Blog de Amazon Web Services (AWS)
Construye stacks serverless usando Kro, ACK y Amazon EKS
Por Jhon Guzmán, Senior Geo Specialist Solutions Architect en AWS.
Nivel: Avanzado
Audiencia objetivo: Ingenieros de Plataforma, Ingenieros DevOps, Arquitectos Cloud, SREs
TL;DR: Construimos un stack completo de aplicación serverless (DynamoDB + Lambda + API Gateway + CloudFront + Cognito) utilizando un único ResourceGraphDefinition (RGD) de Kubernetes con Composiciones Híbridas de Kro. Un solo RGD orquesta 15 recursos de AWS a través de controladores ACK y Crossplane. El patrón elimina la orquestación manual y proporciona gestión automática de dependencias — todo declarativo, compatible con GitOps y listo para producción.
Introducción
Gestionar infraestructura serverless a escala presenta desafíos únicos. Los enfoques tradicionales requieren que los desarrolladores manejen múltiples herramientas—Terraform para algunos recursos, CloudFormation para otros, y configuraciones manuales en la consola de AWS para el resto. Esta fragmentación genera despliegues inconsistentes, ciclos de desarrollo más largos y mayor sobrecarga operativa.
¿Por qué Kro para Serverless? Kro es un orquestador de recursos nativo de Kubernetes diseñado para simplificar despliegues complejos de múltiples recursos. Kro, se destaca en la coordinación de múltiples controladores de infraestructura (como ACK y Crossplane) dentro de un único ResourceGraphDefinition, gestionando automáticamente las dependencias y la propagación de estado entre recursos. Esto lo hace particularmente adecuado para arquitecturas serverless, que típicamente involucran numerosos recursos interdependientes a través de diferentes servicios de AWS.
En este blogpost, mostraremos cómo construir un stack completo de aplicación serverless—desde la base de datos hasta la API y el frontend—utilizando Composiciones Híbridas de Kro (HKC) un patrón de orquestación que combina AWS Controllers for Kubernetes (ACK), Crossplane y Kro dentro de un único ResourceGraphDefinition (RGD) de Kubernetes.
Con un solo RGD, obtiene un stack serverless listo para producción: tabla DynamoDB, función Lambda, API Gateway con autenticación JWT y flujos de trabajo de despliegue automatizados—15 recursos de AWS orquestados automáticamente. Lo guiaremos a través de la implementación real que aprovisiona este stack (10 recursos vía ACK, 2 vía Crossplane, 3 nativos de Kubernetes) con un único manifiesto de Kubernetes.
Repositorio de ejemplo: El código funcional completo de este blogpost está disponible en github.com/aws-samples/sample-kro-serverless-app-stack. Clónelo y siga el proceso paso a paso.
Lo que aprenderá
Este blogpost lo guía a través de la construcción de infraestructura serverless con Composiciones Híbridas de Kro, desde la comprensión del problema hasta la implementación de la solución completa.
Comenzamos con El Desafío, examinando los despliegues serverless y complejidades como la fragmentación de herramientas, configuraciones inconsistentes y la dispersión de autenticación. Exploramos tres escenarios del mundo real: plataformas SaaS multi-tenant, entornos de equipos de desarrollo y despliegues de feature branches.
Los Fundamentos presentan las tres tecnologías que hacen posibles las Composiciones Híbridas de Kro: las capacidades de orquestación de Kro, el mapeo directo de API de AWS de ACK y las fortalezas de composición de Crossplane. Aprenderá por qué funcionan mejor juntas que por separado.
La Visión General de la Solución presenta La arquitectura de tres capas que separa los recursos compartidos de plataforma de los recursos específicos de la aplicación. Verá cómo un único ResourceGraphDefinition orquesta 15 recursos de AWS y cómo la gestión automática de dependencias de Kro elimina los scripts de orquestación.
La Integración entre Controladores profundiza en cómo los datos fluyen sin problemas entre ACK, Crossplane y Kubernetes nativo. Comprenderá el grafo de dependencias unificado, los patrones de referencia entre controladores usando expresiones CEL, y verá ejemplos completos de integración.
Entendiendo Kro y EKS explora los conceptos fundamentales de Kro—ResourceGraphDefinitions, expresiones CEL y propagación de estado—además de las opciones de despliegue en EKS incluyendo EKS Auto Mode y EKS Capabilities.
La Inmersión en la Implementación lo guía a través de la implementación completa con código funcional: desplegando recursos compartidos de plataforma, creando el ResourceGraphDefinition con los 15 recursos, y desplegando instancias de aplicación.
Finalmente, «Lecciones Aprendidas» comparte ocho perspectivas prácticas del despliegue en producción: integración nativa de Kubernetes, estrategias de recursos compartidos, gestión de configuración con envsubst, nomenclatura dinámica con CEL, patrones entre controladores, referencias de campos de estado, enfoques de validación y estrategias de monitoreo.
Prerrequisitos
Para seguir este blogpost, debe considerar:
- Comprensión básica de Kubernetes y servicios de AWS
- Familiaridad con arquitecturas serverless (Lambda, API Gateway, DynamoDB)
- Conocimiento de conceptos de Infraestructura como Código
El Reto
Construir una aplicación serverless típicamente involucra aprovisionar y gestionar múltiples servicios de AWS a través de capas de backend y frontend.
Capa de Backend:
- Tablas DynamoDB para almacenamiento de datos
- Funciones Lambda para lógica de negocio
- API Gateway para endpoints HTTP
- Roles y políticas IAM para seguridad
- Autenticación y autorización para acceso a la API
Capa de Frontend:
- Buckets S3 para hosting estático
- Distribuciones CloudFront para CDN
- Registros Route 53 para DNS
- Certificados ACM para HTTPS
Problemas del enfoque:
- Fragmentación de herramientas: Diferentes herramientas para diferentes recursos (Terraform, CloudFormation, AWS CLI)
- Configuraciones inconsistentes: Los pasos manuales generan drift y errores
- Dependencias: Gestionar dependencias de recursos entre herramientas es propenso a errores
- Complejidad de autenticación: Cada aplicación necesita su propio cliente Cognito y configuración
Complejidad operativa:
Para equipos que ya operan en Kubernetes, gestionar infraestructura a través de múltiples herramientas externas agrega una carga operativa significativa. Los ingenieros deben aprender y mantener experiencia en Terraform HCL, CloudFormation YAML, comandos de AWS CLI y manifiestos de Kubernetes—cada uno con diferente sintaxis, reglas de validación y patrones de despliegue.
Los despliegues de aplicaciones usan kubectl apply, pero la infraestructura requiere terraform apply, aws cloudformation deploy u operaciones manuales en la consola—rompiendo el flujo de trabajo unificado de GitOps. Este cambio de contexto entre el pensamiento nativo de Kubernetes (declarativo, basado en controladores) y la gestión imperativa de infraestructura (ciclos de plan/apply, archivos de estado) aumenta la carga cognitiva y reduce la velocidad de desarrollo.
La observabilidad se fragmenta: logs de aplicación en CloudWatch Logs, estado de infraestructura en archivos de estado de Terraform, historial de despliegue en Git—sin una única fuente de verdad. Ejecutar tanto clústeres de Kubernetes como herramientas separadas de automatización de infraestructura aumenta la sobrecarga de mantenimiento, la superficie de seguridad y la complejidad operativa. Gestionar clientes individuales de Cognito, URLs de callback y secretos para cada instancia de aplicación agrega otra capa de dispersión de autenticación.
El enfoque nativo de Kubernetes:
La solución aborda estos desafíos al traer la gestión de infraestructura dentro de Kubernetes mismo. Todo se gestiona a través de kubectl apply—los mismos comandos, los mismos flujos de trabajo, los mismos patrones de GitOps tanto para aplicaciones como para infraestructura. El servidor de API de Kubernetes se convierte en la única fuente de verdad tanto para el estado de la aplicación como para el estado de la infraestructura.
Los desarrolladores usan conceptos familiares de Kubernetes (CRDs, controladores, condiciones de estado) para infraestructura, eliminando la necesidad de aprender herramientas separadas de IaC. Todas las operaciones de infraestructura son visibles a través de kubectl get, kubectl describe y eventos de Kubernetes—integradas con el monitoreo y alertas existentes. Sin archivos de estado separados, sin ciclos de plan/apply, sin herramientas externas de automatización—solo controladores de Kubernetes gestionando recursos de forma declarativa. La autenticación centralizada con recursos compartidos de Cognito y una única URL de callback con parámetro de estado elimina la gestión de clientes por aplicación.
Este enfoque nativo de Kubernetes es particularmente valioso para equipos de ingeniería de plataforma que construyen Plataformas Internas de Desarrollo (IDPs), donde la consistencia, el autoservicio y la simplicidad operativa son críticos para escalar a través de múltiples equipos de desarrollo.
Impacto en el mundo real
En la plataforma, inicialmente desplegamos aplicaciones serverless usando enfoques tradicionales. Esto representa tres casos de uso comunes que impulsan la proliferación de aplicaciones serverless:
Caso de uso 1: Plataforma SaaS Multi-Tenant
- Escenario: Producto SaaS sirviendo a n tenants, cada uno requiriendo infraestructura aislada
- Patrón: Un stack serverless completo por tenant (tabla DynamoDB, funciones Lambda, API Gateway, CloudFront)
- Por qué stacks separados: Aislamiento de datos, requisitos de cumplimiento, personalización específica por tenant
- Ejemplo:
tenant-a-app-prod,tenant-b-app-prod,tenant-c-app-prod
Caso de uso 2: Entornos de equipos de desarrollo
- Escenario: n desarrolladores × 2 entornos inferiores (dev, staging) = nx2 instancias de aplicación
- Patrón: Cada desarrollador obtiene un entorno personal de dev, más staging/prod compartidos
- Por qué múltiples instancias: Desarrollo paralelo, pruebas de funcionalidades, aislamiento de producción
- Ejemplo:
developer1-app-dev,developer2-app-dev,team-app-staging,team-app-prod
Caso de uso 3: Despliegues de Feature Branch
- Escenario: Desarrollo activo con n feature branches concurrentes que requieren entornos de vista previa
- Patrón: Stack serverless efímero por feature branch para pruebas y revisión
- Por qué stacks temporales: Vistas previas de PR, pruebas de integración, demos para stakeholders
- Ejemplo:
feature-auth-app-dev,feature-payments-app-dev,bugfix-123-app-dev
Estado inicial (enfoque tradicional):
- Cantidad de recursos: n roles IAM, n buckets S3, n distribuciones CloudFront, n clientes Cognito
- Sobrecarga operativa: Alta (gestionando n+ recursos individualmente)
- Consistencia: Baja (pasos manuales, múltiples herramientas, drift de configuración)
Estos casos de uso muestran por qué la cantidad de aplicaciones serverless crece rápidamente en plataformas del mundo real, haciendo que la eficiencia de despliegue y la simplicidad operativa sean preocupaciones críticas.
Fundamentos: Los bloques de construcción
Antes de sumergirnos en la implementación, presentemos brevemente las tres tecnologías que hacen posibles las Composiciones Híbridas de Kro. Si ya está familiarizado con Kro, ACK y Crossplane, puede saltar directamente a la sección Visión General de la Solución.
Kro: Orquestador de Recursos de Kubernetes
Kro es un orquestador nativo de Kubernetes que coordina múltiples controladores de infraestructura dentro de un único ResourceGraphDefinition (RGD). Piense en él como un director de orquesta para su infraestructura—usted define qué recursos necesita y cómo se relacionan entre sí, y Kro determina automáticamente el orden correcto de aprovisionamiento, gestiona las dependencias y propaga la información de estado entre recursos.
Lo que hace a Kro particularmente poderoso es su capacidad de orquestar recursos heterogéneos: controladores ACK, composiciones de Crossplane y recursos nativos de Kubernetes trabajan juntos en un único grafo de dependencias. AWS ha respaldado este patrón en este otro blogpost «Simplifica la gestión de clusters Kubernetes usando ACK, kro y Amazon EKS«, demostrando cómo Kro puede gestionar stacks completos de infraestructura de forma declarativa.
ACK: AWS Controllers for Kubernetes
AWS Controllers for Kubernetes (ACK) proporciona recursos personalizados de Kubernetes que se mapean directamente a servicios de AWS. Cuando crea un recurso de tabla DynamoDB de ACK en Kubernetes, ACK aprovisiona una tabla DynamoDB real en AWS. ACK está diseñado para el mapeo directo de API de AWS—destaca en el aprovisionamiento de servicios nativos de AWS de forma rápida y simple, con excelente exposición de campos de estado que facilita referenciar propiedades de recursos en otras configuraciones. Los controladores ACK están diseñados para servicios de AWS (DynamoDB, API Gateway, Lambda, etc.), proporcionando aprovisionamiento rápido y configuración directa.
Crossplane: Composición Universal de Infraestructura
Crossplane es un proyecto CNCF que extiende Kubernetes con capacidades de aprovisionamiento de infraestructura. Mientras ACK se enfoca en el mapeo directo de API de AWS, Crossplane enfatiza la composición y abstracción—puede combinar múltiples recursos de nube en abstracciones de nivel superior, gestionar integraciones de IAM y crear patrones de infraestructura reutilizables. La fortaleza de Crossplane radica en escenarios que requieren composición de recursos, dependencias entre recursos y gestión avanzada de configuración. Por ejemplo, desplegar una función Lambda con Crossplane le permite referenciar roles IAM, gestionar permisos y manejar despliegue de código basado en S3.
Por qué funcionan bien juntos: Composiciones Híbridas de Kro
Estos no son enfoques competidores son filosofías de diseño complementarias que, cuando son orquestadas por Kro, crean un patrón de gestión de infraestructura. ACK proporciona aprovisionamiento rápido y directo para servicios nativos de AWS. Crossplane proporciona composición rica para escenarios complejos. Kro coordina ambos dentro de un único grafo de dependencias, gestionando automáticamente el flujo de datos entre ellos.
En el stack serverless, esto significa: ACK aprovisiona tablas DynamoDB y configuraciones de API Gateway (rápido, simple), Crossplane maneja funciones Lambda con integración IAM, y Kro orquesta todo el flujo asegurando que la tabla DynamoDB exista antes de crear la función Lambda, que la función Lambda esté lista antes de configurar API Gateway, y que la información de estado fluya sin problemas entre recursos de ACK y Crossplane.
Para equipos interesados en detalles técnicos más profundos, exploraremos los patrones de orquestación entre controladores en la sección Integración entre Controladores más adelante en este blogpost.
Visión General de la Solución: Un RGD, Stack Serverless Completo
El concepto central:
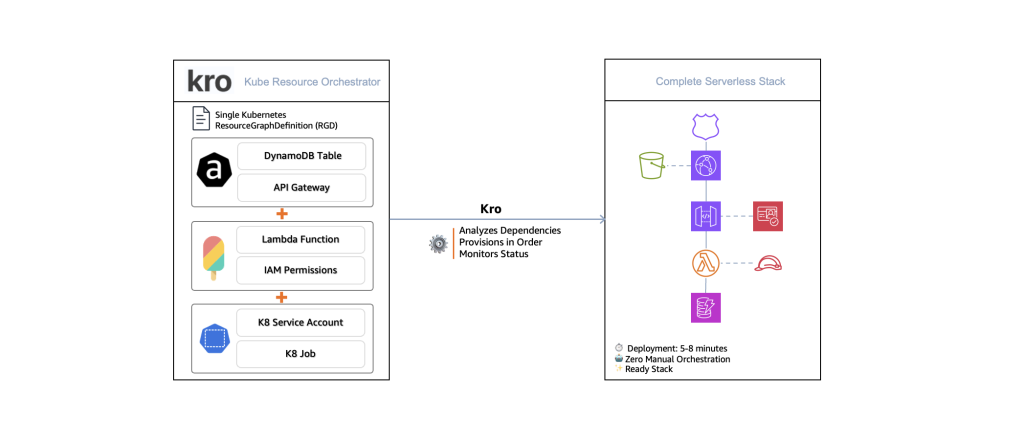
Figura 1. El concepto central de las Composiciones Híbridas de Kro. Un único ResourceGraphDefinition de Kubernetes orquesta 15 recursos de AWS en un stack completo de aplicación serverless.
La solución: Composiciones Híbridas de Kro
Composiciones Híbridas de Kro (HKC) es un patrón de orquestación que le permite definir un stack completo de aplicación serverless en un único ResourceGraphDefinition de Kubernetes. En lugar de gestionar docenas de recursos a través de múltiples herramientas, crea un solo RGD que aprovisiona todo: base de datos, cómputo, capa de API, DNS y autenticación—todo orquestado automáticamente por Kro.
Qué significa «Stack Completo»:
Un único RGD aprovisiona toda su aplicación serverless:
- Capa de datos: Tabla DynamoDB con cifrado y facturación bajo demanda
- Capa de cómputo: Función Lambda con código desde S3, roles IAM e integración con Cognito
- Capa de API: API Gateway con autorizador JWT, 5 rutas (GET, POST, PUT, DELETE, OPTIONS) e integración con Lambda
- Capa de seguridad: Integración con Cognito User Pool para validación JWT
- Capa de automatización: Job de Kubernetes para sincronización de assets de UI, ConfigMap para información de despliegue
Este enfoque proporciona:
- Orquestación unificada: Un único manifiesto YAML para todos los recursos
- La mejor herramienta para cada trabajo: ACK para servicios nativos de AWS, Crossplane para composiciones complejas
- Dependencias declarativas: Kro gestiona el orden de recursos y la propagación de estado
- Listo para GitOps: Infraestructura versionada con integración de ArgoCD
- Autenticación integrada: Recursos compartidos de Cognito con validación JWT automática
Componentes clave
La solución está construida sobre una arquitectura de tres capas que separa la infraestructura a nivel de plataforma de los recursos específicos de la aplicación, con Kro orquestando todo el stack a través de un único ResourceGraphDefinition.
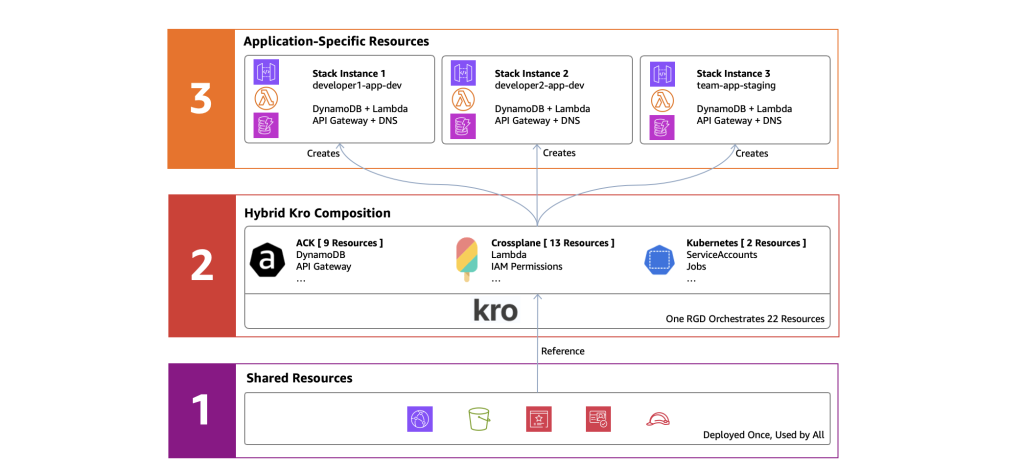
Figura 2. La arquitectura de tres capas de las Composiciones Híbridas de Kro. La Capa 1- proporciona recursos compartidos de plataforma (desplegados una vez), la Capa 2- orquesta la creación de recursos vía Kro, y la Capa 3- contiene recursos específicos de la aplicación (desplegados por instancia).
Capa 1: Recursos compartidos de plataforma
La base de este enfoque es un conjunto de recursos compartidos de plataforma desplegados una vez y reutilizados en todas las aplicaciones. Esta decisión arquitectónica elimina los pasos de aprovisionamiento más lentos, distribuciones CloudFront que toman 20 minutos en desplegarse, roles IAM que requieren 2-3 minutos cada uno, buckets S3 que necesitan nomenclatura cuidadosa y gestión de políticas, y recursos de Cognito que de otro modo requerirían creación y configuración de clientes por aplicación.
Lo que se comparte entre todas las aplicaciones:
- Una única distribución CloudFront con un solo dominio usando CloudFront Functions para enrutamiento basado en rutas (ej.,
domain.com/app-prefix/) - Bucket de assets de plataforma almacenando código Lambda y plantillas de UI
- Bucket compartido de UI alojando todos los frontends de aplicaciones con aislamiento basado en prefijos
- Dos roles IAM compartidos para ejecución de Lambda y operaciones S3
- Cognito User Pool para autenticación centralizada en todas las aplicaciones
- Cliente compartido de Cognito App con una única URL de callback y parámetro de estado soportando todas las instancias de aplicación
- Arquitectura centralizada de callback usando parámetro de estado para login y cookies para logout
Impacto: Se elimina el tiempo de aprovisionamiento de CloudFront, la creación de roles IAM, la gestión de clientes Cognito por aplicación, y se asegura consistencia en todas las aplicaciones con configuración de infraestructura probada en batalla. La arquitectura compartida de Cognito soporta las instancias de desarrolladores con un único App Client, eliminando la necesidad de crear y gestionar clientes individuales para cada aplicación.
Capa 2: La Composición Híbrida de Kro (ResourceGraphDefinition)
La segunda capa es donde las Composiciones Híbridas de Kro realmente brillan. Un único ResourceGraphDefinition (RGD) define un Custom Resource Definition (CRD) y orquesta 15 recursos a través de tres controladores diferentes (10 recursos gestionados por ACK, 2 por Crossplane y 3 recursos nativos de Kubernetes) todos coordinados a través de la resolución automática de dependencias de Kro.
Cómo funciona Kro con los RGDs:
- Los ingenieros de plataforma definen un ResourceGraphDefinition que especifica el stack completo
- Kro valida el RGD y crea dinámicamente un CRD
- Kro despliega un microcontrolador dedicado para gestionar instancias de ese CRD
- Los desarrolladores crean instancias del CRD con sus parámetros
- El microcontrolador aprovisiona los 15 recursos para cada instancia
Distribución de recursos por controlador:
- ACK (10 recursos): Tabla DynamoDB, API Gateway (API, autorizador JWT, integración, 5 rutas, stage)—elegido por su mapeo directo de API de AWS y aprovisionamiento rápido
- Crossplane (2 recursos): Función Lambda, permiso Lambda—elegido por sus capacidades de composición e integración IAM
- Kubernetes (3 recursos): ConfigMap, ServiceAccount y Job para automatización post-aprovisionamiento
Kro orquesta los 15 recursos analizando expresiones Common Expression Language (CEL) como ${lambdaFunction.status.atProvider.arn} para construir un grafo de dependencias, asegurando que DynamoDB exista antes de Lambda, Lambda esté listo antes de API Gateway, API Gateway esté operativo antes de los permisos de Lambda, y el autorizador JWT esté configurado antes de que se creen las rutas. Esta resolución automática de dependencias eliminó scripts de orquestación en bash, reemplazando la coordinación manual con definiciones declarativas de recursos. El resultado: los desarrolladores crean una única instancia del CRD, y todo el stack se vuelve operativo en 5-8 minutos con cero errores de orquestación y autenticación completamente integrada.
Capa 3: Recursos específicos de la aplicación
La tercera capa consiste en recursos creados para cada instancia de aplicación. Cuando un desarrollador despliega una nueva aplicación, Kro aprovisiona automáticamente un stack serverless completo con verdadero aislamiento—cada instancia obtiene su propia tabla DynamoDB (facturación PAY_PER_REQUEST, cifrado en reposo), función Lambda (Python 3.12, código desde bucket de plataforma, validación de grupos de Cognito), API Gateway (autorizador JWT con Cognito User Pool, CORS habilitado, cinco rutas), y un Job de Kubernetes para sincronización de assets de UI.
Lo que hace esto poderoso: Un ConfigMap captura la información de despliegue como «documentación viva»—endpoint de API, nombre de tabla, nombre de función, URL de UI, URL de CloudFront, configuración de Cognito e instrucciones de despliegue. Los desarrolladores entienden la infraestructura de su aplicación sin consultar AWS directamente. La arquitectura de tres capas equilibra la reutilización con la flexibilidad: los recursos compartidos de plataforma eliminan el aprovisionamiento redundante, la Composición Híbrida de Kro proporciona patrones de despliegue estandarizados con autenticación integrada, y los recursos específicos de la aplicación dan a cada instancia el aislamiento que necesita.
Flujo de arquitectura
El siguiente diagrama ilustra cómo estos componentes trabajan juntos para desplegar un stack completo de aplicación serverless:
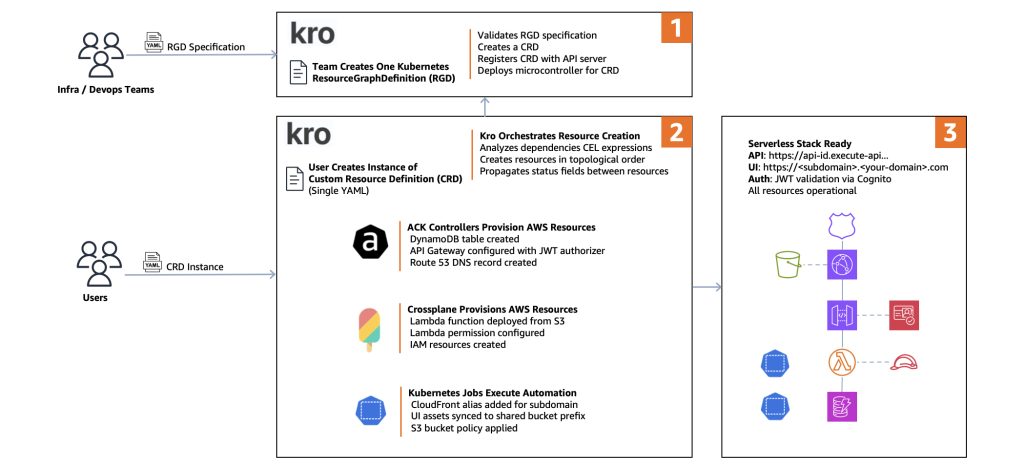
Figura 3. Vista expandida del flujo de arquitectura. 1- El equipo crea un (RGD), 2- El usuario crea una instancia del Custom Resource Definition (CRD), y 3- Stack Serverless listo.
Orquestación automática de dependencias
El avance en la implementación viene de la detección implícita de dependencias de Kro (una funcionalidad que transformó el proceso de despliegue de mantener scripts de orquestación a un único manifiesto declarativo). Cuando referenciamos ${lambdaFunction.status.atProvider.arn} en la integración de API Gateway, Kro automáticamente entiende la relación de dependencia, espera a que la función Lambda alcance el estado «Ready», y aprovisiona los recursos en el orden óptimo.
Lo que hace esto particularmente poderoso: Kro orquesta recursos de fuentes heterogéneas—recursos nativos de Kubernetes (Jobs, ServiceAccounts), controladores ACK (DynamoDB, API Gateway, Route 53) y composiciones de Crossplane (Lambda, permisos IAM)—todo dentro de un único grafo de dependencias. Esta orquestación entre controladores elimina la necesidad de capas de coordinación separadas o código de integración personalizado entre diferentes herramientas de infraestructura.
Esta capacidad tiene un impacto operativo profundo. El enfoque anterior requería declaraciones explícitas de dependencias, coordinación manual entre pasos de aprovisionamiento y secuenciación cuidadosa de comandos de despliegue. Un solo error en la cadena de dependencias podía dejar recursos en un estado inconsistente, requiriendo limpieza manual. Con Kro, eliminamos toda esa complejidad: el stack de 22 recursos se despliega en la secuencia correcta cada vez, con cero errores de orquestación.
El mecanismo técnico es elegante: Kro analiza expresiones CEL para construir un grafo de dependencias, realiza ordenamiento topológico y aprovisiona recursos secuencialmente mientras monitorea condiciones de estado. Pero lo que importa para los equipos de plataforma es el resultado—despliegues más rápidos, cero mantenimiento de orquestación, y un proceso de despliegue tan confiable que los equipos pueden autogestionar infraestructura sin intervención del equipo de plataforma. Para equipos interesados en los detalles de implementación, la documentación oficial de Kro proporciona una explicación completa del algoritmo de resolución de dependencias.
Ejemplo del stack: Tabla DynamoDB (ACK) → Función Lambda (Crossplane) → API Gateway (ACK) → Rutas de API con autorizador JWT (ACK) → Permiso Lambda (Crossplane). Cinco recursos de tres controladores diferentes, cero coordinación manual requerida.
# Ejemplo: Kro orquesta entre ACK, Crossplane y Kubernetes nativo
- id: dynamodbTable # ACK Controller
template:
apiVersion: dynamodb.services.k8s.aws/v1alpha1
kind: Table
spec:
tableName: "my-app-table"
- id: lambdaFunction # Crossplane
template:
apiVersion: lambda.aws.upbound.io/v1beta2
kind: Function
spec:
environment:
variables:
# Kro espera a que la tabla ACK esté lista
TABLE_NAME: "${dynamodbTable.spec.tableName}"
# Configuración de Cognito para validación de grupos
COGNITO_USER_POOL_ID: "${COGNITO_USER_POOL_ID}"
- id: apiIntegration # ACK Controller
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: Integration
spec:
# Kro espera a que la Lambda de Crossplane esté lista
integrationURI: "${lambdaFunction.status.atProvider.arn}"
- id: apiAuthorizer # ACK Controller - validación JWT
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: Authorizer
spec:
# Referencia al Cognito User Pool para validación JWT
jwtConfiguration:
issuer: "${COGNITO_ISSUER_URL}"
audience: ["${COGNITO_CLIENT_ID}"]
- id: syncUIJob # Kubernetes nativo
template:
apiVersion: batch/v1
kind: Job
spec:
template:
spec:
containers:
- name: sync
env:
- name: API_ENDPOINT
# Kro espera a que el API Gateway de ACK esté listo
value: "${apiIntegration.status.apiID}"
Integración entre Controladores: El corazón de las Composiciones Híbridas de Kro
La característica definitoria de las Composiciones Híbridas de Kro es la integración fluida entre ACK y Crossplane dentro de un único ResourceGraphDefinition. Esta orquestación entre controladores permite a Kro construir un grafo de dependencias unificado que abarca controladores de infraestructura heterogéneos, gestionando automáticamente el orden de recursos y la propagación de estado a través de los límites de los controladores.
Entendiendo la orquestación entre controladores
Cuando despliega una aplicación serverless con HKC, Kro orquesta recursos de tres fuentes diferentes dentro de un único grafo de dependencias: los controladores ACK gestionan servicios nativos de AWS como DynamoDB y API Gateway, Crossplane maneja composiciones de funciones Lambda con integración IAM, y los recursos nativos de Kubernetes ejecutan tareas de automatización. El poder de este enfoque radica en cómo estos recursos se referencian entre sí a través de los límites de los controladores.
Considere el stack serverless: la tabla DynamoDB (gestionada por ACK) proporciona su nombre de tabla a la función Lambda (gestionada por Crossplane) a través de una expresión CEL ${dynamodbTable.spec.tableName}. La función Lambda, una vez aprovisionada, expone su ARN a través de ${lambdaFunction.status.atProvider.arn}, que la integración de API Gateway (de vuelta a ACK) usa para configurar el proxy Lambda. El API Gateway luego proporciona su ID a través de ${apiIntegration.status.apiID}, que fluye al permiso Lambda (Crossplane nuevamente) para autorizar invocaciones. El autorizador de API Gateway (ACK) referencia el Cognito User Pool compartido para validación JWT, completando la integración de seguridad. Finalmente, un Job de Kubernetes referencia tanto recursos de ACK como de Crossplane para completar la automatización del despliegue.
Este flujo bidireccional—ACK a Crossplane, Crossplane a ACK, ambos a Kubernetes nativo, con recursos compartidos de plataforma (Cognito) integrados a lo largo—crea un grafo de dependencias heterogéneo que Kro resuelve automáticamente. Cada controlador opera independientemente, gestionando sus propios recursos según su diseño, pero Kro los coordina como si fueran un único sistema.
El grafo de dependencias unificado
El siguiente diagrama ilustra cómo Kro orquesta recursos a través de tres controladores diferentes en el stack serverless:
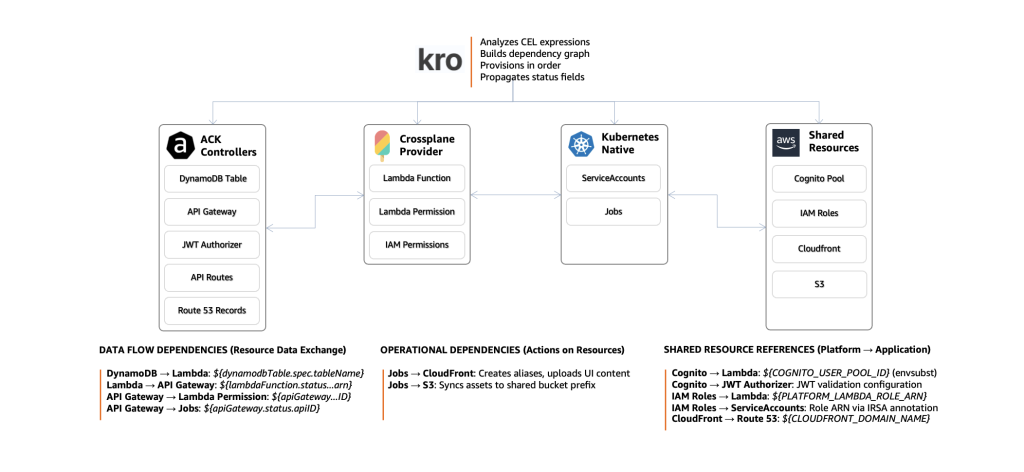
Figura 4. Kro orquesta recursos a través de tres controladores diferentes (ACK, Crossplane, Kubernetes nativo) más recursos compartidos de plataforma. Las flechas de dependencia muestran cómo fluyen los datos entre controladores, con Kro resolviendo automáticamente el orden correcto de aprovisionamiento.
Observaciones clave:
- Fuentes heterogéneas: Los recursos provienen de tres controladores diferentes (ACK, Crossplane, Kubernetes) más recursos compartidos de plataforma (Cognito), pero Kro los trata como un sistema unificado
- Flujo bidireccional: Los datos fluyen de ACK → Crossplane → ACK → Crossplane → Kubernetes, con Cognito integrado a lo largo
- Propagación de estado: Cada recurso expone campos de estado que los recursos dependientes consumen a través de expresiones CEL
- Ordenamiento automático: Kro analiza las expresiones CEL para determinar que DynamoDB debe crearse antes que Lambda, Lambda antes que API Gateway, API Gateway antes que el autorizador, y así sucesivamente
- Integración de seguridad: Cognito User Pool (recurso compartido) proporciona validación JWT para el autorizador de API Gateway y validación de grupos para funciones Lambda
Cómo funcionan las referencias entre controladores
El mecanismo que habilita esta integración es el análisis de expresiones CEL de Kro. Cuando escribe ${lambdaFunction.status.atProvider.arn} en un recurso de API Gateway de ACK, Kro entiende tres cosas: primero, este recurso depende de lambdaFunction; segundo, necesita esperar a que el campo de estado de la función Lambda esté poblado; tercero, debe resolver esta expresión antes de crear la integración de API Gateway.
Esto crea un grafo de dependencias implícito sin requerir declaraciones explícitas de ordenamiento. Simplemente expresa lo que cada recurso necesita, y Kro determina la secuencia. La función Lambda necesita el nombre de la tabla DynamoDB y el ID del Cognito User Pool, así que Kro asegura que estén disponibles primero. El API Gateway necesita el ARN de Lambda, así que Kro espera a que Crossplane aprovisione la función Lambda.
Lo que hace esto particularmente poderoso es la seguridad de tipos: Kro valida estas referencias entre controladores en el momento del apply, antes de que se cree cualquier recurso de AWS. Si referencia ${lambdaFunction.status.wrongField}, Kro reporta inmediatamente un error: «undefined field ‘wrongField'». Esto captura errores de configuración tempranamente, previniendo despliegues parciales y estado inconsistente.
Patrones de integración entre controladores
A través del uso, hemos identificado tres patrones que funcionan particularmente bien:
Patrón 1: ACK para el plano de datos, Crossplane para el plano de control
ACK destaca en el aprovisionamiento de recursos del plano de datos de AWS—tablas DynamoDB, API Gateways, buckets S3—debido a su mapeo directo de API de AWS. Crossplane destaca en recursos del plano de control que requieren integración de IAM. Al usar ACK para recursos de datos y Crossplane para recursos de control, obtiene aprovisionamiento rápido donde importa y composición rica donde la necesita.
# ACK crea el recurso de datos (rápido, simple)
- id: dynamodbTable
template:
apiVersion: dynamodb.services.k8s.aws/v1alpha1
kind: Table
# Crossplane crea el recurso de control (composición con IAM)
- id: lambdaFunction
template:
apiVersion: lambda.aws.upbound.io/v1beta2
kind: Function
Patrón 2: Encadenamiento de campos de estado
Los recursos pueden encadenar campos de estado entre controladores, creando grafos de dependencias complejos que Kro resuelve automáticamente:
# ACK DynamoDB → Crossplane Lambda
- id: lambdaFunction
spec:
environment:
variables:
TABLE_NAME: "${dynamodbTable.spec.tableName}"
# Crossplane Lambda → ACK API Gateway
- id: apiIntegration
spec:
integrationURI: "${lambdaFunction.status.atProvider.arn}"
# ACK API Gateway → Crossplane Lambda Permission
- id: lambdaPermission
spec:
sourceArn: "arn:aws:execute-api:${region}:${account}:${apiGateway.status.apiID}/*/*/*"
Patrón 3: Recursos compartidos de plataforma
Tanto los recursos de ACK como los de Crossplane pueden referenciar los mismos recursos compartidos de plataforma (como roles IAM, distribuciones CloudFront o Cognito User Pools), habilitando configuración consistente en todos los recursos independientemente de qué controlador los gestione.
# Tanto ACK como Crossplane referencian los mismos recursos compartidos
- id: lambdaFunction # Crossplane
spec:
forProvider:
role: "${PLATFORM_LAMBDA_ROLE_ARN}"
environment:
variables:
COGNITO_USER_POOL_ID: "${COGNITO_USER_POOL_ID}"
- id: apiAuthorizer # ACK
spec:
jwtConfiguration:
issuer: "${COGNITO_ISSUER_URL}"
audience: ["${COGNITO_CLIENT_ID}"]
Impacto operativo
La capacidad de integración entre controladores ha transformado el proceso de despliegue. Eliminamos scripts de orquestación que previamente coordinaban entre diferentes herramientas, redujimos el tiempo de despliegue a través de la resolución automática de dependencias, y recortamos el tiempo de resolución de problemas con eventos unificados de Kubernetes. Más importante aún, redujimos la incorporación de herramientas—en lugar de aprender múltiples herramientas de infraestructura, los desarrolladores trabajan con un único recurso personalizado de Kubernetes.
Para equipos de ingeniería de plataforma, esto resuelve un desafío fundamental: proporcionar infraestructura de autoservicio sin forzar a los desarrolladores a convertirse en expertos en múltiples herramientas. La integración entre controladores es invisible para los desarrolladores—crean un simple manifiesto YAML, y Kro orquesta todo detrás de escena, coordinando ACK, Crossplane, recursos nativos de Kubernetes y recursos compartidos de plataforma como un sistema unificado.
Ejemplo: Cadena completa de referencias entre controladores
Aquí hay un ejemplo completo que muestra cómo los recursos se referencian entre sí a través de controladores, incluyendo integración de autenticación:
# ACK crea la tabla DynamoDB
- id: dynamodbTable
template:
apiVersion: dynamodb.services.k8s.aws/v1alpha1
kind: Table
# Crossplane Lambda referencia la tabla ACK y Cognito compartido
- id: lambdaFunction
template:
apiVersion: lambda.aws.upbound.io/v1beta2
kind: Function
spec:
environment:
variables:
# Referencia entre controladores: Crossplane → ACK
TABLE_NAME: "${dynamodbTable.spec.tableName}"
# Referencia a recurso compartido: Crossplane → Cognito
COGNITO_USER_POOL_ID: "${COGNITO_USER_POOL_ID}"
# ACK API Gateway referencia Crossplane Lambda
- id: apiIntegration
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: Integration
spec:
# Referencia entre controladores: ACK → Crossplane
integrationURI: "${lambdaFunction.status.atProvider.arn}"
# ACK Authorizer referencia Cognito compartido
- id: apiAuthorizer
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: Authorizer
spec:
# Referencia a recurso compartido: ACK → Cognito
jwtConfiguration:
issuer: "${COGNITO_ISSUER_URL}"
audience: ["${COGNITO_CLIENT_ID}"]
# Crossplane Lambda Permission referencia ACK API Gateway
- id: lambdaPermission
template:
apiVersion: lambda.aws.upbound.io/v1beta1
kind: Permission
spec:
# Referencia entre controladores: Crossplane → ACK
sourceArn: "arn:aws:execute-api:${region}:${account}:${apiGateway.status.apiID}/*/*/*"
Esta integración entre controladores con recursos compartidos de autenticación es lo que hace poderosas a las Composiciones Híbridas de Kro—combinando lo mejor de ambos mundos en una única capa de orquestación unificada con seguridad integrada.
Arquitectura de autenticación: Recursos compartidos de Cognito
Un componente de la plataforma serverless es la arquitectura de autenticación centralizada usando AWS Cognito. En lugar de crear clientes individuales de Cognito para cada instancia de aplicación (lo que requeriría gestionar más de 200 clientes para 200 entornos de desarrolladores), implementamos un patrón compartido de Cognito que escala sin esfuerzo.
Por qué esto importa:
Los enfoques tradicionales requieren crear un Cognito App Client para cada instancia de aplicación, con URLs de callback específicas, esto crea sobrecarga operativa: gestion de clientes, actualizar URLs de callback cuando cambian los dominios, y mantener secretos de cliente para cada instancia.
El patrón compartido de Cognito elimina esta complejidad:
- Un App Client sirve a todas las aplicaciones
- Una única URL de callback (
https://domain.com/auth/callback) con parámetro de estado soporta todas las instancias - El enrutamiento basado en estado asegura que los usuarios regresen a la aplicación correcta
- Cero configuración por aplicación requerida
Esta arquitectura de autenticación compartida es un componente clave de la Capa 1 (Recursos Compartidos de Plataforma), proporcionando autenticación segura y escalable para todas las aplicaciones serverless desplegadas a través del patrón de Composición Híbrida de Kro.
Patrón de gestión centralizada de assets
Usamos un patrón de bucket centralizado de assets para gestionar código Lambda y plantillas de UI a través de todas las aplicaciones:
Beneficios:
- Actualizar una vez, aplicar en todas partes: Suba nuevo código Lambda al bucket de plataforma, todas las instancias lo usan
- Control de versiones: El versionado de S3 habilita rollback
- Despliegues consistentes: Todas las instancias ejecutan la misma versión de código
- Gestión simplificada: Única fuente de verdad para assets
- Consistencia de autenticación: El mismo módulo auth.js en todas las aplicaciones
CloudFront Function para reescritura de URLs
En lugar de usar Lambda@Edge, usamos CloudFront Functions (<1ms de latencia)
Esta simple función habilita:
- Bucket S3 compartido único: Todo el contenido de UI en un bucket con prefijos de ruta
- Enrutamiento dinámico: CloudFront Function agrega index.html a las rutas de directorio para enrutamiento SPA
- Latencia mínima: <1ms de tiempo de ejecución
- Arquitectura simplificada: Sin capa de cómputo adicional requerida
Beneficios operativos:
- Única fuente de verdad: Un RGD define el stack completo con autenticación
- Despliegues consistentes: La misma configuración en todos los entornos
- Resolución de problemas simplificada: Menos recursos que gestionar
- Incorporación más rápida: Nuevas aplicaciones se despliegan en minutos con autenticación integrada
- Gestión centralizada de usuarios: Un único Cognito User Pool para todas las aplicaciones
Estos resultados demuestran que las Composiciones Híbridas de Kro proporcionan no solo beneficios teóricos, sino mejoras medibles en costo, tiempo y eficiencia operativa—con autenticación integrada que escala sin esfuerzo.
Entendiendo Kro y EKS Capabilities
Antes de sumergirnos en la implementación, es importante entender las tecnologías fundamentales que hacen posibles las Composiciones Híbridas de Kro.
¿Qué es Kro?
Kro es un orquestador de recursos nativo de Kubernetes que le permite definir despliegues complejos de múltiples recursos como un único recurso personalizado. Piense en él como un «meta-controlador» que orquesta otros controladores (como ACK y Crossplane) para aprovisionar infraestructura en el orden correcto con gestión adecuada de dependencias.
Conceptos clave de Kro:
1. ResourceGraphDefinition (RGD) – La plantilla
Un RGD es una plantilla que define un nuevo CRD y los recursos que gestiona. Cuando aplica un RGD a su clúster, Kro:
- Valida la especificación del RGD
- Crea dinámicamente un nuevo CRD basado en el esquema que definió
- Registra el CRD con el servidor de API de Kubernetes
- Despliega un microcontrolador dedicado para gestionar instancias de ese CRD
El RGD especifica:
- Schema: El contrato de API (qué campos proporcionan los usuarios al crear instancias)
- Resources: Los recursos reales de Kubernetes a crear para cada instancia
- Dependencies: Cómo se relacionan los recursos entre sí (vía expresiones CEL)
apiVersion: kro.run/v1alpha1
kind: ResourceGraphDefinition
metadata:
name: my-app-stack
spec:
schema:
# Define el CRD del cual los usuarios crearán instancias
apiVersion: v1alpha1
kind: MyAppStack # Esto se convierte en un nuevo CRD
spec:
appName: string | required
environment: string | default=dev
resources:
# Define los recursos que Kro creará para cada instancia
- id: database
template:
apiVersion: dynamodb.services.k8s.aws/v1alpha1
kind: Table
# ... configuración de tabla
- id: function
template:
apiVersion: lambda.aws.upbound.io/v1beta2
kind: Function
# ... configuración de función
2. Instancia – Lo que crean los desarrolladores
Una vez que el RGD se aplica y Kro crea el CRD, los desarrolladores crean instancias de ese CRD:
apiVersion: v1alpha1
kind: MyAppStack # El CRD creado por el RGD
metadata:
name: my-app-dev
spec:
appName: my-app
environment: dev
Cuando un desarrollador crea esta instancia:
- El microcontrolador de Kro detecta la nueva instancia
- Traduce los parámetros de la instancia en recursos específicos de Kubernetes
- Crea y gestiona todos los recursos subyacentes (tabla DynamoDB, función Lambda, etc.)
- Monitorea el ciclo de vida de todos los recursos para esta instancia
Distinción clave:
- ResourceGraphDefinition (RGD): Los ingenieros de plataforma lo crean una vez para definir la plantilla
- Instancia: Los desarrolladores crean muchas de estas para desplegar aplicaciones
2. Expresiones CEL: El pegamento que hace funcionar HKC
El verdadero poder de las Composiciones Híbridas de Kro viene de cómo los recursos se comunican entre sí a través de los límites de los controladores. Aquí es donde el Common Expression Language (CEL) se vuelve crítico—es el mecanismo que permite que una tabla DynamoDB de ACK pase su nombre a una función Lambda de Crossplane, que luego pasa su ARN a una integración de API Gateway de ACK, creando un flujo fluido de información a través de controladores heterogéneos.
El problema que CEL resuelve
En la orquestación tradicional de infraestructura, pasar valores entre recursos requiere coordinación externa. Con Terraform, usaría variables de salida y fuentes de datos. Con CloudFormation, usaría exports e imports. Con scripts bash, analizaría la salida JSON e inyectaría valores en comandos subsiguientes. Cada enfoque agrega complejidad, introduce puntos de falla y rompe el modelo declarativo.
CEL elimina esta sobrecarga de coordinación al hacer declarativas las referencias de recursos. Cuando escribe ${lambdaFunction.status.atProvider.arn} en una integración de API Gateway, no solo está referenciando un valor—está declarando una relación de dependencia que Kro automáticamente entiende y aplica. Kro sabe que debe crear la función Lambda primero, esperar a que alcance el estado «Ready», extraer el ARN de su estado, y solo entonces crear la integración de API Gateway con ese ARN. Sin orquestación externa, sin coordinación manual, sin scripts bash analizando salida JSON.
Entendiendo la resolución de variables: Dos momentos
La resolución de variables en las Composiciones Híbridas de Kro ocurre en dos momentos distintos, cada uno sirviendo un propósito diferente en el ciclo de vida del despliegue:
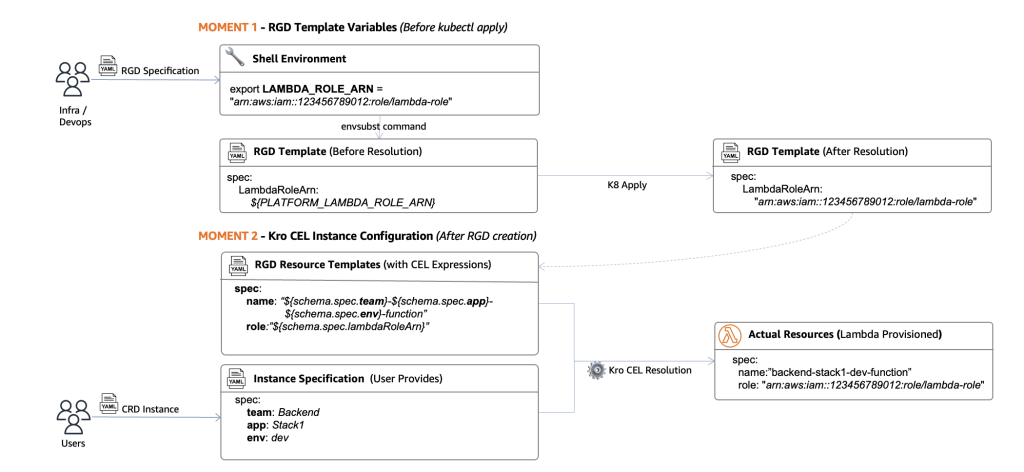
Figura 5. La resolución de variables ocurre en dos momentos. El Momento 1 (envsubst) resuelve las variables de plantilla del RGD antes de kubectl apply. El Momento 2 (Kro CEL) resuelve la configuración de la instancia después de la creación de la instancia.
Momento 1: Variables de plantilla del RGD (envsubst – Antes de kubectl apply)
Los ingenieros de plataforma usan variables de entorno para inyectar identificadores de recursos compartidos de plataforma en la plantilla del RGD antes de desplegarlo al clúster. Esto ocurre una vez durante el despliegue del RGD, no por instancia.
Ejemplo: ARN del rol IAM de Lambda de plataforma
# En la plantilla del RGD (antes de envsubst)
roleArn: "${PLATFORM_LAMBDA_ROLE_ARN}"
# Después de envsubst (antes de kubectl apply)
roleArn: "arn:aws:iam::123456789012:role/platform-lambda-role"
Por qué esto importa: Los recursos compartidos de plataforma (roles IAM, pools de Cognito, distribuciones CloudFront) se crean una vez y son referenciados por todas las instancias de aplicación. Usar envsubst permite a los ingenieros de plataforma inyectar estos ARNs en la plantilla del RGD sin codificarlos directamente, haciendo el RGD portable entre entornos (dev, staging, prod).
Momento 2: Configuración de instancia (Kro CEL – Después de la creación de la instancia)
Los desarrolladores proporcionan valores específicos de la aplicación al crear instancias. Kro resuelve estas expresiones CEL dinámicamente para cada instancia, habilitando personalización por aplicación.
Ejemplo: Nombre de función Lambda
# En la plantilla del RGD (expresión CEL)
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-function"
# El desarrollador crea la instancia con:
spec:
teamName: "team-backend"
appName: "inventory"
environment: "dev"
# Kro resuelve a:
name: "team-backend-app-dev-function"
Por qué esto importa: Cada instancia de aplicación necesita nombres de recursos únicos, configuración personalizada y ajustes específicos del entorno. Las expresiones CEL habilitan esta personalización por instancia mientras mantienen una única plantilla de RGD.
El patrón de dos momentos en acción
Este patrón de resolución en dos momentos es lo que hace a las Composiciones Híbridas de Kro tanto poderosas como flexibles:
- Configuración de plataforma (Momento 1): Recursos compartidos inyectados una vez vía envsubst
- ARNs de roles IAM para ejecución de Lambda
- IDs de Cognito User Pool para autenticación
- Dominios de distribución CloudFront para CDN
- Nombres de buckets S3 para assets de plataforma
- Configuración de aplicación (Momento 2): Valores por instancia resueltos vía Kro CEL
- Nombres de recursos (tabla DynamoDB, función Lambda, API Gateway)
- Configuraciones específicas del entorno (dev, staging, prod)
- Identificadores de equipo y desarrollador para multi-tenancy
- Dominios personalizados y registros DNS
Ejemplo: Configuración de función Lambda
# Plantilla del RGD (combina ambos momentos)
- id: lambdaFunction
template:
apiVersion: lambda.aws.upbound.io/v1beta2
kind: Function
metadata:
# Momento 2: Kro CEL resuelve por instancia
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-function"
spec:
# Momento 1: envsubst resuelve recurso de plataforma
role: "${PLATFORM_LAMBDA_ROLE_ARN}"
environment:
variables:
# Momento 1: envsubst resuelve Cognito compartido
COGNITO_USER_POOL_ID: "${COGNITO_USER_POOL_ID}"
# Momento 2: Kro CEL resuelve por instancia
TABLE_NAME: "${dynamodbTable.spec.tableName}"
Este patrón de dos momentos elimina la necesidad de plantillas de RGD separadas por entorno o por equipo, mientras proporciona la flexibilidad para personalizar cada instancia de aplicación.
Cómo CEL potencia el stack serverless
En la implementación, las expresiones CEL manejan tres patrones críticos de orquestación que de otro modo requerirían código personalizado significativo:
Patrón 1: Nomenclatura dinámica para múltiples casos de uso
La plataforma soporta diversos patrones de despliegue—aplicaciones SaaS multi-tenant, entornos específicos de desarrollador, staging compartido de equipo, vistas previas de feature branch y releases versionados de producción. Cada patrón requiere diferentes convenciones de nomenclatura, y los operadores ternarios de CEL hacen esta lógica declarativa sin requerir definiciones de recursos separadas o plantillas externas.
Para despliegues multi-tenant, los nombres de recursos incluyen el identificador del tenant para aislamiento completo:
name: "${schema.spec.tenantId + '-' + schema.spec.appName + '-' + schema.spec.environment}"
# Resultado: "tenant-a-app-prod", "tenant-b-app-prod"
Para entornos de desarrollador, los nombres incluyen la identidad del desarrollador para desarrollo paralelo:
name: "${schema.spec.environment == 'dev' ?
schema.spec.developerName + '-' + schema.spec.appName + '-dev' :
schema.spec.teamName + '-' + schema.spec.appName + '-' + schema.spec.environment}"
# Resultado: "developer1-app-dev", "team-app-staging"
Para despliegues de feature branch, los nombres incorporan el identificador de la rama para entornos efímeros de vista previa:
name: "${schema.spec.branchName + '-' + schema.spec.appName + '-preview'}"
# Resultado: "feature-auth-app-preview", "bugfix-123-app-preview"
Para releases versionados de producción, los nombres incluyen números de versión semántica para despliegues blue-green:
name: "${schema.spec.appName + '-' + schema.spec.version + '-' + schema.spec.environment}"
# Resultado: "inventory-v2-prod", "inventory-v1-prod"
Este único RGD maneja todos estos patrones a través de expresiones CEL, eliminando la necesidad de múltiples definiciones de recursos, sistemas de plantillas externos o scripts de orquestación que generan nombres programáticamente. La lógica de nomenclatura vive declarativamente en el RGD donde pertenece, haciéndola fácil de entender, modificar y auditar. Cuando surge un nuevo patrón de nomenclatura (como despliegues canary o variantes regionales), agregamos otra expresión CEL en lugar de modificar las herramientas de despliegue.
Patrón 2: Flujo de datos entre controladores
La tabla DynamoDB (ACK) necesita pasar su nombre a la función Lambda (Crossplane), que necesita pasar su ARN al API Gateway (ACK), que necesita pasar su ID de vuelta al permiso Lambda (Crossplane). CEL hace este flujo bidireccional a través de los límites de los controladores fluido:
# ACK DynamoDB → Crossplane Lambda
- id: lambdaFunction
template:
spec:
environment:
variables:
TABLE_NAME: "${dynamodbTable.spec.tableName}"
COGNITO_USER_POOL_ID: "${COGNITO_USER_POOL_ID}"
# Crossplane Lambda → ACK API Gateway
- id: apiIntegration
template:
spec:
integrationURI: "${lambdaFunction.status.atProvider.arn}"
# ACK API Gateway → Crossplane Lambda Permission
- id: lambdaPermission
template:
spec:
sourceArn: "arn:aws:execute-api:${region}:${account}:${apiGateway.status.apiID}/*/*/*"
Cada expresión crea una dependencia implícita que Kro aplica automáticamente. La función Lambda no se creará hasta que la tabla DynamoDB exista. El API Gateway no se configurará hasta que la función Lambda esté lista. El permiso Lambda no se otorgará hasta que el API Gateway esté operativo. Esta cadena de dependencias—abarcando tres controladores diferentes—requiere cero código de orquestación.
Patrón 3: Configuración dinámica basada en estado en tiempo de ejecución
Algunas decisiones de configuración dependen del estado en tiempo de ejecución que solo se conoce después de que los recursos se crean. Por ejemplo, el Job de sincronización de UI necesita el ID real del API Gateway (no conocido hasta que AWS lo crea) para configurar el endpoint correcto de la API. Las expresiones CEL que referencian campos de estado automáticamente esperan ese estado en tiempo de ejecución:
- id: uiSyncJob
template:
spec:
containers:
- env:
- name: API_ENDPOINT
value: "${apiGateway.status.apiID}" # Espera la creación del API Gateway
- name: S3_PREFIX
value: "${schema.spec.developerName}-${schema.spec.appName}-dev" # Disponible inmediatamente
Kro entiende que status.apiID requiere esperar a que el API Gateway sea creado y esté listo, mientras que schema.spec.customDomain está disponible inmediatamente desde la entrada del usuario. Esta conciencia de temporización está incorporada en el modelo de resolución de CEL—no necesita declarar explícitamente «esperar por este recurso antes de crear aquel otro.»
El impacto operativo
Las expresiones CEL transformaron el proceso de despliegue de orquestación imperativa a configuración declarativa. Eliminamos scripts bash que previamente analizaban salida JSON, inyectaban valores en plantillas y coordinaban la temporización de creación de recursos. Más importante aún, eliminamos toda una clase de errores—problemas de temporización donde los recursos se creaban antes de que sus dependencias estuvieran listas, errores de referencia donde los valores se extraían incorrectamente del JSON, y fallas de coordinación donde el script de orquestación no contemplaba todas las relaciones de dependencia.
El resultado es un proceso de despliegue que es tanto más simple como más confiable. Los desarrolladores no piensan en orquestación—declaran qué recursos necesitan y cómo se relacionan, y Kro maneja el resto. El stack serverless de 22 recursos se despliega en la secuencia correcta cada vez, con cero errores de orquestación, porque la lógica de orquestación está codificada en expresiones CEL que Kro aplica automáticamente.
3. Referencias de campos de estado
Kro automáticamente rastrea el estado de los recursos y hace los campos disponibles para referencias entre recursos:
# Lambda referencia la tabla DynamoDB creada anteriormente
environment:
variables:
TABLE_NAME: "${dynamodbTable.spec.tableName}"
# La integración de API Gateway referencia el ARN de Lambda
integrationURI: "${lambdaFunction.status.atProvider.arn}"
# El permiso Lambda referencia el ID del API Gateway
sourceArn: "arn:aws:execute-api:${region}:${account}:${apiGateway.status.apiID}/*/*/*"
Esto elimina la necesidad de coordinación manual o herramientas externas de orquestación—Kro lo maneja nativamente.
EKS Capabilities: Opciones de despliegue para HKC
Las Composiciones Híbridas de Kro son un patrón de orquestación, no un modelo de despliegue. Esta sección explica cómo HKC funciona tanto con controladores auto-hospedados como con EKS Capabilities gestionado por AWS, y por qué esta flexibilidad importa para su implementación.
Implementación HKC: EKS Capabilities o Controladores auto-hospedados
Desplegamos el patrón HKC usando ambas opciones controladores auto-hospedados y EKS Capabilities, en los clúster EKS. Esto permite un control total y acceso inmediato a las últimas funcionalidades:
Clúster EKS (HKC auto-hospedado)
├── Worker Nodes
│ ├── ACK Controllers (DynamoDB, Lambda, API Gateway, Route 53)
│ ├── Crossplane (composiciones Lambda, integración IAM)
│ ├── Kro (orquesta ACK + Crossplane)
│ └── Aplicaciones
Este enfoque funciona bien pero requiere sobrecarga operativa—instalar controladores, gestionar actualizaciones, monitorear salud y consumir recursos de worker nodes para gestión de infraestructura.
EKS Capabilities para HKC
Amazon EKS Capabilities ofrece una alternativa gestionada. AWS ejecuta ACK, Kro y Argo CD en el plano de control de EKS, eliminando la sobrecarga de instalación y mantenimiento:
EKS Capabilities (HKC gestionado)
Plano de control gestionado por AWS
├── ACK Controllers (AWS gestiona)
├── Kro (AWS gestiona)
└── Argo CD (AWS gestiona)
Clúster EKS
├── Worker Nodes
│ ├── Crossplane (auto-hospedado)
│ └── Aplicaciones
El patrón HKC permanece idéntico
La perspectiva crítica: Los ResourceGraphDefinitions de HKC funcionan sin cambios en ambos modelos de despliegue. El mismo RGD que orquesta 15 recursos a través de ACK y Crossplane funciona ya sea que los controladores estén auto-hospedados o gestionados:
# Mismo patrón HKC, diferente modelo de despliegue
apiVersion: v1alpha1
kind: ServerlessAppStack
metadata:
name: my-app
spec:
appName: inventory
environment: dev
# Kro orquesta (auto-hospedado O EKS Capabilities)
# ACK aprovisiona (auto-hospedado O EKS Capabilities)
# Crossplane aprovisiona (auto-hospedado en ambos)
# Resultado: 15 recursos, 5-8 minutos, dependencias automáticas
Por qué esto importa para HKC
Esta flexibilidad de despliegue es una fortaleza del patrón HKC:
- Comience con auto-hospedado: Obtenga control total, acceso inmediato a funcionalidades
- Migre a EKS Capabilities: Reduzca la carga operativa cuando esté listo
- Sin cambios de código: Los RGDs permanecen idénticos, solo cambia el modelo de despliegue
- Portabilidad del patrón: HKC funciona independientemente de cómo se desplieguen los controladores
Eligiendo su modelo de despliegue HKC
Para nuevas implementaciones HKC:
- Auto-hospedado: Si necesita las últimas funcionalidades, configuraciones personalizadas o tiene prácticas establecidas de gestión de controladores
- EKS Capabilities: Si desea reducir la sobrecarga operativa, actualizaciones automáticas y gestión simplificada
Para implementaciones HKC existentes:
- Su inversión en patrones HKC está preparada para el futuro
- La migración entre modelos de despliegue no requiere reescribir RGDs
- El patrón de orquestación, la experiencia del desarrollador y los beneficios operativos permanecen constantes
La conclusión de HKC
Las Composiciones Híbridas de Kro tratan sobre el patrón de orquestación—usar ACK y Crossplane juntos dentro de ResourceGraphDefinitions de Kro. Si despliega controladores auto-hospedados o usa EKS Capabilities es una elección operativa, no arquitectónica. El patrón HKC entrega orquestación unificada, dependencias automáticas e integración entre controladores independientemente del modelo de despliegue.
Esta flexibilidad significa que puede adoptar HKC hoy con controladores auto-hospedados, sabiendo que puede migrar a EKS Capabilities después sin reescribir sus definiciones de infraestructura.
Inmersión en la implementación
Ahora que entendemos la arquitectura y los beneficios, recorramos la implementación real. Cubriremos el ResourceGraphDefinition completo con los 15 recursos, mostrando cómo Kro orquesta ACK, Crossplane y recursos nativos de Kubernetes con autenticación integrada.
Referencia de código: Todos los manifiestos, scripts y documentación están en el repositorio sample-kro-serverless-app-stack. Los fragmentos YAML a continuación están abreviados — consulte el repositorio para las versiones completas y desplegables.
Paso 1: Desplegar recursos compartidos de plataforma
Antes de crear el RGD, despliegue los recursos compartidos de plataforma que todas las aplicaciones usarán. Estos recursos se crean una vez y son referenciados por todas las instancias de aplicación.
Paso 2: Crear el ResourceGraphDefinition
Ahora crearemos el RGD completo que orquesta los 15 recursos. Este es el corazón del patrón de Composición Híbrida de Kro.
apiVersion: kro.run/v1alpha1
kind: ResourceGraphDefinition
metadata:
name: serverless-app-stack
spec:
schema:
apiVersion: v1alpha1
kind: ServerlessAppStack
spec:
# Campos específicos de la instancia
teamName: string | required
developerName: string
appName: string | required
environment: string | default=dev
customDomain: string | required
resources:
# 1. Tabla DynamoDB (ACK)
- id: dynamodbTable
template:
apiVersion: dynamodb.services.k8s.aws/v1alpha1
kind: Table
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-table"
spec:
tableName: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-table"
billingMode: PAY_PER_REQUEST
... (removido por brevedad)
# 2. Función Lambda (Crossplane)
- id: lambdaFunction
template:
apiVersion: lambda.aws.upbound.io/v1beta2
kind: Function
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-function"
spec:
forProvider:
functionName: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-function"
... (removido por brevedad)
environment:
variables:
# Referencia entre controladores: Crossplane → ACK
TABLE_NAME: "${dynamodbTable.spec.tableName}"
# Configuración compartida de Cognito
COGNITO_USER_POOL_ID: "${COGNITO_USER_POOL_ID}"
# 3. API Gateway (ACK)
- id: apiGateway
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: API
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-api"
spec:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-api"
protocolType: HTTP
corsConfiguration:
allowOrigins:
- "https://${schema.spec.customDomain}"
allowMethods:
- GET
... (removido por brevedad)
allowHeaders:
- "*"
# 4. Autorizador de API Gateway (ACK) - validación JWT
- id: apiAuthorizer
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: Authorizer
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-authorizer"
spec:
apiID: "${apiGateway.status.apiID}"
authorizerType: JWT
identitySource:
- "$request.header.Authorization"
jwtConfiguration:
issuer: "${COGNITO_ISSUER_URL}"
audience:
- "${COGNITO_CLIENT_ID}"
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-authorizer"
# 5. Integración de API Gateway (ACK)
- id: apiIntegration
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: Integration
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-integration"
spec:
apiID: "${apiGateway.status.apiID}"
integrationType: AWS_PROXY
# Referencia entre controladores: ACK → Crossplane
integrationURI: "${lambdaFunction.status.atProvider.arn}"
payloadFormatVersion: "2.0"
# 6-10. Rutas de API Gateway (ACK) - con autorizador JWT
- id: apiRouteGet
template:
apiVersion: apigatewayv2.services.k8s.aws/v1alpha1
kind: Route
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-route-get"
spec:
apiID: "${apiGateway.status.apiID}"
routeKey: "GET /products"
target: "integrations/${apiIntegration.status.integrationID}"
authorizationType: JWT
authorizerID: "${apiAuthorizer.status.authorizerID}"
... (rutas removidas por brevedad)
# 11. Permiso Lambda (Crossplane)
- id: lambdaPermission
template:
apiVersion: lambda.aws.upbound.io/v1beta1
kind: Permission
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-permission"
spec:
forProvider:
action: lambda:InvokeFunction
functionNameRef:
name: "${lambdaFunction.metadata.name}"
principal: apigateway.amazonaws.com
# Referencia entre controladores: Crossplane → ACK
sourceArn: "arn:aws:execute-api:${AWS_REGION}:${AWS_ACCOUNT_ID}:${apiGateway.status.apiID}/*/*/*"
# 12. ConfigMap (Kubernetes nativo)
- id: appInfo
template:
apiVersion: v1
kind: ConfigMap
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}-info"
data:
api-endpoint: "https://${apiGateway.status.apiID}.execute-api.${schema.spec.region}.amazonaws.com/${schema.spec.environment}"
ui-url: "https://${DOMAIN_NAME}/${schema.spec.developerName}-${schema.spec.appName}-dev/"
... (removido por brevedad)
# 13. ServiceAccount con IRSA (Kubernetes nativo)
- id: s3UploaderServiceAccount
template:
apiVersion: v1
kind: ServiceAccount
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-s3-uploader"
annotations:
eks.amazonaws.com/role-arn: "${PLATFORM_S3_UPLOADER_ROLE_ARN}"
# 14. Job de sincronización de UI (Kubernetes nativo)
- id: uiSyncJob
template:
apiVersion: batch/v1
kind: Job
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-ui-sync-job"
spec:
template:
spec:
serviceAccountName: "${s3UploaderServiceAccount.metadata.name}"
restartPolicy: OnFailure
containers:
- name: sync-ui-assets
image: amazon/aws-cli:latest
command:
- /bin/bash
- -c
... (removido por brevedad)
env:
- name: API_ENDPOINT
value: "${apiGateway.status.apiID}"
- name: COGNITO_USER_POOL_ID
value: "${COGNITO_USER_POOL_ID}"
- name: COGNITO_CLIENT_ID
value: "${COGNITO_CLIENT_ID}"
Entendiendo el poder de orquestación del RGD
Este RGD demuestra varias capacidades avanzadas de Kro que hacen tan efectivas a las Composiciones Híbridas de Kro:
1. Orquestación entre controladores
Note cómo los recursos fluyen entre diferentes controladores:
- Tabla DynamoDB de ACK → Función Lambda de Crossplane (nombre de tabla pasado vía
${dynamodbTable.spec.tableName}) - Función Lambda de Crossplane → Integración de API Gateway de ACK (ARN de Lambda pasado vía
${lambdaFunction.status.atProvider.arn}) - API Gateway de ACK → Permiso Lambda de Crossplane (ID de API Gateway pasado vía
${apiGateway.status.apiID})
Kro detecta automáticamente estas dependencias entre controladores y aprovisiona recursos en el orden correcto. No escribe código de orquestación—simplemente referencia los campos que necesita, y Kro maneja el resto.
2. Arquitectura de autenticación integrada
La configuración del autorizador JWT demuestra cómo Cognito se integra sin problemas:
- Autorizador de API Gateway referencia Cognito User Pool vía
${COGNITO_ISSUER_URL}y${COGNITO_CLIENT_ID} - Rutas de API Gateway referencian el autorizador vía
${apiAuthorizer.status.authorizerID} - Función Lambda recibe configuración de Cognito vía variables de entorno para validación de grupos
Esto crea un flujo completo de autenticación: API Gateway valida tokens JWT de Cognito, enruta solicitudes autorizadas a Lambda, y Lambda realiza autorización adicional basada en grupos. Todo configurado declarativamente en el RGD.
3. Nomenclatura dinámica con CEL
Los patrones de nomenclatura soportan múltiples escenarios de despliegue:
- Entornos de desarrollador:
${schema.spec.developerName}-${schema.spec.appName}-${schema.spec.environment}→developer1-app-dev - Entornos de equipo:
${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment}→team-backend-app-staging - Feature branches: Los operadores ternarios de CEL pueden crear patrones como
${schema.spec.featureBranch != "" ? schema.spec.featureBranch + "-" : ""}${schema.spec.appName}
Esta flexibilidad significa que un solo RGD soporta todos los patrones de despliegue sin modificación.
4. Propagación de campos de estado
Kro monitorea el estado de los recursos y propaga campos automáticamente:
- Espera a que la tabla DynamoDB alcance el estado «ACTIVE» antes de crear Lambda
- Espera a que Lambda alcance el estado «Ready» antes de crear la integración de API Gateway
- Espera a que API Gateway tenga
apiIDantes de crear rutas y autorizador - Espera a que el autorizador tenga
authorizerIDantes de adjuntarlo a las rutas
Este monitoreo automático de estado elimina condiciones de carrera y asegura que los recursos estén completamente operativos antes de que se creen los recursos dependientes.
5. Recursos nativos de Kubernetes con IRSA
El RGD incluye un ServiceAccount que habilita automatización post-aprovisionamiento usando IRSA (IAM Roles for Service Accounts):
# ServiceAccount para operaciones S3 (sincronización de UI)
- id: s3UploaderServiceAccount
template:
apiVersion: v1
kind: ServiceAccount
metadata:
name: "${schema.spec.teamName}-${schema.spec.appName}-s3-uploader-sa"
annotations:
# IRSA: Otorga permisos de AWS S3 sin credenciales codificadas
eks.amazonaws.com/role-arn: "${PLATFORM_S3_UPLOADER_ROLE_ARN}"
Por qué esta estrategia funciona:
- Roles compartidos de plataforma: El ServiceAccount referencia un rol IAM compartido (creado una vez en la Capa 1, usado por todas las aplicaciones)
- Cero gestión de credenciales: EKS inyecta automáticamente credenciales temporales de AWS en los pods usando estos ServiceAccounts
- Seguridad: Sin credenciales de AWS almacenadas en Secrets de Kubernetes o variables de entorno
- Eficiencia: Elimina 2-3 minutos de creación de roles IAM por despliegue de aplicación
El Job usando este ServiceAccount:
Un Job de Kubernetes completa la automatización del despliegue:
- Job de sincronización de UI (usa
s3UploaderServiceAccount):- Copia assets de UI desde el bucket de plataforma al bucket compartido con prefijo de ruta específico de la aplicación
- Inyecta la URL del endpoint de API y la configuración de Cognito en archivos JavaScript
- Se ejecuta después de que API Gateway esté listo (necesita la URL del endpoint de API)
Esto demuestra el patrón de tres controladores de HKC: ACK aprovisiona servicios nativos de AWS, Crossplane maneja composiciones complejas, y los recursos nativos de Kubernetes ejecutan tareas de automatización que no se mapean a recursos de AWS. Kro orquesta los tres sin problemas.
Resumen de funcionalidades clave:
- 15 recursos orquestados por Kro a través de 3 controladores (ACK, Crossplane, K8s nativo)
- Referencias entre controladores (ACK ↔ Crossplane ↔ K8s nativo) con resolución automática de dependencias
- Nomenclatura dinámica con expresiones CEL soportando múltiples patrones de despliegue
- Resolución automática de dependencias eliminando scripts de orquestación
- Autenticación JWT integrada con Cognito User Pool
- Autorización basada en grupos en funciones Lambda
- Propagación de campos de estado previniendo condiciones de carrera (race conditions)
- ServiceAccounts habilitados con IRSA con roles compartidos de plataforma (cero gestión de credenciales)
- Automatización post-aprovisionamiento vía Job de Kubernetes (sincronización de UI)
Paso 3: Desplegar instancias de aplicación
Con el RGD desplegado, crear nuevas aplicaciones se vuelve notablemente simple. Ya sea que esté desplegando entornos de desarrollador, instancias SaaS multi-tenant o vistas previas de feature branch, el proceso es idéntico—un único recurso personalizado de Kubernetes que Kro orquesta en 15 recursos de AWS con dependencias correctas y autenticación integrada.
La experiencia universal de despliegue
La belleza de este diseño de RGD es su flexibilidad. El mismo ResourceGraphDefinition soporta los tres casos de uso que discutimos anteriormente. Aquí hay un ejemplo concreto usando un entorno de desarrollador:
apiVersion: v1alpha1
kind: ServerlessAppStack
metadata:
name: developer1-app-dev
spec:
teamName: team-backend
developerName: developer1
appName: app
environment: dev
customDomain: developer1-app-dev.example.com
Mecanismos de despliegue: Desde autoservicio hasta GitOps
Aunque este ejemplo muestra un manifiesto YAML directo, las plataformas de producción típicamente integran Kro con mecanismos de entrega que coinciden con los flujos de trabajo organizacionales. Backstage proporciona portales de autoservicio para desarrolladores con plantillas de software que generan estas especificaciones de instancia, permitiendo a los equipos aprovisionar infraestructura a través de formularios intuitivos en lugar de escribir YAML. Canoe.io ofrece capacidades similares de autoservicio con gobernanza integrada y visibilidad de costos. Para plataformas impulsadas por GitOps, ArgoCD o FluxCD sincronizan continuamente las especificaciones de instancia desde repositorios Git a Kubernetes, asegurando despliegues declarativos y auditables con detección automática de drift. Los pipelines de CI/CD pueden generar especificaciones de instancia dinámicamente durante los procesos de build, habilitando entornos efímeros para vistas previas de pull requests o pruebas automatizadas. La belleza del diseño de Kro es su agnosticismo respecto al mecanismo de entrega—ya sea que los desarrolladores usen plantillas de Backstage, los ingenieros de plataforma hagan commit a Git, o la automatización genere especificaciones programáticamente, la orquestación de Kro permanece idéntica. La especificación de instancia es el contrato; cómo llega a Kubernetes es un detalle de implementación que las plataformas pueden adaptar a sus herramientas y procesos existentes.
Adaptando para otros casos de uso:
El mismo RGD funciona para diferentes escenarios simplemente cambiando la especificación de la instancia:
- SaaS Multi-Tenant: Configure
teamName: tenant-acme,developerName: "",environment: prod,customDomain: acme.example.com - Feature Branch: Configure
developerName: feature-auth, mantenga los demás campos similares al entorno de dev
Por qué esta flexibilidad importa
Las expresiones CEL del RGD habilitan esta versatilidad. El patrón de nomenclatura ${schema.spec.teamName}-${schema.spec.appName}-${schema.spec.environment} se adapta automáticamente:
- Entornos de desarrollador:
team-backend-app-dev(recursos compartidos de equipo) - SaaS multi-tenant:
tenant-acme-app-prod(aislamiento específico por tenant) - Feature branches:
team-backend-app-dev(entornos temporales de prueba)
El campo developerName es opcional y se usa solo cuando es necesario (entornos de desarrollador, feature branches). Para despliegues multi-tenant, el campo teamName se convierte en el identificador del tenant. Este patrón de diseño significa que los equipos de plataforma mantienen un solo RGD que sirve a todos los escenarios de despliegue, en lugar de crear plantillas separadas para cada caso de uso.
Lo que hace esto poderoso
Independientemente del caso de uso, este simple manifiesto YAML desencadena la creación de 15 recursos de AWS:
- 1 tabla DynamoDB con cifrado y facturación bajo demanda
- 1 función Lambda con extracción de claims JWT de Cognito
- 1 API Gateway con autorizador JWT
- 1 autorizador JWT validando tokens de Cognito
- 5 rutas de API Gateway (GET, POST, PUT, DELETE, OPTIONS)
- 1 integración de API Gateway conectando rutas a Lambda
- 1 stage de API Gateway con auto-deploy
- 1 permiso Lambda permitiendo invocación desde API Gateway
- 1 ConfigMap capturando información de despliegue
- 1 ServiceAccount de Kubernetes para ejecución de Jobs
- 1 Job de Kubernetes para sincronización de UI
El flujo de orquestación
Cuando aplica cualquiera de estas instancias—ya sea para un desarrollador, un tenant o un feature branch—esto es lo que sucede detrás de escena. La secuencia de orquestación, temporización y aprovisionamiento de recursos son idénticos en todos los casos de uso; solo los nombres de recursos cambian basándose en la especificación de la instancia.
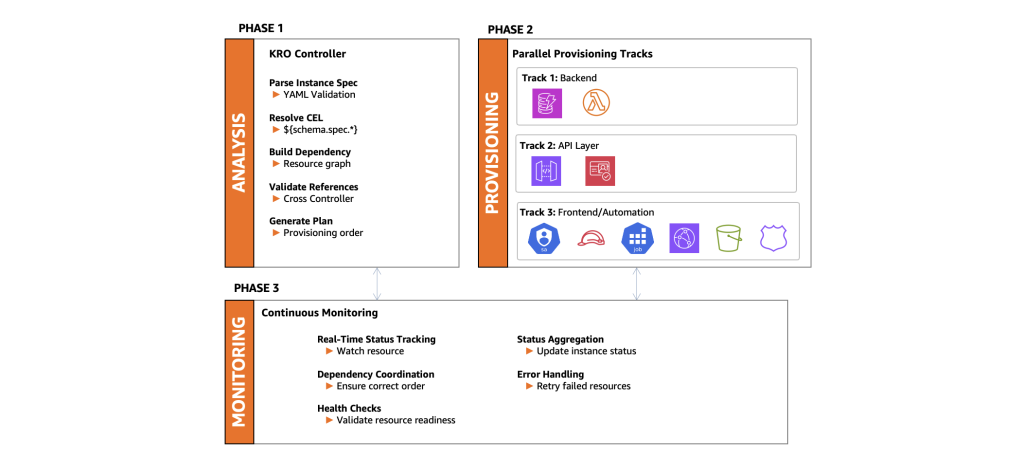
Figura 6. El proceso de orquestación en tres fases de Kro. La Fase 1 analiza y valida el despliegue, la Fase 2 aprovisiona recursos en paralelo, y la Fase 3 monitorea continuamente el estado y coordina dependencias.
Fase 1: Análisis de Kro y construcción del grafo de dependencias
Kro realiza un análisis sofisticado antes de crear cualquier recurso de AWS:
- Análisis de la especificación de instancia – Lee la especificación de la instancia y valida todos los campos requeridos
- Resolución de expresiones CEL – Resuelve todas las expresiones
${schema.spec.*}con los valores de la instancia - Construcción del grafo de dependencias – Analiza todas las plantillas de recursos buscando referencias entre recursos
- Validación y verificaciones previas al vuelo – Verifica que todos los recursos referenciados existan en el RGD
- Generación del plan de aprovisionamiento – Determina qué recursos pueden crearse en paralelo
Por qué esta fase importa: Este análisis previo es lo que hace a Kro tan poderoso. Los enfoques tradicionales requieren scripts de orquestación manuales para manejar dependencias. Kro lo hace automáticamente analizando expresiones CEL, capturando errores antes de que se cree cualquier recurso de AWS.
Fase 2: Aprovisionamiento de recursos
Kro ejecuta el plan de aprovisionamiento, creando recursos en orden de dependencia:
Recursos de backend:
- Tabla DynamoDB (ACK)
- Crea la tabla con facturación PAY_PER_REQUEST y cifrado
- Espera el estado «ACTIVE» antes de proceder
- Función Lambda (Crossplane)
- Descarga código del bucket S3 de plataforma, adjunta rol IAM compartido
- Inyecta variables de entorno (nombre de tabla, configuración de Cognito)
Recursos de la capa de API:
- API Gateway + Integración (ACK)
- Crea API HTTP con configuración CORS
- Conecta API Gateway a Lambda usando el ARN del estado de Crossplane
- Autorizador de API Gateway (ACK)
- Configura validación JWT con Cognito User Pool compartido
- Referencia URL del emisor y Client ID (mismo para todas las aplicaciones)
- Rutas de API Gateway (ACK)
- Crea 5 rutas (GET, POST, PUT, DELETE, OPTIONS) en paralelo
- Adjunta autorizador JWT a rutas protegidas
- Permiso Lambda (Crossplane)
- Otorga permiso a API Gateway para invocar la función Lambda
Recursos de automatización:
- ServiceAccount (K8s nativo)
- Crea ServiceAccount con anotación IRSA para acceso a S3
- Job de sincronización de UI (K8s nativo)
- Copia assets de UI al bucket S3 compartido con prefijo de ruta, inyecta endpoint de API y configuración de Cognito
- ConfigMap (K8s nativo)
- Captura información de despliegue (endpoint de API, URL de UI, configuración de Cognito)
Fase 3: Propagación de estado y monitoreo de salud (continuo)
Mientras la Fase 2 aprovisiona recursos, Kro monitorea y actualiza el estado continuamente:
- Kro observa las condiciones de estado de cada recurso en tiempo real
- Actualiza el estado general de la instancia a medida que los recursos se vuelven listos
- Proporciona condiciones detalladas para resolución de problemas
- Expone el estado a través de comandos
kubectl getykubectl describe
Resultado del despliegue:
Después de 5-8 minutos, el stack serverless completo está operativo:
- Tabla DynamoDB:
team-backend-developer1-inventory-dev-table(cifrada, bajo demanda) - Función Lambda:
team-backend-developer1-inventory-dev-function(con claims JWT de Cognito) - API Gateway:
team-backend-developer1-inventory-dev-api(con autorizador JWT) - Endpoint de API:
https://<api-id>.execute-api.us-east-2.amazonaws.com/dev - URL de UI:
https://domain.com/developer1-inventory-dev/(basado en ruta en CloudFront compartido) - Autenticación: Validación JWT vía Cognito User Pool compartido
Monitoreando el progreso del despliegue
Monitoree el despliegue usando comandos estándar de Kubernetes:
# Verificar estado de la instancia
kubectl get serverlessappstack developer1-app-dev
# Ver condiciones detalladas de estado
kubectl describe serverlessappstack developer1-app-dev
# Observar hasta completar
kubectl get serverlessappstack developer1-app-dev -w
Kro proporciona condiciones detalladas de estado mostrando qué recursos están listos, cuáles están en progreso y cualquier error encontrado. Esta visibilidad hace que la resolución de problemas sea directa—si un despliegue falla, las condiciones de estado señalan exactamente qué recurso y por qué.
La victoria de la ingeniería de plataforma
Esta experiencia universal de despliegue es la culminación de todas las decisiones arquitectónicas que hemos discutido:
- Recursos compartidos de plataforma eliminan más de 20 minutos de tiempo de espera para todos los casos de uso
- Composiciones Híbridas de Kro orquestan 15 recursos automáticamente, independientemente del escenario de despliegue
- Cognito integrado proporciona autenticación sin configuración por aplicación
- Expresiones CEL habilitan patrones de nomenclatura flexibles soportando múltiples casos de uso
- Orquestación entre controladores funciona sin problemas para desarrolladores, tenants y feature branches
Ya sea que sea un desarrollador creando un entorno personal, un equipo de plataforma aprovisionando infraestructura de tenant, o un pipeline de CI/CD desplegando vistas previas de feature branch, la experiencia es idéntica: proporcione 5 campos en un manifiesto YAML, y la plataforma maneja el resto. Esta es la esencia de una Plataforma Interna de Desarrollo (IDP) efectiva—complejidad oculta detrás de simplicidad, con un patrón sirviendo todos los escenarios.
Beneficios operativos
- Única fuente de verdad: Un RGD define el stack completo con autenticación
- Cero errores de orquestación: Resolución automática de dependencias
- Rápida incorporación: Los desarrolladores aprenden un solo patrón
- Despliegues consistentes: La misma configuración en todos los entornos
- Autenticación centralizada: Un único Cognito User Pool para todas las aplicaciones
Lecciones aprendidas
1. Los recursos nativos de Kubernetes completan el patrón HKC
Mientras ACK y Crossplane manejan el aprovisionamiento de recursos de AWS, los recursos nativos de Kubernetes (ServiceAccounts y Jobs) son esenciales para completar el despliegue. Este patrón de tres controladores es lo que hace a HKC verdaderamente «híbrido.»
La estrategia de ServiceAccount: IRSA con roles compartidos de plataforma
El RGD crea un ServiceAccount por aplicación, configurado con anotaciones IRSA (IAM Roles for Service Accounts) que otorgan permisos de AWS sin credenciales codificadas:
s3UploaderServiceAccount: Referenciaplatform-s3-uploader-rolepara operaciones S3
Por qué esto importa:
- Seguridad: Sin credenciales de AWS en Secrets o variables de entorno
- Roles compartidos: El ServiceAccount usa un rol IAM compartido de plataforma (creado una vez, usado por todas las apps)
- Credenciales automáticas: EKS inyecta credenciales temporales de AWS automáticamente
- Cero sobrecarga: Sin creación de roles IAM por aplicación
El Job: Automatización post-aprovisionamiento
Un Job de Kubernetes completa el despliegue usando este ServiceAccount:
- Job sincronizador de assets de UI: Copia assets de UI desde el bucket de plataforma al bucket compartido con prefijo de ruta específico de la aplicación, inyectando endpoint de API y configuración de Cognito
El flujo de orquestación:
ACK (DynamoDB) → Crossplane (Lambda) → ACK (API Gateway) →
Crossplane (Lambda Permission) → K8s nativo (ServiceAccount + Job)
Este patrón de tres controladores demuestra que HKC no se trata solo de orquestar controladores de infraestructura—se trata de orquestar el ciclo de vida completo del despliegue, incluyendo automatización post-aprovisionamiento que no se mapea a recursos de AWS.
2. Comience con recursos compartidos
Despliegue los recursos de plataforma primero. Las aplicaciones dependen de ellos, y aprovisionarlos una vez elimina la sobrecarga por aplicación.
3. Use envsubst para configuración de plataforma
Mantenga ARNs e IDs sensibles fuera de Git. Use variables de entorno para constantes de toda la plataforma, expresiones CEL para valores específicos de la instancia.
4. Aproveche CEL para nomenclatura dinámica
Soporte múltiples patrones de despliegue (multi-tenant, entornos de desarrollador, feature branches) con un único RGD usando operadores ternarios de CEL.
5. La integración entre controladores es poderosa
No elija entre ACK y Crossplane—use ambos. ACK para servicios nativos de AWS, Crossplane para composición, Kro para orquestación.
6. Las referencias de campos de estado eliminan la orquestación
Deje que Kro maneje las dependencias. Referencie campos de estado con expresiones CEL, y Kro automáticamente espera a que los recursos estén listos.
7. Valide temprano con Kro
Kro valida expresiones CEL antes de crear recursos de AWS. Esto captura errores de configuración tempranamente, previniendo despliegues parciales.
8. Monitoree el estado de la instancia de Kro
Use kubectl get <instance-name> para verificar el progreso del despliegue. Kro proporciona condiciones detalladas de estado para resolución de problemas.
Conclusión
Las Composiciones Híbridas de Kro representan un cambio fundamental en cómo arquitectamos patrones de infraestructura en Kubernetes. El avance no es solo orquestar recursos—es diseñar un único patrón que se adapta a múltiples casos de uso y estilos arquitectónicos sin modificación.
Un RGD, stack completo de aplicación
Un único ResourceGraphDefinition aprovisiona todo lo necesario para una aplicación de producción. En el ejemplo serverless, eso son 15 recursos: tabla DynamoDB, función Lambda con lógica de negocio, API Gateway con autenticación JWT, CDN CloudFront, DNS Route 53 y flujos de trabajo de despliegue automatizados—todo orquestado automáticamente en 5-8 minutos desde un único recurso personalizado de Kubernetes.
Pero serverless es solo un ejemplo de lo que las Composiciones Híbridas de Kro pueden orquestar. El mismo patrón aplica a:
- Aplicaciones basadas en contenedores: Clústeres EKS, servicios ECS, ingress ALB, bases de datos RDS, ElastiCache, dashboards de CloudWatch
- Pipelines de datos: Clústeres EMR, jobs de Glue, Step Functions, data lakes S3, tablas Athena, dashboards de QuickSight
- Plataformas de ML: Endpoints de SageMaker, jobs de entrenamiento, registros de modelos, feature stores, pipelines de inferencia
- Arquitecturas orientadas a eventos: Reglas de EventBridge, tópicos SNS, colas SQS, procesadores Lambda, streams de DynamoDB
- Plataformas de microservicios: Service mesh (App Mesh), API Gateway, descubrimiento de servicios, trazabilidad distribuida, logging centralizado
El patrón es agnóstico a la arquitectura. Ya sea que esté construyendo APIs serverless, microservicios en contenedores, pipelines de procesamiento de datos o plataformas de inferencia de ML, las Composiciones Híbridas de Kro proporcionan el framework de orquestación. Un RGD define el stack completo para la arquitectura que elija.
Un patrón, múltiples casos de uso
Más allá de la flexibilidad arquitectónica, el mismo RGD sirve escenarios de despliegue fundamentalmente diferentes a través de expresiones CEL y nomenclatura dinámica:
- Entornos de desarrollador: Desarrollo paralelo con stacks personales aislados (
developer1-app-dev,developer2-app-dev) - SaaS Multi-Tenant: Aislamiento de clientes con recursos específicos por tenant (
tenant-acme-app-prod,tenant-beta-app-prod) - Vistas previas de Feature Branch: Entornos efímeros de prueba para pull requests (
feature-auth-app-dev,feature-payment-app-dev) - Despliegues regionales: Mismo stack en múltiples regiones (
us-east-inventory-prod,eu-west-inventory-prod) - Promoción de entornos: Configuración idéntica a través de dev, staging, producción con valores específicos del entorno
Esta flexibilidad significa que los equipos de plataforma mantienen un patrón en lugar de plantillas separadas para cada escenario. Los desarrolladores usan la misma interfaz independientemente del caso de uso o arquitectura. La plataforma escala de 0 a N aplicaciones sin cambios arquitectónicos.
La ventaja de la composición híbrida
«Híbrido» no se trata solo de mezclar controladores—se trata de componer la herramienta correcta para cada capa de su arquitectura:
- ACK aprovisiona servicios nativos de AWS (DynamoDB, API Gateway, Route 53, EKS, RDS, S3) con mapeo directo de API de AWS
- Crossplane maneja composiciones complejas (Lambda con IAM, ECS con networking, SageMaker con seguridad) que requieren coordinación de múltiples recursos
- Kubernetes nativo ejecuta automatización post-aprovisionamiento (inyección de configuración, verificaciones de salud, flujos de trabajo personalizados) que no se mapea a recursos de nube
- Kro orquesta los tres, resolviendo dependencias entre controladores automáticamente
Esta estrategia de composición elimina la restricción de «elegir una sola herramienta». Cada controlador hace lo que mejor sabe hacer, y Kro los coordina declarativamente. El resultado: puede arquitectar cualquier patrón cloud-native usando la mejor herramienta para cada componente.
Recursos compartidos: El multiplicador de escalabilidad
Desplegar recursos de plataforma una vez (CloudFront, Cognito, roles IAM, VPCs, service meshes) y referenciarlos desde todas las aplicaciones transforma la economía de despliegue:
- Primera aplicación: 50 minutos (aprovisionar todo)
- Segunda aplicación: 8 minutos (referenciar recursos compartidos)
- Aplicación 200: 8 minutos (mismo patrón, misma velocidad)
Esta arquitectura de recursos compartidos es lo que hace que el patrón escale. Sin ella, cada aplicación espera por recursos de aprovisionamiento lento. Con ella, las aplicaciones se despliegan en paralelo a velocidad consistente, independientemente de la arquitectura.
La victoria de la ingeniería de plataforma
Para equipos que construyen Plataformas Internas de Desarrollo, las Composiciones Híbridas de Kro proporcionan:
- Flexibilidad arquitectónica: Mismo patrón para serverless, contenedores, pipelines de datos, plataformas de ML
- Experiencia universal del desarrollador: Misma interfaz para todos los escenarios de despliegue y arquitecturas
- Simplicidad operativa: Un RGD define stacks completos, eliminando scripts de orquestación
- Velocidad de despliegue: 5-8 minutos desde commit hasta stack listo para producción
- Mejores prácticas integradas: Seguridad, networking, observabilidad arquitectadas en los patrones
El camino a seguir
Si está construyendo infraestructura en Kubernetes—ya sea serverless, en contenedores, orientada a datos o enfocada en ML—considere este patrón:
- Comience con recursos compartidos: Despliegue componentes de plataforma una vez (networking, seguridad, observabilidad)
- Diseñe para la flexibilidad: Use expresiones CEL para soportar múltiples escenarios de despliegue
- Componga, no elija: Combine ACK, Crossplane y Kubernetes nativo basándose en requisitos arquitectónicos
- Deje que Kro orqueste: Defina dependencias declarativas, permita que Kro maneje el orden de aprovisionamiento
El resultado: un RGD, stack completo, múltiples casos de uso, cualquier arquitectura, cero orquestación manual.
Más allá de serverless
Este blog demuestra las Composiciones Híbridas de Kro atraves una arquitectura serverless como patrón común. Pero los principios aplican universalmente:
- Plataformas de contenedores: Lambda con ECS/EKS, API Gateway con ALB, DynamoDB con RDS—mismo patrón de orquestación
- Plataformas de datos: Recursos de aplicación con EMR, Glue, Athena—mismo enfoque de composición
- Plataformas de ML: Reemplace API con endpoints de SageMaker, almacenamiento con feature stores—misma flexibilidad
La arquitectura cambia. El patrón de orquestación permanece constante. Ese es el poder de las Composiciones Híbridas de Kro.
Las Composiciones Híbridas de Kro están son compatibles con GitOps y escalan de 0 a más de 100 aplicaciones sin cambios arquitectónicos. No se trata solo de despliegues más rápidos o menos recursos—se trata de arquitectar patrones de infraestructura que se adaptan a las necesidades de su organización, ya sea que esté construyendo APIs serverless hoy, microservicios en contenedores mañana, o plataformas de inferencia de ML el próximo trimestre.
Un patrón. Múltiples arquitecturas. Stacks completos. Orquestación universal.
Recursos adicionales
- Repositorio de ejemplo: https://github.com/aws-samples/sample-kro-serverless-app-stack
- Documentación de Kro: https://kro.run/docs
- Documentación de ACK: https://aws-controllers-k8s.github.io/community/
- Documentación de Crossplane: https://docs.crossplane.io/
Sobre el autor
 |
Jhon Guzmán es Senior Geo Specialist Solutions Architect en AWS, parte del equipo WWSO cubriendo el Norte de Latinoamérica y México. Aporta amplia experiencia en soluciones de contenedores en AWS y tecnologías cloud-native, con enfoque particular en modernización de aplicaciones con Kubernetes e ingeniería de plataformas. Con más de 20 años de experiencia en soluciones empresariales de TI, Jhon ha ayudado a clientes y socios en Latinoamérica a adoptar arquitecturas cloud modernas. |