Clase de almacenamiento Amazon S3 Intelligent-Tiering
Automatiza el ahorro en almacenamiento mediante el traslado de datos según los cambios en los patrones de acceso
Información general
Amazon S3 Intelligent-Tiering es la única clase de almacenamiento en la nube que ofrece ahorro automático en costos de almacenamiento cuando cambian los patrones de acceso a los datos, sin afectar el rendimiento ni generar cargas operativas adicionales. La clase de almacenamiento Amazon S3 Intelligent-Tiering está diseñada para optimizar los costos de almacenamiento al transferir automáticamente los datos al nivel de acceso más rentable cuando cambian los patrones de acceso. Por un cargo mensual reducido por monitoreo y automatización, S3 Intelligent-Tiering analiza los patrones de acceso y transfiere automáticamente los objetos no accedidos a niveles de acceso más económicos. Desde el lanzamiento de S3 Intelligent-Tiering en 2018, los clientes han ahorrado más de 4000 millones de USD en costos de almacenamiento al utilizar S3 Intelligent-Tiering en lugar de Amazon S3 Standard.
S3 Intelligent-Tiering es la clase de almacenamiento ideal para datos con patrones de acceso desconocidos, cambiantes o impredecibles, sin importar el tamaño del objeto ni el período de retención. Puede utilizar S3 Intelligent-Tiering como clase de almacenamiento predeterminada para prácticamente cualquier carga de trabajo, en especial para lagos de datos, análisis de datos, nuevas aplicaciones y contenido generado por usuarios.

Beneficios
Ahorros automáticos mediante la optimización de costos de almacenamiento según los patrones de acceso
El primer y único almacenamiento en la nube que optimiza automáticamente los costos
11 nueves de durabilidad
El almacenamiento en la nube de menor costo con nivel de acceso Deep Archive de activación opcional
Amazon S3 Intelligent-Tiering
La clase de almacenamiento Amazon S3 Intelligent-Tiering se ha diseñado para optimizar los costos mediante la migración automática de los datos al nivel de acceso más rentable cuando cambian los patrones de acceso. Por un pequeño cargo mensual de monitoreo y automatización de objetos, S3 Intelligent-Tiering monitorea los patrones de acceso y traslada de forma automática los objetos a los que no se accedió a los niveles de acceso de menor costo. S3 Intelligent-Tiering ofrece ahorros automáticos en los costos de almacenamiento en tres niveles de acceso de rendimiento alto y latencia baja. En el caso de los datos a los que se puede acceder de manera asíncrona, puede activar las capacidades de archivado automáticas dentro de la clase de almacenamiento S3 Intelligent-Tiering. No hay cargos de recuperación en S3 Intelligent-Tiering. Si después se accede a un objeto en el nivel de acceso Poco frecuente o Instantáneo al archivo, se devuelve automáticamente al nivel de acceso Frecuente. No se aplican cargos adicionales por cambio de nivel cuando los objetos se transfieren entre niveles de acceso dentro de la clase de almacenamiento S3 Intelligent-Tiering.

Más información sobre S3 Intelligent-Tiering
- Los niveles de acceso Frecuente, Poco Frecuente y Archive Instant Access ofrecen el mismo rendimiento de baja latencia y alto rendimiento que S3 Standard
- El nivel de acceso Poco frecuente ahorra hasta un 40 % en costos de almacenamiento
- El nivel de acceso instantáneo al archivo ahorra hasta un 68 % en costos de almacenamiento
- Capacidades de archivado asincrónico de activación opcional para objetos que dejan de accederse con frecuencia
- Los niveles Archive Access y Deep Archive Access ofrecen el mismo rendimiento que S3 Glacier Flexible Retrieval y S3 Glacier Deep Archive, y permiten ahorrar hasta un 95 % en objetos de acceso poco frecuente
- Diseñado para una durabilidad del 99,999999999 % de los objetos en múltiples zonas de disponibilidad y una disponibilidad del 99,9 % en un año determinado.
- Sin cargas operativas, sin cargos por ciclos de vida, sin costos por recuperación y sin duración mínima de almacenamiento.

Cómo funciona: S3 Intelligent-Tiering
La clase de almacenamiento Amazon S3 Intelligent-Tiering está diseñada para optimizar los costos de almacenamiento al transferir automáticamente los datos al nivel de acceso más rentable cuando cambian los patrones de acceso. S3 Intelligent-Tiering almacena automáticamente los objetos en tres niveles de acceso: uno optimizado para acceso frecuente, otro de menor costo optimizado para acceso poco frecuente y un nivel de muy bajo costo optimizado para datos de acceso esporádico. Por una pequeña tarifa mensual de monitoreo y automatización por objeto, S3 Intelligent-Tiering traslada los objetos a los que no se accedió durante 30 días consecutivos al nivel de acceso poco frecuente para ahorrar un 40 %. Después de 90 días sin acceso, se trasladan al nivel de acceso instantáneo al archivo y se ahorra un 68 %. Si los objetos se acceden posteriormente, S3 Intelligent-Tiering los traslada nuevamente al nivel de acceso frecuente. Para maximizar el ahorro en almacenamiento de acceso poco frecuente, consulte los diagramas adicionales donde se muestran los niveles de acceso asincrónico de activación opcional Archive y Deep Archive en S3 Intelligent-Tiering.
S3 Intelligent-Tiering no aplica cargos por recuperación. S3 Intelligent-Tiering no tiene un tamaño mínimo requerido para los objetos, pero los objetos menores de 128 KB no califican para la transferencia automática entre niveles. Estos objetos más pequeños se pueden almacenar, pero siempre se facturan según las tarifas del nivel de acceso frecuente y no generan el cargo por monitoreo y automatización. Consulte la página de precios de Amazon S3 para obtener más información. Para obtener más información, visite la guía del usuario de S3 Intelligent-Tiering.
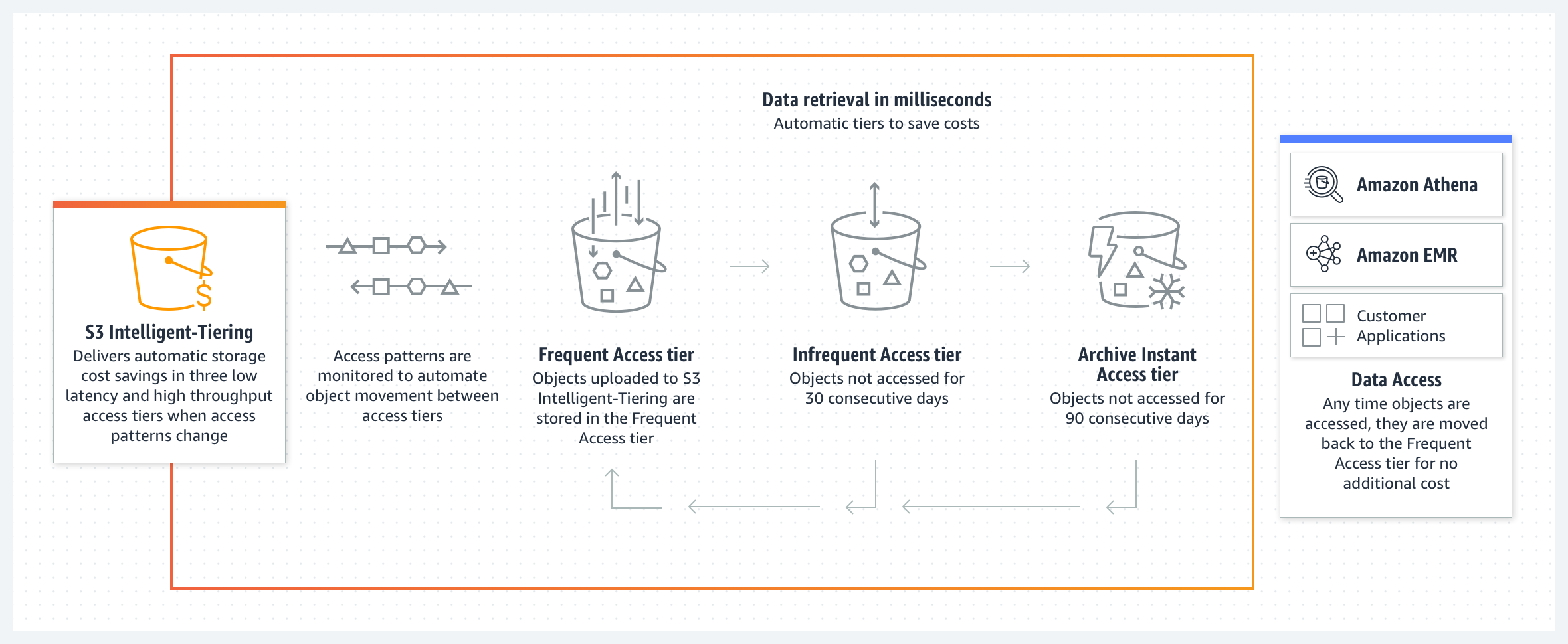
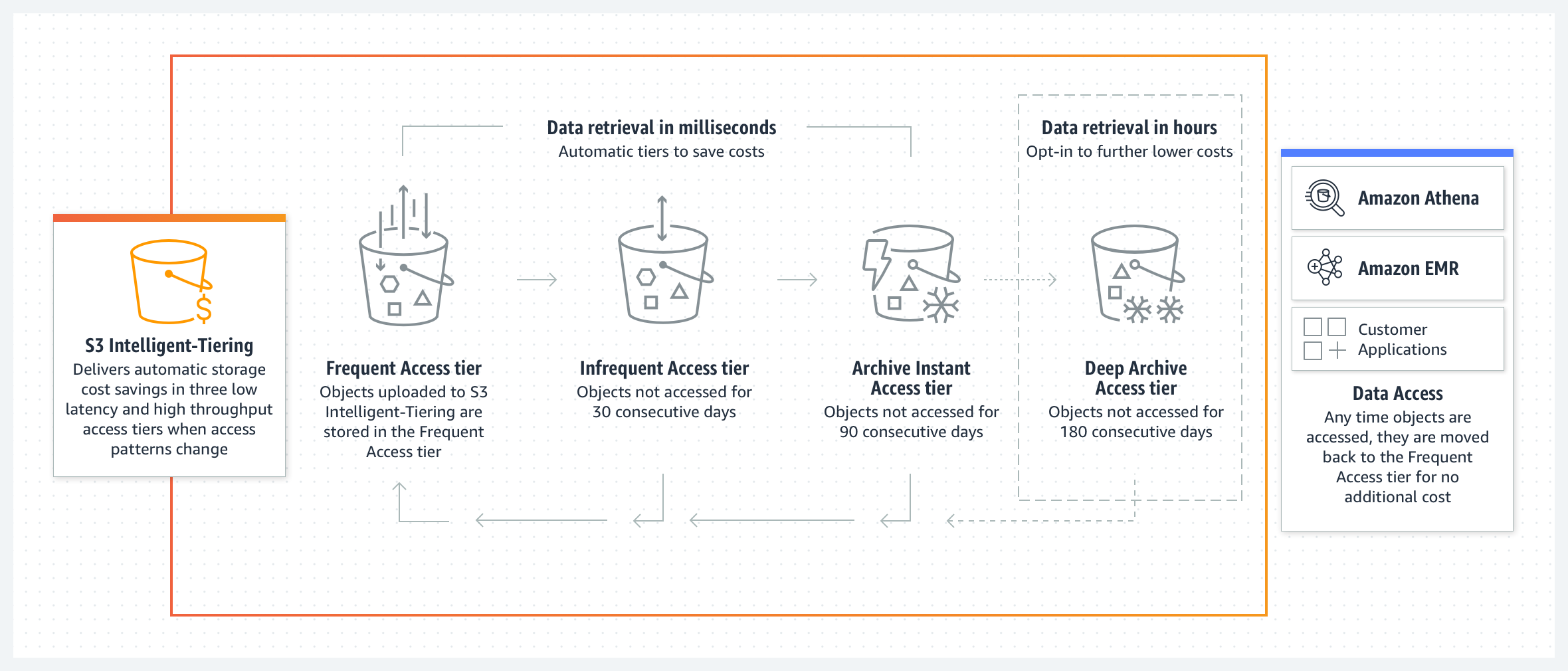
La clase de almacenamiento Amazon S3 Intelligent-Tiering está diseñada para optimizar los costos de almacenamiento al mover automáticamente los datos al nivel de acceso más rentable cuando cambian los patrones de acceso. S3 Intelligent-Tiering almacena objetos de forma automática en tres niveles de acceso: un nivel optimizado para el acceso frecuente, un nivel de bajo costo optimizado para el acceso poco frecuente y otro nivel muy económico optimizado para los datos a los que rara vez se accede. Por una pequeña tarifa mensual de monitoreo y automatización por objeto, S3 Intelligent-Tiering traslada los objetos a los que no se accedió durante 30 días consecutivos al nivel de acceso poco frecuente para ahorrar un 40 %. Después de 90 días sin acceso, se trasladan al nivel de acceso instantáneo al archivo y se ahorra un 68 %. Para ahorrar más en los datos que no requieren una recuperación inmediata, puede activar el nivel opcional de acceso de archivo profundo asíncrono. Cuando este se activa, los objetos a los que no se accede durante 180 días se trasladan al nivel de acceso de archivo profundo con un ahorro en los costos de almacenamiento de hasta el 95 %. Si se accede a los objetos más adelante, S3 Intelligent-Tiering migrará los objetos nuevamente a la capa de acceso frecuente. Si el objeto que desea recuperar se encuentra en el nivel opcional Deep Archive, antes de poder recuperarlo debe restaurar una copia con RestoreObject. Para obtener información sobre la recuperación de objetos archivados, consulte Recuperación de objetos archivados.
S3 Intelligent-Tiering no aplica cargos por recuperación. S3 Intelligent-Tiering no tiene un tamaño de objeto mínimo aceptable, pero los objetos de menos de 128 KB no son elegibles para la designación automática de niveles. Estos objetos más pequeños se pueden almacenar, pero siempre se facturan según las tarifas del nivel de acceso frecuente y no generan el cargo por monitoreo y automatización. Consulte la página de precios de Amazon S3 para obtener más información. Para obtener más información, visite la guía del usuario de S3 Intelligent-Tiering.
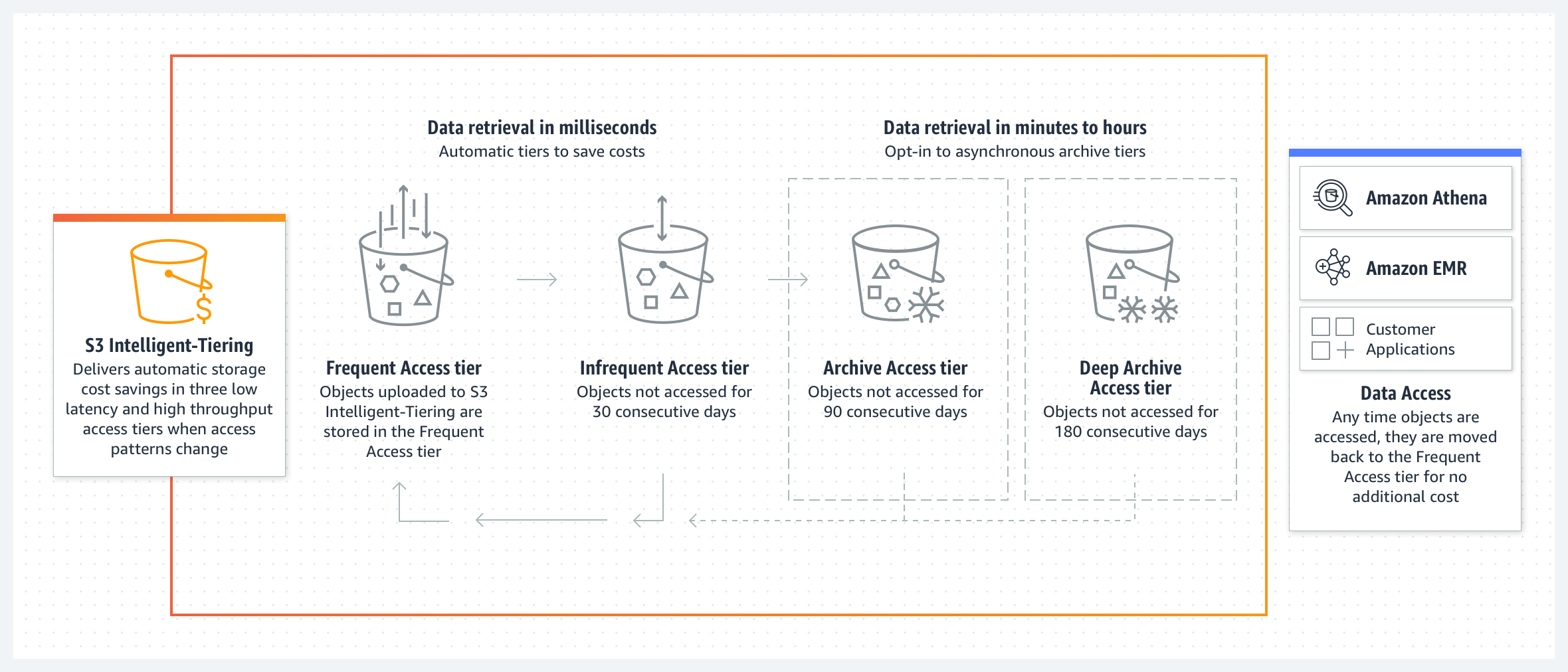
La clase de almacenamiento Amazon S3 Intelligent-Tiering se ha diseñado para optimizar los costos mediante la migración automática de los datos al nivel de acceso más rentable cuando cambian los patrones de acceso. S3 Intelligent-Tiering almacena objetos de forma automática en tres niveles de acceso: un nivel optimizado para el acceso frecuente, un nivel de bajo costo optimizado para el acceso poco frecuente y otro nivel muy económico optimizado para los datos a los que rara vez se accede. Por una pequeña tarifa mensual de monitoreo y automatización por objeto, S3 Intelligent-Tiering traslada los objetos a los que no se accedió durante 30 días consecutivos al nivel de acceso poco frecuente para ahorrar un 40 %. Después de 90 días sin acceso, se trasladan al nivel de acceso instantáneo al archivo y se ahorra un 68 %. Para ahorrar más en los datos que no requieren una recuperación inmediata, puede activar los niveles opcionales de acceso de archivo profundo y de acceso de archivo asíncronos. Cuando estos se activan, los objetos a los que no se accede durante 90 días se trasladan directamente al nivel de acceso de archivo (evitando el nivel automático de acceso instantáneo al archivo) para ahorrar un 71 %, y al nivel de acceso de archivo profundo después de 180 días, con un ahorro de costos de almacenamiento de hasta el 95 %. Si se accede a los objetos más adelante, S3 Intelligent-Tiering migrará los objetos nuevamente a la capa de acceso frecuente. Si el objeto que desea recuperar se encuentra en los niveles opcionales Archive Access o Deep Archive, primero debe restaurar una copia con RestoreObject antes de poder recuperarlo. Para obtener información sobre la recuperación de objetos archivados, consulte Recuperación de objetos archivados.
S3 Intelligent-Tiering no aplica cargos por recuperación. S3 Intelligent-Tiering no tiene un tamaño de objeto mínimo aceptable, pero los objetos de menos de 128 KB no son elegibles para la designación automática de niveles. Estos objetos más pequeños se pueden almacenar, pero siempre se facturan según las tarifas del nivel de acceso frecuente y no generan el cargo por monitoreo y automatización. Consulte la página de precios de Amazon S3 para obtener más información. Para obtener más información, visite la guía del usuario de S3 Intelligent-Tiering.
Shutterstock
Shutterstock, fundada en 2003, es una plataforma creativa líder a nivel mundial para marcas y compañías de medios transformadoras. Gracias a una comunidad de más de 2 millones de colaboradores, el catálogo de Shutterstock ha superado los 405 millones de imágenes y los 25 millones de videos.
Blog: Shutterstock transforma la infraestructura de TI y ahorra un 60 % en costos de almacenamiento con Amazon S3
Sesión de re:Invent: La revolución del almacenamiento en la nube de Shutterstock con Amazon S3
Cómo Shutterstock aplica las previsiones para garantizar que los ahorros en costos se reinviertan en el negocio
“Los ahorros obtenidos al utilizar S3 Intelligent-Tiering, de hasta un 60 % en algunos buckets, nos permitieron reinvertir en nuestra infraestructura de almacenamiento y replicar nuestro entorno de almacenamiento en una segunda región de AWS. En poco tiempo, experimentamos varias mejoras importantes, que aumentaron el rendimiento y redujeron el costo de Amazon S3. Esto no requirió una renovación invasiva importante por nuestra parte, como lo habría hecho si nos hubiéramos quedado en las instalaciones. El aumento del uso del acceso a nuestros buckets también se ve superado por las mejoras de rendimiento en S3, gracias a su innovación continua. Para nuestra satisfacción, muchas de nuestras adquisiciones recientes también utilizan Amazon S3, lo que facilita una integración óptima con nuestras arquitecturas existentes y ha dado lugar a conversaciones productivas sobre transformación empresarial con nuestros nuevos colegas. Además, esto ha generado un cambio en el enfoque del equipo, que pasó de la planificación de recursos de almacenamiento a la innovación real”.
Chris S. Borys, gerente de equipo de servicios de almacenamiento en la nube, Shutterstock

Illumina
Illumina es un desarrollador, fabricante y comerciante líder de herramientas y sistemas de ciencias biológicas para el análisis genético a gran escala. Fundada en 1998, Illumina ofrece una gama completa de software, instrumentos y servicios que ayudan a sus clientes a analizar los genomas, avanzar rápidamente en la investigación de las ciencias biológicas y mejorar la salud humana. Los clientes de Illumina utilizan sus soluciones de secuenciación genética para acelerar la obtención de información terapéutica y farmacéutica.
“Después de solo tres meses de utilizar S3 Intelligent-Tiering, Illumina comenzó a registrar ahorros mensuales significativos en costos. Por cada TB de datos, la empresa ahorra un 60 % en costos de almacenamiento. “Creo que es el mayor retorno de inversión que hemos visto”, afirma Al Maynard. Además, Illumina puede ofrecer a los clientes acceso casi instantáneo a miles de secuencias genómicas completas a un costo bajo y competitivo, lo que permite acelerar los procesos de investigación y desarrollo”.
Al Maynard, director de ingeniería de software, Illumina
Caso práctico: Illumina redujo un 89 % las emisiones de carbono y disminuyó los costos de almacenamiento de datos con AWS »

Torc Robotics
Torc Robotics, líder mundial y pionera en el transporte por carretera, ofrece un software completo para vehículos autónomos y una solución de integración. En la actualidad, la empresa se centra en la comercialización de camiones autónomos. Con el rápido crecimiento de Torc Robotics, su almacenamiento en S3 creció rápidamente hasta alcanzar petabytes de datos en buckets de S3 que su equipo de adquisición de datos de vehículos quería optimizar. El uso de S3 Intelligent-Tiering por parte de Torc Robotics genera automáticamente un ahorro mensual del 24 % en costos de almacenamiento, sin afectar el rendimiento de las aplicaciones ni requerir trabajo adicional de desarrollo.
Blog: Cómo reduce Torc Robotics los costos de almacenamiento con S3 Intelligent-Tiering
Sesión de re:Invent: Almacenamiento mejor, más rápido y a menor costo: Optimización de Amazon S3
Torc Robotics logra un almacenamiento más eficiente, rápido y económico con S3
“Dimos prioridad a la optimización del uso de Amazon S3 para respaldar el crecimiento futuro. Sin embargo, no teníamos visibilidad sobre el contenido y uso de los buckets, y necesitábamos una solución segura que pudiéramos implementar en toda Torc Robotics sin afectar el rendimiento. S3 Intelligent-Tiering fue nuestra “solución sencilla” y nos permitió avanzar al ritmo que requeríamos sin agregar ciclos de desarrollo”.
Justin Brown, director de adquisición de datos de vehículos, Torc Robotics

Electronic Arts
Electronic Arts (EA) es líder mundial en entretenimiento digital interactivo. EA desarrolla videojuegos que llegan a más de 450 millones de jugadores en consola, PC y dispositivos móviles, incluidas franquicias líderes como FIFA, Madden y Battlefield. EA ha pasado de ser un entorno dominado por Hadoop a uno centrado en un lago de datos basado en el almacenamiento en la nube de AWS en Amazon S3, que incluye S3 Glacier Flexible Retrieval para archivar datos y realizar copias de seguridad a largo plazo. Para respaldar nuestros principales videojuegos, nuestros sistemas centrales de telemetría administran de forma habitual decenas de petabytes, decenas de miles de tablas y más de 2000 millones de objetos. EA utilizó S3 Intelligent-Tiering para optimizar los costos de almacenamiento del lago de datos con patrones de acceso variables.
“Con pocos o ningún cambio en nuestras herramientas existentes, logramos reducir los costos de almacenamiento en un 30 % con S3 Intelligent-Tiering para datos con patrones de acceso impredecibles. Esto ha permitido que nuestro equipo de infraestructura de datos se enfoque en nuestras competencias clave relacionadas con los lanzamientos de videojuegos. Nuestra colaboración con AWS nos da la posibilidad de concentrarnos aún más en hacer crecer y satisfacer a nuestros clientes para seguir inspirando al mundo a través del juego”.
Sundeep Narravula, director técnico principal, EA

Stripe
Stripe es una empresa de tecnología que crea una infraestructura económica para Internet. Empresas de todos los tamaños, desde empresas emergentes hasta empresas que cotizan en bolsa, utilizan el software Stripe para aceptar pagos y gestionar sus negocios en línea.
“Desde el lanzamiento de S3 Intelligent-Tiering en 2018, hemos ahorrado automáticamente alrededor de un 30 % al mes en nuestros costos de almacenamiento sin afectar al rendimiento ni tener que analizar nuestros datos. Con el nuevo nivel Archive Instant Access, prevemos aprovechar automáticamente las ventajas del precio del almacenamiento de archivos y, al mismo tiempo, conservar la capacidad de acceder a nuestros datos de forma instantánea cuando sea necesario”.
Kalyana Chadalavada, director de eficiencia, Stripe
Sesión de re:Invent: Modernice su archivo de datos con Amazon S3, con la participación de Stripe »

GRAIL
GRAIL es una empresa de atención médica que se centra en salvar vidas y mejorar la salud al ser pionera en nuevas tecnologías para la detección temprana del cáncer. GRAIL ha creado una organización multidisciplinaria de científicos, ingenieros y médicos. Utilizan el poder de la secuenciación de nueva generación, estudios clínicos a escala poblacional y tecnologías de punta en computación y ciencia de datos para superar uno de los mayores desafíos de la medicina.
“Trasladamos la mayor parte de nuestros datos a S3 Intelligent-Tiering, lo que generó un ahorro del 40 % por gigabyte en costos de almacenamiento”.
Olga Ignatova, directora de desarrollo de software, GRAIL
Caso práctico: GRAIL desarrolla una prueba pionera de detección temprana de múltiples tipos de cáncer con AWS »

CineSend
CineSend es un proveedor líder de herramientas de administración de activos multimedia en la nube para la industria del cine y la televisión. CineSend ofrece un portafolio de soluciones de software listas para usar y personalizadas para estudios, productores independientes y distribuidores de cine, con el fin de administrar flujos de trabajo de entrega de contenido multimedia de alta calidad,
“El uso de S3 Intelligent-Tiering nos permitió adoptar un modelo de ‘configúrelo y olvídese’ para el contenido multimedia almacenado. Con la confianza de que los archivos a los que se accede con frecuencia y con poca frecuencia están en la clase de almacenamiento adecuada, y de que los costos se mantienen al mínimo de forma eficiente, mi equipo se puede concentrar en nuestra misión: entregar contenido de video seguro en todo el mundo con tecnología de vanguardia”.
D’Arcy Rail-Ip, vicepresidente de tecnología, CineSend
Blog: Cómo CineSend administra el contenido multimedia con S3 Intelligent-Tiering »

Zalando
Zalando, fundada en 2008, es la plataforma en línea líder de Europa para la moda y el estilo de vida con más de 32 millones de clientes activos. Amazon S3 es el pilar de la infraestructura de datos de Zalando y han utilizado las clases de almacenamiento de S3 para optimizar los costos de almacenamiento.
“Estamos ahorrando un 37 % anual en costos de almacenamiento mediante el uso de Amazon S3 Intelligent-Tiering para migrar automáticamente los objetos que no se han tocado en 30 días al nivel de acceso poco frecuente”.
Max Schultze, jefe de ingeniería de datos, Zalando
Blog: Cómo Zalando creó su lago de datos en Amazon S3 »

Amazon Photos
Amazon Photos ofrece almacenamiento ilimitado de fotos y 5 GB de almacenamiento de video a los miembros de Amazon Prime en ocho mercados de todo el mundo. Los clientes utilizan las aplicaciones móviles, web y de escritorio de Amazon Photos para hacer copias de seguridad, revivir y compartir sus recuerdos, y pueden volver a disfrutarlos en dispositivos con pantallas inteligentes de Amazon, como Echo Show y Fire TV.
“Desde el lanzamiento de Amazon Photos, hemos utilizado Amazon S3. Si bien el almacenamiento S3 Standard pudo escalar junto con el crecimiento de nuestra empresa, la necesidad de optimizar los costos y el rendimiento de un volumen de datos grande (y en aumento) representó varios desafíos. Con el lanzamiento de S3 Intelligent-Tiering en 2018, y la incorporación reciente del nivel Archive Instant Access dentro de S3 Intelligent-Tiering, el equipo de Amazon Photos pudo adoptar de inmediato una solución de AWS con pocos o ningún cambio en nuestros servicios existentes, y logró así reducir en más de un 10 % los costos de almacenamiento”.
Arun Kumar Agarwal, director de desarrollo de software de Amazon Photos; Stacie Buckingham, directora sénior de desarrollo de software de Amazon Photos
Blog: Cómo Amazon Photos utiliza Amazon S3 Intelligent-Tiering para reducir significativamente los costos de almacenamiento »

Teespring
Teespring, una plataforma en línea que permite a los creadores convertir ideas únicas en productos personalizados, experimentó un rápido crecimiento comercial y los datos de la empresa también crecieron exponencialmente (a un petabyte) y continuaron aumentando. Teespring, como muchas empresas nativas en la nube, abordó el problema con AWS y almacenó datos específicamente en Amazon S3.
Al utilizar S3 Intelligent-Tiering, Teespring ahora ahorra más del 30 % en costos mensuales de almacenamiento.
Blog: Teespring administra sus datos heredados con Amazon S3

Joyn
El servicio alemán de streaming en directo Joyn GmbH, una empresa conjunta de ProSiebenSat.1 y Discovery, está aprovechando su enorme bóveda de contenido para ofrecer a los suscriptores series y películas del pasado exclusivas e hiperlocales para que disfruten. Para hacerlo posible, Joyn transfirió recientemente más de 3 petabytes (PB) de archivos multimedia de una instalación local a Amazon S3 en menos de tres meses con 40 dispositivos AWS Snowball.
Al utilizar Amazon S3 Intelligent-Tiering, Joyn puede mantener todo su contenido en línea y también optimizar el almacenamiento automáticamente a medida que cambian los patrones de acceso, sin repercusiones en el rendimiento ni gastos operativos generales. El contenido del archivo que genera mucho interés se clasifica en un nivel de acceso frecuente, mientras que el contenido que recibe menos atención se almacena en un nivel de acceso poco frecuente.
“Antes teníamos que ser selectivos con respecto al contenido que recuperábamos de nuestro archivo profundo o, en algunos casos, sobre qué conservar en el archivo, pero ahora la decisión es obvia. Gracias al uso de S3 Intelligent-Tiering, pudimos triplicar nuestro volumen de almacenamiento con el mismo costo total de propiedad (TCO). Es un alivio no tener que pensar más en eliminar contenido para liberar espacio, y si está inactivo, el contenido se ubica en un nivel de acceso poco frecuente o de archivo”.
Stefan Haufe, ingeniero multimedia, Joyn
Blog: Joyn prepara contenido exclusivo para su audiencia con Amazon S3 Intelligent-Tiering y Amazon S3 Glacier »

SimilarWeb
Al utilizar AWS, SimilarWeb administra grandes volúmenes de datos, con los cuales los científicos de datos desarrollan algoritmos para mejorar su plataforma de inteligencia de mercado. Gracias al uso de S3 Intelligent-Tiering, SimilarWeb puede democratizar esos datos para los empleados y ahorrar un 20 % en costos de almacenamiento.
Video: SimilarWeb ahorra un 20 % en costos de almacenamiento con Amazon S3 Intelligent-Tiering

AppsFlyer
AppsFlyer es una plataforma líder de atribución de publicidad móvil y análisis de marketing. AppsFlyer almacena los datos de sus 100 000 millones de eventos al día en un lago de datos a escala de petabytes en Amazon S3. Sin embargo, tenía poca idea de si los objetos de más de 365 días volverían a necesitarse con frecuencia en el futuro y, por lo tanto, incurrirían en gastos de recuperación inesperados. AppsFlyer necesitaba una solución diferente y la encontró en S3 Intelligent-Tiering.
AppsFlyer pudo tomar una decisión informada para migrar los datos a S3 Intelligent-Tiering, lo que supuso una reducción de costos del 18 % por GB almacenado. Reducir costos es fundamental para AppsFlyer, ya que contribuye a aumentar los ingresos y permite invertir en nuevas cargas de trabajo.
“S3 Intelligent-Tiering nos permite aprovechar mejor los datos históricos y ser más eficientes en costos cada vez que necesitamos acceder a estos y realizar modificaciones”.
Reshef Mann, director de tecnología y cofundador de AppsFlyer
Blog: Cómo AppsFlyer redujo el costo del lago de datos con Amazon S3 Intelligent-Tiering »

Capital One
Capital One ha sido un disruptor en la industria de los servicios financieros desde 1994, al utilizar la tecnología para transformar la banca y los pagos. En la actualidad, el “banco digital” apuesta por AWS y adopta el almacenamiento, el análisis de datos, los microservicios, las tecnologías de IA y ML y otras soluciones para seguir innovando.
“Queríamos encontrar una forma de optimizar rápidamente los costos de almacenamiento en los buckets más grandes y de más rápido crecimiento de la empresa. Dado que los patrones de uso del almacenamiento varían mucho entre nuestros buckets principales, no existía una regla clara que pudiéramos aplicar de forma segura sin incurrir en gastos operativos generales. La clase de almacenamiento S3 Intelligent-Tiering ofreció ahorros automáticos basados en los patrones de acceso cambiantes de nuestros datos, sin afectar el rendimiento. Esperamos con entusiasmo el nuevo nivel Archive Instant Access de S3 Intelligent-Tiering, que nos permitirá lograr aún mayores ahorros sin esfuerzo adicional”.
Jerzy Grzywinski, director de ingeniería de software, Capital One

Mobileye
Mobileye lidera la revolución de la movilidad con sus tecnologías de conducción autónoma y asistencia al conductor, y aprovecha una experiencia de renombre mundial en visión artificial, machine learning, mapeo y análisis de datos.
“Usamos Amazon S3 Intelligent-Tiering porque los patrones de acceso suelen ser impredecibles. Con el nuevo nivel Archive Instant Access de S3 Intelligent-Tiering, reduciremos aún más los costos de muchos petabytes de datos de vehículos autónomos y, al mismo tiempo, los mantendremos accesibles de inmediato para que los usen nuestros desarrolladores”.
Yanor Barros, director de desarrollo de infraestructura en la nube, Mobileye

Epic Games
Epic Games es la empresa de entretenimiento interactivo detrás de Fortnite, uno de los videojuegos más populares del mundo con más de 400 millones de jugadores. Fundada en 1991, Epic revolucionó el mundo de los videojuegos con el lanzamiento de Unreal Engine, el motor de creación 3D que impulsa cientos de videojuegos y que hoy se utiliza en diversas industrias como la automotriz, el cine y la televisión o la simulación, para producción en tiempo real.
“Gracias a S3 Intelligent-Tiering, podemos implementar cambios en el almacenamiento sin interrupciones en el servicio ni en la actividad. Nuestros datos se trasladan automáticamente a niveles de menor costo según el acceso, lo que nos ahorra mucho tiempo de desarrollo además de reducir los costos. Con ese tiempo, mi equipo se puede concentrar en identificar otras oportunidades para reducir los costos de infraestructura y así apoyar los objetivos de nuestra organización. El nuevo nivel Archive Instant Access de S3 Intelligent-Tiering nos ayudará a ahorrar aún más en costos de almacenamiento”.
Joshua Bergen, director de administración de costos, Epic Games

Embark
Embark está desarrollando tecnología de camiones autónomos para hacer que las carreteras sean más seguras y mejorar la eficiencia del transporte. Cuando se produjo la pandemia de la COVID-19, Embark tomó la decisión de detener sus operaciones de camiones para cumplir con su responsabilidad social con la salud pública y garantizar la seguridad de su personal. Embark recurrió a sus petabytes de datos históricos en Amazon S3 y desarrolló sistemas que le permitieran aprovecharlos más a fondo.
Los ingenieros empezaron a basarse en años de datos históricos, analizaron miles de horas de datos de conducción para encontrar escenarios de interés y utilizaron estos datos para crear simulaciones más sólidas con las que poder probar su sistema. Como todos los datos de Embark se almacenaban con la clase de almacenamiento S3 Intelligent-Tiering, Embark no tuvo que perder tiempo pensando en qué datos deberían estar disponibles ni en cómo moverlos entre los diferentes niveles de almacenamiento para optimizar los costos y, al mismo tiempo, permitir este patrón repentino de acceso aleatorio a los datos en su lago de datos.
S3 Intelligent-Tiering se encargó de optimizar los costos para que su equipo pudiera centrar todos sus esfuerzos de ingeniería en crear mejores canalizaciones de datos y sistemas de simulación. Con la ayuda de AWS, el equipo de Embark se pudo adaptar rápidamente a los desafíos de la pandemia y, una vez levantada la pausa, retomó su enfoque en ofrecer los beneficios de seguridad y eficiencia de los camiones autónomos.

Recursos
Introducción a S3 Intelligent-Tiering
Puede configurar S3 Intelligent-Tiering como la clase de almacenamiento predeterminada para los datos nuevos. Para ello, especifique INTELLIGENT-TIERING en el encabezado de la solicitud PUT de la API de S3. S3 Intelligent-Tiering está diseñado para ofrecer un 99,9 % de disponibilidad y una durabilidad del 99,999999999 %, y proporciona automáticamente el mismo rendimiento de baja latencia y alto rendimiento que S3 Standard. Para más información, consulte la guía del usuario de S3 Intelligent-Tiering.
Empiece a ahorrar hoy mismo: migre su almacenamiento a Amazon S3
El Programa de Aceleración de la Migración de AWS para almacenamiento está compuesto por servicios de AWS, prácticas recomendadas y herramientas diseñadas para ayudar a los clientes a reducir costos y acelerar la migración de cargas de trabajo de almacenamiento a AWS. Alcance sus objetivos de migración aún más rápido con los incentivos, las prácticas recomendadas, las herramientas y los servicios de AWS. Las cargas de trabajo que son adecuadas para la migración del almacenamiento incluyen lagos de datos en las instalaciones, repositorios de datos grandes no estructurados, recursos compartidos de archivos, directorios de inicio, copias de seguridad y archivos.
AWS ofrece más formas de ayudarlo a reducir los costos de almacenamiento y muchas opciones para migrar sus datos. Es por eso que cada vez más clientes eligen el almacenamiento de AWS para sentar las bases de su entorno de TI en la nube. Más información sobre el Programa de Aceleración de la Migración para almacenamiento »