亚马逊AWS官方博客
使用 Amazon Rekognition Custom Labels 训练一套定制化单类对象检测模型
客户通常需要分析自己的图像,从中找到满足实际业务需求的独特对象。在大多数情况下,我们需要识别的对象可能是企业徽标、工业或农业运营场景下的某些缺陷,或者在卫星扫描图中定位特定事件(例如飓风等)。在本文中,我们将向大家介绍如何训练出一套自定义模型,通过 Amazon Rekognition Custom Labels自定义标签对单一对象加以检测。
Amazon Rekognition是一项全托管服务,用于提供计算机视觉(CV)功能,其通过深度学习技术对规模化的图像及视频进行分析,且用户无需具备任何机器学习(ML)专业知识。Amazon Rekognition Custom Labels则是Amazon Rekognition提供的一项自动化机器学习功能,通过已经标记好的图像来快速训练出符合特定业务需求的计算机视觉模型。此外,Amazon Rekognition Custom Labels还在最新更新中推出针对单一对象的训练支持,帮助大家对单一类对象创建自定义对象检测模型。
解决方案概述
为了向大家展示单一类对象检测功能的工作原理,我们首先创建一套自定义模型,用于检测披萨。使用这项新功能,我们无需额外创建“非披萨”或者其他食品类型的标签。
要创建一套自定义模型,请执行以下操作步骤:
- 在Amazon Rekognition Custom Labels当中创建一个项目。
- 使用包含一个或多个披萨的图像创建一套数据集。
- 使用Amazon Rekognition Custom Labels提供的用户界面,为图像中的全部披萨添加边框以完成图像标记。
- 训练模型并评估其性能。
- 使用自动生成的API端点测试这套新的自定义模型。
Amazon Rekognition Custom Labels使您可以在Amazon Rekognition控制台上管理机器学习模型的训练过程,显著简化整个端到端流程。
创建项目
要创建我们的披萨检测项目,请完成以下操作步骤:
- 在Amazon Rekognition控制台上,选择 Custom Labels。
- 选择Get Started。
- 在Project name部分,输入
PizzaDetection。 - 选择Create project。


您也可以在Projects页面上完成项目创建。大家可以通过左侧导航窗格访问到Projects页面。
创建数据集
要创建这套披萨识别模型,我们首先需要创建一套用于模型训练的数据集。在本文的示例中,我们的数据集由39张包含披萨的图像组成,所有图像来自pexels.com网站。
要创建数据集,请完成以下操作:
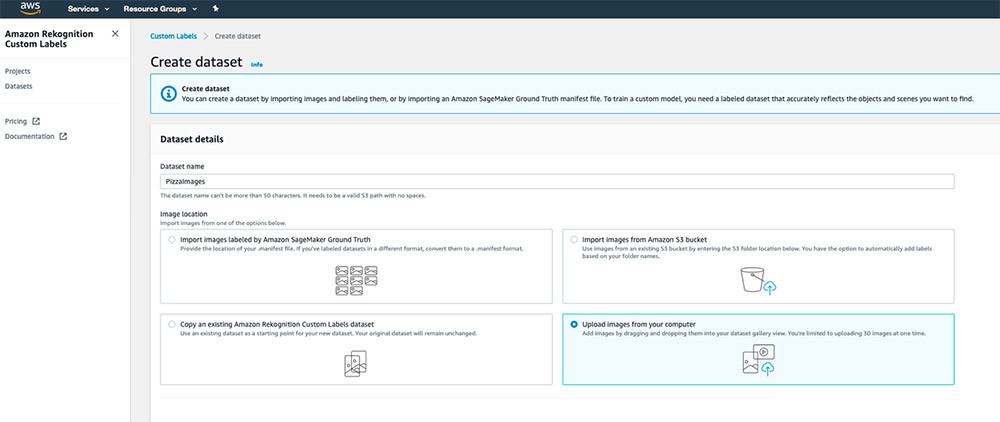
- 选择 Create dataset。
- 选择 Upload images from your computer。

- 选择 Add Images。
- 上传您的图像。您可以随时添加更多后续图像。


用边框标记图像
现在,大家可以在所有带有披萨的图像上使用边框以完成图像标记。
- 通过图库左侧的标签列表,将
Pizza作为标签添加到该数据集内。
- 选择所有带有披萨的图像,并选择Draw Bounding Box,将该标签应用至所有图像中的披萨处。

您可以使用Shift键自动在第一张与最后一张选定的图像之间,快速选定多幅图像。
请绘制一个尽可能紧密覆盖披萨的边界框。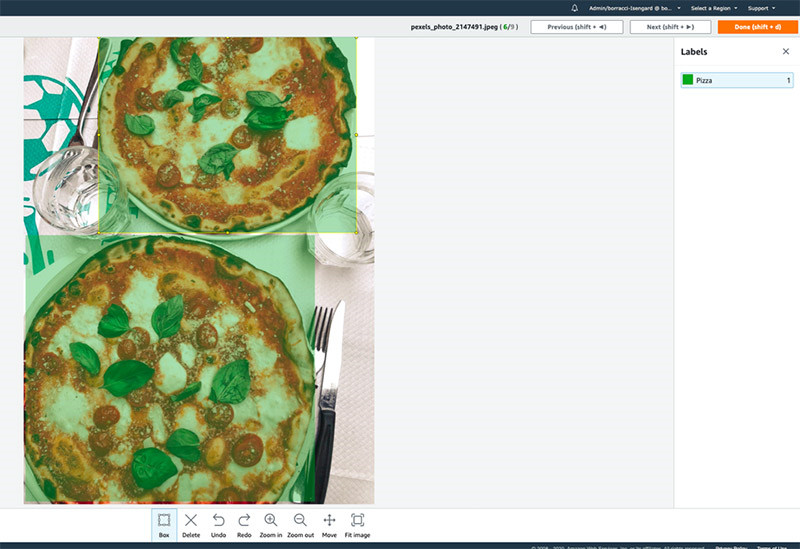
模型训练
在图像标记完成之后,即可开始进行模型训练。
- 选择 Train Model。
- 在Choose project部分, 选择您的
PizzaDetection项目。 - 在 Choose training dataset部分, 选择您的
PizzaImages数据集。
作为模型训练中的重要环节,Amazon Rekognition Custom Labels要求大家提供带有标签的测试数据集。Amazon Rekognition Custom Labels会使用这套测试数据集验证已经训练完成的模型,根据正确标签判断其能否顺利做出预测,同时提供评估指标。测试数据集中的图像不应与训练数据集相重复,且需要保证其与未来模型实际分析的图像类型相同。
- 在Create test set部分,选择如何提供测试数据集。
Amazon Rekognition Custom Labels提供以下三种选项:
- 选择一套现有测试数据集
- 创建一套新的测试数据集
- 拆分训练数据集
在本文中,我们选择拆分训练数据集,而后由Amazon Rekognition保留其中20%的图像进行测试,其余80%图像则用于模型训练。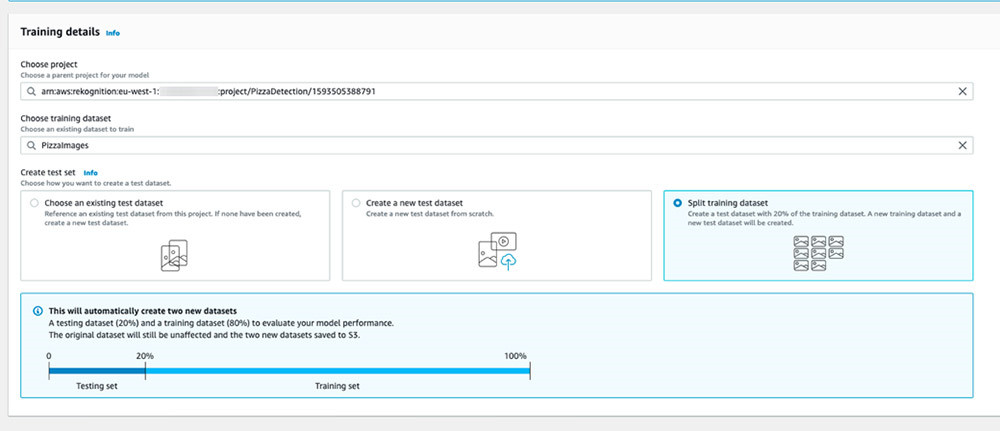
整个模型训练周期大约为1个小时。模型的实际训练时长取决于多种因素,包括数据集中所包含的图像数量以及模型自身的复杂程度。
在训练完成之后,Amazon Rekognition Custom Labels将输出各项关键质量指标,包括F1评分、精度、召回率与阈值等。关于各项指标的更多详细信息,请参阅模型评估指标。
来看看我们的评估结果。当前模型的精度为1.0,意味着这套模型在测试数据集中没有将对象错误识别为披萨(误报)。但这套模型在测试集中,未能正确识别出某些披萨图案(漏报),而召回率得分仅为0.81。我们一般可以将F1评分作为整体质量得分,因为其中已经同时考虑到精度与召回率指标。最后,我们看到这套披萨检测模型的F1得分、精度与召回率指标的阈值为0.61。在默认情况下,我们的模型会将置信度高于0.61的预测结果作为正确答案返回;如果下调这一置信度阈值,则会增加模型的召回率,但也很可能导致精度有所下降。
我们还可以选择View Test Results以查看这套模型在每幅测试图像上的具体表现。以下截屏所示,为模型在测试过程中正确识别出披萨部分的示例。
模型测试
现在这套自定义披萨检测模型已经可以投入使用了。Amazon Rekognition Custom Labels提供用于启动、使用及停止模型的API调用,大家无需管理任何对应基础设施。以下截屏所示,为如何使用模型的API调用。
通过使用API,我们在来自pexels.com的新图像测试集上试用这套模型。例如,下图所示为桌上的披萨以及其他对象。
这套模型以91.72%的置信度与正确的边界框成功检测出了披萨图案。以下代码,为API调用接收到的JSON响应。
下图的置信度得分为98.40。
下图的置信度得分为96.51。

如下图所示,由于图像中并不包含披萨,因此结果如您所料为空JSON。

下图同样为空JSON结果。

除了使用API之外,大家还可以使用Custom Labels Demonstration(自定义标签演示)。通过这套AWS CloudFormation模板,您可以设置自定义且受密码保护的UI,在其中启动并停止模型,以及运行推理演示。
总结
在本文中,我们向大家展示了如何使用Amazon Rekognition Custom Labels创建单一类对象检测模型。这项功能使自定义模型的训练过程变得非常简单,该自定义模型能够检测到对象类,且无需为其指定其他对象或降低结果的准确率。
关于使用自定义标签的更多详细信息,请参阅 Amazon Rekognition Custom Labels是什么?