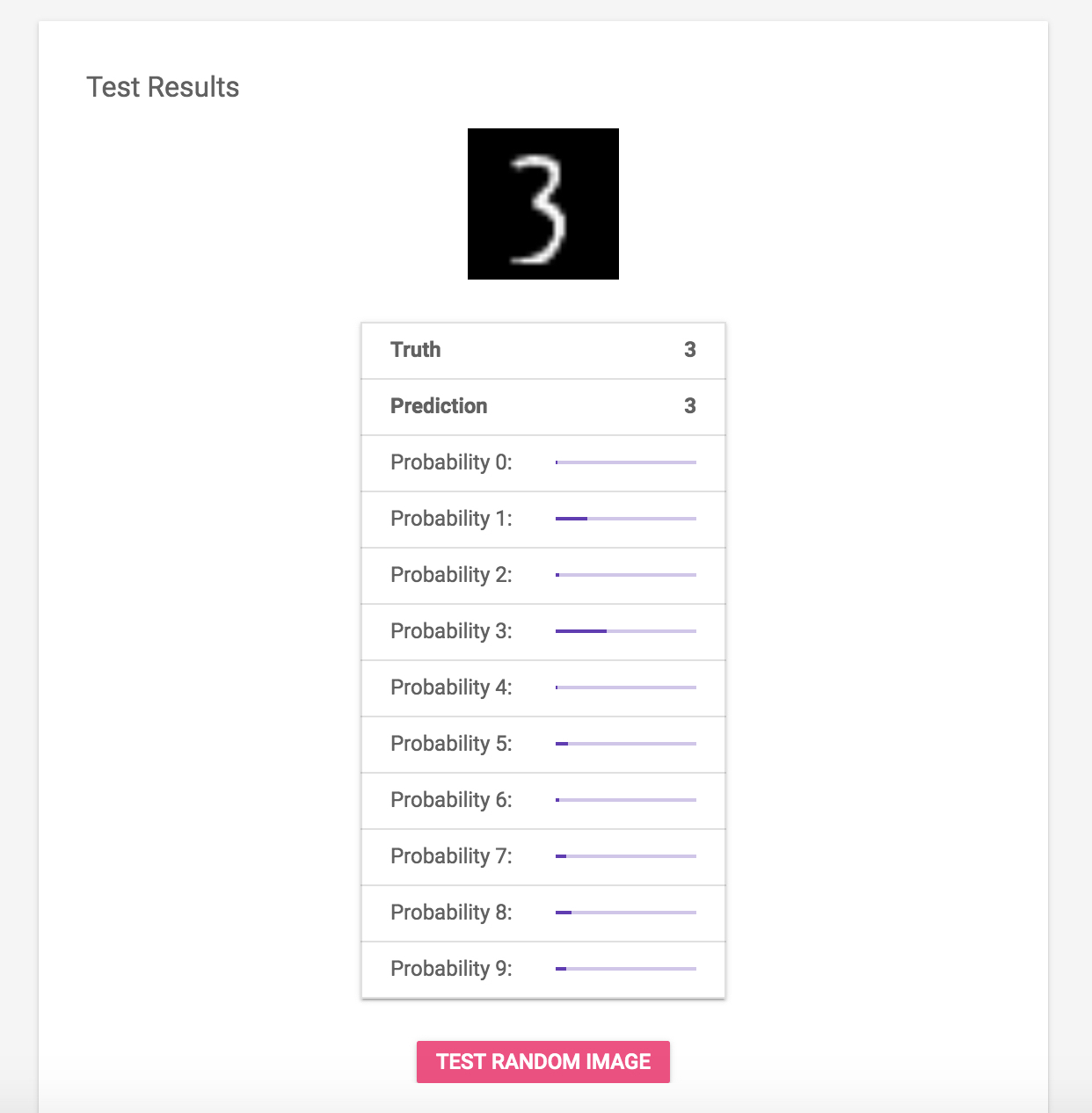
对于每个手写数字图像,模型都会预测在0 – 9的概率。您也可以单击页面底部的TEST RANDOM IMAGE测试其他图像。

现在,您可以使用不同的输入(手写数字)来测试模型。在上面的截图中,图片显示了一个手写的3这个图像是模型的输入。下表显示了从0到9的每个分类标签的柱状图,作为模型的输出。每个柱状图表示图像与相应标签匹配的概率,从上图可以看出,模型正确预测了手写图像的数字。
3.小结
在本文中,我们完整演示一个从创建托管的Jupyter笔记本,用Kubeflow Fairing远程构建模型训练镜像,用TFJob 实现分布式训练用于图像分类的MNIST机器学习模型,用TensorFlow Serving一键式模型部署以及应用界面集成进行在线预测的一个端到端机器学习的完整过程。企业可以通过Kubeflow在Amazon EKS上实现完整的ML工作流程,并对机器学习中的模型训练,超参数训练,模型部署等进行组合并以容器化的方式进行部署。
4. 资料参考
https://eksworkshop.com/tags/opn401/
https://www.kubeflow.org/docs/
https://github.com/kubeflow/pipelines/tree/master/components/aws/sagemaker
https://medium.com/Kubeflow/Kubeflow-1-0-cloud-native-ml-for-everyone-a3950202751
https://cloud.google.com/blog/products/ai-machine-learning/getting-started-kubeflow-pipelines
本篇作者
 从上图可以看出 Kubeflow从工业上机器学习的整体流程,数据采集,验证,到模型训练和服务发布,几乎所有的步骤Kubeflow都提供解决方案的组件,Kubeflow将机器学习各个阶段涉及的组件以微服务的方式进行组合并以容器化的方式进行部署,提供整个流程各个系统的高可用及方便的进行扩展。本文将通过Kubeflow中如下系列组件提供一个端到端的机器学习过程。
从上图可以看出 Kubeflow从工业上机器学习的整体流程,数据采集,验证,到模型训练和服务发布,几乎所有的步骤Kubeflow都提供解决方案的组件,Kubeflow将机器学习各个阶段涉及的组件以微服务的方式进行组合并以容器化的方式进行部署,提供整个流程各个系统的高可用及方便的进行扩展。本文将通过Kubeflow中如下系列组件提供一个端到端的机器学习过程。