亚马逊AWS官方博客
使用 Amazon SageMaker Data Wrangler 准备 Snowflake 数据以进行机器学习
数据准备仍然是机器学习 (ML) 领域的主要挑战之一。数据科学家和工程师需要编写查询和代码以从源数据存储中获取数据,然后编写查询来转换这些数据,以创建用于模型开发和训练的特征。所有这些数据管道开发工作并不关注机器学习模型的构建,而是侧重于构建向模型提供数据所需的数据管道。Amazon SageMaker Data Wrangler 使数据科学家和工程师能够通过使用可视界面更轻松地在开发机器学习(ML)应用程序的早期阶段准备数据。
Data Wrangler 使用单个可视界面简化了数据准备和特征工程的过程。Data Wrangler 附带了 300 多种内置数据转换功能,可帮助实现特征的标准化、转换和组合,而无需编写任何代码。现在,您可以在 Data Wrangler 中使用 Snowflake 作为数据源,轻松为机器学习(ML)准备 Snowflake 数据。
在这篇文章中,我们使用了一组模拟数据集,该数据集是金融服务提供商提供的贷款数据,由 Snowflake 提供。该数据集包含有关向个人发放贷款的贷款人数据。我们使用 Data Wrangler 来转换和准备数据以在 ML 模型中使用,首先在 Data Wrangler 中构建数据流,然后将其导出到 Amazon SageMaker Pipelines。首先,我们将完成将 Snowflake 设置为数据源,然后使用 Data Wrangler 探索和转换数据。
先决条件
本文假设您已满足以下先决条件:
- 拥有创建存储集成权限的 Snowflake 账户
- Snowflake 表中的数据
- 具有创建 Identity and Access Management (IAM) 策略和角色的权限的亚马逊云科技账户
- 一个 Amazon Simple Storage Service (Amazon S3) 存储桶,Data Wrangler 可用于输出转换后的数据
设置 Data Wrangler 的权限
在本节中,我们会介绍将 Snowflake 设置为 Data Wrangler 的数据源所需的权限。本节内容要求您在 亚马逊云科技管理控制台和 Snowflake 中执行步骤。各个环境中的用户都应有权在亚马逊云科技平台中创建策略、角色和密钥,并有权在 Snowflake 中创建存储集成。
亚马逊云科技资源的所有权限均通过挂载到 Amazon SageMaker Studio 实例的 IAM 角色进行管理。Snowflake 特定的权限由 Snowflake 管理员管理;它们可以向每个 Snowflake 用户授予精细权限和特权。这包括数据库、架构、表、仓库和存储集成对象。请确保在 Data Wrangler 之外设置了正确的权限。
访问权限要求
Snowflake 需要对输出 S3 存储桶和前缀的以下权限才能访问这些对象:
- s3:GetObject
- s3:GetObjectVersion
- s3:ListBucket
您可以添加存储桶策略,以确保 Snowflake 仅通过 HTTPS 与存储桶通信。有关说明,请参阅我应该使用什么 S3 存储桶策略来遵守 Amazon Config 规则 s3-bucket-ssl-requests-only?
创建允许 Amazon S3 访问的 IAM 策略
在本节中,我们将介绍如何创建所需策略以便 Snowflake 访问您选择的 S3 存储桶中的数据。如果您已经拥有允许访问计划用于 Data Wrangler 输出的 S3 存储桶的策略和角色,则可以跳过本节和下节内容,然后开始在 Snowflake 中创建存储集成。
- 在 IAM 控制台上,在左侧导航窗格中选择Policies(策略)。
- 选择 Create policy(创建策略)。
- 在 JSON 选项卡上,输入以下 JSON 代码段,用存储桶和前缀名称替换占位符:
- 选择 Next: Tags(下一步:标签)。
- 选择 Next: Review(下一步:审查)。
- 对于名称,输入策略的名称(例如,snowflake_datawrangler_s3_access)。
- 选择 Create policy(创建策略)。
创建 IAM 角色
在本节中,我们创建了一个 IAM 角色并将其附加到我们创建的策略中。
- 在 IAM 控制台上,在左侧导航窗格中选择 Roles(角色)。
- 选择 Create role(创建角色)。
- 选择 Another AWS account(另一个亚马逊云科技账户)作为信任实体类型
- 对于账户 ID 字段,请输入您自己的亚马逊云科技账户 ID。
稍后您可以修改信任关系并授予对 Snowflake 的访问权限。
- 选择 Require External ID(需要外部 ID)
- 输入虚拟 ID,例如您自己的账户 ID。
稍后,我们会修改信任关系并为 Snowflake 阶段指定外部 ID。需要外部 ID 才能向第三方 (Snowflake) 授予对您的亚马逊云科技资源(例如 Amazon S3)的访问权限。
- 选择 Next(下一步)。
- 找到您之前为 S3 存储桶创建的策略,然后选择此策略。
- 选择 Next(下一步)。
- 输入角色的名称和描述,然后选择 Create role(创建角色)。
现在,您已为 IAM 角色创建了 IAM 策略,并且该策略已挂载到该角色。
- 记录角色摘要页面上的角色 ARN 值。
在下一步中,您将创建引用此角色的 Snowflake 集成。
在 Snowflake 中创建存储集成
Snowflake 中的存储集成将存储生成的 IAM 实体用于外部云存储,并可选地配置在 Amazon S3 中的允许或阻止的位置。您组织中的亚马逊云科技管理员向生成的 IAM 实体授予存储位置的权限。使用此功能,用户在创建阶段或加载或卸载数据时无需提供凭证。
使用以下代码创建存储集成:
为您的 Snowflake 账户检索 IAM 用户
运行以下 DESCRIBE INTEGRATION 命令来检索为您的 Snowflake 账户自动创建的 IAM 用户的 ARN:
DESC INTEGRATION SAGEMAKER_DATAWRANGLER_INTEGRATION;
记录以下输出的值:
- STORAGE_AWS_IAM_USER_ARN — 为您的 Snowflake 账户创建的 IAM 用户
- STORAGE_AWS_EXTERNAL_ID — 建立信任关系所需的外部 ID
更新 IAM 角色信任策略
现在我们更新信任策略。
- 在 IAM 控制台上,在左侧导航窗格中选择 Roles(角色)。
- 选择您创建的角色。
- 在 Trust relationship(信任关系)选项卡上,选择 Edit trust relationship(编辑信任关系)。
- 修改策略文档,如以下代码所示,使用您在上一步中记录的 DESC STORAGE INTEGRATION 输出值:
5. 选择 Update trust policy(更新信任策略)。
在 Snowflake 中创建一个外部阶段
我们使用 Snowflake 中的外部阶段将数据从您自己账户中的 S3 存储桶加载到 Snowflake 中。在此步骤中,我们创建了一个外部 (Amazon S3) 阶段,该阶段引用了您创建的存储集成。有关更多信息,请参阅创建 S3 阶段。
这需要一个对架构具有 CREATE_STAGE 权限以及对存储集成拥有 USAGE 权限的角色。您可以向角色授予这些权限,如下一步中的代码中所示。
使用 CREATE_STAGE 命令创建阶段,其中包含外部阶段的占位符、S3 存储桶和前缀。该阶段还引用了名为 my_csv_format 的命名文件格式对象:
将架构上的创建阶段公开授予角色<iam_role>;
将集成 SAGEMAKE_DATAWRANGLER_INTEGRATION 的使用授予角色<iam_role_arn>;
创建阶段 <external_stage>
为 Snowflake 凭证创建密钥(可选)
Data Wrangler 允许用户使用 Amazon Secrets Manager 密钥的 ARN 或 Snowflake 账户名称、用户名和密码来访问 Snowflake。如果您打算使用 Snowflake 账户名称、用户名和密码选项,请跳到下一节,其中涉及添加数据源的操作。默认情况下,Data Wrangler 在使用第二个选项时会代表您创建一个 Secrets Manager 密钥。
要手动创建 Secrets Manager 密钥,请完成以下步骤:
-
- 在 Secrets Manager 控制台中,选择Store a new secret(存储新密钥)。
- 对于 Select secret type(选择密钥类型),选择 Other types of secrets(其他类型的密钥)。
- 将密钥的详细信息指定为键值对。
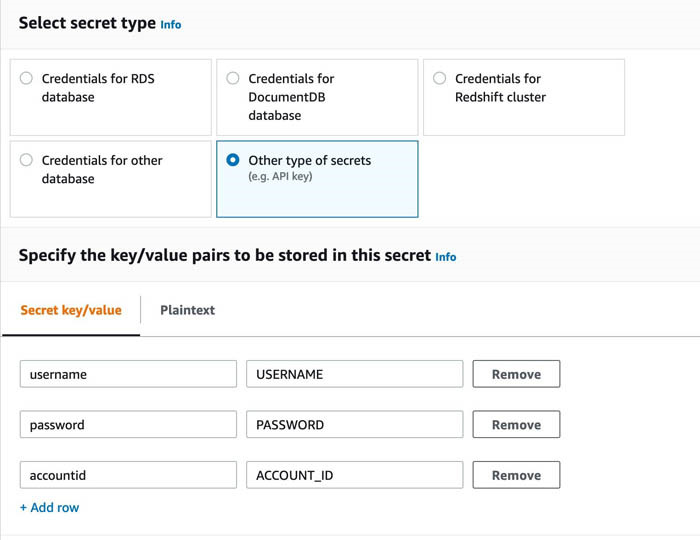
密钥的名称区分大小写,必须使用小写。如果您输入的内容出现任何错误,Data Wrangler 将会报错。
如果愿意,您可以使用纯文本选项并以JSON形式输入密码值:
- 选择 Next(下一步)。
- 对于密钥名称,请添加前缀 AmazonSageMaker(例如,我们的密钥为 AmazonSageMaker-DataWranglerSnowflakeCreds)。
- 在标签部分中,添加一个带有键 SageMaker 且值为 true 的标签。

- 选择 Next(下一步)。
- 其余字段是可选的;选择 Next(下一步),直到您可以选择 Store(存储)来存储密码。
存储密码后,您将返回到 Secrets Manager 控制台。
- 选择刚创建的密钥,然后检索密钥 ARN。
- 将其存储在您选择的文本编辑器中,以便稍后在创建 Data Wrangler 数据源时使用。
在 Data Wrangler 中设置数据源
在本节中,我们将介绍如何在 Data Wrangler 中将 Snowflake 设置为数据源。在本文中,我们假设您有权访问 Studio 的实例 SageMaker,并拥有 Studio 的用户。有关先决条件的更多信息,请参阅 Data Wrangler 入门。
创建新的数据流
要创建数据流,请完成以下步骤:
-
- 在 SageMaker 控制台上,在导航窗格中选择 Amazon SageMaker Studio。
- 选择Open Studio(打开 Studio)。
- 在启动器中,选择 New data flow(新建数据流)。
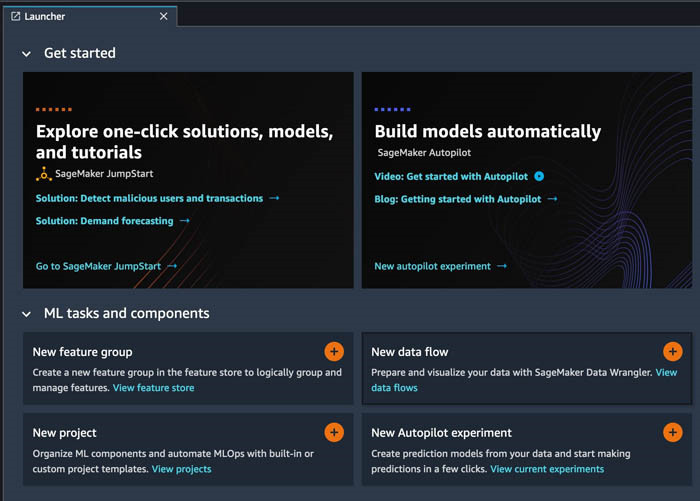
或者,在 File(文件)下拉列表中,选择 New(新建),然后选择 Data Wrangler Flow。
创建新的流程可能需要几分钟时间。创建流程后,您将看到导入数据页面。

在 Data Wrangler 中添加 Snowflake 作为数据源
接下来,我们将添加 Snowflake 作为数据源。
- 在 Add data source(添加数据源)菜单上,选择 Snowflake。
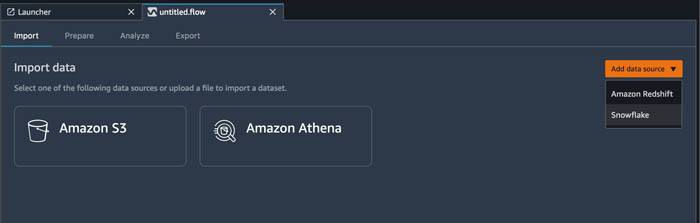
- 添加您的 Snowflake 连接详细信息。
Data Wrangler 使用 HTTPS 连接到 Snowflake。

- 如果您手动创建了 Secrets Manager 密钥,请选择 Authentication method(身份验证方法)下拉菜单,然后选择 ARN。

- 选择 Connect(连接)。
您被重新导向到导入菜单。

运行查询
现在 Snowflake 已设置为数据源,您可以直接从 Data Wrangler 查询编辑器访问 Snowflake 中的数据。我们在编辑器中编写的查询是 Data Wrangler 用来从 Snowflake 导入数据以开始数据流的内容。
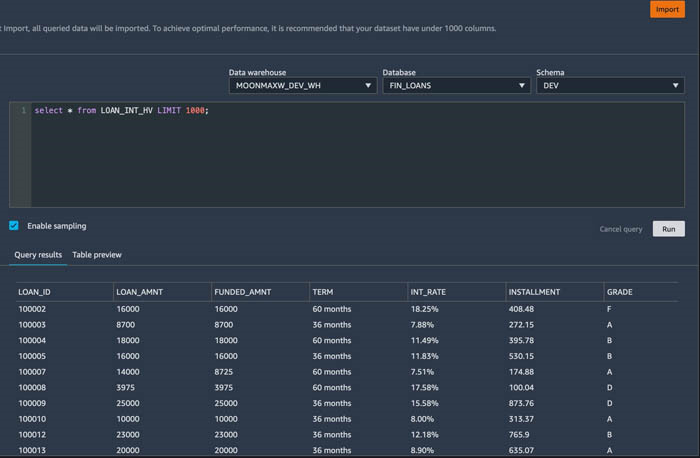
- 在下拉菜单中,选择要用于查询的数据仓库、数据库和架构。
在本文中,我们的数据集位于数据库 FIN_LOANS 中,架构为 DEV,表格是 LOAN_INT_HV。我的数据仓库名为 MOONMAXW_DEV_WH;根据您的设置,这些可能会有所不同。
或者,您可以在查询编辑器中指定数据集的完整路径。确保您仍然在下拉菜单中选择数据库和架构。
- 在查询编辑器中,输入查询并预览结果。
在本文中,我们从 1,000 行中检索所有列。
- 选择 Import(导入)。
- 在出现提示时输入数据集名称(在本文中,我们使用 snowflake_loan_int_hv)。
- 选择 Add(添加)。
您将转到准备页面,在此可以向数据添加转换和分析。
向数据添加转换
Data Wrangler 有 300 多项内置转换。在本节中,我们使用其中的一些转换来为机器学习(ML)模型准备数据集。
在 Data Wrangler 流程页面上,确保选择了 Prepare(准备)选项卡。如果您按照文中的步骤操作,则在添加数据集后将自动定向到此处。

转换数据类型
我们要执行的第一步是检查是否在每列的摄取时推断出了正确的数据类型。
- 在 Data types(数据类型)旁,选择加号。
- 选择 Edit data types(编辑数据类型)。

通过这些列,我们发现 MNTHS_SINCE_LAST_DELINQ 和 MNTHS_SINCE_LAST_RECORD 最有可能表示为数字类型,而不是字符串。

- 在右侧菜单上,向下滚动直至找到 MNTHS_SINCE_LAST_DELINQ 和 MNTHS_SINCE_LAST_LAST_RECORD。
- 在下拉菜单中,选择 Float(浮点数)。

通过数据集,我们可以确认其余列似乎已正确推断。
- 选择 Preview(预览)以预览更改。
- 选择 Apply(应用)以应用更改。
- 选择 Back to data flow(返回到数据流)以查看流程的当前状态。
管理列
我们正在使用的数据集有几个可能对未来模型无益的列,因此我们首先删除那些没有用处的列来开始转换过程。
- 在 Data types(数据类型)旁,选择加号。
- 选择 Add transformation(添加转换)。
转换控制台随即打开。在这里,您可以预览数据集、从可用的转换中选择并预览转换。

通过数据,我们可以看到,EMP_TITLE、URL、DESCRIPTION 和 TITLE 字段在我们的使用案例中可能不会为我们的模型提供价值,因此我们将其删除。
- 在转换菜单上,选择 Manage columns(管理列)。
- 在转换下拉菜单中,离开“删除”列
- 为要删除的列输入 EMP_TITLE。
- 选择 Preview(预览)以查看更改。
- 选择 Add(添加)以添加步骤。
- 如果要查看添加的步骤和之前的步骤,请在 Transform(转换)中选择 Previous steps(上一步)
- 对其余列(URL、DESCRIPTION 和 TITLE)重复这些步骤。
- 选择 Back to data flow(返回到数据流)以查看流程的当前状态。
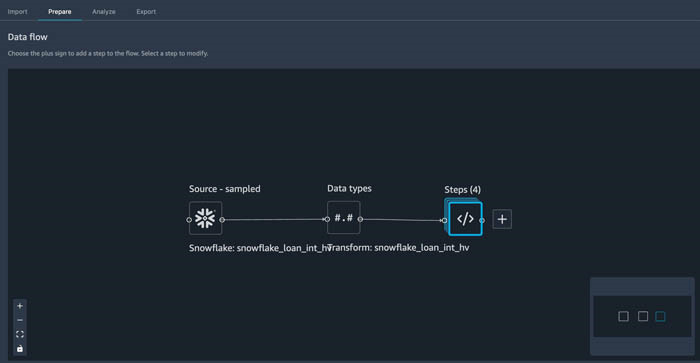
在数据流视图中,我们可以看到流程中的此节点有四个步骤,它们表示我们为流程的这一部分删除的四列。
格式化字符串
接下来,我们寻找可以格式化的字符串数据的列,以帮助后续使用。通过我们的数据集,我们可以看到 INT_RATE 在未来的浮点模型中可能很有用,但有 % 作为尾随字符。在我们可以使用另一个内置转换(解析为类型)将其转换为浮点数之前,我们必须去掉尾随字符。
- 在 Steps(步骤)旁,选择加号。
- 选择 Add transform(添加转换)。
- 选择 Format string(格式字符串)。
- 在 Transform(转换)下拉列表中,选择 Remove Symbols(移除符号)。
- 在 Input column(输入列)下拉列表中,选择 INT_RATE 列。
- 对于符号,请输入 %。
- 或者,在输出字段中,输入写入此数据的列的名称。
对于本文,我们保留原始列并将输出列设置为 INT_RATE_PERCENTAGE,以便向未来的用户说明此列是利率的百分比。之后,我们将其转换为浮点数。
- 选择 Preview(预览)。
当 Data Wrangler 添加新列时,它会自动添加为最右侧的列。
- 查看更改以确保准确性。
- 选择 Add(添加)。
将列解析为类型
继续上面的示例,我们已经确定 INT_RATE_PERCENTAGE 应该转换为浮点型。
- 在 Steps(步骤)旁,选择加号。
- 选择 Add transform(添加转换)。
- 选择 Parse Column as Type(将列解析为类型)。
- 在 Column(列)下拉列表中,选择 INT_RATE_PERCENTAGE。
From字段将自动填充。
- 在 to(至)下拉菜单中,选择 Float(浮点数)。
- 选择 Preview(预览)。
- 选择 Add(添加)。
- 选择 Back to data flow(返回到数据流)。
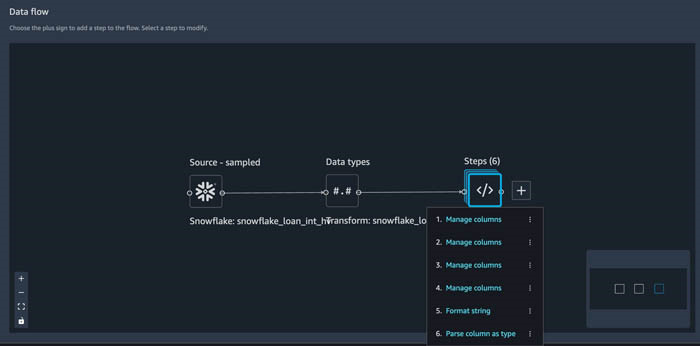
正如您所看到的,我们现在在流程的这一部分有六个步骤,其中四个表示被删除的列,一个表示字符串格式化,另一个将解析列为类型。
对分类数据进行编码
接下来,我们想在数据集中查找分类数据。Data Wrangler 具有内置功能,可以使用序号和独热编码对分类数据进行编码。查看我们的数据集,我们可以看到 TERM、HOME_OWNERSHIP 和 PURPOSE 列在本质上都看起来都是分类的。
- 在 Steps(步骤)旁,选择加号。
- 选择 Add transform(添加转换)。
我们列表中的第一列 TERM 有两个可能的值:60 个月和 36 个月。也许对这些值进行独热编码并放入新列中将使我们未来的模型受益。
- 选择 Encode Categorical(编码类别)。
- 在 Transform(转换)下拉列表中,选择 One-hot encode(独热编码)。
- 对于 Inputcolumn(输入列),选择 TERM。
- 在 Output style(输出样式)下拉列表中,选择 Columns(列)。
- 保留所有其他字段和复选框。
- 选择 Preview(预览)。
我们现在可以看到两列,TERM_36 months 和 TERM_60 months,是独热编码来表示 TERM 列中的相应值。
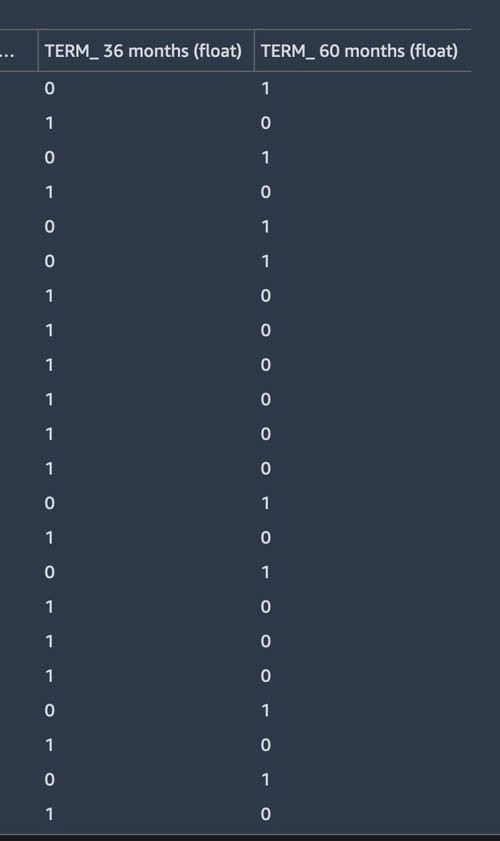
- 选择 Add(添加)。
HOME_OWNERSHIP 列有四个可能的值:RENT、MORTGAGE、OWN 和 other。
- 重复上述步骤,对这些值应用独热编码方法。
最后,PURPOSE 列有几个可能的值。对于这些数据,我们也使用独热编码方法,但我们将输出设置为矢量而不是列。
- 在 Transform(转换)下拉列表中,选择 One-hot encode(独热编码)。
- 对于 Inputcolumn(输入列),选择 PURPOSE。
- 在 Output style(输出样式)下拉列表中,选择 Vector(向量)。
- 对于输出列,我们将此列称为 PURPOSE_VCTR。
如果我们决定以后使用它,这将保留原来的 PURPOSE 列。
- 保留所有其他字段和复选框。
- 选择 Preview(预览)。

- 选择 Add(添加)。
- 选择 Back to data flow(返回到数据流)。
我们现在可以在这个流程中看到九种不同的转换,但我们还没有编写一行代码。

处理异常值
作为此流程的最后一步,我们希望处理数据集中的异常值。作为数据探索过程的一部分,我们可以创建一个分析(将在下一节中介绍)。在以下示例散点图中,我探讨了是否可以通过在散点图上观察数据集来查看年收入、利率和就业时间之间的关系来获得见解。在图上,我们在 X 轴上有贷款接收人 INT_RATE_PERCENTAGE,Y 轴上有 ANNUAL_INC,数据用 EMP_LENGTH 进行颜色编码。数据集中有一些异常值,可能会在以后扭曲我们模型的结果。为了解决这个问题,我们使用 Data Wrangler 的内置转换来处理异常值。

- 在 Steps(步骤)旁,选择加号。
- 选择 Add transform(添加转换)。
- 选择 Handle outliers(处理异常值)。
- 在 Transform(转换)下拉列表中,选择 Standard deviation numeric outliers(标准差数字异常值)。
- 对于“输入”列,输入 ANNUAL_INC。
- 对于“输出”列,输入 ANNUAL_INC_NO_OUTLIERS。
这是可选的,但最好注意有一列已经为之后的消费者进行了转换。
- 在 Fix method(修复方法)下拉菜单中,保留Clip(剪切)
此选项会自动将值剪切到相应的异常值检测边界,我们接下来设置该边界。
- 对于标准差,请保留默认值 4 以开始。
这让平均值四个标准差范围内的值都将被视为有效(因此不会剪切)。超出此限制的值将被剪切。
- 选择 Preview(预览)。
- 选择 Add(添加)。
输出包括对象类型。我们需要将其转换为浮点数,才能使其在我们的数据集和可视化结果中有效。
- 按照将列解析为类型时的步骤,这次使用 ANNUAL_INC_NO_OUTLIERS 列。
- 选择 Back to data flow(返回到数据流)以查看流程的当前状态。
向数据添加分析
在本节中,我们将介绍向数据集添加分析。我们专注于可视化,但还有其他几种选择,包括检测目标泄漏、生成偏差报告或使用 Altair 库添加自己的自定义可视化效果。
散点图
要创建散点图,请完成以下步骤:
- 在数据流页面的 Steps(步骤)旁,选择加号。
- 选择 Add analysis(添加分析)。
- 对于 Analysis type(分析类型),选择 Scatter plot(散点图)。
- 使用前面的示例,我们将此分析命名为 EmpLengthAnnualIncIntRate。
- 对于 X 轴,请输入 INT_RATE_PERCENTAGE。
- 对于 Y 轴,请输入 ANNUAL_INC_NO_OUTLIERS。
- 对于颜色依据,输入 EMP_LENGTH。
- 选择 Preview(预览)。
以下屏幕截图显示了我们的散点图。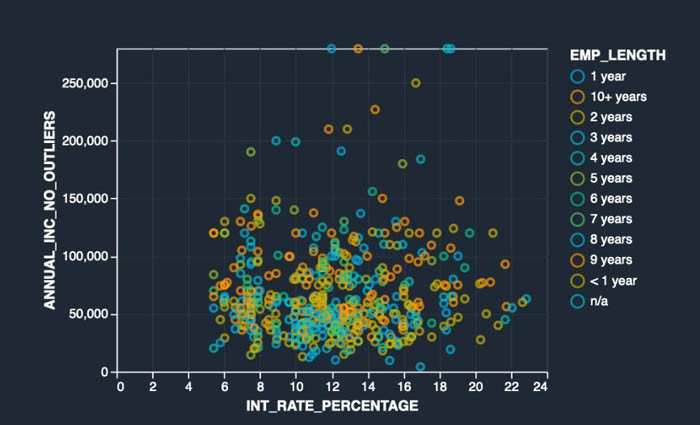
在移除异常之前,我们可以将其与旧版本进行比较。
到目前为止,结果看起来不错,让我们添加一个分面来将级别列中的每个类别分解为自己的图表。
- 对于 Facet by(分面依据),选择 GRADE。
- 选择 Preview(预览)。
为了便于显示,下面的屏幕截图已被调整。Y 轴仍然代表 ANNUAL_INC。对于分面图,这将显示在最底层的绘图上。
- 选择 Save(保存)以保存分析。
导出数据流
最后,我们将整个数据流导出为管道,这将创建一个具有预先填充代码的 Jupyter 笔记本。借助 Data Wrangler,您还可以将数据导出到 Jupyter 笔记本作为 SageMaker Processing 任务、SageMaker Feature Store,或直接导出到 Python 代码。
- 在 Data Flow 控制台上,选择 Export(导出)
- 选择要导出的步骤。在我们的使用案例中,我们选择代表步骤的每个框。


- 选择 Export step(导出步骤),然后选择 Pipeline(管道)。
预先填充的 Jupyter 笔记本会自动加载并打开,显示数据流生成的所有步骤和代码。以下屏幕截图显示了定义数据源的输入部分。
清理
如果您使用 Data Wrangler 的工作已完成,请关闭 Data Wrangler 实例以避免产生额外费用。
结论
在本文中,我们介绍了将 Snowflake 设置为 Data Wrangler 的数据源,将转换和分析添加到数据集中,然后导出到数据流以便在 Jupyter 笔记本中进一步使用。在使用 Data Wrangler 内置的分析功能对数据集进行可视化处理后,我们进一步改善了数据流。最值得注意的是,我们不必编写一行代码,便构建了数据准备管道。
要开始使用 Data Wrangler,请参阅使用 Amazon SageMaker Data Wrangler 准备机器学习(ML)数据,并查看 Data Wrangler 产品页面上的最新信息。
Data Wrangler 可以轻松摄取数据和执行数据准备任务,例如探索性数据分析、特征选择、特征工程。在这篇文章中,我们只介绍了 Data Wrangler 的一部分数据准备功能;您还可以使用 Data Wrangler,借助简单直观的用户界面进行更高级的数据分析,例如特征重要性、目标泄漏和模型可解释性。