AWS Germany – Amazon Web Services in Deutschland
AWS Clean Rooms führt die Generierung synthetischer Datensätze zur Verbesserung des Datenschutzes für das Training von ML-Modellen ein
Author: Micah Walter, Übersetzung: Philip Gutberlet
| Hiermit kündigen wir die Generierung von datenschutzoptimierten synthetischen Datensätzen für AWS Clean Rooms an. Diese neue Funktion können Unternehmen und ihre Partner nutzen, um aus ihren gemeinsamen Daten datenschutzoptimierte synthetische Datensätze zu generieren, mit denen sie Regressions- und Klassifizierungsmodelle für maschinelles Lernen (ML) trainieren können. Mit dieser Funktion können Sie synthetische Trainingsdatensätze generieren, die die statistischen Muster der Originaldaten beibehalten, ohne dass das Modell Zugriff auf die Originaldatensätze hat. Damit eröffnen sich neue Möglichkeiten für das Modelltraining, die aufgrund von Datenschutzbedenken bisher nicht möglich waren. |
Beim Erstellen von ML-Modellen stehen Datenwissenschaftler und Analysten in der Regel vor einem grundlegenden Konflikt zwischen Datennutzbarkeit und Datenschutz. Der Zugriff auf hochwertige, detaillierte Daten ist für das Training präziser Modelle unerlässlich, die Trends erkennen, Erfahrungen personalisieren und Geschäftsergebnisse vorantreiben können. Die Verwendung detaillierter Daten, wie z. B. Ereignisdaten auf Benutzerebene von mehreren Parteien, wirft jedoch erhebliche Datenschutzbedenken und Compliance-Herausforderungen auf. Unternehmen möchten Fragen wie „Welche Merkmale deuten auf eine hohe Wahrscheinlichkeit einer Kundenkonversion hin?“ beantworten, aber das Training auf der indiviudellen Ebene steht oft im Widerspruch zu Datenschutzrichtlinien und gesetzlichen Anforderungen.
Datenschutzoptimierte synthetische Datensatzgenerierung für benutzerdefiniertes ML
Um dieser Herausforderung zu begegnen, führen wir in AWS Clean Rooms ML die Generierung synthetischer Datensätze zur Verbesserung des Datenschutzes ein. Damit können Unternehmen synthetische Versionen sensibler Datensätze erstellen, die sicherer für das Training von ML-Modellen verwendet werden können. Diese Funktion nutzt fortschrittliche ML-Techniken, um neue Datensätze zu generieren, die die statistischen Eigenschaften der Originaldaten beibehalten und gleichzeitig die Probanden aus den Originalquelldaten anonymisieren.
Herkömmliche Anonymisierungstechniken wie Maskierung bergen nach wie vor das Risiko, dass Personen in einem Datensatz wieder identifiziert werden können – bereits wenige Informationen wie Postleitzahl und Geburtsdatum können ausreichen, um eine Person anhand von Volkszählungsdaten zu identifizieren. Die Erstellung synthetischer Datensätze zur Verbesserung des Datenschutzes begegnet diesem Risiko mit einem grundlegend anderen Ansatz. Das System trainiert ein Modell, das die wesentlichen statistischen Muster des ursprünglichen Datensatzes lernt, und generiert dann synthetische Datensätze, indem es Werte aus dem ursprünglichen Datensatz auswählt und das Modell zur Vorhersage der Spalte mit den vorhergesagten Werten verwendet. Anstatt die Originaldaten lediglich zu kopieren oder zu verfälschen, verwendet das System eine Technik zur Reduzierung der Modellkapazität, um das Risiko zu mindern, dass das Modell Informationen über Personen in den Trainingsdaten speichert. Der resultierende synthetische Datensatz hat das gleiche Schema und die gleichen statistischen Eigenschaften wie die Originaldaten und eignet sich daher für das Training von Klassifikations- und Regressionsmodellen. Dieser Ansatz reduziert das Risiko einer Re-Identifizierung quantifizierbar.
Organisationen, die diese Funktion nutzen, haben die Kontrolle über die Datenschutzparameter, einschließlich der Menge des angewendeten Rauschens und des Schutzniveaus gegen Mitgliedschafts-Inferenzangriffe, bei denen ein Angreifer versucht, festzustellen, ob die Daten einer bestimmten Person im Trainingssatz enthalten waren. Nach der Generierung des synthetischen Datensatzes liefert AWS Clean Rooms detaillierte Metriken, die Kunden und ihren Compliance-Teams helfen, die Qualität des synthetischen Datensatzes in zwei entscheidenden Dimensionen zu verstehen: die Übereinstimmung mit den Originaldaten und die Wahrung der Privatsphäre. Der Genauigkeitswert verwendet die KL-Divergenz, um zu messen, wie ähnlich die synthetischen Daten dem ursprünglichen Datensatz sind, und der Datenschutzwert quantifiziert, wie wahrscheinlich es ist, dass der Datensatz vor Angriffen durch Mitgliederinferenz geschützt ist.
Arbeiten mit synthetischen Daten in AWS Clean Rooms
Die ersten Schritte zur Erstellung datenschutzoptimierter synthetischer Datensätze folgen dem etablierten AWS Clean Rooms ML-Workflow für benutzerdefinierte Modelle, wobei neue Schritte zur Festlegung von Datenschutzanforderungen und zur Überprüfung von Qualitätsmetriken hinzukommen. Unternehmen erstellen zunächst konfigurierte Tabellen mit Analyseregeln unter Verwendung ihrer bevorzugten Datenquellen, schließen sich dann mit ihren Partnern zusammen oder gehen eine Kooperation mit ihnen ein und verknüpfen ihre Tabellen mit dieser Kooperation.
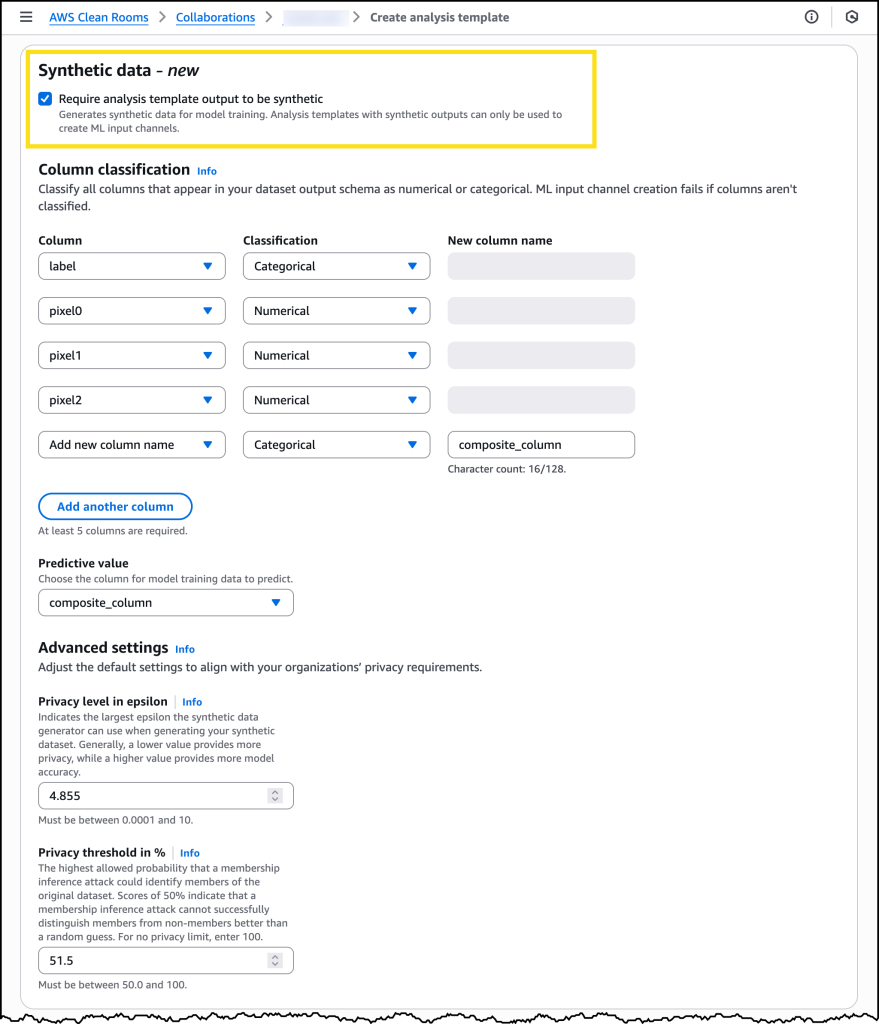
Die neue Funktion führt eine verbesserte Analysevorlage ein, in der Datenbesitzer nicht nur die SQL-Abfrage definieren, die den Datensatz erstellt, sondern auch festlegen, dass der resultierende Datensatz synthetisch sein muss. Innerhalb dieser Vorlage klassifizieren Unternehmen Spalten, um anzugeben, welche Spalte das ML-Modell vorhersagen wird und welche Spalten kategoriale gegenüber numerischen Werten enthalten. Entscheidend ist, dass die Vorlage auch Datenschutzschwellenwerte enthält, die die generierten synthetischen Daten erfüllen müssen, um für das Training verfügbar zu sein. Dazu gehören ein Epsilon-Wert, der angibt, wie viel Rauschen in den synthetischen Daten vorhanden sein muss, um vor einer erneuten Identifizierung zu schützen, und ein Mindestschutzwert gegen Mitgliedschafts-Inferenz-Angriffe. Um diese Schwellenwerte angemessen festzulegen, müssen Sie die spezifischen Datenschutz- und Compliance-Anforderungen Ihres Unternehmens kennen. Wir empfehlen Ihnen, während dieses Prozesses mit Ihren Rechts- und Compliance-Teams zusammenzuarbeiten.
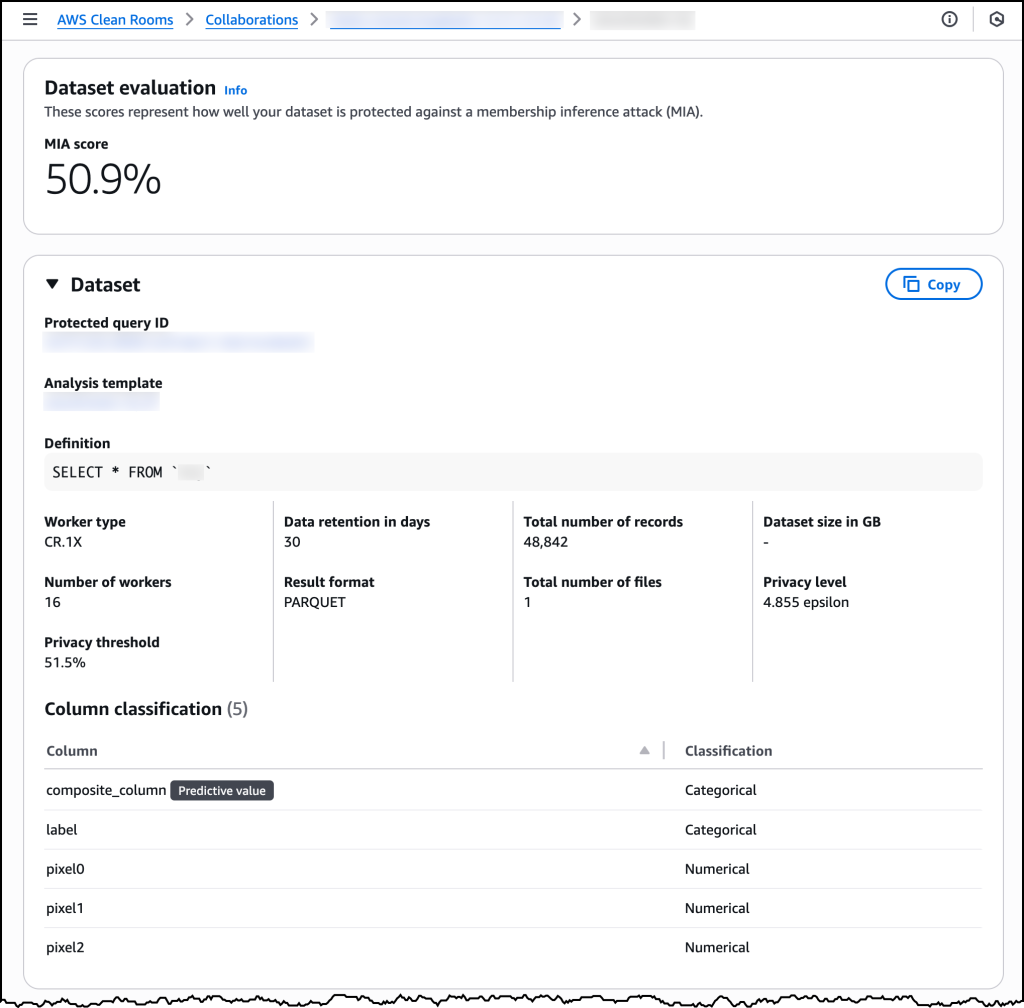
Nachdem alle Dateneigentümer die Analysevorlage überprüft und genehmigt haben, erstellt ein Mitglied der Kooperation einen Machine Learning Eingabekanal, der auf die Vorlage verweist. AWS Clean Rooms beginnt dann den Prozess der synthetischen Datensatzgenerierung, der abhängig von der Größe und Komplexität des Datensatzes typischerweise innerhalb weniger Stunden abgeschlossen ist. Wenn der generierte synthetische Datensatz die in der Analysevorlage definierten erforderlichen Datenschutzschwellenwerte erfüllt, wird ein synthetischer Machine Learning Eingabekanal zusammen mit detaillierten Qualitätsmetriken verfügbar. Datenwissenschaftler können den tatsächlich erreichten Schutzwert gegen einen simulierten Mitgliedschafts-Inferenzangriff überprüfen.
Sobald sie mit den Qualitätsmetriken zufrieden sind, können Organisationen mit dem Training ihrer ML-Modelle unter Verwendung des synthetischen Datensatzes innerhalb der AWS-Clean-Rooms-Kooperation fortfahren. Je nach Anwendungsfall können sie die trainierten Modellgewichte exportieren oder weitere Inferenzjobs innerhalb der Kooperation selbst ausführen.
Probieren wir es aus
Beim Erstellen einer neuen AWS-Clean-Rooms-Kooperation kann ich jetzt festlegen, wer für die synthetische Datensatzgenerierung bezahlt.
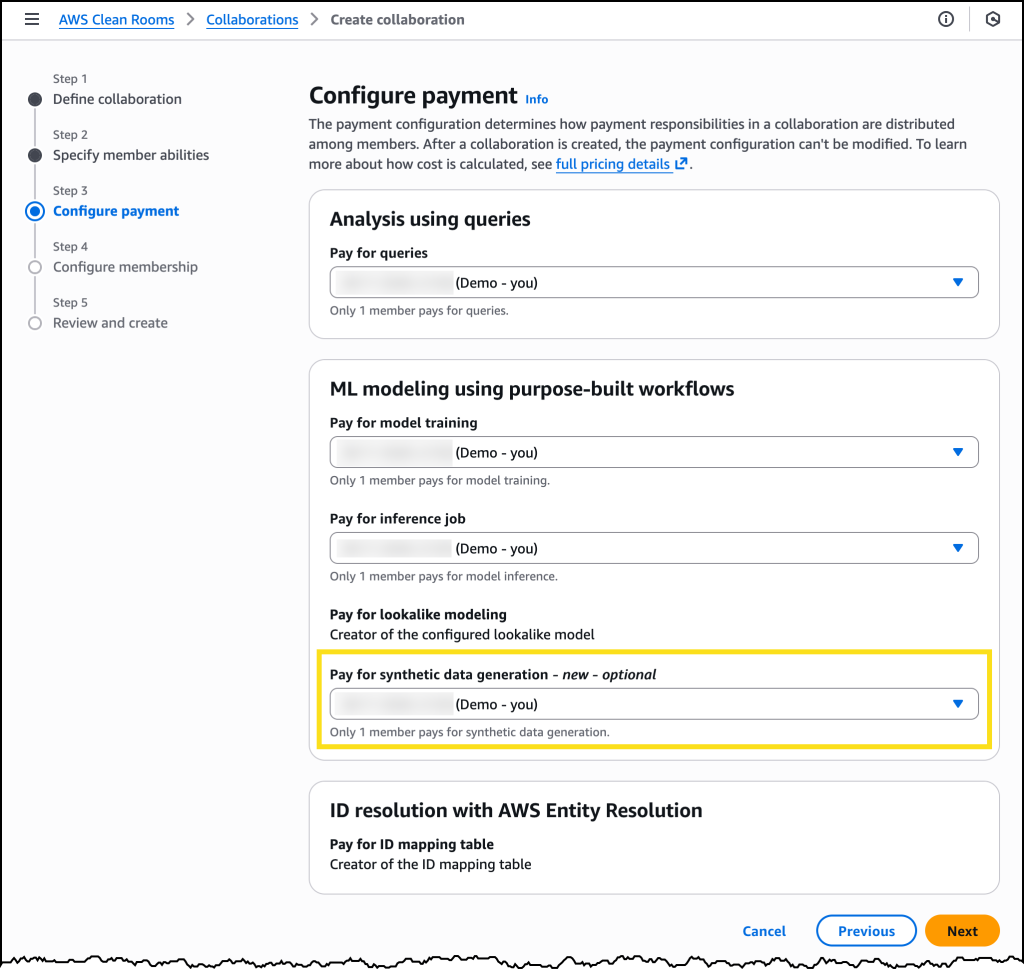
Nachdem meine Kooperation konfiguriert ist, kann ich Ausgabe des Analyse-Templates muss synthetisch sein auswählen, wenn ich eine neue Analysevorlage erstelle.
Nachdem meine synthetische Analysevorlage bereit ist, kann ich sie beim Ausführen geschützter Abfragen verwenden und alle relevanten ML-Eingabekanal-Details anzeigen.
Jetzt verfügbar
Sie können noch heute mit der Verwendung der datenschutzoptimierten synthetischen Datensatzgenerierung über AWS Clean Rooms beginnen. Die Funktion ist in allen kommerziellen AWS-Regionen verfügbar, in denen AWS Clean Rooms verfügbar ist. Erfahren Sie mehr darüber in der AWS-Clean-Rooms-Dokumentation.
Die datenschutzoptimierende synthetische Datensatzgenerierung wird separat auf Nutzungsbasis abgerechnet. Sie zahlen nur für die Rechenleistung, die zur Generierung Ihres synthetischen Datensatzes verwendet wird, abgerechnet als Synthetic Data Generation Units (SDGUs). Die Anzahl der SDGUs variiert je nach Größe und Komplexität Ihres ursprünglichen Datensatzes. Diese Gebühr kann als Zahlereinstellung konfiguriert werden, was bedeutet, dass jedes Mitglied der Kooperation zustimmen kann, die Kosten zu übernehmen. Weitere Informationen zur Preisgestaltung finden Sie auf der AWS Clean Rooms Preisseite.
Die erste Version unterstützt das Training von Klassifizierungs- und Regressionsmodellen auf tabellarischen Daten. Die synthetischen Datensätze funktionieren mit Standard-ML-Frameworks und können in bestehende Modellentwicklungs-Pipelines integriert werden, ohne dass Änderungen an Ihren Workflows erforderlich sind.
Diese Funktion stellt einen bedeutenden Fortschritt im datenschutzoptimierten maschinellen Lernen dar. Organisationen können den Wert sensibler Daten auf Benutzerebene für das Modelltraining erschließen und gleichzeitig das Risiko mindern, dass sensible Informationen über einzelne Benutzer durchsickern könnten. Ob Sie Werbekampagnen optimieren, Versicherungsangebote personalisieren oder Betrugserkennungssysteme verbessern – die datenschutzverbessernde synthetische Datensatzgenerierung ermöglicht es, genauere Modelle durch Datenkooperation zu trainieren und dabei die Privatsphäre des Einzelnen zu respektieren.

Micah Walter
Micah Walter ist ein Sr. Solutions Architect, der Unternehmenskunden in der Region New York City und darüber hinaus unterstützt. Er berät Führungskräfte, Ingenieure und Architekten bei jedem Schritt auf ihrem Weg in die Cloud, mit einem tiefen Fokus auf Nachhaltigkeit und praktisches Design. In seiner Freizeit genießt Micah die Natur, Fotografie und verbringt Zeit mit seinen Kindern.
Dieser Inhalt wurde aus dem ursprünglichen Blogbeitrag übersetzt, der hier zu finden ist.