- ¿Qué es la computación en la nube?›
- Centro de conceptos de computación en la nube›
- Machine Learning
¿Cuál es la diferencia entre el ML y el aprendizaje profundo?
¿Cuál es la diferencia entre el ML y el aprendizaje profundo?
El machine learning (ML) es la ciencia que se encarga de entrenar un programa o sistema informático para que lleve a cabo tareas sin instrucciones explícitas. Los sistemas informáticos utilizan algoritmos de ML para procesar grandes cantidades de datos, identificar patrones de datos y predecir resultados precisos para escenarios nuevos o desconocidos. El aprendizaje profundo es un subconjunto del ML que utiliza estructuras algorítmicas específicas llamadas redes neuronales, basadas en el cerebro humano. Los métodos de aprendizaje profundo intentan automatizar tareas más complejas que normalmente requieren inteligencia humana. Por ejemplo, puede usar el aprendizaje profundo para describir imágenes, traducir documentos o transcribir un archivo de sonido a texto.
¿Cuáles son las similitudes entre el ML y el aprendizaje profundo?
Puede utilizar tanto el machine learning (ML) como el aprendizaje profundo para identificar patrones en los datos. Ambos se basan en conjuntos de datos para entrenar algoritmos que se basan en modelos matemáticos complejos. Durante el entrenamiento, los algoritmos encuentran correlaciones entre las salidas y las entradas conocidas. A continuación, los modelos pueden generar o predecir automáticamente las salidas en función de entradas desconocidas. A diferencia de la programación tradicional, el proceso de aprendizaje también es automático con una mínima intervención humana.
Estas son otras similitudes entre el ML y el aprendizaje profundo.
Técnicas de inteligencia artificial
Tanto el ML como el aprendizaje profundo son subconjuntos de la ciencia de datos y la inteligencia artificial (IA). Ambos pueden completar tareas computacionales complejas que, de otro modo, requerirían mucho tiempo y recursos mediante técnicas de programación tradicionales.
Base estadística
Tanto el ML como el aprendizaje profundo utilizan métodos estadísticos para entrenar sus algoritmos con conjuntos de datos. Estas técnicas incluyen análisis de regresión, árboles de decisión, álgebra lineal y cálculo. Tanto los expertos en ML como los expertos en aprendizaje profundo entienden bien las estadísticas.
Conjuntos de datos grandes
Tanto el ML como el aprendizaje profundo requieren grandes conjuntos de datos de entrenamiento de calidad para hacer predicciones más precisas. Por ejemplo, un modelo de ML requiere entre 50 y 100 puntos de datos por característica, mientras que un modelo de aprendizaje profundo comienza con miles de puntos de datos por característica.
Aplicaciones variadas y de amplio alcance
Las soluciones de aprendizaje profundo y ML resuelven problemas complejos en todos los sectores y aplicaciones. Se necesitaría mucho más tiempo para resolver u optimizar este tipo de problemas si usara métodos estadísticos y de programación tradicionales.
Requisitos de potencia computacional
Para entrenar y ejecutar algoritmos de ML se requiere una potencia de cálculo considerable, y los requisitos computacionales son aún mayores para el aprendizaje profundo debido a su mayor complejidad. La disponibilidad de ambos para uso personal ahora es posible gracias a los recientes avances en la potencia de cálculo y los recursos en la nube.
Mejora gradual
A medida que las soluciones de aprendizaje profundo y ML ingieren más datos, se vuelven más precisas en el reconocimiento de patrones. Cuando se añade una entrada al sistema, el sistema mejora al emplearla como punto de datos para el entrenamiento.
¿Qué limitaciones del machine learning condujeron a la evolución del aprendizaje profundo?
El machine learning (ML) tradicional requiere una interacción humana significativa a través de la ingeniería de características para producir resultados. Por ejemplo, si está entrenando un modelo de ML para clasificar imágenes de perros y gatos, tendrá que configurarlo manualmente para que reconozca características como la forma de los ojos, la forma de la cola, la forma de las orejas, el contorno de la nariz, etc.
Dado que el objetivo del ML es reducir la necesidad de intervención humana, las técnicas de aprendizaje profundo eliminan la necesidad de que los humanos etiqueten los datos en cada paso.
Si bien el aprendizaje profundo existe desde hace muchas décadas, a principios de la década de los 2000, científicos como Yann LeCun, Yoshua Bengio y Geoffrey Hinton exploraron este campo con más detalle. Si bien los científicos promovieron el aprendizaje profundo, los conjuntos de datos grandes y complejos fueron limitados durante este tiempo y la potencia de procesamiento necesaria para entrenar los modelos era cara. Durante los últimos 20 años, estas condiciones han mejorado y el aprendizaje profundo ahora es viable desde el punto de vista comercial.
Diferencias clave: machine learning y aprendizaje profundo
El aprendizaje profundo es un subconjunto del machine learning (ML). Puede considerarlo como una técnica avanzada de ML. Cada uno tiene una amplia variedad de aplicaciones. Sin embargo, las soluciones de aprendizaje profundo exigen más recursos: conjuntos de datos más grandes, requisitos de infraestructura y costos posteriores.
Estas son otras diferencias entre el ML y el aprendizaje profundo.
Casos de uso previstos
La decisión de utilizar el ML o el aprendizaje profundo depende del tipo de datos que necesite procesar. El ML identifica patrones a partir de datos estructurados, como los sistemas de clasificación y recomendación. Por ejemplo, una empresa puede emplear el ML para predecir cuándo un cliente se dará de baja basándose en los datos de abandono de clientes anteriores.
Por otro lado, las soluciones de aprendizaje profundo son más adecuadas para datos no estructurados, donde se necesita un alto nivel de abstracción para extraer características. Las tareas del aprendizaje profundo incluyen la clasificación de imágenes y el procesamiento del lenguaje natural, donde es necesario identificar las complejas relaciones entre los objetos de datos. Por ejemplo, una solución de aprendizaje profundo puede analizar las menciones en las redes sociales para determinar la opinión de los usuarios.
Enfoque de resolución de problemas
El ML tradicional suele requerir ingeniería de características, en la que los humanos seleccionan y extraen manualmente las características de los datos sin procesar y les asignan pesos. Por el contrario, las soluciones de aprendizaje profundo llevan a cabo la ingeniería de características con una mínima intervención humana.
La arquitectura de redes neuronales del aprendizaje profundo es más compleja por su diseño. La forma en que las soluciones de aprendizaje profundo aprenden se basa en el funcionamiento del cerebro humano, con las neuronas representadas por nodos. Las redes neuronales profundas comprenden tres o más capas de nodos, incluidos los nodos de las capas de entrada y salida.

En el aprendizaje profundo, cada nodo de la red neuronal asigna pesos a cada característica de forma autónoma. La información fluye a través de la red en dirección ascendente desde la entrada hasta la salida. A continuación, se calcula la diferencia entre la salida prevista y la salida real. Y este error se retropropaga a través de la red para ajustar los pesos de las neuronas.
Debido al proceso de ponderación automático, a la profundidad de los niveles de la arquitectura y a las técnicas utilizadas, se necesita un modelo para resolver muchas más operaciones en el aprendizaje profundo que en el ML.
Métodos de entrenamiento
El ML tiene cuatro métodos de entrenamiento principales: aprendizaje supervisado, aprendizaje no supervisado, aprendizaje semisupervisado y aprendizaje por refuerzo. Otros métodos de capacitación incluyen el aprendizaje por transferencia y el aprendizaje autosupervisado.
Por el contrario, los algoritmos de aprendizaje profundo utilizan varios tipos de métodos de entrenamiento más complejos. Estas incluyen las redes neuronales convolucionales, las redes neuronales recurrentes, las redes generativas conflictivas y los autocodificadores.
Lea acerca de Generative Adversarial Networks (GAN)»
Rendimiento
Tanto el ML como el aprendizaje profundo tienen casos de uso específicos en los que funcionan mejor que los demás.
Para tareas más sencillas, como identificar nuevos mensajes spam entrantes, el ML es adecuado y, por lo general, superará a las soluciones de aprendizaje profundo. Para tareas más complejas, como el reconocimiento de imágenes médicas, las soluciones de aprendizaje profundo superan a las soluciones de ML, ya que pueden identificar anomalías que no son visibles para el ojo humano.
Participación humana
Tanto las soluciones de ML como las de aprendizaje profundo requieren una participación humana significativa para funcionar. Alguien tiene que definir un problema, preparar los datos, seleccionar y entrenar un modelo y, a continuación, evaluar, optimizar e implementar una solución.
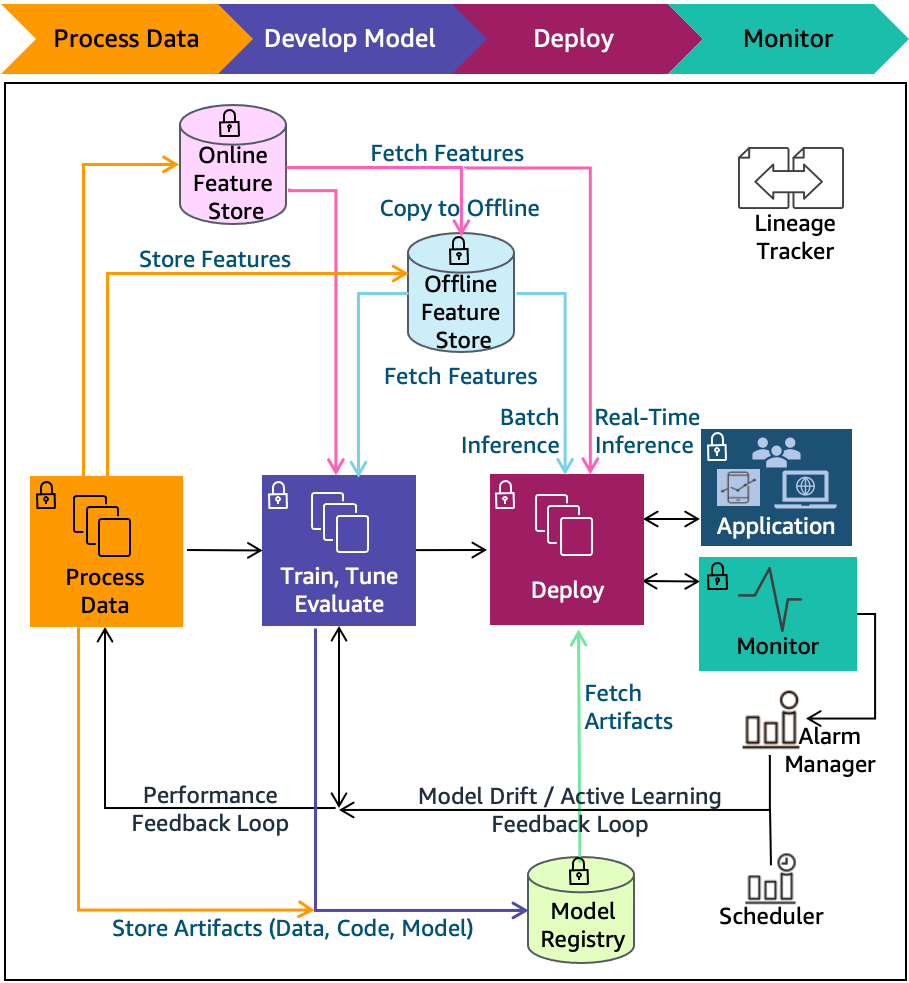
Los modelos de ML pueden ser más fáciles de interpretar para las personas, ya que se derivan de modelos matemáticos más simples, como los árboles de decisión.
Por el contrario, los modelos de aprendizaje profundo requieren una cantidad significativa de tiempo para que alguien los analice en detalle, porque los modelos son matemáticamente complejos. Dicho esto, la forma en que las redes neuronales aprenden elimina la necesidad de que las personas etiqueten los datos. Puede reducir aún más la participación humana si elige modelos y plataformas previamente entrenados.
Requisitos de infraestructura
Como son más complejos y requieren conjuntos de datos más grandes, los modelos de aprendizaje profundo exigen más capacidad de almacenamiento y computación que los modelos de ML. Si bien los datos y modelos de ML pueden ejecutarse en una sola instancia o en un clúster de servidores, un modelo de aprendizaje profundo suele requerir clústeres de alto rendimiento y otra infraestructura sustancial.
Los requisitos de infraestructura para las soluciones de aprendizaje profundo pueden generar costos significativamente más altos que el ML. Es posible que la infraestructura in situ no sea práctica ni rentable para ejecutar soluciones de aprendizaje profundo. Puede utilizar una infraestructura escalable y servicios de aprendizaje profundo totalmente gestionados para controlar los costos.
Resumen de las diferencias: machine learning vs. aprendizaje profundo
|
Machine Learning |
Aprendizaje profundo |
|
|
¿Cómo lo haces? |
ML es una metodología de inteligencia artificial (IA). No todo el ML se puede considerar aprendizaje profundo. |
El aprendizaje profundo es una metodología de ML avanzada. Todo el aprendizaje profundo es ML. |
|
Más adecuada para lo siguiente: |
El ML es mejor para tareas bien definidas con datos estructurados y etiquetados. |
El aprendizaje profundo es mejor para tareas complejas que requieren que las máquinas den sentido a los datos no estructurados. |
|
Enfoque de resolución de problemas |
El ML resuelve problemas mediante la estadística y las matemáticas. |
El aprendizaje profundo combina la estadística y las matemáticas con una arquitectura de redes neuronales. |
|
Formación |
Debe seleccionar y extraer manualmente las características de los datos sin procesar y asignar pesos para entrenar un modelo de ML. |
Los modelos de aprendizaje profundo pueden aprender por sí mismos mediante la retroalimentación de errores conocidos. |
|
Recursos necesarios |
El ML es menos complejo y tiene un volumen de datos más bajo. |
El aprendizaje profundo es más complejo con un volumen de datos muy alto. |
¿Cómo puede AWS satisfacer sus necesidades de machine learning y aprendizaje profundo?
Hay muchas soluciones de aprendizaje automático (ML) y aprendizaje profundo (DL) en Amazon Web Services (AWS). Le permiten integrar la inteligencia artificial (IA) en todas sus aplicaciones y casos prácticos.
Para el aprendizaje automático tradicional, Amazon SageMaker es una plataforma completa para crear, entrenar e implementar algoritmos en una infraestructura de nube potente y escalable.
Para sus necesidades de aprendizaje profundo, puede utilizar servicios completamente administrados como estos:
- Amazon Comprehend le ayuda a descubrir información valiosa de cualquier texto mediante el procesamiento del lenguaje natural, o Amazon Comprehend Medical para textos médicos más complejos.
- Amazon Fraud Detector le ayuda a detectar operaciones fraudulentas basándose en registros históricos.
- Amazon Lex le ayuda a crear chatbots e interfaces conversacionales inteligentes.
- Amazon Personalize le ayuda a segmentar rápidamente a los clientes y a crear sistemas de recomendación seleccionados.
- Amazon Polly le ayuda a producir palabras habladas con un sonido natural a partir del texto de entrada en docenas de idiomas.
- Amazon Rekognition le ayuda con el reconocimiento de imágenes y el análisis de vídeo prediseñados.
- Amazon Textract le ayuda a extraer texto de cualquier documento escrito a mano o generado por ordenador.
Comience con el aprendizaje automático y el aprendizaje profundo creando una cuenta de AWS gratuita hoy mismo.