AWS News Blog
New – Automatic Cost Optimization for Amazon S3 via Intelligent Tiering

|
Amazon Simple Storage Service (Amazon S3) has been around for over 12.5 years, stores trillions of objects, and processes millions of requests for them every second. Our customers count on S3 to support their backup & recovery, data archiving, data lake, big data analytics, hybrid cloud storage, cloud-native storage, and disaster recovery needs. Starting from the initial one-size-fits-all Standard storage class, we have added additional classes in order to better serve our customers. Today, you can choose from four such classes, each designed for a particular use case. Here are the current options:
 Standard – Designed for frequently accessed data.
Standard – Designed for frequently accessed data.
Standard-IA – Designed for long-lived, infrequently accessed data.
One Zone-IA – Designed for long-lived, infrequently accessed, non-critical data.
Glacier – Designed for long-lived, infrequent accessed, archived critical data.
You can choose the applicable storage class when you upload your data to S3, and you can also use S3’s Lifecycle Policies to tell S3 to transition objects from Standard to Standard-IA, One Zone-IA, or Glacier based on their creation date. Note that the Reduced Redundancy storage class is still supported, but we recommend the use of One Zone-IA for new applications.
If you want to tier between different S3 storage classes today, Lifecycle Policies automates moving objects based on the creation date of the object in storage. If your data is stored in Standard storage today and you want to find out if some of that storage is suited to the S-IA storage class, you can use Storage Class Analytics in the S3 Console to identify what groups of objects to tier using Lifecycle. However, there are many situations where the access pattern of data is irregular or you simply don’t know because your data set is accessed by many applications across an organization. Or maybe you are spending so much focusing on your app, you don’t have time to use tools like Storage Class Analysis.
New Intelligent Tiering
In order to make it easier for you to take advantage of S3 without having to develop a deep understanding of your access patterns, we are launching a new storage class, S3 Intelligent-Tiering. This storage class incorporates two access tiers: frequent access and infrequent access. Both access tiers offer the same low latency as the Standard storage class. For a small monitoring and automation fee, S3 Intelligent-Tiering monitors access patterns and moves objects that have not been accessed for 30 consecutive days to the infrequent access tier. If the data is accessed later, it is automatically moved back to the frequent access tier. The bottom line: You save money even under changing access patterns, with no performance impact, no operational overhead, and no retrieval fees.
You can specify the use of the Intelligent-Tiering storage class when you upload new objects to S3. You can also use a Lifecycle Policy to effect the transition after a specified time period. There are no retrieval fees and you can use this new storage class in conjunction with all other features of S3 including cross-region replication, encryption, object tagging, and inventory.
If you are highly confident that your data is accessed infrequently, the Standard-IA storage class is still a better choice with respect to cost savings. However, if you don’t know your access patterns or if they are subject to change, Intelligent-Tiering is for you!
Intelligent Tiering in Action
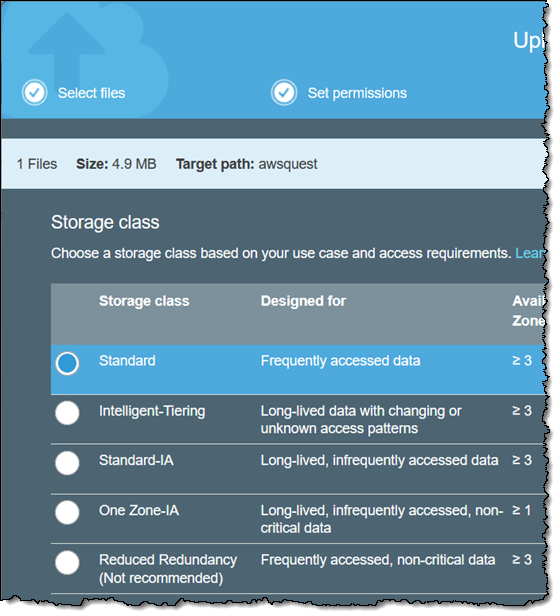
I simply choose the new storage class when I upload objects to S3:
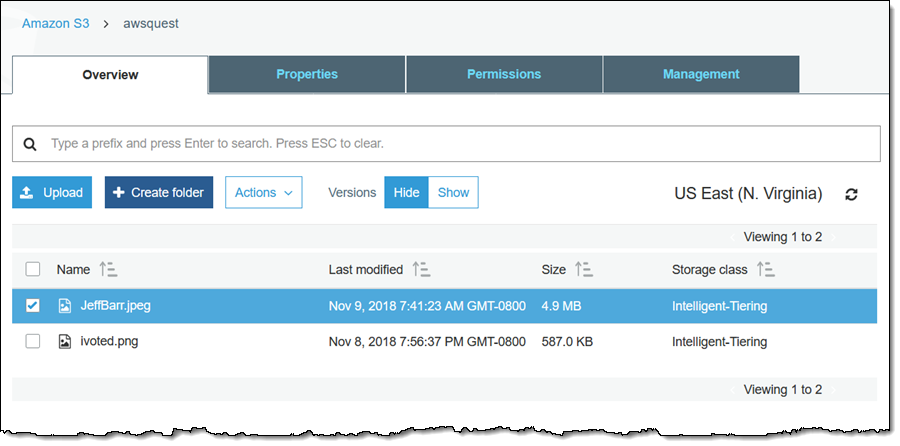
I can see the storage class in the S3 Console, as usual:
And I can create Lifecycle Rules that make use of Intelligent-Tiering:
![]()
And that’s just about it. Here are a few things that you need to know:
Object Size – You can use Intelligent-Tiering for objects of any size, but objects smaller than 128 KB will never be transitioned to the infrequent access tier and will be billed at the usual rate for the frequent access tier.
Object Life – This is not a good fit for objects that live for less than 30 days; all objects will be billed for a minimum of 30 days.
Durability & Availability – The Intelligent-Tiering storage class is designed for 99.9% availability and 99.999999999% durability, with an SLA that provides for 99.0% availability.
Pricing – Just like the other storage classes, you pay for monthly storage, requests, and data transfer. Storage for objects in the frequent access tier is billed at the same rate as S3 Standard; storage for objects in the infrequent access tier is billed at the same rate as S3 Standard-Infrequent Access. When you use Intelligent-Tiering, you pay a small monthly per-object fee for monitoring and automation; this means that the storage class becomes even more economical as object sizes grow. As I noted earlier, S3 Intelligent-Tiering will automatically move data back to the frequent access tier based on access patterns but there is no retrieval charge.
Query in Place – Queries made using S3 Select do not alter the storage tier. Amazon Athena and Amazon Redshift Spectrum access the data using the regular GET operation and will trigger a transition.
API and CLI Access – You can use the storage class INTELLIGENT_TIERING from the S3 CLI and S3 APIs.
Available Now
This new storage class is available now and you can start using it today in all AWS Regions.
— Jeff;
PS – Remember the trillions of objects and millions of requests that I just told you about? We fed them into an Amazon Machine Learning model and used them to predict future access patterns for each object. The results were then used to inform storage of your S3 objects in the most cost-effective way possible. This is a really interesting benefit that is made possible by the incredible scale of S3 and the diversity of use cases that it supports. There’s nothing else like it, as far as I know!