AWS News Blog
S3 Intelligent-Tiering Adds Archive Access Tiers

|
We launched S3 Intelligent-Tiering two years ago, which added the capability to take advantage of Amazon S3 without needing to have a deep understanding of your data access patterns. Today we are launching two new optimizations for S3 Intelligent-Tiering that will automatically archive objects that are rarely accessed. These new optimizations will reduce the amount of manual work you need to do to archive objects with unpredictable access patterns and that are not accessed for months at a time.
What is S3 Intelligent-Tiering?
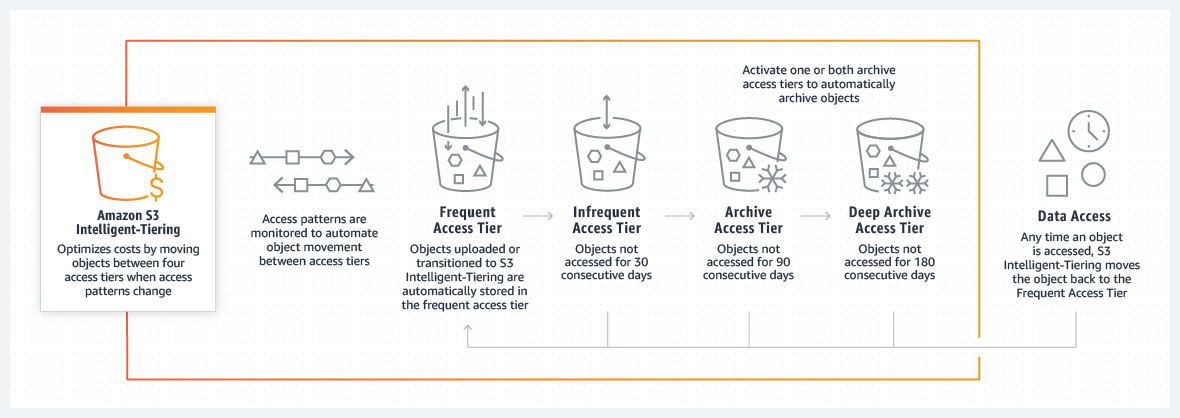
S3 Intelligent-Tiering is a storage class that is designed to optimize storage costs by automatically moving data to the most cost-effective access tier without performance impact or operational overhead. We added S3 Intelligent-Tiering to Amazon Amazon S3 to solve the problem of using the right storage class and optimizing costs when access patterns are irregular.
S3 Intelligent-Tiering delivers automatic cost savings by moving data on a granular object level between access tiers when the access patterns change. This is the perfect storage class when you want to optimize storage costs for data that has unknown or unpredictable access patterns. For a small monthly object monitoring and automation fee, S3 Intelligent-Tiering monitors the access patterns and moves the objects automatically from one tier to another.
What Are We Announcing Today?
In order to further reduce their storage costs, many customers prefer to archive rarely accessed objects directly to S3 Glacier or S3 Glacier Deep Archive. However, this requires you to build complex systems that understand the access patterns of objects for a long period of time and archive them when the objects are not accessed for months at a time.
Today we are announcing two new archive access tiers designed for asynchronous access that are optimized for rare access at a very low cost: Archive Access tier and Deep Archive Access tier. You can opt-in to one or both archive access tiers and you can configure them at the bucket, prefix, or object tag level.
Now with S3 Intelligent-Tiering, you can get high throughput and low latency access to your data when you need it right away, and automatically pay about $1 per TB per month when objects haven’t been accessed for 180 days or more. Already customers of S3 Intelligent-Tiering have realized cost savings up to 40% and now using the new archive access tiers they can reduce storage costs up to 95% for rarely accessed objects.
Available access tiers:
- Frequent Access tier and Infrequent Access tier: One tier is optimized for frequent access and another lower-cost tier that is optimized for infrequent access. These tiers give customers low latency and high throughput performance. After 30 days in the frequent access tier, an object that was not accessed will be moved to the infrequent access tier. Frequent access tier is priced as S3 Standard and Infrequent access tier is priced as S3 Standard – Infrequent Access.
- Archive Access tier (NEW): It has the same performance and pricing as S3 Glacier storage class.
- Deep Archive Access tier (NEW): It has the same performance and pricing as S3 Glacier Deep Archive storage class.
How Do the New Archive Access Tiers Work?
Once you have activated one or both of the archive access tiers, S3 Intelligent-Tiering will automatically move objects that haven’t been accessed for 90 days to the Archive Access tier, and after 180 days without being accessed to the Deep Archive Access tier. At any time that an object that is in one of the archive access tiers is restored, the object will move to the Frequent Access tier within a few hours and then it will be ready to be retrieved.
Objects in the archive access tiers are retrieved in 3-5 hours and if they are in the deep archive access tier within 12 hours. If you need access to an object in any of the archive tiers faster, you can pay for faster retrieval by selecting in the console expedited retrieval.
How S3 Intelligent-Tiering works
How to Get Started With the New Intelligent-Tiering Archive Access Tiers?
The configuration for the Intelligent-Tiering archive access tiers is defined on the bucket level. First, in the bucket Properties, create a new configuration for the Intelligent-Tiering Archive. You can define one or more configuration rules for your Intelligent-Tiering archive.

Archive configuration settings
In the archive configuration settings page, you can choose to apply the configuration to all the objects in the bucket that are using the S3 Intelligent-Tiering storage class or you can limit the scope of this configuration rule by defining filters. The two options available to define filters are: object prefix or object tags.
After you decide which objects in the bucket this rule should apply to, you need to enable one or both archive access tiers. When you enable one of the archive access tiers, you can define in how many days you want this object to transition to this access tier – for the Archive Access tier this number needs to be equal or greater than 90 and for the Deep Archive Access tier equal or greater than 180 days.

Configure the archive access tier movement
After you are done creating your configuration, you can see all of the rules in the Properties of the bucket under Intelligent-Tiering archive configurations, and you can edit the rules at any time.

Intelligent-tiering archive configurations
After defining the configuration, when you upload a new object to Amazon S3 that matches the filters you defined in the rules, and you select the storage class Intelligent-Tiering, this object will transition for all the access tiers you configured as time passes and it is not accessed.
For more information on optimizing costs with S3 Intelligent-Tiering Archive Access Tiers watch this video.
Some last things to keep in mind:
- Object size: You can use Intelligent-Tiering for objects of any size, but objects smaller than 128KB will be kept in the Frequent Access tier. For each object archived to the Archive Access tier or Deep Archive Access tier, Amazon S3 uses 8 KB of storage for the name of the object and other metadata (billed at S3 Standard storage rates) and 32 KB of storage for index and related metadata (billed at S3 Glacier and S3 Glacier Deep Archive storage rates). This enables you to get a real-time list of all of your S3 objects or the S3 Inventory report.
- Object life: Intelligent-Tiering is suited for objects with a life longer than 30 days, and all the objects that use this storage class will be billed for a minimum of 30 days.
- Durability and availability: S3 Intelligent-Tiering is designed for 99.9% availability and 99.999999999% durability.
- Pricing: You pay for monthly storage, request and data transfer. When using Intelligent-Tiering you pay for a small monthly per-object fee for monitoring and automation. There is no retrieval fee in S3 Intelligent-Tiering and no fee for moving data between tiers. Objects in the Frequent Access tier are billed at the same rate as S3 Standard, objects stored in the Infrequent Access tier are billed at the same rate as S3 Standard Infrequent Access, objects stored in the Archive Access tier are billed at the same rate as S3 Glacier and objects stored in the Deep Archive access tier are billed at the same rate as S3 Deep Glacier.
- API and CLI access: You can use Intelligent-Tiering from S3 CLI and S3 APIs with the INTELLIGENT_TIERING storage class. You can also configure the Intelligent-Tiering archive using PUT, GET, and Delete configuration APIs for a specific bucket.
- Feature support: S3 Intelligent-Tiering supports features like S3 Inventory to report on the access tier of objects, and S3 Replication to replicate data to any AWS Region.
Available Now
New archive access tiers for S3 Intelligent-Tiering are available now in all AWS Regions. Get started today.
— Marcia