背景介绍
随着CodePipeline在中国北京和宁夏区的发布,越来越多的企业开始把原有的流水线迁移到AWS上。对于不同的业务和需求,流水线的复杂度也各不相同。其中不乏一些较为复杂的流水线,其复杂主要体现在两个方面,一个是流水线的阶段(stage)比较多,另一个则是阶段(stage)里面动作(action)的步骤比较复杂,这就直接导致了流水线的整个执行时间比较长。本文着重从两个方面对流水线的执行进行加速,一是使用缓存对CodeBuild的任务进行加速,二是根据Docker的特性对镜像构建进行加速。
部署架构
出于简化的目的,本文提炼出如下具备通用性的持续集成流水线。该流水线包含了从代码提交,到代码扫描,最后到打包成Docker镜像推送到ECR的全过程。其中,代码扫描任务使用了CodeBuild的缓存策略进行加速,而镜像打包则使用了Docker镜像的特性进行加速。

阅读本文的先决条件
本文假定以下前提:
- 对AWS CDK(AWS Cloud Development Kit)有一定的了解
- 对Python编程语言有一定的基础
- 具备一个AWS中国区的账号
实施步骤
本文假定一个Lambda应用需要使用上述流水线进行持续集成。以下实施操作主要使用AWS CDK完成,您可以通过Amazon EC2或者本地电脑构建CDK应用环境,本文操作均在Mac笔记本电脑中执行。在安装CDK前,请确保您已经安装了Node.js并更新到了最新版本。AWS CDK支持TypeScript,Java,Python等多种语言,本文将使用Python语言。请参考此文档构建CDK应用环境。
- 创建代码目录,例如cache_pipeline
- 进入代码目录并执行
cdk init命令初始化代码工程目录
cdk init -l python --generate-only
这时候得到的代码目录结构如下图所示:

- 进入目录cache_pipeline并编辑cache_pipeline_stack.py
- 第一步:首先添加创建ECR镜像库相关的代码。这里创建一个镜像库并对相关服务授权,以便于后续对镜像的操作。
from aws_cdk import (
Duration,
Stack,
aws_codebuild as codebuild,
aws_codecommit as codecommit,
aws_codepipeline as codepipeline,
aws_codepipeline_actions as cpactions,
aws_iam as iam,
aws_ec2 as ec2,
aws_s3 as s3
)
from constructs import Construct
class CachePipelineStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
repo = ecr.Repository(
self,
"LambdaRepository",
repository_name="lambda-repository",
image_scan_on_push=True,
removal_policy=RemovalPolicy.DESTROY,
)
repo.add_to_resource_policy(
iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=[
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"ecr:BatchCheckLayerAvailability",
"ecr:GetAuthorizationToken",
],
principals=[
iam.ServicePrincipal(service="codebuild.amazonaws.com"),
iam.ServicePrincipal(service="lambda.amazonaws.com"),
],
)
)
- 第二步:创建CodeBuild所需要的服务角色以及CodeBuild缓存策略所需要的S3存储桶。
codebuild_policy = [
iam.PolicyStatement(actions=["sts:GetServiceBearerToken"], resources=["*"]),
iam.PolicyStatement(actions=["sts:AssumeRole"], resources=["*"]),
iam.PolicyStatement(
actions=[
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"ecr:BatchCheckLayerAvailability",
"ecr:PutImage",
"ecr:DescribeImages",
"ecr:InitiateLayerUpload",
"ecr:UploadLayerPart",
"ecr:CompleteLayerUpload",
"ecr:GetDownloadUrlForLayer",
"ecr:GetAuthorizationToken",
"ec2:DescribeAvailabilityZones",
"kms:Decrypt",
"kms:Encrypt",
"kms:GenerateDataKey",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"ssm:GetParametersByPath",
"ssm:GetParameters",
"ssm:GetParameter",
"ssm:PutParameter",
"codecommit:GitPull",
],
resources=["*"],
),
]
codebuild_project_role = iam.Role(
self,
id="CachePipelineCodeBuildServiceRole",
assumed_by=iam.ServicePrincipal("codebuild.amazonaws.com"),
inline_policies={
"CachePipelineCodeBuildServicePolicy": iam.PolicyDocument(
statements=codebuild_policy
)
},
)
# create a s3 bucket for caching
cache_bucket = s3.Bucket(
self,
"CachePipelineCacheBucket",
bucket_name="cache-pipeline-cache-bucket",
block_public_access=s3.BlockPublicAccess(
block_public_acls=True,
block_public_policy=True,
ignore_public_acls=True,
restrict_public_buckets=True,
)
)
cache_bucket.add_to_resource_policy(
permission=iam.PolicyStatement(
actions=["s3:*"],
resources=[cache_bucket.bucket_arn],
principals=[iam.ArnPrincipal(arn=codebuild_project_role.role_arn)],
)
)
- 第三步:创建CodePipeline,添加Source阶段用于从源代码仓库(本文使用CodeCommit作为源代码仓库)拉取代码。此阶段作为流水线的起点,每当有新的改动推送到CodeCommit的代码库中,流水线就会被触发执行。
pipeline = codepipeline.Pipeline(
self, id="CachePipeline", pipeline_name="CachePipeline"
)
# source stage
source_artifact = codepipeline.Artifact("Src")
pipeline.add_stage(
stage_name="Source",
actions=[
cpactions.CodeCommitSourceAction(
action_name="CodeCommit",
output=source_artifact,
repository=codecommit.Repository(
self, "sourcerepo", repository_name="lambda_function"
),
branch="main",
)
],
)
- 第四步:创建代码安全扫描阶段(代码的安全扫描是持续集成流水线中比较常见且非常重要的一个步骤)。
security_check = codebuild.PipelineProject(
self,
id="SecurityCheck",
environment=codebuild.BuildEnvironment(
build_image=codebuild.LinuxBuildImage.STANDARD_4_0
),
role=codebuild_project_role,
build_spec=codebuild.BuildSpec.from_source_filename(
"cache_pipeline/build_spec/doing_security_check.yaml"
),
cache=codebuild.Cache.bucket(cache_bucket),
)
pipeline.add_stage(
stage_name="SecurityCheck",
actions=[
cpactions.CodeBuildAction(
action_name="VulnerabilityCheck",
input=source_artifact,
project=security_check,
),
],
)
- 第五步:创建代码镜像构建以及推送镜像仓库阶段(注意需要替换正确的账号以及区域)。
# build image and push to ECR
lambdas_image = codebuild.PipelineProject(
self,
id="LambdaImage",
environment=codebuild.BuildEnvironment(
build_image=codebuild.LinuxBuildImage.STANDARD_4_0,
privileged=True,
environment_variables={
"REPOSITORY_URI": codebuild.BuildEnvironmentVariable(
value="<your_account_id>.dkr.ecr.<your_region>.amazonaws.com.cn/lambda-repository"
),
"IMAGE_NAME": codebuild.BuildEnvironmentVariable(
value="lambdas"
),
"REGION": codebuild.BuildEnvironmentVariable(
value="<your_region>"
),
"AccountId": codebuild.BuildEnvironmentVariable(
value="<your_account_id>"
),
"BUILD_FOLDER": codebuild.BuildEnvironmentVariable(value="lambda"),
"DOCKERFILE": codebuild.BuildEnvironmentVariable(
value="Dockerfile"
),
},
),
role=codebuild_project_role,
build_spec=codebuild.BuildSpec.from_source_filename(
"cache_pipeline/build_spec/processing_image_buildspec.yaml"
),
)
pipeline.add_stage(
stage_name="ECRAssets",
actions=[
cpactions.CodeBuildAction(
action_name="LambdaImages",
input=source_artifact,
project=lambdas_image,
),
]
)
- 第六步:保存并退出cache_pipeline_stack.py的编辑。在当前目录下创建build_spec目录,并在build_spec目录中创建文件doing_security_check.yaml,具体内容如下所示。这个文件主要定义了代码安全扫描的具体步骤。其中,我们启用了CodeBuild的缓存策略,具体配置在cache字段下,这里主要是对应用所需要的依赖库进行缓存以加速后续的构建。
# doing_security_check.yaml
version: 0.2
env:
shell: bash
phases:
pre_build:
on-failure: ABORT
commands:
- pip install --upgrade pip
- pip install virtualenv
- virtualenv /root/env
build:
on-failure: ABORT
commands:
- . /root/env/bin/activate
- pip install --upgrade pip
- pip install example --use-feature=2020-resolver
- pip install -r requirements.txt
- pip install bandit
- bandit -lll -r cache_pipeline
cache:
paths:
- "/root/env/**/*"
- 第七步:在build_spec目录中创建文件processing_image_buildspec.yaml,具体内容如下所示。这个文件主要定义了代码镜像构建以及推送镜像仓库的具体步骤。其中,我们使用System Parameter对当前镜像的标签进行存储,主要目的是为了在下一次的镜像构建中使用当前的镜像作为缓存。这里主要利用了Docker Layer的特性,具体用法体为添加参数–cache-from指定作为缓存的目标镜像。
# processing_image_buildspec.yaml
version: 0.2
env:
shell: bash
phases:
pre_build:
on-failure: ABORT
commands:
- apt-get update && apt-get -y install postgresql
- docker version
build:
on-failure: ABORT
commands:
- aws ecr get-login-password --region ${REGION} | docker login --username AWS --password-stdin ${AccountId}.dkr.ecr.${REGION}.amazonaws.com.cn
- PREVIOUS_TAG=$(aws ssm get-parameter --name /lambda/ecr/${IMAGE_NAME}-tag --query "Parameter.Value"| tr -d \"); retval=$?; if [ "x"$PREVIOUS_TAG != "x" ]; then docker pull $REPOSITORY_URI:$PREVIOUS_TAG; fi
- COMMITID=$(echo ${CODEBUILD_RESOLVED_SOURCE_VERSION} | head -c 8)
- IMAGE_TAG=${IMAGE_NAME}-${COMMITID}
- if [ "x"$PREVIOUS_TAG == "x" ]; then cd ${BUILD_FOLDER} && docker build -f ${DOCKERFILE} -t $REPOSITORY_URI:$IMAGE_TAG . ; else cd ${BUILD_FOLDER} && docker build --cache-from $REPOSITORY_URI:$PREVIOUS_TAG -f ${DOCKERFILE} -t $REPOSITORY_URI:$IMAGE_TAG . ; fi
- docker push $REPOSITORY_URI:$IMAGE_TAG
- aws ssm put-parameter --name "/lambda/ecr/${IMAGE_NAME}-tag" --value "${IMAGE_TAG}" --type "String" --overwrite
- 接下来回到项目的根目录下,创建Lambda应用程序目录,例如名字为Lambda的目录(此时Lambda目录和cache_pipeline目录是同等级的目录)。
- 第一步:在Lambda目录中创建文件handler.py,内容如下:
import os
import logging
import jsonpickle
import boto3
from aws_xray_sdk.core import patch_all
logger = logging.getLogger()
logger.setLevel(logging.INFO)
patch_all()
client = boto3.client('lambda')
client.get_account_settings()
def lambda_handler(event, context):
logger.info('### ENVIRONMENT VARIABLE\r' + jsonpickle.encode(dict(**os.environ)))
logger.info('### EVENT\r' + jsonpickle.encode(event))
logger.info('### CONTEXT\r' + jsonpickle.encode(context))
response = client.get_account_settings()
return response['AccountLimit']
- 第二步:在Lambda目录中创建Dockerfile,内容如下:
FROM public.ecr.aws/amazonlinux/amazonlinux:latest
ARG FUNCTION_DIR="/home/app/"
ARG PYTHON_VERSION="3.8.7"
RUN yum -y groupinstall "Development Tools"
RUN yum -y install openssl-devel bzip2-devel libffi-devel postgresql-devel
RUN yum -y install wget
RUN wget https://registry.npmmirror.com/-/binary/python/${PYTHON_VERSION}/Python-${PYTHON_VERSION}.tgz
RUN tar xvf Python-${PYTHON_VERSION}.tgz
RUN cd Python-${PYTHON_VERSION} && ./configure --enable-optimizations && make install
WORKDIR ${FUNCTION_DIR}
COPY . ./
RUN python3.8 -m pip install -r requirements.txt -t .
RUN python3.8 -m pip install awslambdaric --target ${FUNCTION_DIR}
ENTRYPOINT [ "python3.8", "-m", "awslambdaric" ]
CMD ["handler.lambda_handler"]
- 第三步:在Lambda目录中创建文件requirements.txt,内容如下:
jsonpickle==1.3
aws-xray-sdk==2.4.3
- 至此,准备工作已经完成了。接下来设置目标账号的密钥,这里建议使用环境变量进行设置,主要使用以下命令进行设置。(注意需要将正确的密钥替换上去后才可以执行)
export AWS_ACCESS_KEY_ID=<your_access_key_id>
export AWS_SECRET_ACCESS_KEY=<your_access_key_secret>
export AWS_SESSION_TOKEN=<your_session_token>
- 执行下面命令检查代码并查看能否正常生成对应的CloudFormation的模版。
- 执行下面命令创建ECR镜像仓库以及流水线。
创建成功之后会见到类似如下截图的信息:

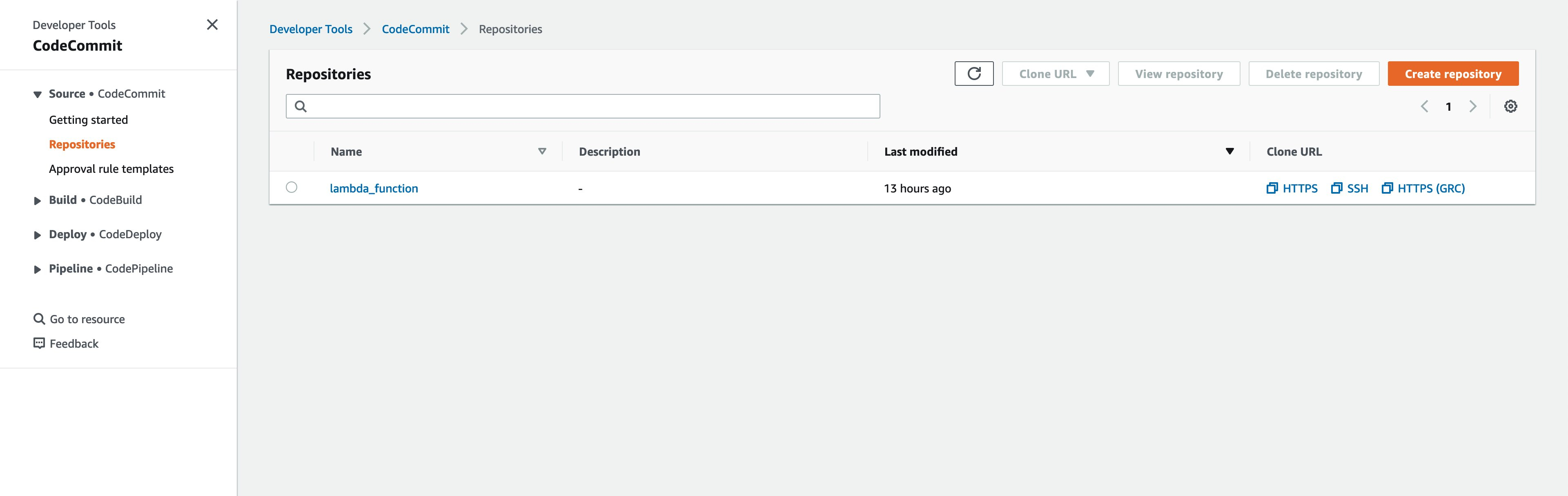
进入AWS控制台并搜索CodeCommit,进入CodeCommit服务页面应该能看到类似如下截图的结果。

接下来准备将代码推送到CodeCommit存储库中以触发流水线的执行。可根据此文档来设置连接CodeCommit的环境,这里采用的是HTTPS (GRC)的方式。推送代码的具体步骤如下:
- 在项目根目录执行以下命令初始化Git仓库并指定分支。
git init && git checkout -b main
- 指定远程仓库地址。此时可回到如上图所示的页面,点击HTTPS(GRC)即可完成地址的复制。
git remote add origin codecommit::cn-northwest-1://lambda_function
- 提交代码并推送远程仓库。
git add . && git commit -m "a new lambda function" && git push origin main
稍待片刻,进入AWS控制台并搜索CodePipeline,进入CodePipeline服务页面找到名字为CachePipeline的流水线并点击,应该能看到类似如下截图的效果。

到这里,我们的流水线已经完成了第一次执行。出于对比的目的,我们需要触发流水线进行第二次执行。我们选取项目根目录下的README.md文件并在末尾加上两个空行,保存并按照上述步骤推送到远程仓库。
结果比对
上述流水线的第一次执行,并没有利用到缓存,而是把需要缓存的东西都准备好了。比如SecurityCheck这一个阶段,在第一次执行成功之后,CodeBuild会把我们在BuildSpec文件里面指定的缓存目录上传到前面创建的S3存储桶中。这时我们进入AWS控制台并搜索S3服务,进入S3服务页面找到名字为cache-pipeline-cache-bucket的S3存储桶并点击,应该能看到类似如下截图的结果。

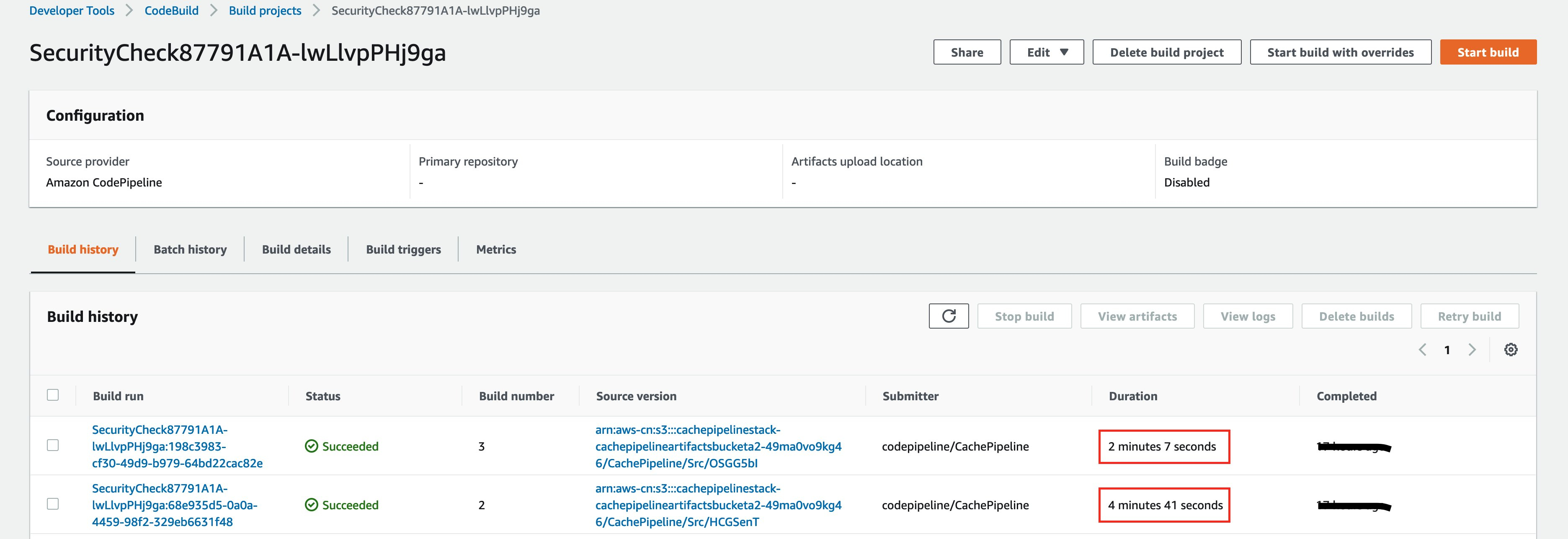
图中的文件即为经过CodeBuild处理后的缓存文件,在之后的执行中,只要相关的依赖库没有改动,那么CodeBuild就会直接读取缓存,而不会重新下载。第一次执行与第二次执行的时间对比如下图所示。

可以看到,在使用了缓存策略之后,执行时间减少了50%以上。同样的,对于镜像构建,第一次的是没有使用缓存的,因为我们还没有第一个镜像。但是从第二次开始,我们就可以利用上一次的镜像作为缓存了。时间对比如下图所示。

可以看到,在使用了Docker Layer的缓存之后,执行时间减少了50%以上。通过这两项的加速,整个流水线的执行时间得到大幅缩短。
总结
本文详细描述了如何利用CodeBuild的缓存策略以及Docker Layer的缓存策略加速流水线的执行。这两个方面的缓存策略对于绝大多数的持续集成和持续部署流水线都具备适用性,尤其是对于包含需要下载大量依赖库步骤的流水线,加速的效果更为显著。
本篇作者